

PyTorch的CUDA错误:Error 804: forward compatibility was attempted on non supported HW


背景
最近在从源码编译PyTorch,使用的环境是NVIDIA官方的Docker镜像:
- nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04
- nvidia/cuda:11.1.1-cudnn8-devel-ubuntu20.04
宿主机为Ubuntu20.04 + RTX2080ti,Nvidia driver版本为450.102.04。
在这两个不同的Docker image起的容器上,编译后的PyTorch python库倒是能运行,但是一旦要使用CUDA功能的时候,就会报错:Error 804: forward compatibility was attempted on non supported HW。
python -c 'import torch; torch.randn([3,5]).cuda()'
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/opt/conda/envs/env_py3.8_cuda11.2_cudnn8.1.1_0_20210331/lib/python3.8/site-packages/torch/cuda/__init__.py", line 170, in _lazy_init
torch._C._cuda_init()
RuntimeError: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 804: forward compatibility was attempted on non supported HW联想到之前在nvidia/cuda:11.0.3-cudnn8-devel-ubuntu20.04上并没有这个错误,所以不言而喻的事实就是cuda镜像从版本11.0.3到11.1.1的过程中发生了什么变动。
备注: 在Linux宿主机上使用docker(版本>= 19.3)之前,请确保安装了nvidia-container-runtime和nvidia-container-toolkit:
gemfield@ai01:~$ sudo apt-get install nvidia-container-runtime nvidia-container-toolkit并且确保nvidia-container-runtime-hook在PATH环境变量的路径中:
gemfield@ai01:~$ which nvidia-container-runtime-hook
/usr/bin/nvidia-container-runtime-hookCUDA初探
既然是个cuda初始化就报错的问题,那Gemfield不妨先抛开PyTorch,在当前的Docker环境上直接写一个最简化的C程序来初始化CUDA设备,看看是否会出错。
代码:
#include <stdio.h>
#include <cuda_runtime.h>
int main() {
int device = 0;
int gpuDeviceCount = 0;
struct cudaDeviceProp properties;
cudaError_t cudaResultCode = cudaGetDeviceCount(&gpuDeviceCount);
if (cudaResultCode == cudaSuccess){
cudaGetDeviceProperties(&properties, device);
printf("%d GPU CUDA devices(s)(%d)\n", gpuDeviceCount, properties.major);
printf("\t Product Name: %s\n" , properties.name);
printf("\t TotalGlobalMem: %ld MB\n" , properties.totalGlobalMem/(1024^2));
printf("\t GPU Count: %d\n" , properties.multiProcessorCount);
printf("\t Kernels found: %d\n" , properties.concurrentKernels);
return 0;
printf("\t gemfield error: %d\n",cudaResultCode);
编译:
g++ -I/usr/local/cuda-11.2/targets/x86_64-linux/include/ gemfield.cpp -o gemfield -L/usr/local/cuda-11.2/targets/x86_64-linux/lib/ -lcudart运行:
root@gemfield:~# ./gemfield
gemfield error: 804可见,背景中提到的错误和PyTorch是没什么关系了,就是CUDA初始化的时候会报804的错误。那804错误码又是什么意思呢?在CUDA文档上,Gemfield找到了如下的描述:
cudaErrorCompatNotSupportedOnDevice =804:
This error indicates that the system was upgraded to run with forward compatibility but the visible hardware detected by CUDA does not support this configuration. Refer to the compatibility documentation for the supported hardware matrix or ensure that only supported hardware is visible during initialization via the CUDA_VISIBLE_DEVICES environment variable.
联想到背景中所看到的错误:“Error 804: forward compatibility was attempted on non supported HW”,这就对上了。这个错误的意思是说:你的硬件不支持forward compatibility。这又引入了两个问题:
- CUDA的forward compatibility是什么?
- 为什么这个Docker环境会引入forward compatibility 问题?
- 有办法解决吗?
