


CVPR 2022 | 港科大提出C2FViT:使用粗到精的视觉Transformer的仿射医学图像配准

一句话总结
本文提出了一种专用于 3D 仿射医学图像配准的由粗到精视觉Transformer:C2FViT,利用了卷积、VIT和多分辨率策略,性能表现SOTA!代码即将开源!收录于CVPR 2022!
想看更多CVPR 2022论文和开源项目可以点击:
点击关注 @CVer计算机视觉 ,第一时间看到最优质、最前沿的CV、AI工作~
注:文末附【Transformer】和【医学图像】交流群
C2FViT
Affine Medical Image Registration with Coarse-to-Fine Vision Transformer


单位:香港科技大学
代码: https:// github.com/cwmok/C2FViT
论文: https:// arxiv.org/abs/2203.1521 6
仿射配准在综合医学图像配准pipeline中是必不可少的。然而,只有少数研究关注快速和稳健的仿射配准算法。这些研究中的大多数利用卷积神经网络 (CNN) 来学习联合仿射和非参数配准,而对仿射子网络的独立性能的探索较少。此外,现有的基于 CNN 的仿射配准方法要么关注局部错位,要么关注输入的全局方向和位置来预测仿射变换矩阵,这对空间初始化很敏感,并且除了训练数据集之外表现出有限的泛化性。
