【领域自适应目标检测】论文及代码整理

持续更新中......
上次更新:2022-06-19
阅读建议:以下论文的整理按照时间先后顺序,在小标题有对应年份与发表刊物,如“2018_CVPR”
关于Domain Adaptation Object Detection的最新进展可以关注下面两个github链接:
感谢以上两位的整理!
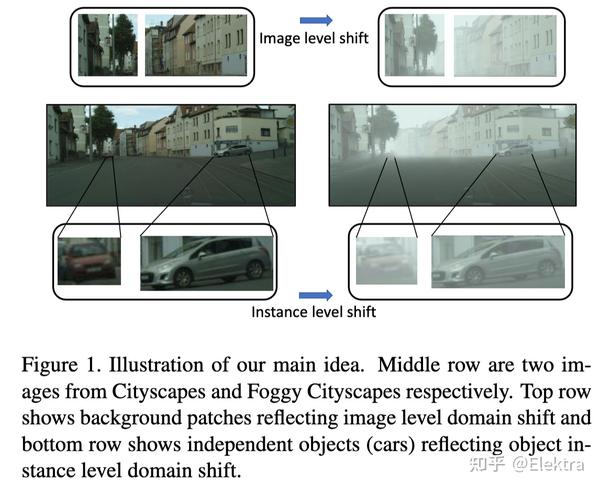
2018_CVPR Domain Adaptive Faster R-CNN for Object Detection in the Wild

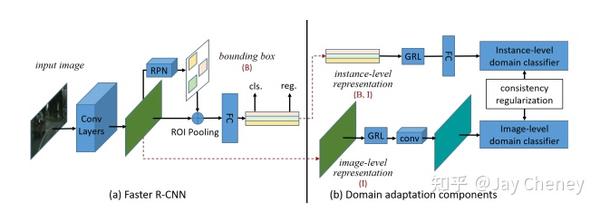
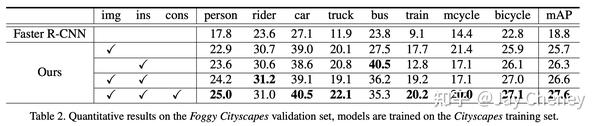
摘要: 目标检测通常假设训练和测试数据来自相同的分布,但是实际上并不总是如此。这样的分配不匹配将导致性能显著下降。在这项工作中,我们旨在提高目标检测的跨域鲁棒性。我们在两个级别上处理域偏移: 1)图像级别的偏移 ,例如图像样式,光照等;以及 2)实例级别的偏移 ,例如对象的外观,大小等。我们使用的Faster R-CNN模型,并在图像级别和实例级别设计两个域自适应组件,以减少域差异。这两个领域自适应组件基于 H-散度 理论,并且通过以对抗训练的方式学习领域分类器来实现。通过 一致性正则化 进一步增强不同级别的域分类器,以学习Faster R-CNN模型中的领域不变区域提议网络(RPN)。我们使用包括Cityscapes,KITTI,SIM10K等在内的多个数据集评估了我们提出的新方法。结果证明了我们提出的方法在各种域移动场景下对鲁棒物体检测的有效性。


相关代码:
https://
github.com/yuhuayc/da-f
aster-rcnn
(官方 caffe)
star271
https://
github.com/krumo/Detect
ron-DA-Faster-RCNN
(caffe2)
star32
https://
github.com/krumo/Domain
-Adaptive-Faster-RCNN-PyTorch
(pytorch)
star151
https://
github.com/divyam02/daf
rcnn-pytorch/tree/cleaning
(pytorch)
star43
https://
github.com/tiancity-NJU
/da-faster-rcnn-PyTorch
(pytorch)
star88
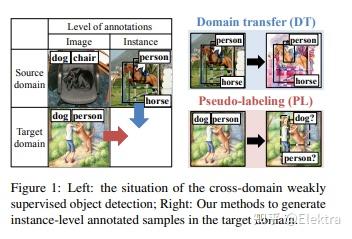
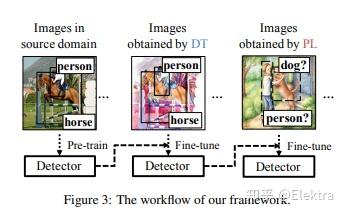
2018_CVPR Cross-Domain Weakly-Supervised Object Detection through Progressive Domain Adaption


摘要: 我们是否可以在没有实例级注释的情况下检测各种图像域中的常见对象?在本文中,我们提出了一个新颖的任务框架,即 跨域弱监督目标检测(cross-domain weakly supervised object detection) ,它解决了这个问题。在本文中,我们有实例级标注(instance-level annotations)的图像作为源域(例如,自然图像)和具有图像级别标注(image-level annotations)的图像(例如,watercolor)。另外,要在目标域中检测的类是源域中的所有类或这些类的子集。从在源域上经过预训练的全监督的目标检测器开始,我们通过在两种类型的人工和自动生成的样本上对检测器进行微调,提出了一种 两步式渐进域自适应 技术。我们在我们新收集的包含三个图像域的数据集上测试我们的方法,并且在mAP上比性能最好的baselines提高了大约5-20个百分点。
1.在源域数据训练检测器
2. 利用cyclegan,将源域数据转换为目标域,然后微调
3. 对目标域数据生成伪标签,继续微调
代码: https:// github.com/naoto0804/cr oss-domain-detection star325
备注:229Citations
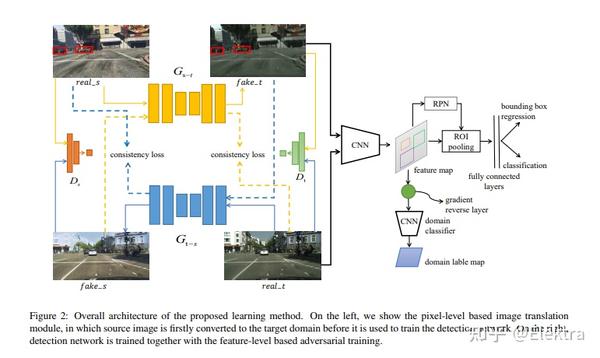
2018_Neurocomputing Pixel and Feature Level Based Domain Adaption for Object Detection in Autonomous Driving
摘要: 对于许多实际任务来说,标注大规模数据集以训练卷积神经网络的成本高得令人望而却步且耗时。一种可替代的方法是在标记的合成数据集上训练模型,并将其应用于真实场景。然而,这种简单的方法通常无法很好地推广,主要是由于合成数据集和真实数据集之间的域偏差(domain bias)。引入了许多无监督域适应(UDA)方法来解决此问题,但其中大多数仅关注简单的分类任务。在本文中,我们提出了一种新的UDA模型,以解决 自动驾驶背景下更复杂的目标检测问题( the more complex object detection problem in the context of autonomous driving ) 。我们的模型集成了基于像素级和特征级的转换,以完成跨域检测任务,并且可以进一步进行端到端训练,以追求更好的性能。我们采用 生成对抗网络的优化目标(objectives of the generative adversarial network ) 和 循环一致性损失( the cycle consistency loss) 来进行像素空间中的图像转换。为了解决潜在的语义不一致问题,我们提出了基于 区域提案的特征对抗训练( region proposal based feature adversarial training ),以保留目标对象的语义,并进一步减少域偏移。在几个不同的数据集上进行了广泛的实验,结果证明了我们方法的鲁棒性和优越性。

2018_WACV Unsupervised Adversarial Visual Level Domain Adaptation for Learning Video Object Detectors from Images


摘要: 基于深度学习的目标检测器需要大量带边界框和类标注的样本。尽管近年来,随着多个大规模静态图像数据集的发布,图像目标检测器取得了快速进展,但由于没有带标注的视频帧,视频上的目标检测仍然是一个悬而未决的问题。拥有强大的视频目标检测器是视频理解和策划视频中大规模自动标注的重要组成部分。图像和视频之间的域差异使得图像目标检测器对视频的可转移性次优。最常见的解决方案是使用弱监督标注,其中必须将视频帧标记为存在/不存在对象类别。这仍然需要手动工作。在本文中,我们通过调整无监督对抗性图像到图像转换的概念,使静态高质量图像在视觉上与视频帧集无法区分,从而实现了视频域的零监督。我们假设存在一个完全注释的静态图像数据集和一个未注释的视频帧。目标检测器使用原始数据集的注释在对抗变换的图像数据集上进行训练。使用两个当代基线目标检测器对Youtube-Objects和Youtube-Objects-Subset数据集进行的实验表明,与直接应用图像目标检测器相比,这种无监督像素级域自适应提高了视频帧的泛化性能。此外,与最近弱监督方法的基线相比,我们实现了有竞争力的表现。本文可以看作是图像转换在跨域目标检测中的应用。



备注: 文章表述不清
2018_ArXiv SPLAT: Semantic Pixel-Level Adaptation Transforms for Detection


摘要: 视觉检测器的领域自适应是一个critical的挑战,但现有的方法忽略了像素外观转换(pixel appearance transformations),而是专注于自举和领域混淆损失。我们提出了一种 语义像素级自适应变换(Semantic Pixel-Level Adaptation Transform) (SPLAT)方法来自适应检测器,可有效地生成跨域图像对。我们的模型使用 对齐对(aligned-pair) 和/或 伪标签损失( pseudo-label losses) 来使目标检测器适应目标域,并且可以学习源域中具有或不具有密集标记数据(例如语义分割注释)的转换。如果没有密集标签,源域中只有检测标签可用时,使用 CycleGAN 对齐来学习变换。否则,当密集标签可用时,我们引入了一种更有效的cycle-free的方法,该方法利用像素级语义标签来调节转换网络的训练。然后使用来自源域的检测框标签训练结束任务,其中可能包括在未标记的源域数据上推断的标签。我们的实验表明像素级变换优于先前的检测器域适应方法,还表明我们的cycle-free方法优于先前的用于无约束的cycle-based的通用变换学习模型,同时运行速度提高了3.8倍。我们的组合模型在先前的检测基线基础上改进了 12.5 mAP ,从Sim 10K适应到Cityscapes,在unadapted baseline和labeled-target upper bound之间恢复了超过50%的缺失性能。
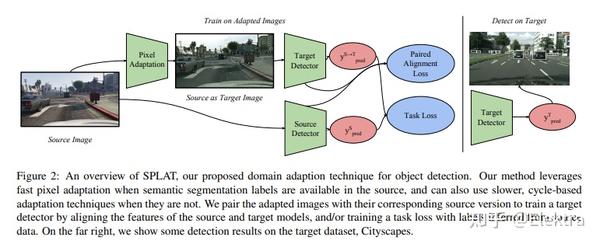

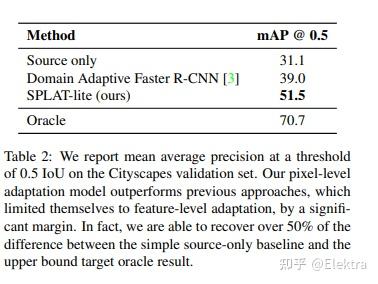
备注: 提升性能较高,文章仍然是对抗的思想
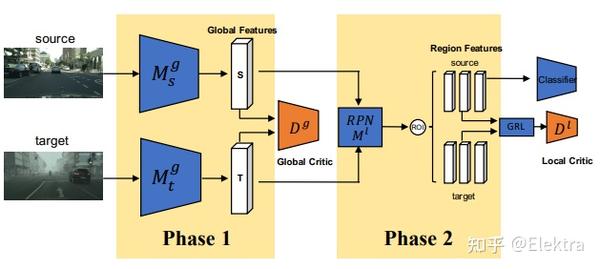
2019_CVPR Strong-Weak Distribution Alignment for Adaptive Object Detection


我们提出了一种用于目标检测器从label-rich域到label-poor域的无监督适配方法,该方法可以显着降低与检测相关的标注成本。近来,已证明使用对抗损失来对齐源域图像和目标图像分布的方法对于适应对象分类器是有效的。但是,对于目标检测,由于域可能具有不同的场景布局和对象的不同组合,因此在全局图像级别将源图像和目标图像的整个分布彼此完全匹配可能会失败。另一方面,局部特征(例如纹理和颜色)的强匹配是有意义的,因为它不会更改类别级别的语义。这促使我们提出一种基于 强局部对准和弱全局对准(strong local alignment and weak global alignment) 的检测器自适应新方法。我们的主要贡献是 弱对齐模型(the weak alignment model) ,该模型将对抗对齐损失集中在全局相似的图像上,而较少强调对齐全局不相似的图像。此外,我们设计了 强域对齐模型(the strong domain alignment model) ,来仅查看特征图的局部感受野。我们通过实验验证了我们的方法在包含大和小域偏移的四个数据集上的有效性。
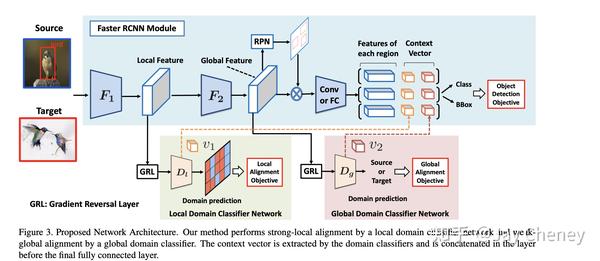