CUDA的forward compatibility
我们先引入三个概念:CUDA Toolkit、CUDA driver、GPU driver:
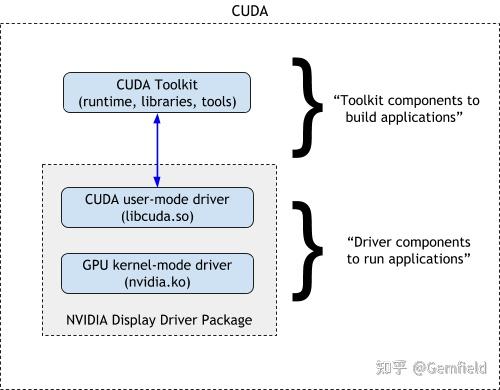
- CUDA Toolkit (libraries, CUDA runtime and developer tools) - User-mode SDK used to build CUDA applications;
- CUDA driver - User-mode driver component used to run CUDA applications (比如libcuda.so);
- NVIDIA GPU device driver - Kernel-mode driver component for NVIDIA GPUs。
兼容性概念
下面Gemfield就来说说CUDA生态上的3种兼容性:
1,源码API兼容性
在CUDA driver 和CUDA runtime的不同版本之间,源码API总是不兼容的;也就是说,当升级了CUDA driver 和CUDA runtime的版本,你的应用程序基本上总是要修改源码才能重新编译。
2,二进制兼容性
编译好的程序在使用更新版本的cuda driver时是否兼容。基本上都是兼容的,举个例子,编译好的应用程序即使把cuda driver从老旧的版本3.2升级到最新的11.0,程序依然能够运行起来。
3,CUDA Binary (cubin)兼容性
和cuda arch相关的,你看官方文档就行了。本文gemfield说的问题和 二进制兼容性 相关。
二进制兼容性
包含两个重要概念:
- 从CUDA10开始引入的 CUDA Forward Compatible Upgrade;
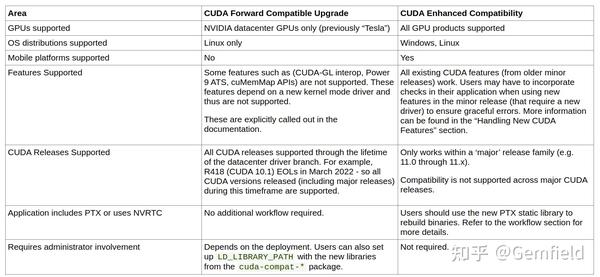
- 从CUDA11.1开始引入的 CUDA Enhanced Compatibility。
先说说CUDA driver (libcuda.so)。CUDA driver 是NVIDIA driver软件包的一部分,提供二进制的后向兼容性(backward compatibility)——比如基于非常老旧的CUDA 3.2 SDK编译的程序如今仍然能够运行在最新的驱动栈上。
再说说CUDA runtime(libcudart.so)。在南向方面,每个版本的CUDA运行时(libcudart.so)都对NVIDIA driver有一个最低版本的要求:
| CUDA Toolkit | Linux x86_64 Driver Version |
| CUDA 11.2 | >= 450.80.02 |
| CUDA 11.1 (11.1.0) | >= 450.80.02 |
| CUDA 11.0 (11.0.3) | >= 450.36.06 |
| CUDA 10.2 (10.2.89) | >= 440.33 |
| CUDA 10.1 (10.1.105) | >= 418.39 |
| CUDA 10.0 (10.0.130) | >= 410.48 |
| CUDA 9.2 (9.2.88) | >= 396.26 |
| CUDA 9.1 (9.1.85) | >= 390.46 |
| CUDA 9.0 (9.0.76) | >= 384.81 |
| CUDA 8.0 (8.0.61 GA2) | >= 375.26 |
| CUDA 8.0 (8.0.44) | >= 367.48 |
| CUDA 7.5 (7.5.16) | >= 352.31 |
| CUDA 7.0 (7.0.28) | >= 346.46 |
在北向方面,CUDA运行时(libcudart.so)既不会对你的应用程序提供源码API的兼容性,也不会提供二进制兼容性。只要major和minor的CUDA运行时版本一变,你的程序就歇菜了。比如,如果你的程序动态链接了libcudart.so.11.0,那它只能运行在含有libcudart.so.11.0的环境中。
应用程序所使用的cuda运行时库(libcudart.so)比系统上的Nvidia driver(CUDA driver + GPU device driver)还要新的时候,应用程序还能不能正常运行且使用到新的功能,就是所谓的 forward compatibility 。实际上,这正是从CUDA 10开始引入的 CUDA Forward Compatible Upgrade。
再重复一遍, CUDA Forward Compatible Upgrade 的目的是为了让用户在 老旧的GPU驱动 上基于最新的 cuda toolkit版本 编译从而可以使用最新的CUDA features。而在 更新的GPU驱动 上运行 更旧的cuda toolkit 不是这个范畴——因为这是backward compatible——是一直以来都支持的。所以, CUDA Forward Compatible Upgrade 讲的是 新cuda toolkit版本和旧GPU驱动版本 的关系:
CUDA Forward Compatible Upgrade = 新cuda toolkit版本(+新libcuda.so) VS 旧GPU驱动版本(kernel mode)
而从CUDA11.1引入的 CUDA Enhanced Compatibility 讲的是,基于cuda toolkit 11.1编译的应用程序能否运行在cuda11.2软件栈上,或者基于cuda11.2编译的应用程序能否运行在cuda11.1软件栈上。下面章节会详细描述。
forward compatibility
在cuda10.0以前,为了满足上述所述的forward compatibility的要求,当我们需要升级libcudart.so的时候,就需要跟着升级CUDA driver + GPU device driver,也就是libcuda.so + nvidia.ko。如下图所示:
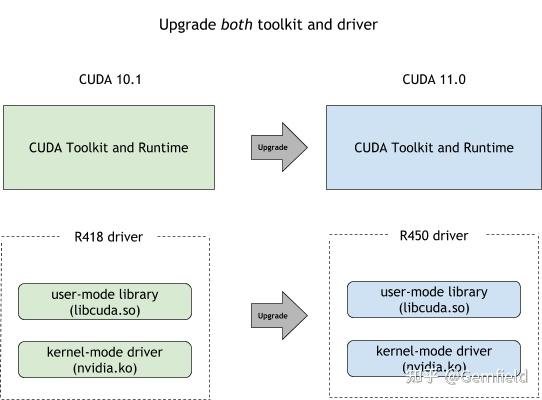
很复杂对不对?