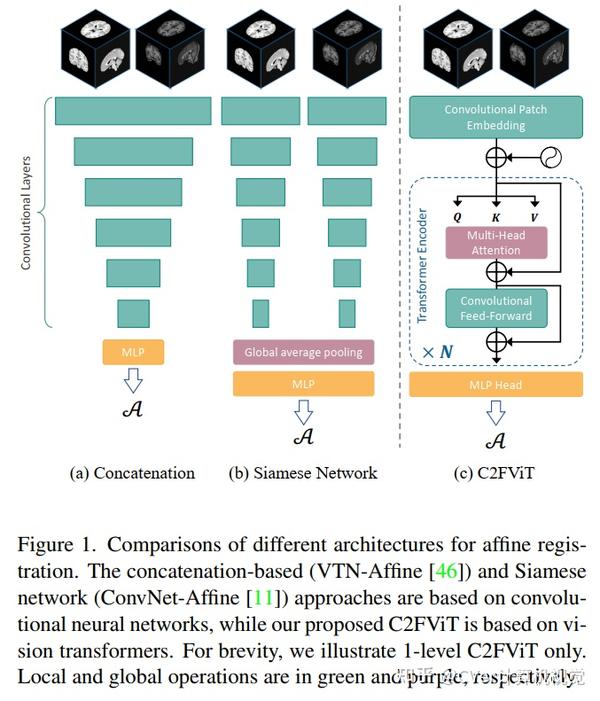
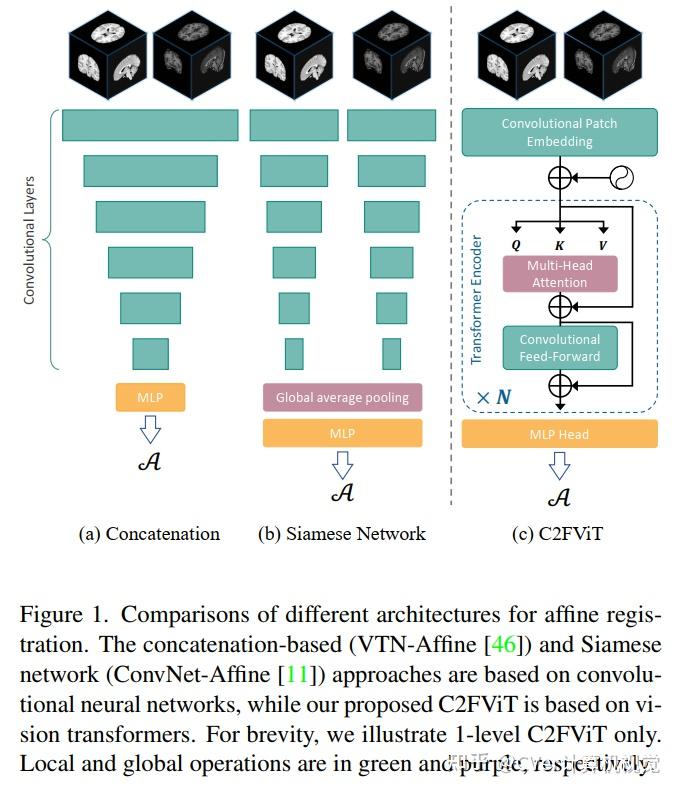
在本文中,我们提出了一种快速且稳健的基于学习的算法,即粗到精视觉Transformer (C2FViT),用于 3D 仿射医学图像配准。
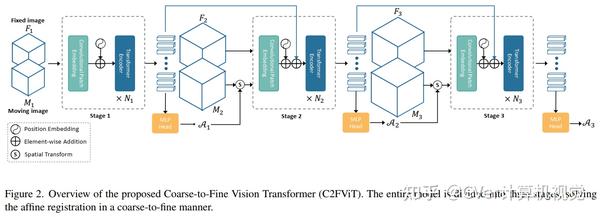
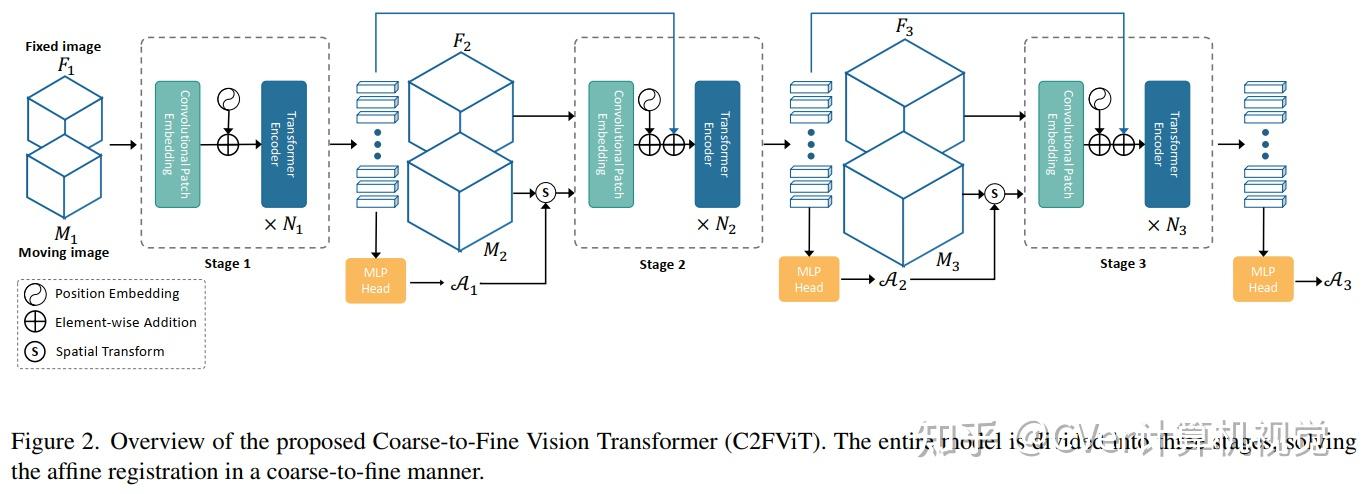
我们的方法自然地利用了卷积视觉Transformer的全局连通性和局部性以及多分辨率策略来学习全局仿射配准。我们评估了我们在 3D 脑图谱配准和模板匹配归一化方面的方法。
主要贡献


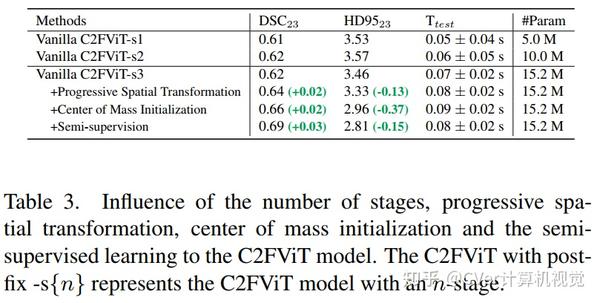
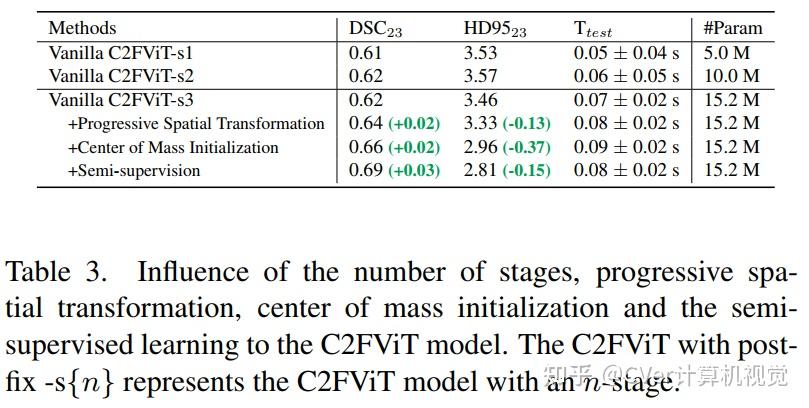
实验结果
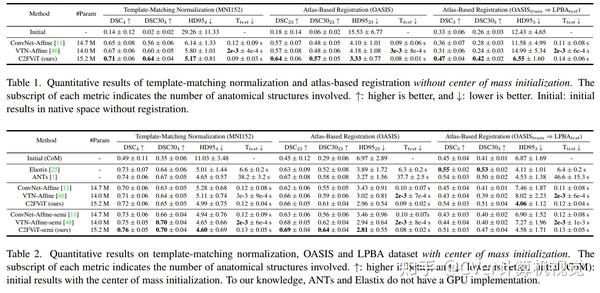
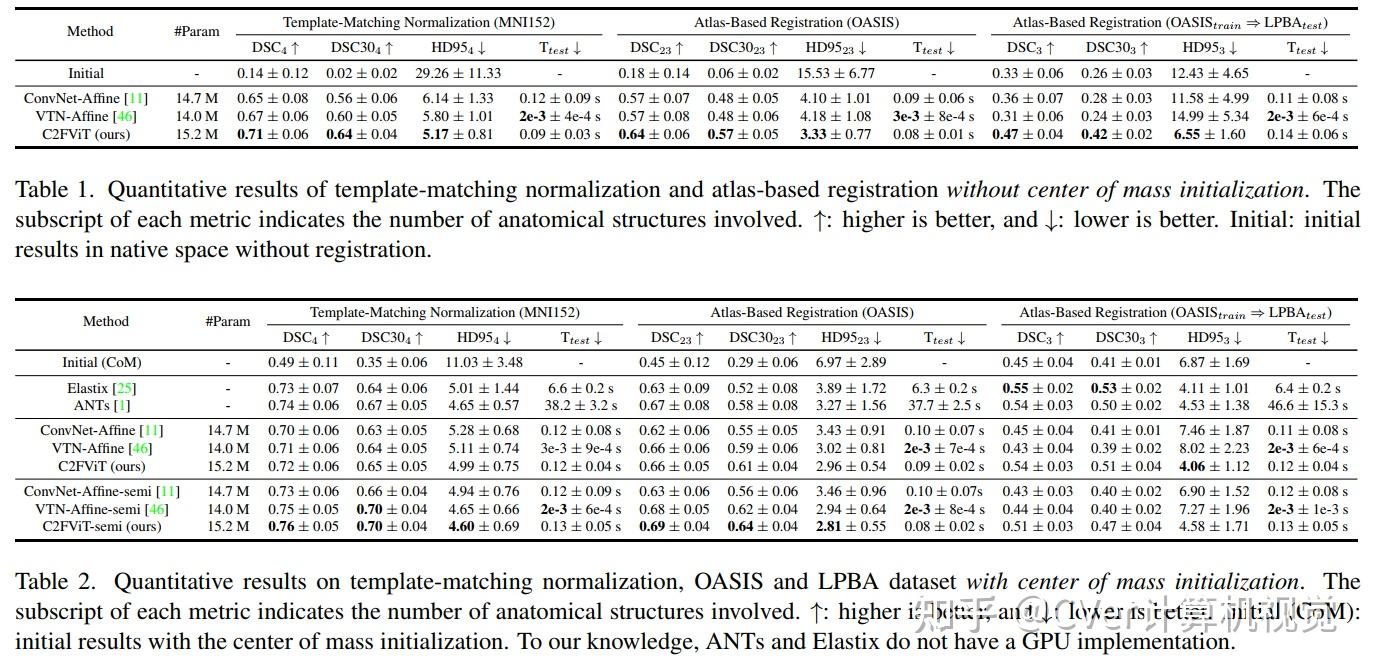