相关代码: https:// github.com/VisionLearni ngGroup/DA_Detection star240
2019CVPR Automatic adaptation of object detectors to new domains using self-training


摘要: 这项工作解决了现有目标检测器对新目标域的无监督适应。我们假设来自此域的大量未标注视频随时可用。我们通过使用来自现有检测器的高置信度检测来自动获取目标数据上的标签,并通过使用跟踪器利用时间线索获得的困难(错误分类)样本进行增强。然后,这些自动获取的标签用于重新训练原始模型。提出了一种修正的知识蒸馏损失,并研究了集中将软标签分配给目标域中的训练样本的方法。我们的方法在具有挑战性的人脸和行人检测任务上进行实证评估:在WIDES-Face上训练的人脸检测器,由从网上抓取的高质量图像组成,适用于大规模监控数据集;行人检测器根据来自 BDD-100K 驾驶数据集的清晰日间图像进行训练,适用于所有其他场景,如下雨、多雾、夜间。我们的研究结果证明了结合从跟踪中获得的困难样本的有用性,通过蒸馏损失使用软标签与硬标签相比的优势,显示出作为目标检测器无监督域适应的简单方法的高性能,并且对超参数的依赖性最小。




20190409_CVPR Towards Universal Object Detection by Domain Attention


摘要: 尽管在视觉识别的通用表示方面做出了越来越多的努力,但很少有人解决目标检测问题。在本文中,我们开发了一种有效且高效的通用目标检测系统,该系统能够处理从人脸和交通标志到医学CT图像的各种图像域。与多域模型(multi-domain models)不同,这种通用模型不需要感兴趣的域的先验知识。这是通过引入基于 挤压和激发(squeeze and excitation) 原理的新适应层系列以及新的域注意机制来实现的。在提出的通用检测器中,所有参数和计算在域之间共享,并且单个网络始终处理所有域。在新建立的11个不同数据集的通用目标检测基准上进行的实验表明,所提出的探测器优于一组单个探测器,一个多域探测器和一个基线通用探测器,参数比单域基线探测器增加1.3倍。


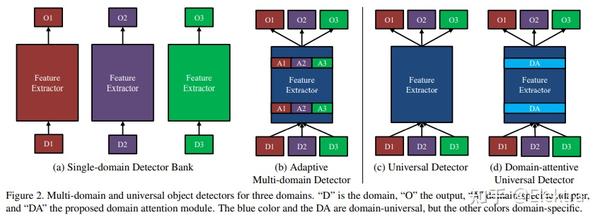
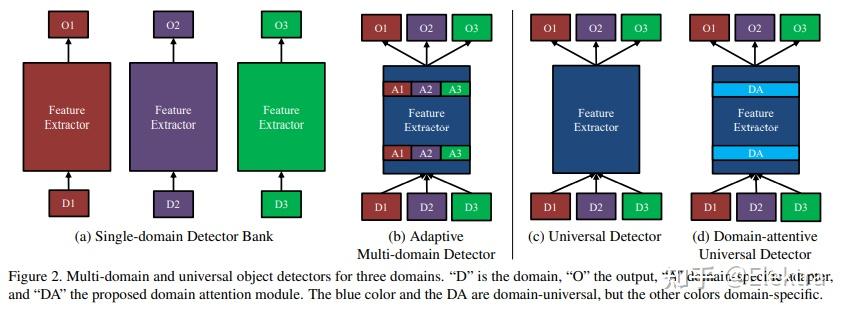
备注: 构建了一个11个域的通用数据集
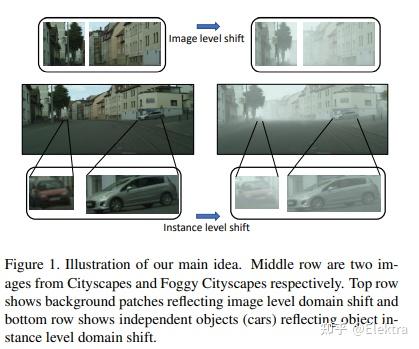
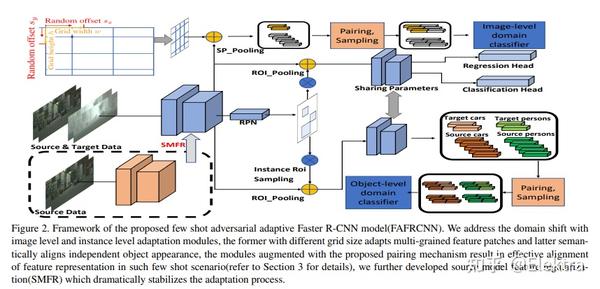
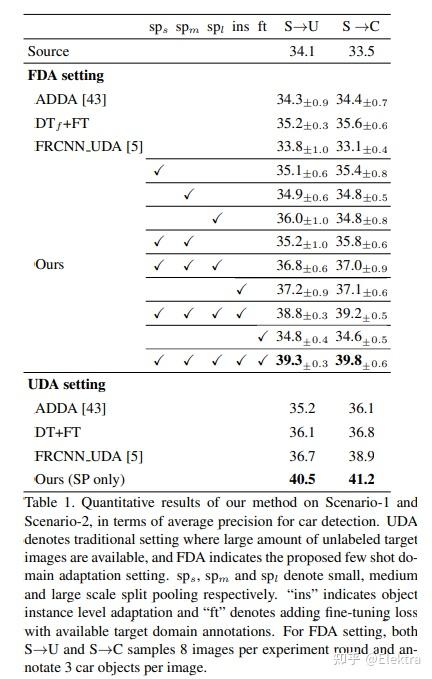
20190322_CVPR Few-shot Adaptive Faster R-CNN


摘要: 为了减轻由域偏移引起的检测性能下降,我们的目标是开发一种新颖的少样本适应方法,该方法只需要几个具有有限边界框注释的目标域图像。为此,我们首先观察到几个重大挑战。首先, 目标域数据严重不足 ,使得大多数现有的域适应方法无效。其次, 目标检测同时涉及定位和分类 ,使模型适应过程进一步复杂化。第三, 该模型存在过度适应 (类似于使用几个数据示例进行训练时的过度拟合)和不稳定性风险,这可能导致目标域中的检测性能下降。为了应对这些挑战,我们首先在源和目标特征上引入了一种 配对机制 ,以缓解目标域样本不足的问题。然后,我们提出了一个双级模块(bi-level module),使经过源训练的探测器适应目标域:
1)基于拆分池的图像级自适应模块以不同的比例和纵横比均匀地提取和对齐位置上成对的本地补丁特征;
2)实例级适配模块在语义上对齐配对目标特征,同时避免类间混淆。
同时,应用源模型特征正则化(source model feature regularization,SMFR)来稳定两个模块的适应过程。结合这些贡献,可以得到一种新颖的少样本自适应Faster-RCNN框架,称为FAFRCNN,它可以有效地适应了只具有一些标注的目标域。多个数据集的实验表明,在感兴趣的少样本域适应(FDA)和无监督域适应(UDA)设置下,我们的模型都实现了最先进的新性能。


20190404_ICCV A Robust Learning Approach to Domain Adaptive Object Detection


摘要:在目标检测的实际应用中,域漂移(Domain shift)是不可避免的。例如,在自动驾驶汽车中,目标域由不受约束的道路环境组成,这些环境不可能在训练数据中全部观察到。同样,由于隐私法规,在监控应用中可能缺乏具有足够代表性的训练数据。 在本文中,我们从鲁棒学习的角度解决了域适应问题,并表明该问题可以表述为带有噪声标签的训练。 我们提出了一个鲁棒的目标检测框架,该框架可以对边界框类标签,位置和大小注释中的噪声进行适应。为了适应域漂移,使用一组噪声目标边界框在目标域上训练模型,这些框由仅在源域中训练的检测模型获得。我们评估了我们的方法在各种源/目标域对中的准确性,并证明该模型在SIM10K,Cityscapes和KITTI数据集上的多个域适应场景中达到了SOTA。
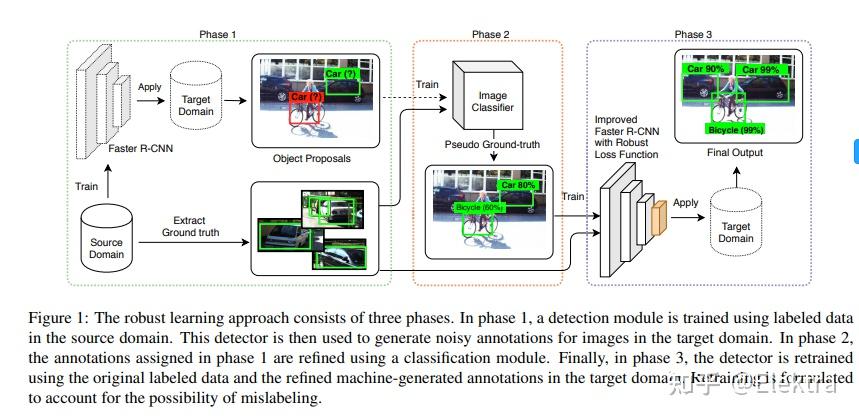
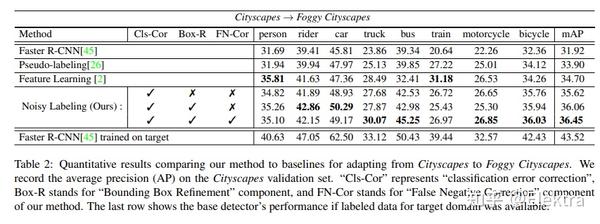

相关代码: Gabriel-Macias/robust_frcnn: Domain Adaptive Robust Faster R-CNN Implementation in Keras/TF (github.com) [非官方实现,基于 Keras/TF ]
99 Citations
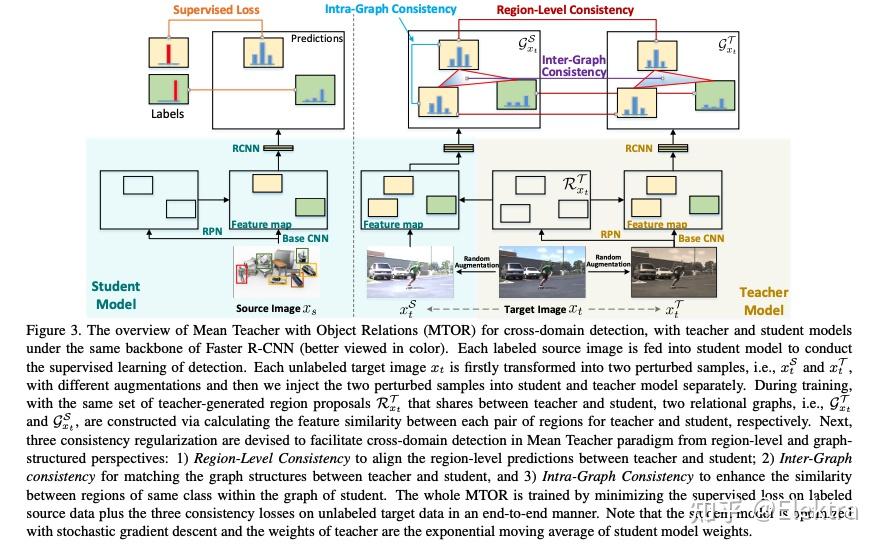
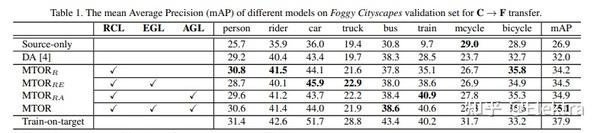
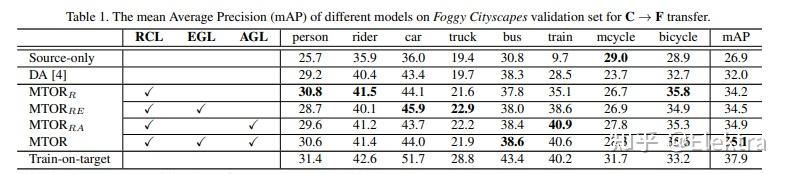
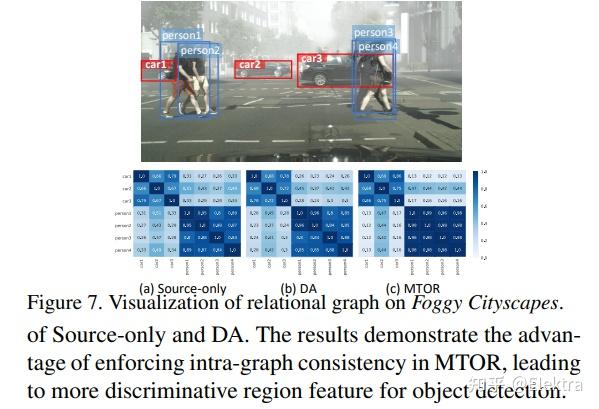
20190425_CVPR Exploring Object Relation in Mean Teacher for Cross-Domain Detection