但是,从CUDA 10.0开始,NVIDIA引入了新的forward-compatible升级路径:GPU device driver可以不用再随着更新了(nvidia.ko内核驱动),而只需要升级CUDA driver(libcuda.so),如下图所示:
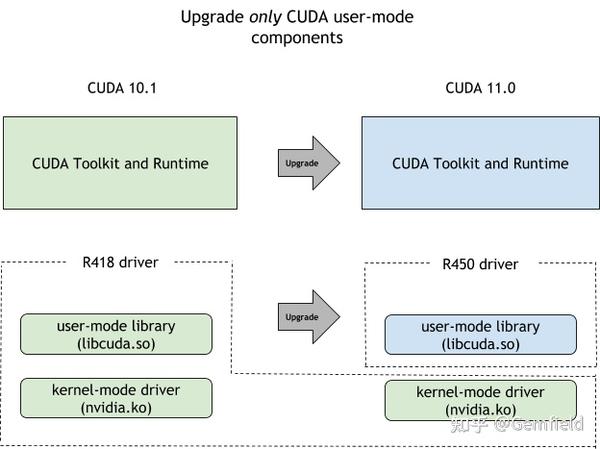
这个功能好呀,那我们就用上呗。但是问题来了——虽说从架构上来说,Kepler、Maxwell、Pascal、Volta、Turing、Ampere这些都支持——但是NVIDIA限制了只有 Datacenter (Tesla) GPU产品, 也就是只有tesla系列显卡才支持这种升级路径 。
也就是说,有了CUDA compatible upgrade这个功能,用户使用更新版本的cuda toolkit编译的应用程序,可以运行在更旧的nvidia driver上(前提是tesla级别的显卡)。如下图所示:
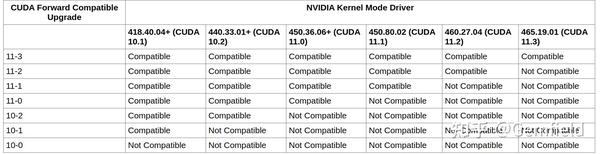
从图中可以看出,假设pytorch基于cua11.2 toolkit进行编译,那么在没有这个功能之前,只能运行在460.27的驱动上;而有了这个功能后,可以运行在从418到460的所有驱动上。
CUDA enhanced compatibility
这是从CUDA11.1开始引入的功能。
SONAME
首先,为了符合ELF规范,cuda toolkit 所有11.x的release的SONAME都保持一样(除了NVRTC),这样以来,当你的程序基于cuda toolkit11.1库进行动态链接编译后,然后程序放到cuda toolkit 11.0的环境中,动态链接器首先不会因为SONAME而发难。但是,SONAME这一关过去后,如果cuda toolkit 11.1中有11.0中不具备的符号又该怎么办呢?如果这个符号是编译你的应用程序时所链接的,那这个时候还是会报错。但是,你的应用程序运行在cuda toolkit11.2(更高版本的cuda toolkit 11.x)中则不会有任何问题。
Driver
除了ELF涉及的SONAME和符号外,底层的驱动也要为这个feature提供一些便利性支持,本文就不展开了。
为什么Docker环境会引入forward compatibility 问题?
问题就出在,Gemfield的宿主机上的驱动版本是:
- GPU device driver:450.102.04;
- CUDA driver:libcuda.so.450.102.04。
而Gemfield所使用的下面两个image中的cuda runtime分别是:
- nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04的cuda runtime是libcudart.so.11.2
- nvidia/cuda:11.1.1-cudnn8-devel-ubuntu20.04的cuda runtime是libcudart.so.11.1
现在猜测这个问题的真相就藏在以下两种情况之中:
- 以libcudart.so.11.2为例,正常情况下它需要的CUDA driver是libcuda.so.460.32.03,而nvidia-docker容器则从宿主机上mount了libcuda.so.450.102.04,导致版本不匹配。又因为Gemfield使用的是RTX2080ti显卡,而不是tesla系列,也不支持forward compatibility。所以最终导致了这个错误: Error 804: forward compatibility was attempted on non supported HW;
- nvidia docker有专门的逻辑来处理驱动依赖,也就是nvidia docker在启动容器的时候能正确选择image中可能包含的正确版本的CUDA driver(libcuda.so),然而宿主机的GPU device驱动版本过低,这就产生了forward compatibility问题。
那真相究竟是什么呢?