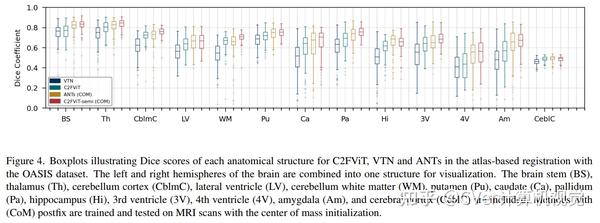
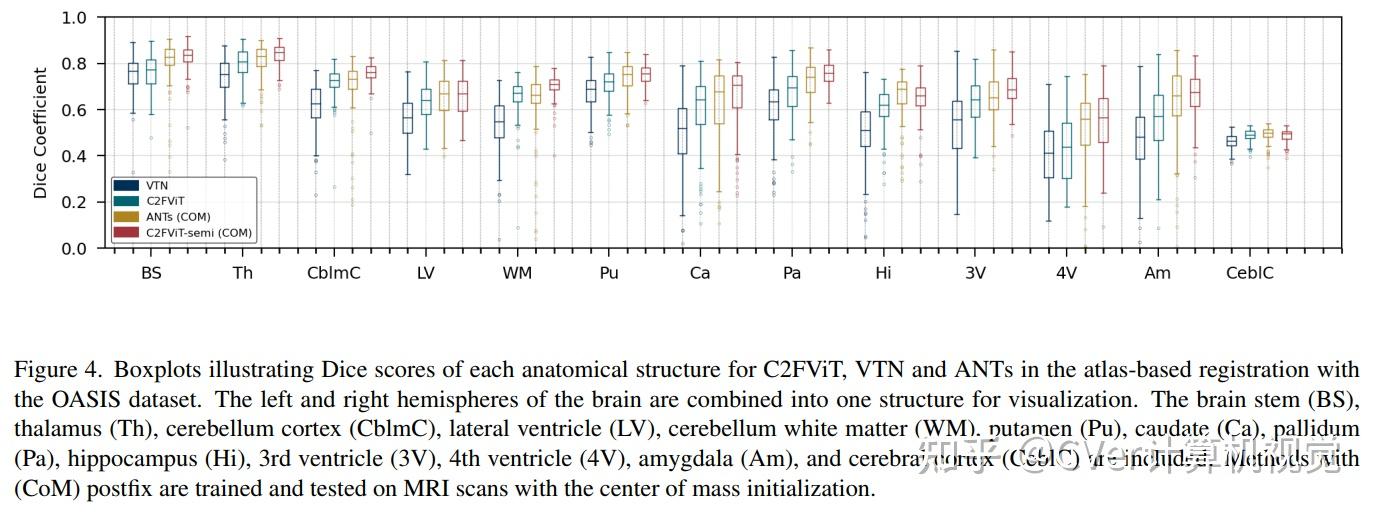
综合结果表明,我们的方法在配准精度、鲁棒性和通用性方面优于现有的基于 CNN 的仿射配准方法,同时保留了基于学习的方法的运行时优势。
CVer-Transformer交流群
建了CVer-Transformer交流群!想要进Transformer学习交流群的同学,可以直接加微信号: CVer6666 。加的时候备注一下: Transformer+学校/公司+昵称+知乎 ,即可。然后就可以拉你进群了。
CVer-医学图像交流群
建了CVer-医学图像交流群!想要进医学图像学习交流群的同学,可以直接加微信号: CVer6666 。加的时候备注一下: 医学图像+学校/公司+昵称+知乎 ,即可。然后就可以拉你进群了。
强烈推荐大家关注 CVer知乎 账号和 CVer 微信公众号,可以快速了解到最新优质的CV论文。
推荐阅读
CVPR 2022 | 百度开源Rope3D:用于单目3D目标检测的路侧感知数据集
刷新纪录!SCUNet:通过Swin-Conv-UNet和数据合成的实用盲去噪
CVPR 2022 | UniDet:通用的多数据集目标检测
CVPR 2022 | SparseInst:实时实例分割的稀疏实例激活
复旦&亚马逊开源BigDetection:改进目标检测器预训练的大规模基准
替代微调!Meta AI提出VPT:视觉Prompt Tuning
CVPR 2022 | Transformer再屠榜!南大提出MixFormer:端到端目标跟踪新网络
CVPR 2022 | DW:一种用于目标检测的双重加权标签分配方案
CVPR 2022 | TATT:用于场景文本图像超分辨率的文本注意力网络
CVPR2022 | 武大提出E2EC:基于端到端轮廓的高质量高速实例分割方法
CVPR 2022 | BoostMIS:医学图像半监督学习(SSL)框架
CVPR 2022 | 即插即用!助力自监督涨点的ContrastiveCrop开源了!
CVPR 2022 | MPViT:用于密集预测的多路径视觉Transformer
Transformer-UNet:基于Transformer的可变形医学图像配准网络
清华提出:最新的计算机视觉注意力机制(Attention)综述!
Swin Transformer夺得ICCV 2021最佳论文!中国学者拿下“半壁江山”!