摘要:近年来,渲染合成数据(例如 3D CAD 渲染图像)来生成用于在视觉任务中学习深度模型的标签已引起越来越多的关注。然而,简单地应用在合成图像上学习的模型可能会由于域漂移而导致对真实图像的高泛化误差。为了解决这个问题,跨域识别的最新进展以 Mean teacher 为特色,它直接将无监督域适应模拟为半监督学习。因此,在师生范式中,领域差距自然而然地与一致性正则化(consistency regularization)相联系。在这项工作中,我们推进了这种Mean teacher范式以适用于跨域检测。具体来说,我们提出了具有对象关系的Mean teacher(MTOR),它通过在 Faster R-CNN 的框架下新颖地将对象关系集成到教师和学生模块之间的一致性成本的度量中。从技术上讲,MTOR 首先学习关系图,分别捕捉教师和学生的区域对之间的相似性。然后使用三个一致性正则化优化整个架构:
1)region-level consistency to align the region-level predictions between teacher and student
2)inter-graph consistency for matching the graph structures between teacher and student
3)intra-graph consistency to enhance the similarity between regions of the same class within the graph of students.
对跨Cityscapes、Foggy Cityscapes 和 SIM10k 的跨域迁移进行了广泛的实验,与最先进的方法相比,取得了STOA的结果。更值得注意的是,我们获得了单一模型的新记录:Syn2Real 检测数据集上 mAP 的 22.8%。


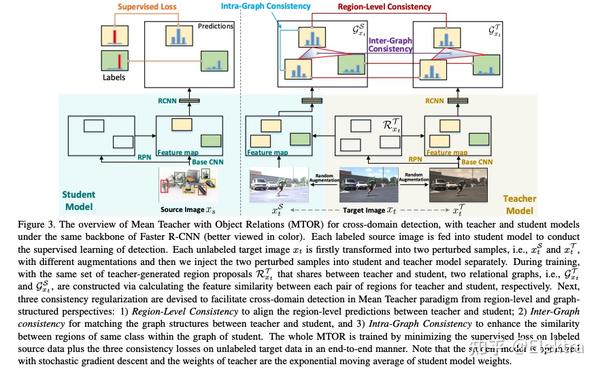

2019_CVPR Adapting Object Detectors via Selective Cross-Domain Alignment


通常在公共数据集上训练最先进的物体检测器。当将它们应用于不同的域时,它们通常会面临很大的困难,由于成像条件会显著不同,并且相应的注释数据不可用(或获取成本很高)。一种自然的补救方法是通过在两个域上对齐图像表示来适应模型。例如,这可以通过对抗学习来实现,并且已经证明在诸如图像分类的任务中是有效的。但是,我们发现在目标检测中,以这种方式获得的改进非常有限。一个重要的原因是, 传统的域自适应方法会努力将图像整体对齐,而目标检测本质上会关注可能包含感兴趣对象的局部区域。 受此启发,我们提出了一种用于目标检测的域自适应新方法,以处理“在哪里看”和“如何对齐”中的问题。我们的关键思想是挖掘区分区域,即与目标检测直接相关的区域,并专注于在两个域之间对齐它们。实验表明,在保持良好的可扩展性的前提下,该方法在各种域迁移情况下的性能明显优于现有方法,并提高了约4%~6%。
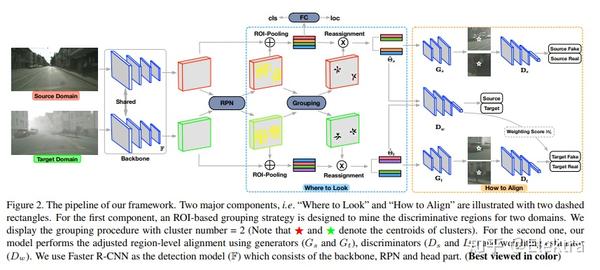

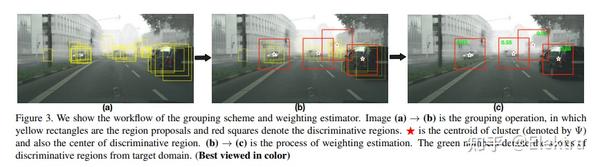

相关代码:无 (基于Faster RCNN框架)
20190902 ICCV 2019(oral) Self-Training and Adversarial Background Regularization for Unsupervised Domain Adaptive One-Stage Object Detection


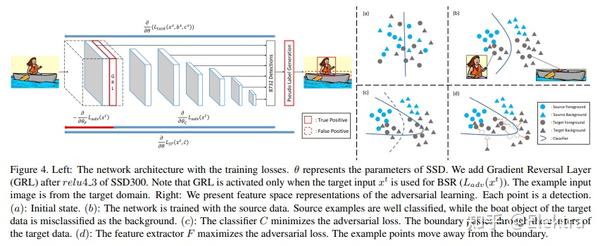
摘要: 基于深度学习的目标检测器已经显示出显着的改进。但是,当训练数据和测试数据具有不同的分布时,基于监督学习的方法表现不佳。为了解决这个问题,域适应将知识从标签足够的域(源域)转移到标签稀缺域(目标域)。 自我训练(Self-training) 是实现领域适应的强大方法之一,因为它有助于class-wise领域适应。不幸的是,利用伪标签作为GT的方法会由于不正确的伪标签而使性能下降。本文介绍了一种weak self-training(WST)方法和对抗性背景评分正则化(BSR),用于域自适应一阶段目标检测。WST减少了不准确伪标签的不利影响,以稳定学习过程。BSR 帮助网络提取目标背景的判别特征,以减少域偏移。两个组成部分是相辅相成的,因为BSR增强了前景和背景之间的可鉴别性,而WST则加强了基于类别的可鉴别性。实验结果表明,该方法有效提高了无监督域自适应设置下单阶段目标检测的性能。
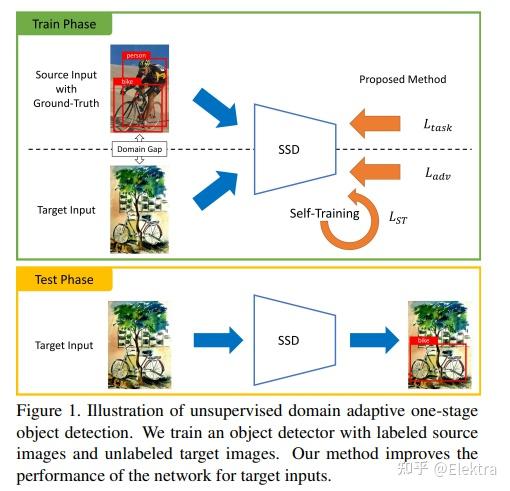

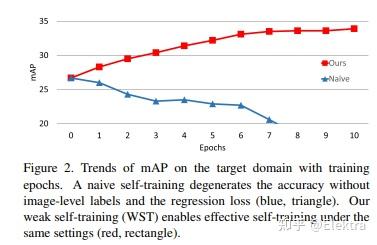
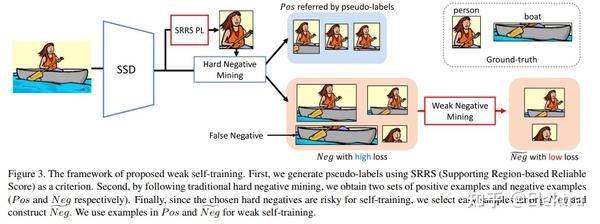


20191024 WACV 2020 Progressive Domain Adaptation for Object Detection


摘要:最近用于目标检测的深度学习方法依赖于大量的边界框注释。收集这些注释既费力又昂贵,但是在测试来自不同分布的图像时,监督模型不能很好地泛化。Domain Adaptation通过使现有标签适应目标测试数据来提供解决方案。然而,域之间的巨大差距可能会使适应成为一项具有挑战性的任务,从而导致不稳定的训练过程和次优结果。在本文中,我们提出用 中间域 弥合 域gap,并逐步解决更容易适应的子任务(bridge the domain gap with an intermediate domain and progressively solve easier adaptation subtasks)。此中间域是通过转换源图像以模拟目标域中的图像来构造的。为了解决域转移问题,我们采用对抗性学习来协调特征级别的分布。此外,还应用加权任务损失来处理中间域中不平衡的图像质量。实验结果表明,在目标域的性能方面,我们的方法优于最先进的方法。
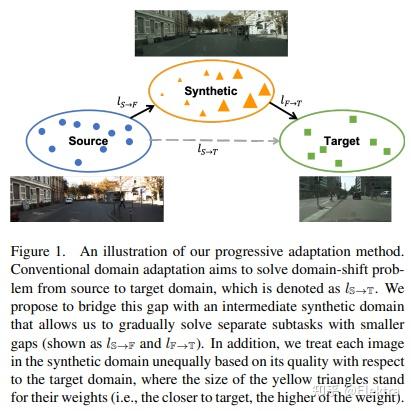
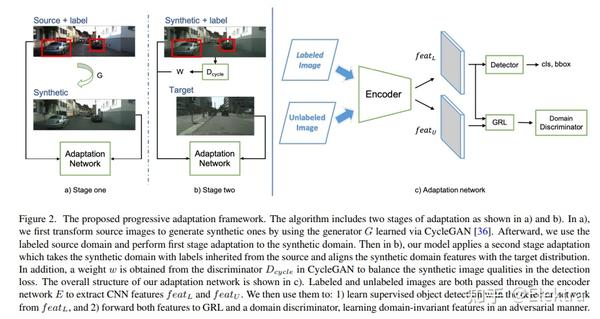
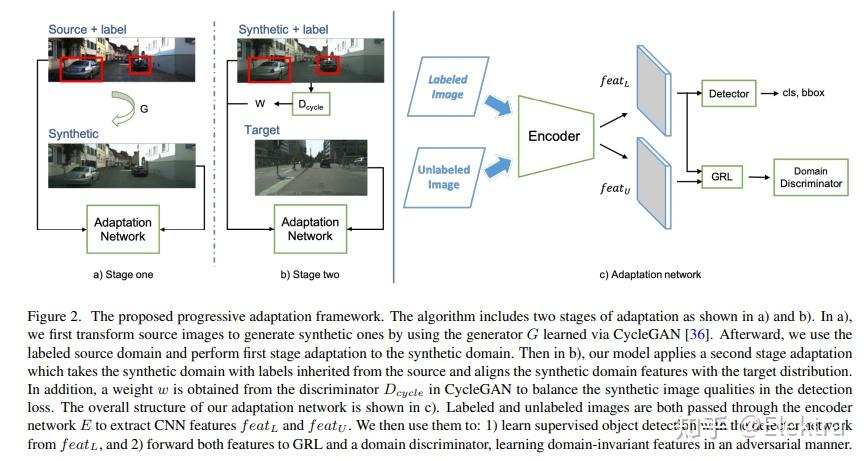


备注:引入一个中间域,从Source-->>Synthetic-->>Target渐进地适应域差异
相关代码: kevinhkhsu/DA_detection: Progressive Domain Adaptation for Object Detection (github.com)
20190514 CVPR 2019 Diversify and Match: A Domain Adaptive Representation Learning Paradigm for Object Detection


摘要: 我们介绍了一种用于目标检测的新型无监督域自适应方法。我们旨在同时缓解像素级适应的不完全平移问题,以及特征级适应的源偏置判别性问题。我们的方法由两个阶段组成,即域多样化(Domain Diversification,DD)和多域不变表示学习(Multi domain-invariant Representation Learning,MRL)。在DD阶段,我们通过从源域生成各种独特的移位域来使标记数据的分布多样化。在MRL阶段,我们将对抗性学习与多域鉴别器相结合,以使得特征在域之间无法区分。DD 解决了源域偏移的判别性,而 MRL 则缓解了图像转换的不完美。我们为我们的学习范式构建了一个结构化的领域适应框架,并引入了一种实用的DD实施方式。我们的方法在各种数据集的平均精度(mAP)方面比最先进的方法高出3%~11%。