如果我们打开宿主机上/etc/nvidia-container-runtime/config.toml中的debug开关,然后启动容器,就会看到启动日志(备注,这是一个cuda11.3.1的image产生的日志,要和上文的11.2区别开来):
I0629 12:10:31.001378 930305 nvc.c:372] initializing library context (version=1.4.0, build=704a698b7a0ceec07a48e56c37365c741718c2df)
I0629 12:10:31.001469 930305 nvc.c:346] using root /
I0629 12:10:31.001483 930305 nvc.c:347] using ldcache /etc/ld.so.cache
I0629 12:10:31.001494 930305 nvc.c:348] using unprivileged user 65534:65534
I0629 12:10:31.001523 930305 nvc.c:389] attempting to load dxcore to see if we are running under Windows Subsystem for Linux (WSL)
I0629 12:10:31.001717 930305 nvc.c:391] dxcore initialization failed, continuing assuming a non-WSL environment
I0629 12:10:31.003740 930312 nvc.c:274] loading kernel module nvidia
I0629 12:10:31.004043 930312 nvc.c:278] running mknod for /dev/nvidiactl
I0629 12:10:31.004094 930312 nvc.c:282] running mknod for /dev/nvidia0
I0629 12:10:31.004129 930312 nvc.c:282] running mknod for /dev/nvidia1
I0629 12:10:31.004162 930312 nvc.c:286] running mknod for all nvcaps in /dev/nvidia-caps
I0629 12:10:31.012668 930312 nvc.c:214] running mknod for /dev/nvidia-caps/nvidia-cap1 from /proc/driver/nvidia/capabilities/mig/config
I0629 12:10:31.012820 930312 nvc.c:214] running mknod for /dev/nvidia-caps/nvidia-cap2 from /proc/driver/nvidia/capabilities/mig/monitor
I0629 12:10:31.015665 930312 nvc.c:292] loading kernel module nvidia_uvm
I0629 12:10:31.015790 930312 nvc.c:296] running mknod for /dev/nvidia-uvm
I0629 12:10:31.015888 930312 nvc.c:301] loading kernel module nvidia_modeset
I0629 12:10:31.016016 930312 nvc.c:305] running mknod for /dev/nvidia-modeset
I0629 12:10:31.016283 930313 driver.c:101] starting driver service
I0629 12:10:31.020636 930305 nvc_container.c:388] configuring container with 'compute utility supervised'
I0629 12:10:31.021014 930305 nvc_container.c:236] selecting /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/local/cuda-11.3/compat/libcuda.so.465.19.01
I0629 12:10:31.021113 930305 nvc_container.c:236] selecting /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/local/cuda-11.3/compat/libnvidia-ptxjitcompiler.so.465.19.01
I0629 12:10:31.021292 930305 nvc_container.c:408] setting pid to 930291
I0629 12:10:31.021309 930305 nvc_container.c:409] setting rootfs to /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged
I0629 12:10:31.021322 930305 nvc_container.c:410] setting owner to 0:0
I0629 12:10:31.021335 930305 nvc_container.c:411] setting bins directory to /usr/bin
I0629 12:10:31.021348 930305 nvc_container.c:412] setting libs directory to /usr/lib/x86_64-linux-gnu
I0629 12:10:31.021360 930305 nvc_container.c:413] setting libs32 directory to /usr/lib/i386-linux-gnu
I0629 12:10:31.021373 930305 nvc_container.c:414] setting cudart directory to /usr/local/cuda
I0629 12:10:31.021385 930305 nvc_container.c:415] setting ldconfig to @/sbin/ldconfig.real (host relative)
I0629 12:10:31.021398 930305 nvc_container.c:416] setting mount namespace to /proc/930291/ns/mnt
I0629 12:10:31.021411 930305 nvc_container.c:418] setting devices cgroup to /sys/fs/cgroup/devices/docker/796b3d7686d9596acb54485478b6126d1429acaa5607e9a8a47d17eb004545ab
I0629 12:10:31.021430 930305 nvc_info.c:676] requesting driver information with ''
I0629 12:10:31.023521 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvoptix.so.460.80
I0629 12:10:31.023615 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-tls.so.460.80
I0629 12:10:31.023691 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-rtcore.so.460.80
I0629 12:10:31.023770 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-ptxjitcompiler.so.460.80
I0629 12:10:31.023870 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-opticalflow.so.460.80
I0629 12:10:31.023970 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-opencl.so.460.80
