对于如何补全一个矩阵,历史上有过很多的研究。一个空的矩阵有很多种补全方法,而我们要找的是一种对矩阵扰动最小的补全方法。那么什么才算是对矩阵扰动最小呢?一般认为,如果补全后矩阵的特征值和补全之前矩阵的特征值相差不大,就算是扰动比较小。所以,最早的矩阵分解模型就是从数学上的SVD(奇异值分解)开始的。给定m个用户和n个物品,和用户对物品

奇异值分解将矩阵分解为奇异值和奇异向量
R是一个m
n的矩阵,U是一个m
m的矩阵,S是一个m
n的矩阵,V是一个n
n的矩阵
矩阵S对角元素上的值称为矩阵A的奇异值,U的列向量称为左奇异向量,V的列向量称为右奇异向量
左奇异向量是RRT的特征向量,右奇异向量是RTR的特征向量,A的非零奇异值是和特征值的平方根
SVD分解是早期推荐系统研究常用的矩阵分解方法,不过该方法具有以下缺点,因此很难在实际系统中应用。
-
该方法首先需要用一个简单的方法补全稀疏评分矩阵。一般来说,推荐系统中的评分矩阵是非常稀疏的,一般都有95%以上的元素是缺失的。而一旦补全,评分矩阵就会变成一个稠密矩阵,从而使评分矩阵的存储需要非常大的空间,这种空间的需求在实际系统中是不可能接受的。
-
该方法依赖的SVD分解方法的计算复杂度很高,特别是在稠密的大规模矩阵上更是非常慢。一般来说,这里的SVD分解用于1000维以上的矩阵就已经非常慢了,而实际系统动辄是上千万的用户和几百万的物品,所以这一方法无法使用。如果仔细研究关于这一方法的论文可以发现,实验都是在几百个用户、几百个物品的数据集上进行的。
LFM提出之后获得了很大的成功,后来很多著名的模型都是通过对LFM修修补补获得的,下面的各节将分别介绍一下改进LFM的各种方法。这些改进有些是对模型的改进,有些是将新的数据引入到模型当中。


class
SVDPP
(
object
)
:
implementation of SVD++ for CF
def
__init__
(
self
,
epoch
,
eta
,
userNums
,
itemNums
,
ku
=
0.001
,
km
=
0.001
,
\
f
=
30
,
save_model
=
False
)
:
super
(
SVDPP
,
self
)
.
__init__
(
)
self
.
epoch
=
epoch
self
.
userNums
=
userNums
self
.
itemNums
=
itemNums
self
.
eta
=
eta
self
.
ku
=
ku
self
.
km
=
km
self
.
f
=
f
self
.
save_model
=
save_model
self
.
U
=
None
self
.
M
=
None
def
fit
(
self
,
train
,
val
=
None
)
:
self
.
Udict
=
{
}
for
i
in
range
(
train
.
shape
[
0
]
)
:
uid
=
train
[
i
,
0
]
iid
=
train
[
i
,
1
]
self
.
Udict
.
setdefault
(
uid
,
[
]
)
self
.
Udict
[
uid
]
.
append
(
iid
)
rateNums
=
train
.
shape
[
0
]
self
.
meanV
=
np
.
sum
(
train
[
:
,
2
]
)
/
rateNums
initv
=
np
.
sqrt
(
(
self
.
meanV
-
1
)
/
self
.
f
)
self
.
U
=
initv
+
np
.
random
.
uniform
(
-
0.01
,
0.01
,
(
self
.
userNums
+
1
,
self
.
f
)
)
self
.
M
=
initv
+
np
.
random
.
uniform
(
-
0.01
,
0.01
,
(
self
.
itemNums
+
1
,
self
.
f
)
)
self
.
bu
=
np
.
zeros
(
self
.
userNums
+
1
)
self
.
bi
=
np
.
zeros
(
self
.
itemNums
+
1
)
self
.
y
=
np
.
zeros
(
(
self
.
itemNums
+
1
,
self
.
f
)
)
+
0.1
start
=
time
.
time
(
)
for
i
in
range
(
self
.
epoch
)
:
sumRmse
=
0.0
for
sample
in
train
:
uid
=
sample
[
0
]
iid
=
sample
[
1
]
vij
=
float
(
sample
[
2
]
)
sumYj
,
sqrt_Ni
=
self
.
get_Yi
(
uid
)
p
=
self
.
meanV
+
self
.
bu
[
uid
]
+
self
.
bi
[
iid
]
+
\
np
.
sum
(
self
.