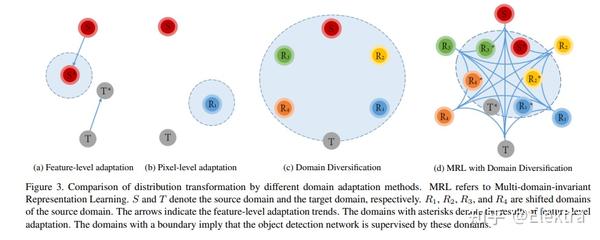
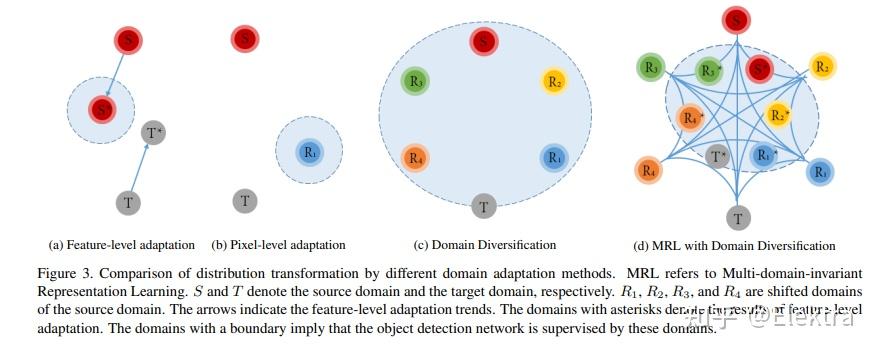



134Citations
20190907 ICCV 2019 Multi-adversarial Faster-RCNN for Unrestricted Object Detection


摘要: 传统的目标检测方法基本上假设训练和测试数据是从受限的目标域收集的,具有昂贵的标注成本。为了缓解域依赖性和繁琐的标注问题,本文建议利用从具有足够标签的辅助源域训练的域知识来检测不受限制环境中的对象。具体而言,我们提出了一个用于不受限制的目标检测的多对抗性Faster-RCNN(multi-adversarial,MAF)框架,该框架本质上解决了特征表示中域适应的域差异最小化问题。本文优点有三个方面:1)当图像分布导致域差异出现时,目标检测器经常变得域不兼容,我们提出了一个 分层域特征对齐模块 ,其中设计了用于逐层域特征混淆的多个对抗域分类器子模块;2)提出一种用于分层特征图调整大小的信息不变尺度缩减模块(SRM),以提高对抗域自适应的训练效率;3) 为了提高域适应性,将聚合的建议特征和检测结果输入到所提出的加权梯度反转层(WGRL)中,用于表征硬混淆域样本。我们在不受限制的任务上评估我们的MAF,包括Cityscapes,KITTI,Sim10k等,实验达到SOTA。

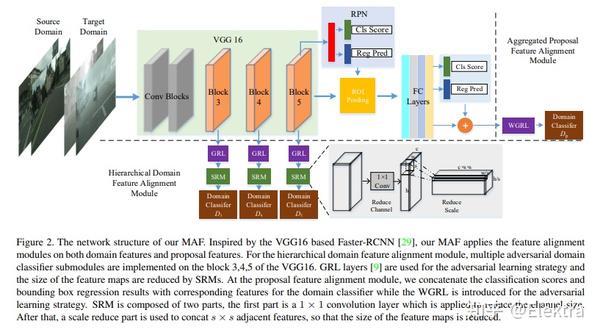

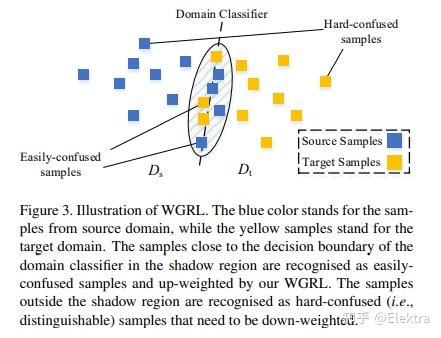

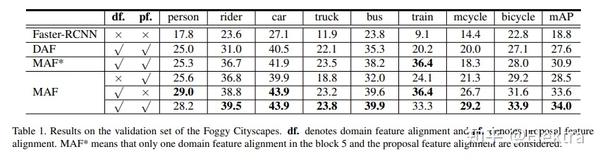

代码: He-Zhenwei/MAF: The implementation of the paper "Multi-adversarial Faster-RCNN for Unrestricted Object Detection" (github.com) Star13(基于caffe)
20190918 arxiv Wasserstein Distance Based Domain Adaptation for Object Detection


摘要: 在本文中,我们提出了一种用于目标检测的对抗性无监督域适应框架。先前的方法利用基于源域和目标域分布之间交叉熵的对抗训练来学习共享特征映射,从而最大限度地减少域间隙。在这里,我们最小化了两个分布之间的Wasserstein距离,而不是交叉熵或Jensen-Shannon散度,以提高目标检测任务固有的高维特征空间中域适应的稳定性。此外,我们删除了源域和目标域之间共享特征映射的确切一致性约束,以便可以独立优化目标特征映射,这在域差距显著的情况下是必要的。我们通过经验表明, 所提出的框架可以缓解不同场景下的域偏移, 并改善目标域对象检测性能。


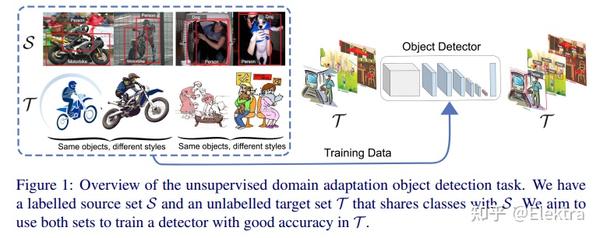
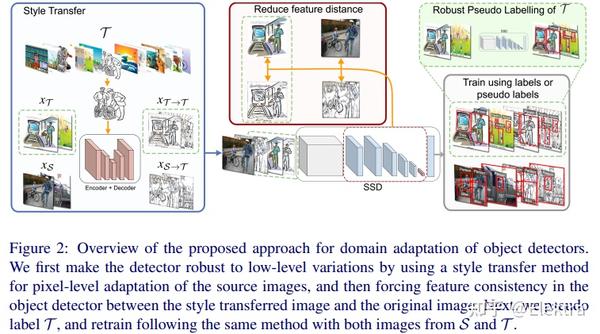
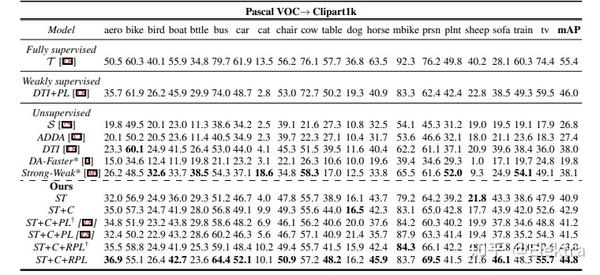
20191122 BMVC 2019 Domain Adaptation for Object Detection via Style Consistency


摘要:我们提出了一种用于目标检测的领域自适应方法。我们引入了一个两步的方法:
第一步使检测器对低级差异鲁棒,第二步使分类器适应高级特征的变化。对于第一步,我们使用样式迁移方法将源图像像素化到目标域。我们发现,在目标检测器的高级特征中,在样式迁移的图像和源图像之间强制执行低距离可以提高目标域的性能。对于第二步,我们提出了一种鲁棒的伪标签方法,以减少正采样和负采样中的噪声。使用检测器SSD300在PASCAL VOC及扩展数据集上的进行实验评估,其中目标域图像具有不同的样式。我们的方法显著提高了该基准测试中最先进的性能。



代码: pb2377/Pytorch-Domain-Adaptation-via-Style-Consistency (github.com) Star2
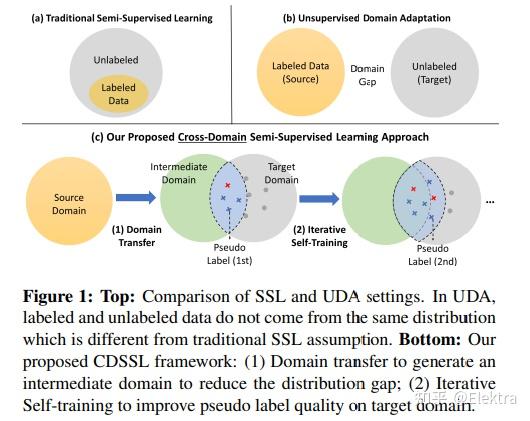
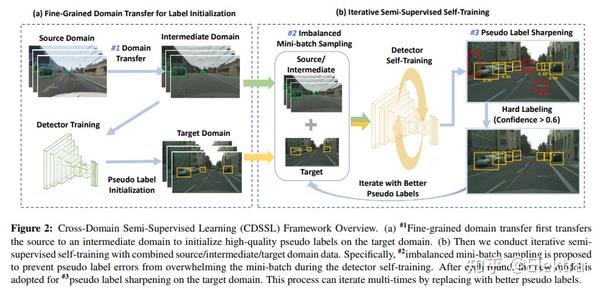
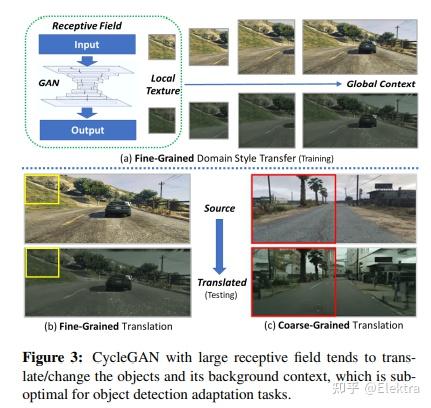
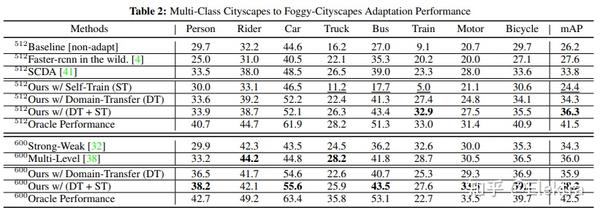
20191124 WACV'2022 Unsupervised Domain Adaptation for Object Detection via Cross-Domain Semi-Supervised Learning


摘要: 当前SOTA的目标检测器在野外部署时,由于与训练数据存在域差距,性能可能会显著下降。无监督域适应 (UDA) 是一种很有前途的方法,可以在没有任何昂贵的标签成本的情况下使模型适应新的域/环境。但是,如果没有GT标签,大多数先前用于目标检测任务的UDA工作只能通过使用对抗性学习方法执行粗略的图像级和/或特征级适应。在这项工作中,我们表明,这种基于对抗的方法只能缩小domain style gap,但不能解决对目标检测器很重要的domain content distribution gap。为了克服这一限制,我们提出了跨域半监督学习(CDSSL)框架,利用高质量的伪标签直接从目标域学习更好的表示。为了使半监督学习能够进行跨域对象检测,我们提出了细粒度域转移,基于渐进置信度的标签锐化和不平衡采样策略,以解决两个挑战:(i)源域和目标域数据之间的不相同分布,(ii)由于目标域上的噪声伪标签而导致的错误放大/累积。实验结果表明,在各种域适应场景下,我们提出的方法始终如一地实现了最先进的新性能(比先前在mAP上的最佳工作好2.2%-9.5%)。




20191129 arxiv_ECCV2020 Prior-based Domain Adaptive Object Detection for Adverse Weather Conditions


摘要: 雾霾和雨水等不利天气条件会破坏捕获图像的质量,从而导致在干净图像上训练的检测网络在这些图像上表现不佳。为了解决这个问题,我们提出了一个 基于先验的无监督域对抗目标检测框架 ,以使探测器适应朦胧和下雨的条件。特别是,我们使用使用图像形成原理获得的特定于天气的先验知识来定义新的先验对抗性损失。用于训练适应过程的先验对抗性损失旨在减少特征中特定于天气的信息,从而减轻天气对探测性能的影响。此外,我们还在目标检测管道中引入了一组残留特征恢复块,以消除特征空间的失真,从而进一步改进。对各种数据集(Foggy-Cityscapes, Rainy-Cityscapes, RTTS and UFDD)的雨霾条件进行了评估,证明了所提出方法的有效性。