I0629 12:10:31.024044 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-ngx.so.460.80
I0629 12:10:31.024127 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.460.80
I0629 12:10:31.024228 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-ifr.so.460.80
I0629 12:10:31.024330 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-glvkspirv.so.460.80
I0629 12:10:31.024401 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-glsi.so.460.80
I0629 12:10:31.024470 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-glcore.so.460.80
I0629 12:10:31.024539 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-fbc.so.460.80
I0629 12:10:31.024641 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-encode.so.460.80
I0629 12:10:31.024743 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-eglcore.so.460.80
I0629 12:10:31.024813 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-compiler.so.460.80
I0629 12:10:31.024883 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-cfg.so.460.80
I0629 12:10:31.024982 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-cbl.so.460.80
I0629 12:10:31.025053 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvidia-allocator.so.460.80
I0629 12:10:31.025155 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libnvcuvid.so.460.80
I0629 12:10:31.025465 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libcuda.so.460.80
I0629 12:10:31.025645 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libGLX_nvidia.so.460.80
I0629 12:10:31.025716 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libGLESv2_nvidia.so.460.80
I0629 12:10:31.025789 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libGLESv1_CM_nvidia.so.460.80
I0629 12:10:31.025867 930305 nvc_info.c:169] selecting /usr/lib/x86_64-linux-gnu/libEGL_nvidia.so.460.80
W0629 12:10:31.025957 930305 nvc_info.c:350] missing library libnvidia-nscq.so
W0629 12:10:31.025977 930305 nvc_info.c:350] missing library libnvidia-fatbinaryloader.so
W0629 12:10:31.025990 930305 nvc_info.c:350] missing library libvdpau_nvidia.so
W0629 12:10:31.026002 930305 nvc_info.c:354] missing compat32 library libnvidia-ml.so
W0629 12:10:31.026015 930305 nvc_info.c:354] missing compat32 library libnvidia-cfg.so
W0629 12:10:31.026027 930305 nvc_info.c:354] missing compat32 library libnvidia-nscq.so
W0629 12:10:31.026040 930305 nvc_info.c:354] missing compat32 library libcuda.so
W0629 12:10:31.026052 930305 nvc_info.c:354] missing compat32 library libnvidia-opencl.so
W0629 12:10:31.026065 930305 nvc_info.c:354] missing compat32 library libnvidia-ptxjitcompiler.so
W0629 12:10:31.026077 930305 nvc_info.c:354] missing compat32 library libnvidia-fatbinaryloader.so
W0629 12:10:31.026090 930305 nvc_info.c:354] missing compat32 library libnvidia-allocator.so
W0629 12:10:31.026102 930305 nvc_info.c:354] missing compat32 library libnvidia-compiler.so
W0629 12:10:31.026114 930305 nvc_info.c:354] missing compat32 library libnvidia-ngx.so
W0629 12:10:31.026127 930305 nvc_info.c:354] missing compat32 library libvdpau_nvidia.so
W0629 12:10:31.026139 930305 nvc_info.c:354] missing compat32 library libnvidia-encode.so
W0629 12:10:31.026151 930305 nvc_info.c:354] missing compat32 library libnvidia-opticalflow.so
W0629 12:10:31.026164 930305 nvc_info.c:354] missing compat32 library libnvcuvid.so
W0629 12:10:31.026176 930305 nvc_info.c:354] missing compat32 library libnvidia-eglcore.so
W0629 12:10:31.026189 930305 nvc_info.c:354] missing compat32 library libnvidia-glcore.so
W0629 12:10:31.026201 930305 nvc_info.c:354] missing compat32 library libnvidia-tls.so
W0629 12:10:31.026213 930305 nvc_info.c:354] missing compat32 library libnvidia-glsi.so
W0629 12:10:31.026226 930305 nvc_info.c:354] missing compat32 library libnvidia-fbc.so
W0629 12:10:31.026238 930305 nvc_info.c:354] missing compat32 library libnvidia-ifr.so
