

WEKA在机器学习、数据挖掘领域的应用(一)

WEKA简介
•Weka的主要开发者来自新西兰的怀卡托(Waikato)大学,是一款免费的,非商业化的,基于JAVA环境下开源的机器学习(Machine Learning)以及数据挖掘(Data Mining)软件。
•Weka可以对数据进行预处理,分类,聚类、关联规则、属性选择以及可视化。
•Weka的源码使用java编写,所有它的jar包还可以导入java的工程中,直接调用api。
•weka可以打开.xls文件(Excel文件),可以连接数据库(这里连接了mysql数据库)。
•Weka数据格式:ARFF(Attribute-Relation File Format)文件
Weka数据格式:*.ARFF
ARFF数据由三部分构成:关系声明、属性声明、数据信息。
•关系声明 @relation <relation-name>
•属性声明 @attribute <attribute-name> <datatype>
•数据信息 @data




数据准备
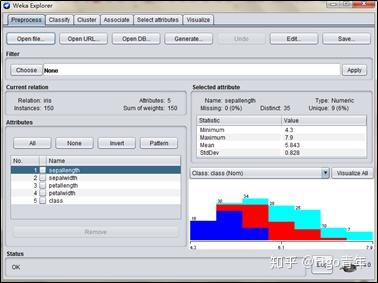
•打开.xls文件:在(GUI选择器)Weka GUI Chooser中找到
•访问mysql数据库:需要提前解压缩weka.jar包,然后修改weka里面的jdbc配置代码,打开Sqlviewer进行操作。
•GUI选择器的Arffviewer可以直接以表格形式查看以及修改数据集。



预处理
•加载数据:可以打开文件;也可以通过URL地址,weka通过http协议下载数据文件;可以打开数据库文件。
•属性处理:预处理界面显示了数据集的基本信息,如属性数量、样本数量、属性信息,并且可以手动去除某些不需要的属性。
•过滤器:过滤器分为监督学习与非监督学习两大类,每类里面又分为滤除样本和滤除属性的过滤器。
无监督属性过滤器:增加和删除属性(给定位置插入或者删除属性)、改变值(比如处理缺失值)、转换(比如离散化)、字符串转换(将字符串属性转换为标称属性)。

无监督实例过滤器:随机化和子抽样、稀疏实例。


有监督属性过滤器:离散化(将数值型属性离散化为标称型属性)、改变类别顺序(根据类别频率进行顺序或降序排序)、等等。
有监督实例过滤器:ClassBalancer(使得每个类别都有相同的总权重)、SpreadSubsample(产生一个随机子样本)、等等
在预处理标签页加载UCI的glass.arff数据集,选择无监督属性Discretize过滤器, 先等宽离散化,再设置useEqualFrequence = true进行等频离散化。
glass数据集是通过折射率和化学元素确定玻璃类型的数据库。数据集有9个属性,其中1个为折射率,剩余8个为玻璃所含化学元素的相对重量,类别标签共有7种,是7种用途的玻璃类型。