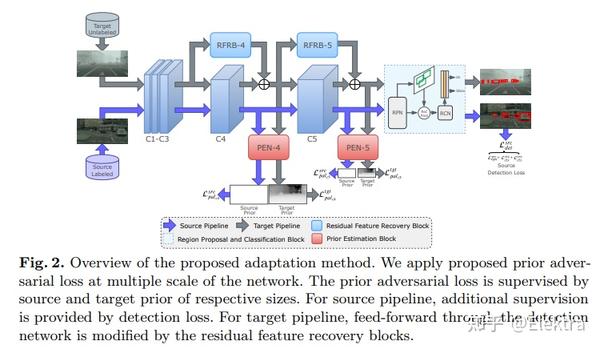

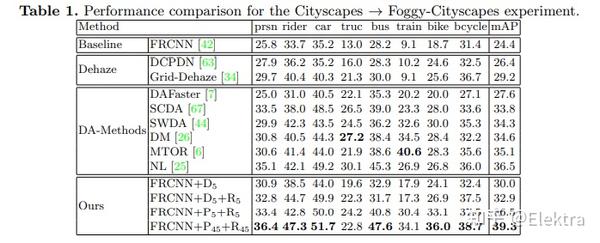

备注:使用了先验知识
20191215 arxiv Curriculum Self-Paced Learning for Cross-Domain Object Detection
Accepted for publication in Computer Vision and Image Understanding


摘要:训练(源)域偏差在应用于新(目标)域时会影响最先进的目标检测器性能,例如 Faster R-CNN。为了缓解这个问题,研究人员提出了各种域自适应方法来改善跨域设置中的目标检测结果,例如,通过使用Cycle-GAN将带有GT标签的图像从源域转换为目标域。除了以智能和高效的方式将Cycle-GAN转换和self-paced learning相结合之外,本文还提出了一种新颖的self-paced算法,该算法可以从简单到困难地学习。我们的方法简单有效,在推理过程中没有任何开销。它仅对从目标域中获取的样本使用伪标签,即域适应是无监督的。我们在四个跨域基准上进行实验,显示出比现有技术更好的结果。我们还进行了一项消融研究,展示了我们框架中每个组件的实用性。此外,我们还研究了我们的框架对其他对象检测器的适用性。此外,我们将我们的难度度量与相关文献中的其他度量进行比较,证明它产生了更好的结果,并且与性能指标密切相关。
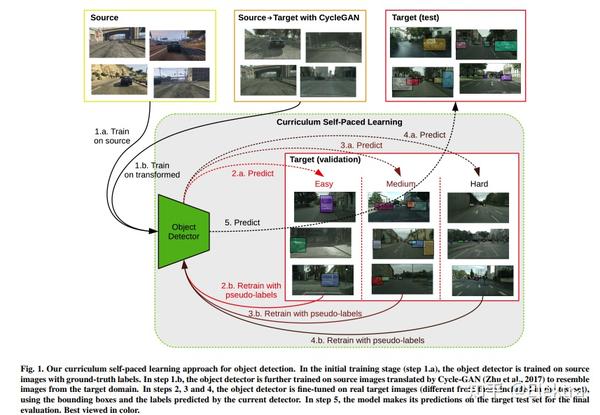



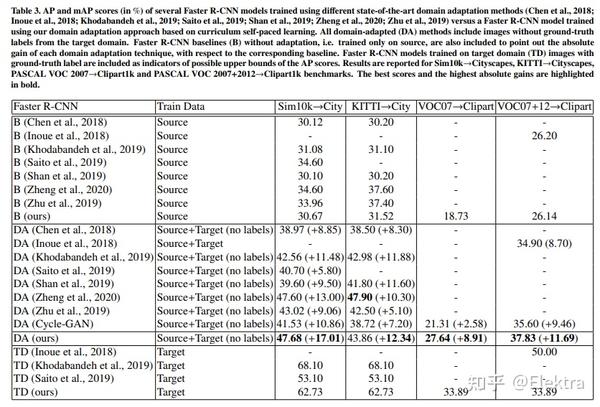

2019ICCVW Multi-Level Domain Adaptive Learning for Cross-Domain Detection


摘要: 近年来,有监督深度学习在目标检测上取得了激动人心的效果,但是在跨域上仍然面临挑战。光照、风格、尺度和外观等不同域的变化会影响检测模型的效果。先前的工作使用对抗训练来对齐全局特征来跨越域漂移,从而达到图像信息的迁移。但是,这些方法由于不能有效地匹配局部特征的分布而让跨域目标检测的效果受到限制。为了解决这个问题,我们提出了一个多级域适应的网络同时对齐local-level特征和global-level特征。我们在多个实验设置上进行评估,包括极端天气适应、虚拟数据适应和跨境头适应。在大多数目标类别上,取得了SOTA。
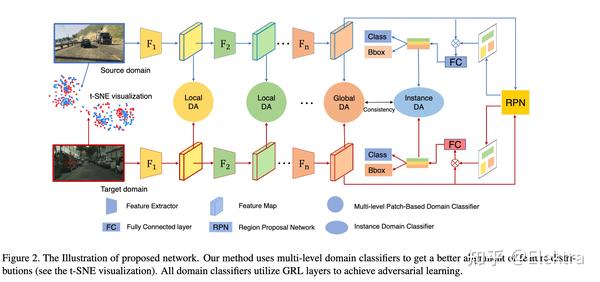



2019CVPR Few-Shot Adaptive Faster R-CNN


摘要:为了减轻由域偏移引起的检测性能下降,我们的目标是开发一种新颖的少样本自适应方法,该方法只需要几个具有有限边界框注释的目标域图像。为此,我们首先观察到几个重大挑战。首先,目标域数据高度不足,使得现有的大多数域自适应方法无效。其次,目标检测涉及同时定位和分类,使模型适应过程进一步复杂化。第三,该模型存在过度适应(类似于使用少量数据示例进行训练时的过度拟合)和可能导致目标域检测性能下降的不稳定风险。为了应对这些挑战,我们首先在源和目标特征上引入配对机制,以缓解目标域样本不足的问题。然后,我们提出了一个双层模块,以使源训练的检测器适应目标域:1)基于拆分池的图像级适应模块均匀地提取和对齐位置上的成对局部补丁特征,具有不同的比例和纵横比;2) 实例级适配模块在语义上对齐配对对象特征,同时避免类间混淆。同时,应用源模型特征正则化(SMFR)来稳定两个模块的适应过程。结合这些贡献,给出了一种新颖的少样本自适应 Faster-RCNN 框架,称为 FAFRCNN,它有效地适应具有少量标记样本的目标域。


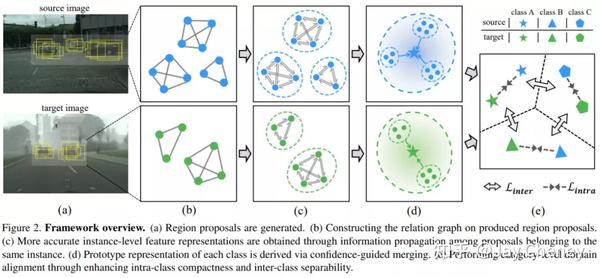
20200328 CVPR 2020 Cross-domain Detection via Graph-induced Prototype Alignment
摘要:
将在特定领域上训练的目标检测器的知识直接应用到新领域是有风险的,因为两个领域之间的差异可能会严重降低模型的性能。此外,由于目标检测场景中不同的实例通常包含不同的模态信息,因此很难实现源域和目标域的特征对齐。为了缓解这些问题,我们提出了一种图诱导原型对齐(GPA)框架,通过精细的原型表示来寻求类别级别的领域对齐。简而言之,通过基于图的region proposals之间的信息传播获得更精确的实例级特征,并在此基础上推导出用于类别级领域比对的每类的原型表示。此外,为了缓解类别不平衡对领域适应的负面影响,我们设计了一个类别加权对比损失来调整适应训练过程。结合Faster R-CNN,该框架分两步进行特征对齐。在各种跨域检测任务上的综合结果表明,该方法的性能明显优于现有方法。

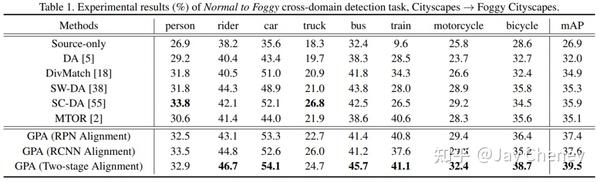

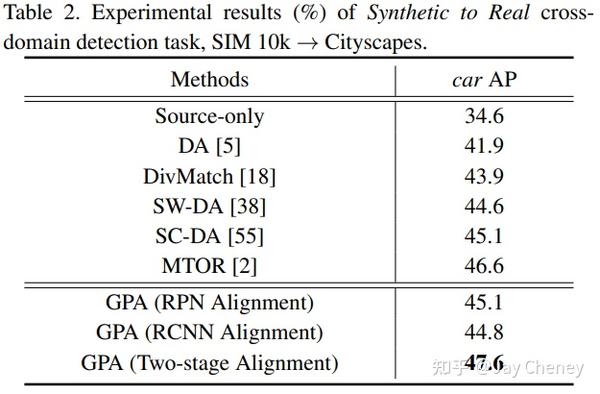

代码: https:// github.com/ChrisAllenMi ng/GPA-detection Star117
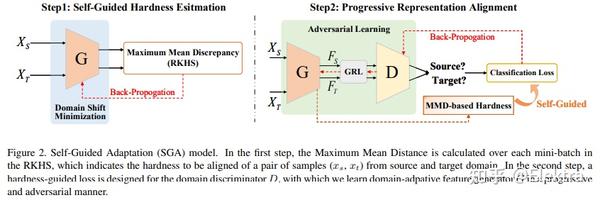
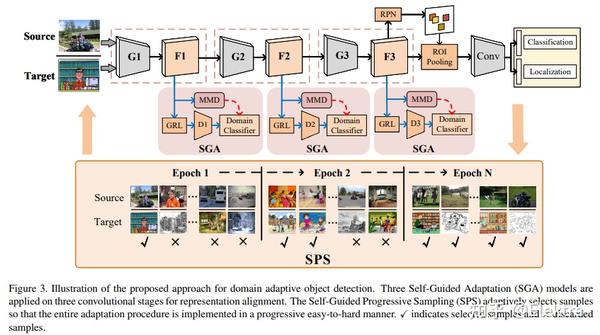
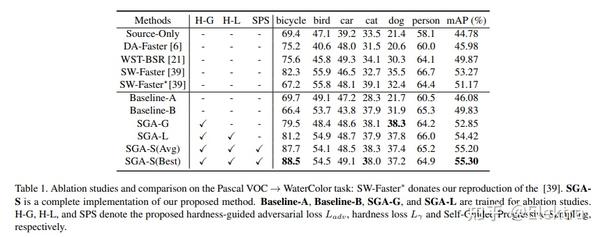
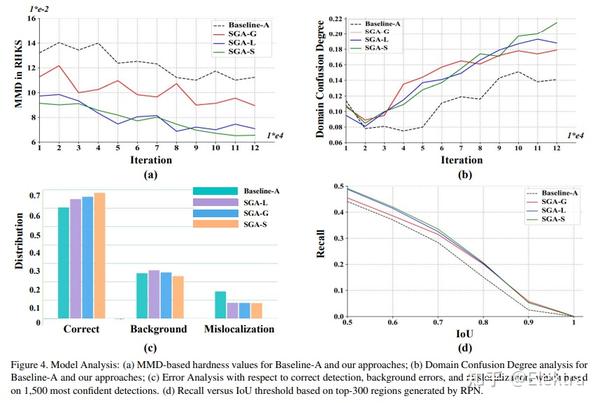
20200322 arxiv Self-Guided Adaptation: Progressive Representation Alignment for Domain Adaptive Object Detection


摘要 :无监督域自适应(UDA)在提高目标检测模型的跨域鲁棒性方面取得了前所未有的成功。然而,现有的UDA方法在很大程度上忽略了模型学习过程中的瞬时数据分布(instantaneous data distribution),这可能会在域转换较大的情况下恶化特征表示。在这项工作中,我们提出了一个自导自适应(a Self-Guided Adaptation,SGA)模型,在考虑瞬时对齐难度的同时,在域之间对齐特征表示和跨域适应目标检测模型。SGA 的核心是计算指示核空间中域距离的样本对的"硬度"因子。利用硬度因子,所提出的SGA自适应地指示了样品的重要性,并赋予它们不同的约束。由硬度因素表示,自导渐进式采样(SPS)在模型适应过程中以"易于硬"的方式实现。使用多阶段卷积特征,SGA 进一步聚合以完全对齐检测模型的分层表示。对常用基准的广泛实验表明,SGA改进了最先进的方法,具有显着的余量,同时证明了对大域转移的有效性。