W0629 12:10:31.026250 930305 nvc_info.c:354] missing compat32 library libnvidia-rtcore.so
W0629 12:10:31.026263 930305 nvc_info.c:354] missing compat32 library libnvoptix.so
W0629 12:10:31.026283 930305 nvc_info.c:354] missing compat32 library libGLX_nvidia.so
W0629 12:10:31.026295 930305 nvc_info.c:354] missing compat32 library libEGL_nvidia.so
W0629 12:10:31.026308 930305 nvc_info.c:354] missing compat32 library libGLESv2_nvidia.so
W0629 12:10:31.026320 930305 nvc_info.c:354] missing compat32 library libGLESv1_CM_nvidia.so
W0629 12:10:31.026333 930305 nvc_info.c:354] missing compat32 library libnvidia-glvkspirv.so
W0629 12:10:31.026345 930305 nvc_info.c:354] missing compat32 library libnvidia-cbl.so
I0629 12:10:31.026804 930305 nvc_info.c:276] selecting /usr/bin/nvidia-smi
I0629 12:10:31.026840 930305 nvc_info.c:276] selecting /usr/bin/nvidia-debugdump
I0629 12:10:31.026874 930305 nvc_info.c:276] selecting /usr/bin/nvidia-persistenced
I0629 12:10:31.026929 930305 nvc_info.c:276] selecting /usr/bin/nvidia-cuda-mps-control
I0629 12:10:31.026964 930305 nvc_info.c:276] selecting /usr/bin/nvidia-cuda-mps-server
W0629 12:10:31.027162 930305 nvc_info.c:376] missing binary nv-fabricmanager
I0629 12:10:31.027207 930305 nvc_info.c:438] listing device /dev/nvidiactl
I0629 12:10:31.027219 930305 nvc_info.c:438] listing device /dev/nvidia-uvm
I0629 12:10:31.027230 930305 nvc_info.c:438] listing device /dev/nvidia-uvm-tools
I0629 12:10:31.027241 930305 nvc_info.c:438] listing device /dev/nvidia-modeset
I0629 12:10:31.027286 930305 nvc_info.c:317] listing ipc /run/nvidia-persistenced/socket
W0629 12:10:31.027326 930305 nvc_info.c:321] missing ipc /var/run/nvidia-fabricmanager/socket
W0629 12:10:31.027356 930305 nvc_info.c:321] missing ipc /tmp/nvidia-mps
I0629 12:10:31.027369 930305 nvc_info.c:733] requesting device information with ''
I0629 12:10:31.033849 930305 nvc_info.c:623] listing device /dev/nvidia0 (GPU-66be7464-6dee-a588-1ad6-b95e626f907b at 00000000:4b:00.0)
I0629 12:10:31.040214 930305 nvc_info.c:623] listing device /dev/nvidia1 (GPU-a92e2821-9637-a638-a485-4cb36f5f3ee1 at 00000000:4c:00.0)
I0629 12:10:31.040327 930305 nvc_mount.c:344] mounting tmpfs at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/proc/driver/nvidia
I0629 12:10:31.040943 930305 nvc_mount.c:112] mounting /usr/bin/nvidia-smi at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/bin/nvidia-smi
I0629 12:10:31.041067 930305 nvc_mount.c:112] mounting /usr/bin/nvidia-debugdump at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/bin/nvidia-debugdump
I0629 12:10:31.041161 930305 nvc_mount.c:112] mounting /usr/bin/nvidia-persistenced at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/bin/nvidia-persistenced
I0629 12:10:31.041265 930305 nvc_mount.c:112] mounting /usr/bin/nvidia-cuda-mps-control at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/bin/nvidia-cuda-mps-control
I0629 12:10:31.041364 930305 nvc_mount.c:112] mounting /usr/bin/nvidia-cuda-mps-server at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/bin/nvidia-cuda-mps-server
I0629 12:10:31.041657 930305 nvc_mount.c:112] mounting /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.460.80 at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/lib/x86_64-linux-gnu/libnvidia-ml.so.460.80
I0629 12:10:31.041763 930305 nvc_mount.c:112] mounting /usr/lib/x86_64-linux-gnu/libnvidia-cfg.so.460.80 at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/lib/x86_64-linux-gnu/libnvidia-cfg.so.460.80
I0629 12:10:31.041860 930305 nvc_mount.c:112] mounting /usr/lib/x86_64-linux-gnu/libcuda.so.460.80 at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/lib/x86_64-linux-gnu/libcuda.so.460.80