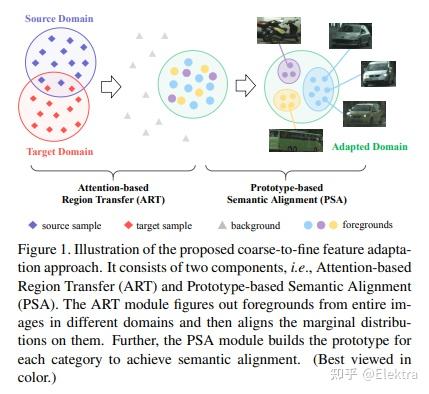
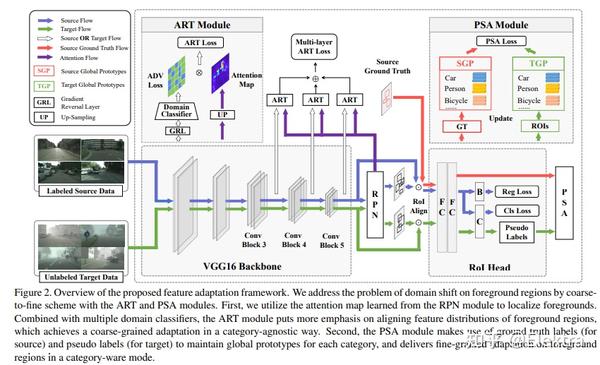
20200320 CVPR 2020 Cross-domain Object Detection through Coarse-to-Fine Feature Adaptation


摘要: 近年来,基于深度学习的目标检测取得了巨大进步。但是,由于域偏移问题,将现成的检测器应用于未知的域会导致性能显著下降。针对这一问题,提出一种新颖的coarse-to-fine特征自适应跨域目标检测方法。在粗粒度阶段,与文献中粗略的图像级或实例级特征对齐不同,采用注意机制提取前景区域,并通过共同特征空间中的多层对抗学习,根据其边际分布进行对齐。在细粒度阶段,我们通过最小化具有相同类别但来自不同域的全局原型的距离来执行前景的条件分布对齐。由于这种从粗到细的特征适应性,前景区域的领域知识可以有效地转移。在各种跨域检测场景中进行了广泛的实验。结果是最先进的,证明了所提出的方法的广泛适用性和有效性。
具体方法
- 注意力模块:在 Multi-adversarial Faster-RCNN for Unrestricted Object Detection 的基础上添加了注意力图(Attention Map)
- 基于原型网络的语义匹配:引入原型网络来匹配不同域的相同类别目标物


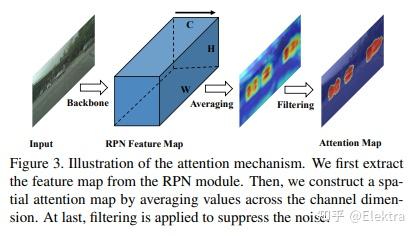

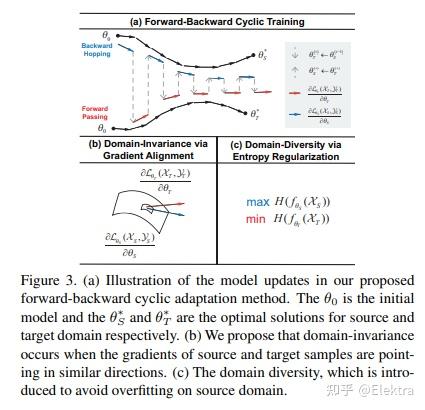
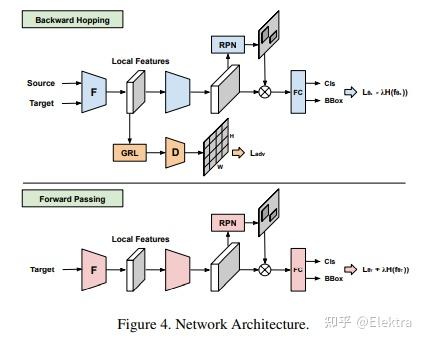
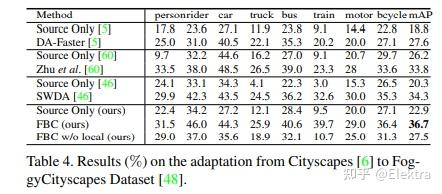
20200203 arxiv(ACCV2020) Unsupervised Domain Adaptive Object Detection using Forward-Backward Cyclic Adaptation
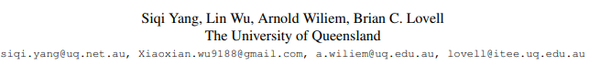

摘要: 我们提出了一种通过前向后循环(FBC)训练执行对象检测的无监督域适应的新方法。最近基于对抗训练的域适应方法已经显示出它们通过边缘特征分布对齐来最小化域差异的有效性。但是,对齐边际特征分布并不能保证类条件分布的对齐。在调整对象检测器时,这种限制更为明显,因为与图像分类任务相比,域差异更大,例如,一个图像中存在不同数量的对象,并且图像中的大部分内容是背景。这促使我们通过梯度对齐来学习类别级语义的域不变性。直观地说,如果两个域的梯度指向相似的方向,那么一个域的学习可以改善另一个域的学习。为了实现梯度对齐,我们提出了向前 - 向后循环适应,它通过向后跳跃迭代计算从源到目标的适应性,并通过向前传递从目标到源。此外,我们还调整了低级功能,以便通过对抗性训练来适应整体颜色/纹理。但是,检测器在这两个域上都表现良好,对于目标域而言并不理想。因此,在每个周期中,域多样性通过源域上的最大熵正则化来强制执行,以惩罚自信的源特定学习和目标域上的最小熵正则化,以吸引特定于目标的学习。对训练过程进行了理论分析,并对具有挑战性的跨域对象检测数据集进行了广泛的实验,表明我们的方法优于最先进的方法。




- 2020cvpr Exploring Categorical Regularization for Domain Adaptive Object Detection


论文链接: https:// arxiv.org/abs/2003.0915 2
旷视研究院基于领域自适应 Faster R-CNN 系列模型提出了一个类别正则化框架,以提升自适应检测的性能。研究人员研究了多标签分类 CNN 的弱局部定位能力,和图像级与物体级预测之间的类别一致性,发现对与物体相关的局部区域进行对齐以及对困难物体的对齐能够很好提升模型整体的效果。
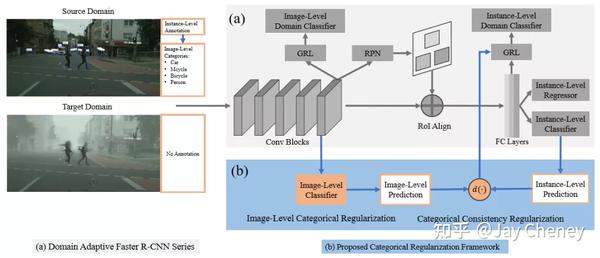

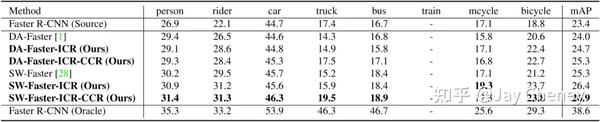

https:// mp.weixin.qq.com/s/sbMv C0ydokOWMtqJhrysXw CVPR 2020 | 旷视提出优化领域自适应目标检测性能的类别正则化框架
论文代码: https:// github.com/Megvii-Nanji ng/CR-DA-DET star82
81 Citations
20200329 ECCV 2020 Spatial Attention Pyramid Network for Unsupervised Domain Adaptation


摘要:无监督域自适应在各种计算机视觉任务中至关重要,例如目标检测、实例分割和语义分割,旨在缓解域偏移导致的性能下降。以前的大多数方法都依赖于源域和目标域的单模分布,以使其与对抗性学习保持一致,从而导致在各种情况下的结果较差。为此,本文设计了一种新的无监督域适应空间注意力金字塔网络。具体来说,我们首先构建空间金字塔表示,以捕获不同尺度上对象的上下文信息。在任务特定信息的指导下,利用空间注意力机制,有效地将每个空间位置的密集全局结构表示和局部纹理模式相结合。通过这种方式,网络被强制关注具有上下文信息的区分区域,以便进行域适应。我们在各种具有挑战性的数据集上进行了广泛的实验,以便在目标检测,实例分割和语义分割方面进行无监督域适应,这表明我们的方法与最先进的方法相比具有很大的优势。
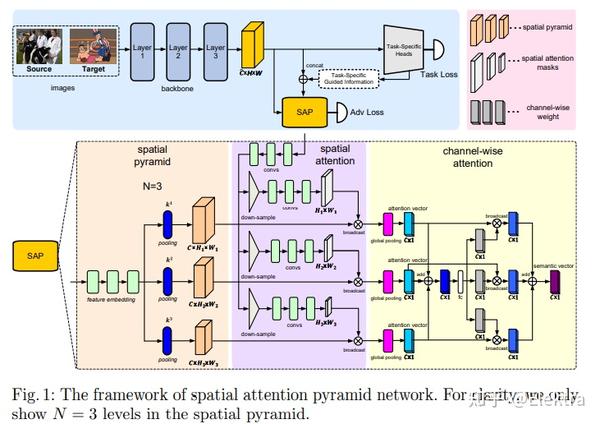

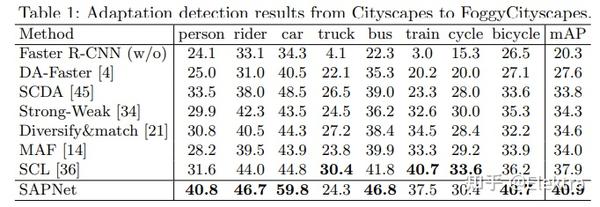

代码: IntelligentTEAM / ECCV 2020 Domain Adaption · GitLab (iscas.ac.cn)
20200329 arxiv(ECCV2020) Adaptive Object Detection with Dual Multi-Label Prediction


摘要:本文提出一种利用多标签目标识别作为双重辅助任务的自适应目标检测端到端无监督深度域自适应模型。该模型利用 多标签预测 来揭示每个图像中的目标类别信息,然后使用预测结果执行 条件对抗全局特征对齐 ,从而可以处理图像特征的多模态结构,以弥合全局特征级别的域分歧,同时保持特征的可判别性。此外,我们引入了一种预测一致性正则化机制来辅助目标检测,该机制使用多标签预测结果作为辅助正则化信息,以确保目标识别任务和目标检测任务之间的对象类别发现一致。在几个基准数据集上进行了实验,结果表明,所提出的模型优于最先进的比较方法。
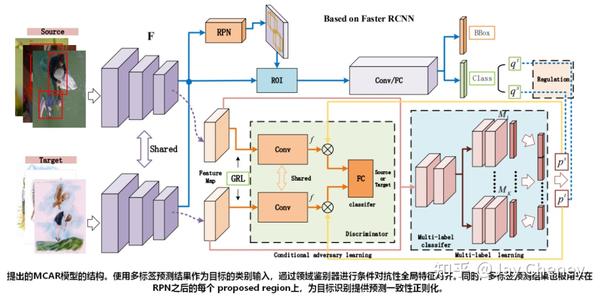

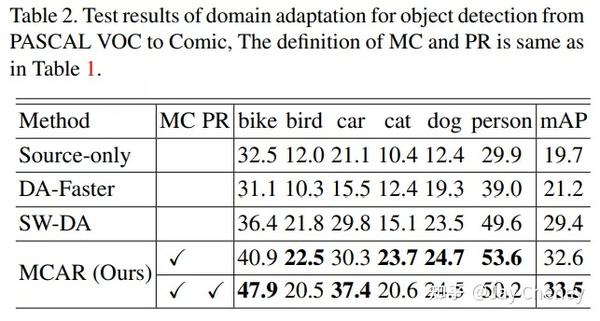


备注: 结合目标识别多标签分类信息 的无监督深度域自适应目标检测模型,性能达到了SOTA, PASCAL VOC → Comic mAP 33.5。
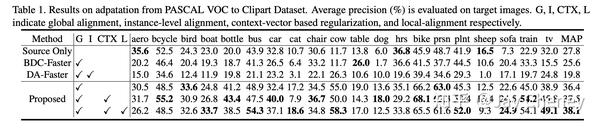
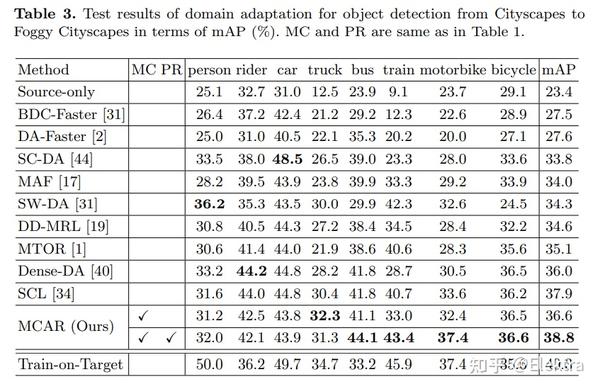
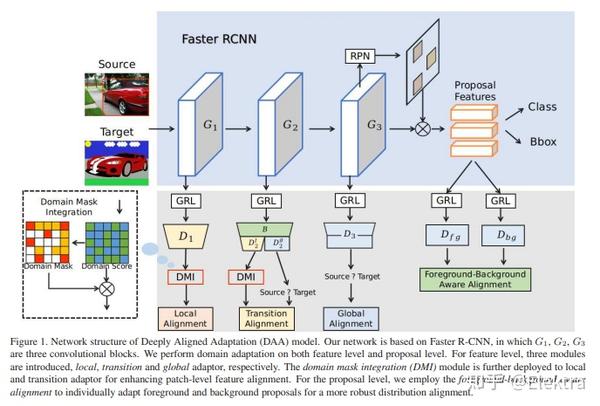
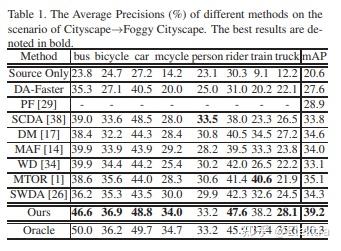
20200409 arxiv Deeply Aligned Adaptation for Cross-domain Object Detection