I0629 12:10:31.041997 930305 nvc_mount.c:112] mounting /usr/lib/x86_64-linux-gnu/libnvidia-opencl.so.460.80 at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/lib/x86_64-linux-gnu/libnvidia-opencl.so.460.80
I0629 12:10:31.042114 930305 nvc_mount.c:112] mounting /usr/lib/x86_64-linux-gnu/libnvidia-ptxjitcompiler.so.460.80 at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/lib/x86_64-linux-gnu/libnvidia-ptxjitcompiler.so.460.80
I0629 12:10:31.042221 930305 nvc_mount.c:112] mounting /usr/lib/x86_64-linux-gnu/libnvidia-allocator.so.460.80 at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/lib/x86_64-linux-gnu/libnvidia-allocator.so.460.80
I0629 12:10:31.042320 930305 nvc_mount.c:112] mounting /usr/lib/x86_64-linux-gnu/libnvidia-compiler.so.460.80 at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/lib/x86_64-linux-gnu/libnvidia-compiler.so.460.80
I0629 12:10:31.042372 930305 nvc_mount.c:524] creating symlink /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/lib/x86_64-linux-gnu/libcuda.so -> libcuda.so.1
I0629 12:10:31.042580 930305 nvc_mount.c:112] mounting /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/local/cuda-11.3/compat/libcuda.so.465.19.01 at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/lib/x86_64-linux-gnu/libcuda.so.465.19.01
I0629 12:10:31.042688 930305 nvc_mount.c:112] mounting /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/local/cuda-11.3/compat/libnvidia-ptxjitcompiler.so.465.19.01 at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/usr/lib/x86_64-linux-gnu/libnvidia-ptxjitcompiler.so.465.19.01
I0629 12:10:31.042930 930305 nvc_mount.c:239] mounting /run/nvidia-persistenced/socket at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/run/nvidia-persistenced/socket
I0629 12:10:31.043039 930305 nvc_mount.c:208] mounting /dev/nvidiactl at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/dev/nvidiactl
I0629 12:10:31.043088 930305 nvc_mount.c:499] whitelisting device node 195:255
I0629 12:10:31.043190 930305 nvc_mount.c:208] mounting /dev/nvidia-uvm at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/dev/nvidia-uvm
I0629 12:10:31.043232 930305 nvc_mount.c:499] whitelisting device node 235:0
I0629 12:10:31.043318 930305 nvc_mount.c:208] mounting /dev/nvidia-uvm-tools at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/dev/nvidia-uvm-tools
I0629 12:10:31.043359 930305 nvc_mount.c:499] whitelisting device node 235:1
I0629 12:10:31.043469 930305 nvc_mount.c:208] mounting /dev/nvidia0 at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/dev/nvidia0
I0629 12:10:31.043630 930305 nvc_mount.c:412] mounting /proc/driver/nvidia/gpus/0000:4b:00.0 at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/proc/driver/nvidia/gpus/0000:4b:00.0
I0629 12:10:31.043676 930305 nvc_mount.c:499] whitelisting device node 195:0
I0629 12:10:31.043778 930305 nvc_mount.c:208] mounting /dev/nvidia1 at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/dev/nvidia1
I0629 12:10:31.043921 930305 nvc_mount.c:412] mounting /proc/driver/nvidia/gpus/0000:4c:00.0 at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged/proc/driver/nvidia/gpus/0000:4c:00.0
I0629 12:10:31.043963 930305 nvc_mount.c:499] whitelisting device node 195:1
I0629 12:10:31.044003 930305 nvc_ldcache.c:360] executing /sbin/ldconfig.real from host at /var/lib/docker/overlay2/dd8d1c44a88df34c3257d7d6cc323c206a57a70abb108ebc389456002466b76b/merged
I0629 12:10:31.170223 930305 nvc.c:423] shutting down library context
I0629 12:10:31.171158 930313 driver.c:163] terminating driver service
I0629 12:10:31.171814 930305 driver.c:203] driver service terminated successfully从中可以看到以下关键信息:
- mknod,创建所需的设备文件,/dev/nvidiactl、/dev/nvidia0、/dev/nvidia1(取决于宿主机有几个cuda设备)、/dev/nvidia-caps、/dev/nvidia-uvm、/dev/nvidia-modeset;如果你接触过docker 的--device参数的话,你就知道mknod这些文件是要干啥了;