摘要:跨域目标检测最近吸引了越来越多的关注,因为它有助于构建能够很好地适应新环境的强大检测器。在这篇论文中,我们提出了一种基于Faster R-CNN的端到端解决方案,其中GT注释可用于源图像(例如,cartoon),但在训练期间不适用于目标域图像(例如,watercolor)。基于对不同神经网络层的可转移性差异的观察,我们提出将许多域对齐策略应用于Faster R-CNN的不同层,其中对齐强度从低层逐渐降低到较高层。此外,在我们的网络中获得region proposals后,我们开发了一个前景背景感知对齐模块,通过分别对齐源域和目标域中的前景和背景区域的特征来进一步减少域不匹配。对基准数据集的广泛实验证明了我们提出的方法的有效性。

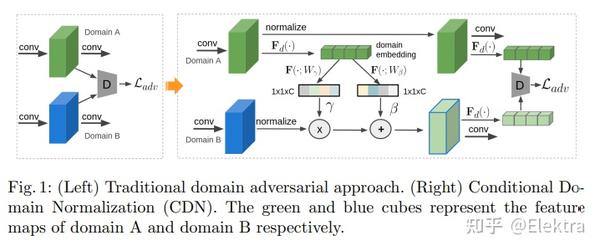
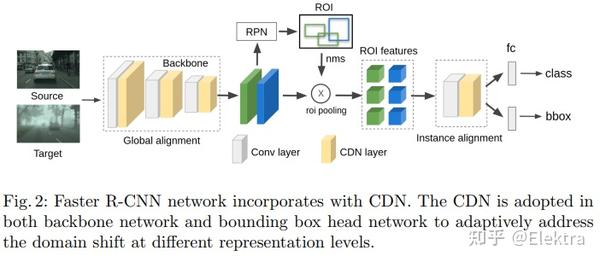
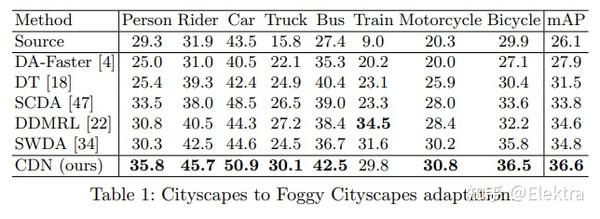
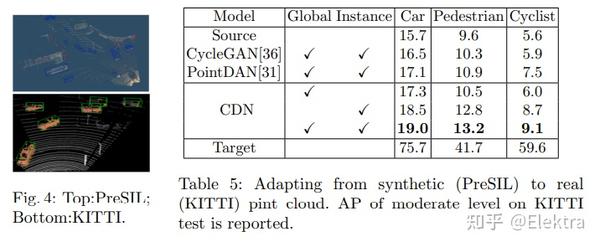
20200316 ECCV 2020 Adapting Object Detectors with Conditional Domain Normalization


摘要:现实世界的目标检测器经常受到不同数据集之间域差异的挑战。在这项工作中,我们提出了条件域规范化(Conditional Domain Normalization,CDN)来缩小域差距。CDN 旨在将不同的域输入编码到共享的潜在空间中,其中来自不同域的特征具有相同的域属性。为了实现这一点,我们首先通过域嵌入模块将域特定属性从一个域的语义特征中分离出来,该模块学习域向量来表征相应的域属性信息。然后,此域向量用于通过条件规范化对来自另一个域的特征进行编码,从而生成不同域的特征具有相同的域属性。我们将CDN整合到目标检测器的各个卷积阶段中,以适应不同级别表示的领域转移。与现有的适应工作相比,这些工作对语义特征进行域混淆学习以消除域特定因素;而CDN通过调节一个域的语义特征来调整不同的域分布,而该语义特征取决于另一个域的学习域向量。大量实验表明,CDN在real-to-real和synthetic-to-real的适应基准(包括2D图像检测和3D点云检测)上都明显优于现有方法。




2020cvpr_Harmonizing Transferability and Discriminability for Adapting Object Detectors


摘要:自适应目标检测的最新进展凭借对抗性特征自适应来减轻沿检测管线的分布偏移而获得了令人信服的结果。尽管对抗性适应可以显着增强特征表示的可传递性,但 对物体检测器的特征可分辨性的研究仍较少 。此外,鉴于对象的复杂组合和域之间差异化的场景布局,可传递性和可辨别性在对抗性适应中可能会出现矛盾。在本文中,我们提出了一种分层可传递性校准网络(HTCN),该网络可分层(局部区域/图像/实例)对特征表示的可传递性进行校准,以协调可传递性和可辨别性。提议的模型包括三个部分:(1)具有输入插值的重要性加权对抗训练(IWAT-I),通过对插值的图像级特征重新加权来增强全局可辨性;(2)上下文感知的实例级对齐(CILA)模块,它通过捕获实例级功能和全局上下文信息之间的基础互补效应来增强实例的可区分性,以实现实例级功能对齐;(3)局部特征蒙版,用于校准局部可传递性,以为随后的区别性模式对齐提供语义指导。实验结果表明,HTCN明显优于基准数据集上的最新方法。
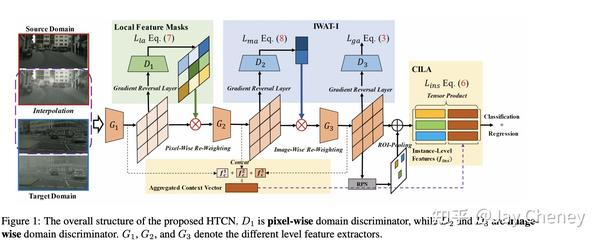

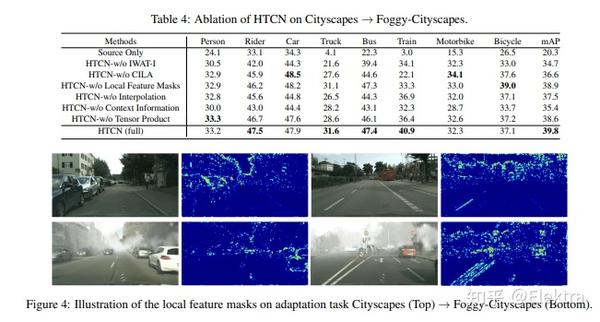

代码: https:// github.com/chaoqichen/H TCN star83 (基于 jwyang/faster-rcnn.pytorch at pytorch-1.0 (github.com) 框架)
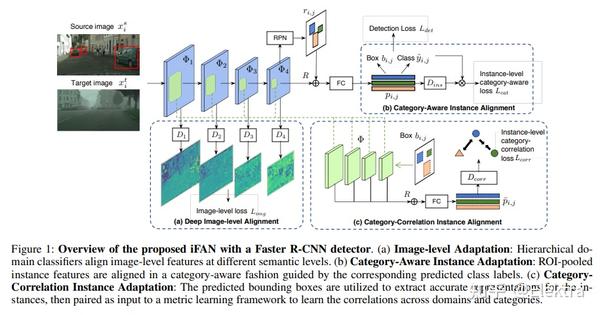
202003 AAAI iFAN: Image-Instance Full Alignment Networks for Adaptive Object Detection


摘要:在数据丰富的域训练一个目标检测器,并将其运用到一个数据有限的域并且性能下降不明显,这在业界极具吸引力,因为它节省了巨大的注释成本。最近对无监督域自适应目标检测的研究已经证实,通过对抗学习在源图像和目标图像之间对齐数据分布非常有用。关键是何时、何地以及如何使用它来实现最佳实践。我们提出图像-实例完全对齐网络(Image -Instance Full Alignment Networks,iFAN)通过精确对齐图像和实例级别上的特征分布来解决这个问题:1)图像级对齐:多尺度特征通过以分层嵌套的方式训练对抗性域分类器来大致对齐。2)完全实例级对齐:充分利用深度语义信息和精心设计的实例表示,在类别和域之间建立牢固的关系。通过仔细构造实例对,建立这些相关性被表述为指标学习问题。上述调整可以集成到目标检测器中(例如,Faster RCNN),从而形成一个端到端的可训练框架,其中多个对齐可以以粗略的方式协同工作。In two domain adaptation tasks: synthetic-to-real (SIM10K->Cityscapes) and normal-to-foggy weather (Cityscapes->Foggy Cityscapes), iFAN outperforms the state-of-the-art methods with a boost of 10%+ AP over the source-only baseline.

20200217_IEEE SSCI 2020_ Deep Domain Adaptive Object Detection: a Survey


Abstract: This paper aims to review the state-of-the-art progress on deep domain adaptive object detection approaches.
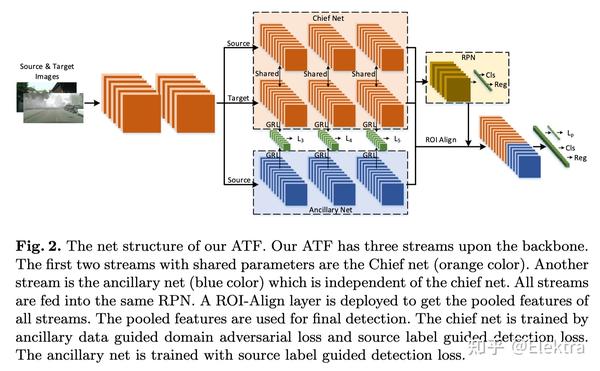
2020ECCV Domain Adaptive Object Detection via Asymmetric Tri-way Faster-RCNN (ATF)


摘要:由于存在域差异,传统的目标检测模型不可避免地会遇到性能下降。最近提出了无监督域自适应目标检测以减少域之间的差异,其中源域是标签丰富的,而目标域是标签不可知的。现有模型遵循参数共享孪生结构进行对抗域对齐,但容易导致源域崩溃和失控风险,给特征适配带来负面影响。主要原因是源和目标之间的标注不公平(不对称)使得参数共享机制无法适应。因此,为了避免参数共享导致的源域崩溃风险,我们提出了一种用于域自适应目标检测的非对称三路 Faster-RCNN (ATF)。我们的 ATF 模型有两个明显的优点:1)部署了一个由源标签监督的辅助网络来学习辅助目标特征并同时保留源域的区分,这增强了域对齐的结构区分(对象分类与边界框回归) ;2)由主网和独立辅助网组成的非对称结构从根本上克服了参数共享引起的源风险崩溃。保证了所提出的 ATF 检测器的自适应安全性。在包括 Cityscapes、Foggy-cityscapes、KITTI、Sim10k、Pascal VOC、Clipart 和水彩在内的多个数据集上进行的大量实验证明了我们方法的 SOTA 性能。

2020ECCV Every Pixel Matters: Center-aware Feature Alignment for Domain Adaptive Object Detector


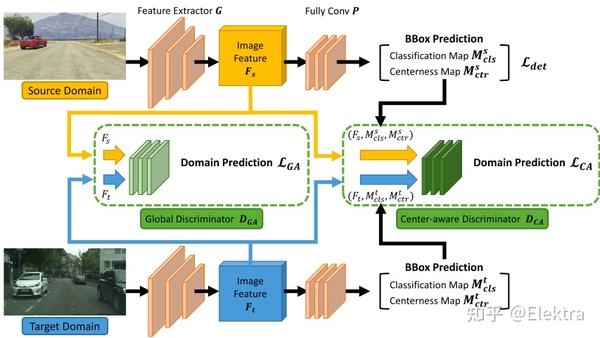
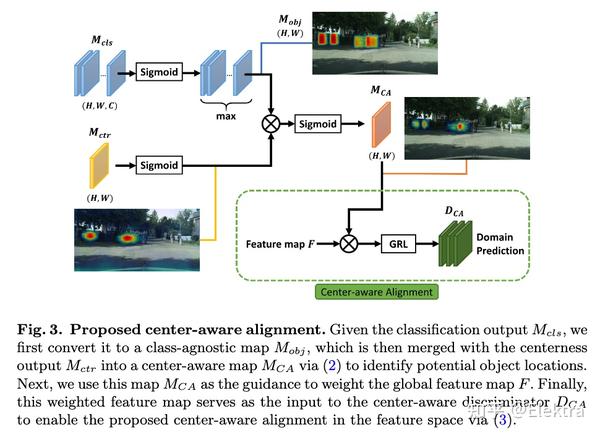
摘要: 域自适应目标检测器旨在使自己适应可能包含对象外观、视点或背景变化的看不见的域。大多数现有方法在图像级别或实例级别采用特征对齐。然而,全局特征上的图像级对齐可能会同时混淆前景/背景像素,而使用proposal的实例级对齐可能会受到背景噪声的影响。与现有解决方案不同,我们提出了一个域适应框架,通过预测像素对象性和中心性来解释每个像素。具体来说,所提出的方法通过更多地关注前景像素来执行中心感知对齐,从而实现更好的跨域自适应。
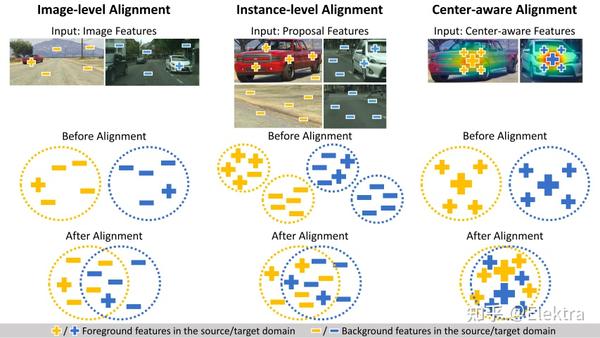



2020ECCV Collaborative Training between Region Proposal Localization and Classification for Domain Adaptive Object Detection


摘要: 目标检测器通常使用大量标记数据进行训练,这是昂贵且耗费劳力的。应用于未标记数据集的预训练检测器总是受到数据集分布差异的影响,也称为域偏移。目标检测的域自适应尝试将检测器从标记数据集调整为未标记数据集,以获得更好的性能。在本文中,我们首次揭示了两阶段检测器(例如,Faster RCNN)中的区域提议网络(RPN)和区域提议分类器(RPC)在面对大的域差距时表现出显着不同的可迁移性。区域分类器表现出更好的性能,但如果没有 RPN 的高质量建议,则会受到限制,而骨干网络中的简单对齐对于 RPN 适应来说不够有效。我们深入研究了 RPN 和 RPC 的一致性和差异,分别对待它们,并利用其中一个的高置信度输出作为相互指导来训练另一个。此外,低置信度的样本用于RPN和RPC之间的差异计算以及极小极大优化。各种场景的广泛实验结果证明了我们提出的方法在域自适应区域提议生成和目标检测方面的有效性。
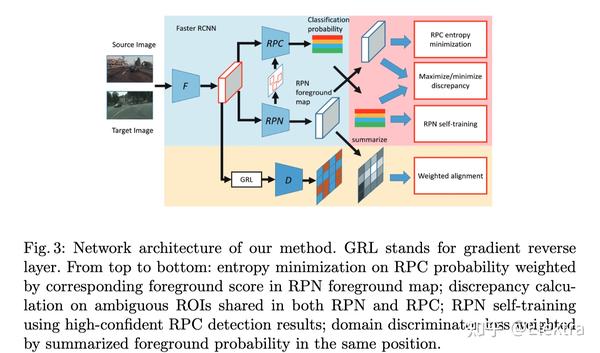


代码: https:// github.com/GanlongZhao/ CST_DA_detection star19
ECCV 2020 Prior-based Domain Adaptive Object Detection for Hazy and Rainy Conditions


摘要:Hazy和Rainy等恶劣天气条件破坏了捕捉到的图像的质量,导致在清晰图像上训练的检测网络在这些图像上表现不佳。为了解决这个问题,我们提出了一个无监督的基于先验的域对抗目标检测框架,以使检测器适应hazy和rainy的条件。特别地,我们使用weather-specific的先验知识获得使用图像形成的原则来定义一个新的prior-adversarial损失。用于train adaptation的prior-adversarial损失旨在减少特征中与天气有关的信息,从而减轻天气对探测性能的影响。此外,我们在目标检测pipeline中引入了一组残差特征恢复块来de-distort特征空间,进一步改进性能。对不同数据集(Foggy-Cityscapes, RainyCityscapes, RTTS and UFDD)进行的多雨和雾天条件下的评估表明了该方法的有效性。


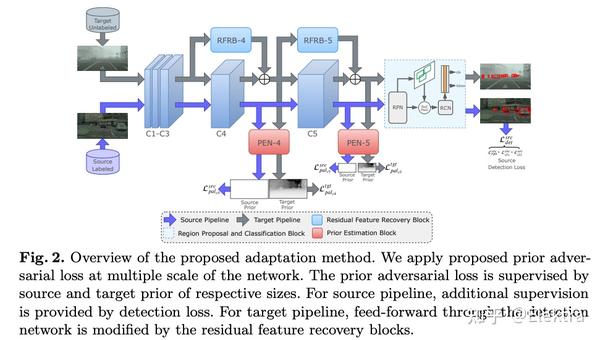

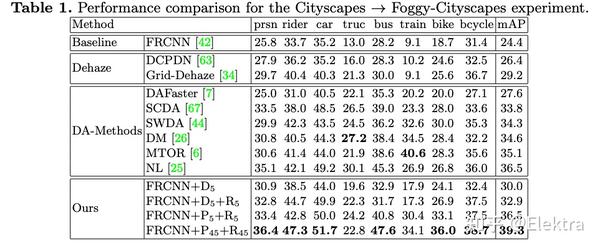

备注:这个在目标域上设计一个先验知识来重新设计这个域损失函数挺有意思的
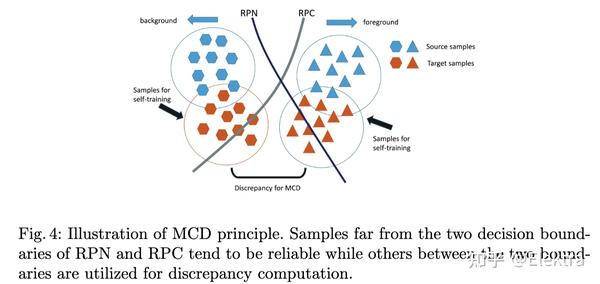
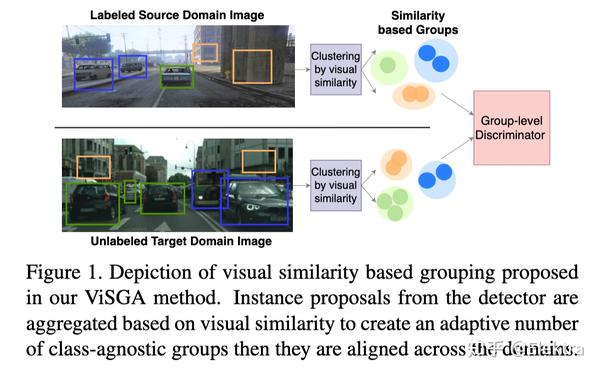
2021 ICCV Seeking Similarities over Differences: Similarity-based Domain Alignment for Adaptive Object Detection


摘要: 为了在广泛的场景中稳健地部署目标检测器,它们应该能够适应输入分布的变化,而无需不断注释新数据。这激发了对用于检测的无监督域适应 (UDA) 算法的研究。 UDA 方法通过诱导来自源域和目标域的检测器特征之间的对齐来学习从标记的源域适应未标记的目标域。 然而,在对齐哪些特征以及如何对齐方面还没有达成共识。在我们的工作中,我们提出了一个框架,该框架概括了 UDA 方法常用的不同组件,为深入分析 UDA 设计空间奠定了基础。具体来说,我们提出了一种新颖的 UDA 算法 ViSGA,它是我们框架的直接实现,它利用了最佳设计选择,并引入了一种简单但有效的方法,在通过对抗训练诱导组对齐之前,基于视觉相似性在实例级别聚合特征。我们表明,基于相似性的分组和对抗训练都允许我们的模型专注于粗略对齐的特征组,而不是被迫匹配松散对齐域中的所有实例。最后,我们检查了 ViSGA 对从不同来源收集标记数据的设置的适用性。实验表明,我们的方法不仅在 Sim2Real 和 Adverse Weather 上优于以前的单源方法,而且可以很好地推广到多源设置。无需被迫匹配松散对齐的域中的所有实例。最后,我们检查了 ViSGA 对从不同来源收集标记数据的设置的适用性。实验表明,我们的方法不仅在 Sim2Real 和 Adverse Weather 上优于以前的单源方法,而且可以很好地推广到多源设置。

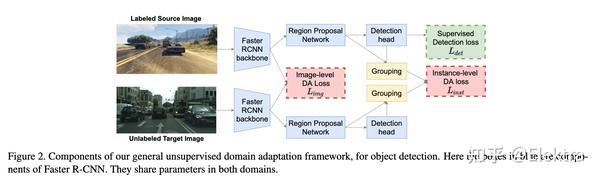

2022ArXiv Cross-Domain Object Detection with Mean-Teacher Transformer


摘要:最近,端到端目标检测管道 DEtection TRansformer (DETR) 取得了可喜的性能。但是,它需要大规模的标记数据并且会受到域偏移的影响,特别是当目标域中没有可用的标记数据时。为了解决这个问题,我们提出了一种基于mean teacher knowledge transfer(MTKT)的端到端跨域检测转换器,它通过伪标签在域之间传递知识。为了提高目标域中伪标签的质量,这是更好地适应域的关键因素,我们基于 Transformer 的架构设计了三个级别的源-目标特征对齐策略,包括基于域查询的特征对齐(DQFA )、基于双层图的原型对齐 (BGPA) 和令牌图像特征对齐 (TIFA)。这三个级别的特征对齐分别匹配源和目标之间的全局、局部和实例特征。通过这些策略,可以获得更准确的伪标签,并且可以更好地将知识从源转移到目标,从而提高检测转换器的跨域能力。大量实验表明,我们提出的方法在三个域适应场景中实现了最先进的性能,特别是 Sim10k 到 Cityscapes 场景的结果从 52.6 mAP 显着提高到 57.9 mAP。
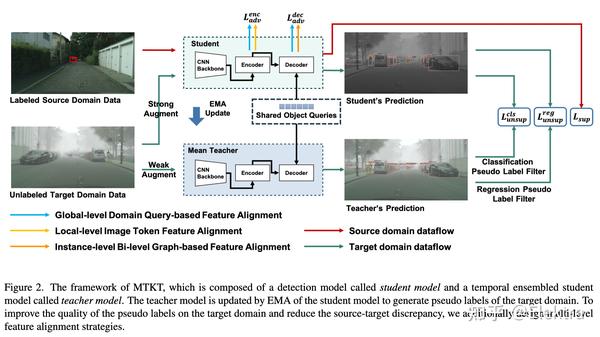

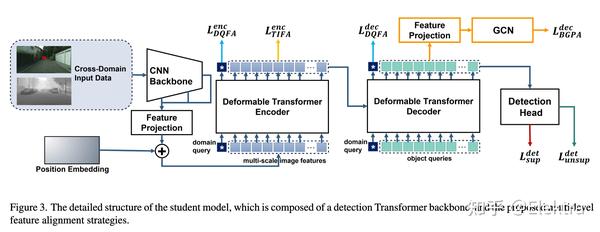

2022ArXiv Improving Transferability for Domain Adaptive Detection Transformers


摘要:DETR 风格的检测器在域内场景中脱颖而出,但它们在域转移设置中的属性尚未得到充分探索。本文旨在基于两个发现在域移位设置上使用 DETR 式检测器构建一个简单但有效的基线。一方面,减轻骨干网和解码器输出特征上的域偏移在获得有利结果方面表现出色。另一方面,两个部分中的高级域对齐方法进一步提高了性能。因此,我们提出了对象感知对齐(OAA)模块和基于优化传输的对齐(OTA)模块,以实现骨干和检测器输出的全面域对齐。OAA 模块对齐由主干输出中的伪标签标识的前景区域,从而产生基于域不变的特征。OTA 模块利用切片的 Wasserstein 距离来最大化位置信息的保留,同时最小化解码器输出中的域间隙。我们将发现和对齐模块实现到我们的适应方法中,并在域移位设置上对 DETR 式检测器进行基准测试。各种域自适应场景的实验验证了我们方法的有效性。