- 选择user mode的cuda driver版本,在这里,选择了:cuda-11.3/compat/libcuda.so.465.19.01和cuda-11.3/compat/libnvidia-ptxjitcompiler.so.465.19.01,也就是选择了libcuda.so.465.19.01(这两个文件是docker image中的,后文会再次说明);注意,宿主机上只有/usr/lib/x86_64-linux-gnu/libcuda.so.460.80;
- 向容器中注入以下宿主机上的工具(从宿主机的/usr/bin到容器的/usr/bin目录):
/usr/bin/nvidia-smi
/usr/bin/nvidia-debugdump
/usr/bin/nvidia-persistenced
/usr/bin/nvidia-cuda-mps-control
/usr/bin/nvidia-cuda-mps-server- 向容器中注入以下宿主机上的库(从宿主机的/usr/lib/x86_64-linux-gnu/到容器的/usr/lib/x86_64-linux-gnu/目录):
/usr/lib/x86_64-linux-gnu/libnvidia-ml.so.460.80
/usr/lib/x86_64-linux-gnu/libnvidia-cfg.so.460.80
/usr/lib/x86_64-linux-gnu/libcuda.so.460.80
/usr/lib/x86_64-linux-gnu/libnvidia-opencl.so.460.80
/usr/lib/x86_64-linux-gnu/libnvidia-ptxjitcompiler.so.460.80
/usr/lib/x86_64-linux-gnu/libnvidia-allocator.so.460.80
/usr/lib/x86_64-linux-gnu/libnvidia-compiler.so.460.80- 将image中本来就包含的/usr/local/cuda-11.3/compat/libcuda.so.465.19.01注入到容器的/usr/lib/x86_64-linux-gnu/libcuda.so.465.19.01;
- 将image中本来就包含的/local/cuda-11.3/compat/libnvidia-ptxjitcompiler.so.465.19.01注入到容器中的/usr/lib/x86_64-linux-gnu/libnvidia-ptxjitcompiler.so.465.19.01;
- 在容器中设置文件链接,也就是/libcuda.so -> libcuda.so.1 -> libcuda.so.465.19.01:
# ls -l /usr/lib/x86_64-linux-gnu/libcuda.so*
lrwxrwxrwx 1 root root 12 6月 30 00:09 /usr/lib/x86_64-linux-gnu/libcuda.so -> libcuda.so.1
lrwxrwxrwx 1 root root 20 6月 30 00:09 /usr/lib/x86_64-linux-gnu/libcuda.so.1 -> libcuda.so.465.19.01
-rw-r--r-- 1 root root 21795104 5月 7 15:00 /usr/lib/x86_64-linux-gnu/libcuda.so.460.80
-rw-r--r-- 1 root root 22033824 3月 19 16:07 /usr/lib/x86_64-linux-gnu/libcuda.so.465.19.01- 将宿主机的/run/nvidia-persistenced/socket注入到容器中的/run/nvidia-persistenced/socket;
- 将以下宿主机的设备文件注入到容器中(从宿主机的/dev到容器中的/dev):
/dev/nvidiactl
/dev/nvidia-uvm
/dev/nvidia-uvm-tools
/dev/nvidia0
/dev/nvidia1
/proc/driver/nvidia/gpus/0000:4b:00.0
/proc/driver/nvidia/gpus/0000:4c:00.0可以看到,虽然容器中从宿主机上mount了和kernel mode GPU driver对应的user mode CUDA driver,但是libcuda.so通过软链接指向了image中本来就包含的user mode CUDA driver,也就是容器中真正使用的是libcuda.so.465.19.01 而非宿主机的libcuda.so.460.80,这正好产生了 forward compatibility 问题!!!
怎么解决呢?
在非tesla系列显卡且使用nvidia docker的情况下,我们有3种办法:
- 要么升级宿主机的驱动(kernel mode + user mode drivers)和docker image中cuda toolkit所需的一致;
- 要么降低nvidia镜像的版本,使得其中的cuda toolkit需要的驱动(kernel mode + user mode drivers)版本正好为宿主机上的驱动版本;
- 要么降级docker image(或者运行起来的容器)中的user mode driver(libcuda.so)的版本和宿主机的user mode driver版本一致,然后容器中的cuda toolkit版本依然维持为新版本,这样就是 "newer version cuda toolkit + older version cuda driver + older version kernel mode GPU driver", 从而将 forward compatibility 问题变成了 CUDA enhanced compatibility问题(被非tesla显卡所支持):
# 修改前
root@1d0d6b4ec38d:/.gemfield_install# ls -l /usr/lib/x86_64-linux-gnu/libcuda.so*
lrwxrwxrwx 1 root root 12 6月 30 00:09 /usr/lib/x86_64-linux-gnu/libcuda.so -> libcuda.so.1
lrwxrwxrwx 1 root root 20 6月 30 00:09 /usr/lib/x86_64-linux-gnu/libcuda.so.1 -> libcuda.so.465.19.01
-rw-r--r-- 1 root root 21795104 5月 7 15:00 /usr/lib/x86_64-linux-gnu/libcuda.so.460.80
-rw-r--r-- 1 root root 22033824 3月 19 16:07 /usr/lib/x86_64-linux-gnu/libcuda.so.465.19.01
# 修改
ln -sf /usr/lib/x86_64-linux-gnu/libcuda.so.460.80 /usr/lib/x86_64-linux-gnu/libcuda.so.1但是最后这种情况下会遇到一个问题,那就是程序使用了新版本cuda toolkit才具备的功能,那么运行时会导致程序错误。
后续
Ubuntu20.04的apt仓库在今年五月份引入了最新的NVIDIA 460.80驱动,宿主机经过更新后,驱动信息如下:
gemfield@ai03:/gemfield/hostpv$ nvidia-smi
Tue Jun 22 11:19:24 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.80 Driver Version: 460.80 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce RTX 208... Off | 00000000:19:00.0 Off | N/A |
| 35% 41C P8 9W / 250W | 5MiB / 11019MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 GeForce RTX 208... Off | 00000000:67:00.0 Off | N/A |
|ERR! 48C P2 ERR! / 250W | 5MiB / 11019MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 GeForce RTX 208... Off | 00000000:68:00.0 Off | N/A |
| 79% 73C P2 219W / 250W | 5650MiB / 11018MiB | 13% Default |
| | | N/A |