M
[
iid
]
*
(
self
.
U
[
uid
]
+
sumYj
)
)
error
=
vij
-
p
sumRmse
+=
error
**
2
deltaU
=
error
*
self
.
M
[
iid
]
-
self
.
ku
*
self
.
U
[
uid
]
deltaM
=
error
*
(
self
.
U
[
uid
]
+
sumYj
)
-
self
.
km
*
self
.
M
[
iid
]
self
.
U
[
uid
]
+=
self
.
eta
*
deltaU
self
.
M
[
iid
]
+=
self
.
eta
*
deltaM
self
.
bu
[
uid
]
+=
self
.
eta
*
(
error
-
self
.
ku
*
self
.
bu
[
uid
]
)
self
.
bi
[
iid
]
+=
self
.
eta
*
(
error
-
self
.
km
*
self
.
bi
[
iid
]
)
rating_list
=
self
.
Udict
[
uid
]
self
.
y
[
rating_list
]
+=
self
.
eta
*
(
error
*
self
.
M
[
rating_list
]
/
sqrt_Ni
-
\
self
.
ku
*
self
.
y
[
rating_list
]
)
trainRmse
=
np
.
sqrt
(
sumRmse
/
rateNums
)
if
val
.
any
(
)
:
_
,
valRmse
=
self
.
evaluate
(
val
)
print
(
"Epoch %d cost time %.4f, train RMSE: %.4f, validation RMSE: %.4f"
%
\
(
i
,
time
.
time
(
)
-
start
,
trainRmse
,
valRmse
)
)
else
:
print
(
"Epoch %d cost time %.4f, train RMSE: %.4f"
%
\
(
i
,
time
.
time
(
)
-
start
,
trainRmse
)
)
if
self
.
save_model
:
model
=
(
self
.
meanV
,
self
.
bu
,
self
.
bi
,
self
.
U
,
self
.
M
)
pickle
.
dump
(
model
,
open
(
save_model
+
'/svcRecModel.pkl'
,
'wb'
)
)
def
evaluate
(
self
,
val
)
:
loss
=
0
pred
=
[
]
for
sample
in
val
:
uid
=
sample
[
0
]
iid
=
sample
[
1
]
if
uid
>
self
.
userNums
or
iid
>
self
.
itemNums
:
continue
sumYj
,
_
=
self
.
get_Yi
(
uid
)
predi
=
self
.
meanV
+
self
.
bu
[
uid
]
+
self
.
bi
[
iid
]
\
+
np
.
sum
(
self
.
M
[
iid
]
*
(
self
.
U
[
uid
]
+
sumYj
)
)
if
predi
<
1
:
predi
=
1
elif
predi
>
5
:
predi
=
5
pred
.
append
(
predi
)
if
val
.
shape
[
1
]
==
3
:
vij
=
sample
[
2
]
loss
+=
(
predi
-
vij
)
**
2
if
val
.
shape
[
1
]
==
3
:
rmse
=
np
.
sqrt
(
loss
/
val
.
shape
[
0
]
)
return
pred
,
rmse
return
pred
def
predict
(
self
,
test
)
:
return
self
.
evaluate
(
test
)
def
get_Yi
(
self
,
uid
)
:
Ni
=
self
.
Udict
[
uid
]
numNi
=
len
(
Ni
)
sqrt_Ni
=
np
.
sqrt
(
numNi
)
yj
=
np
.
zeros
(
(
1
,
self
.
f
)
)
if
numNi
==
0
:
sumYj
=
yj
+
0.1
else
:
yj
=
np
.
mean
(
self
.
y
[
Ni
]
,
axis
=
0
)
sumYj
=
yj
/
sqrt_Ni
return
sumYj
,
sqrt_Ni
[1]:项亮《推荐系统实战》
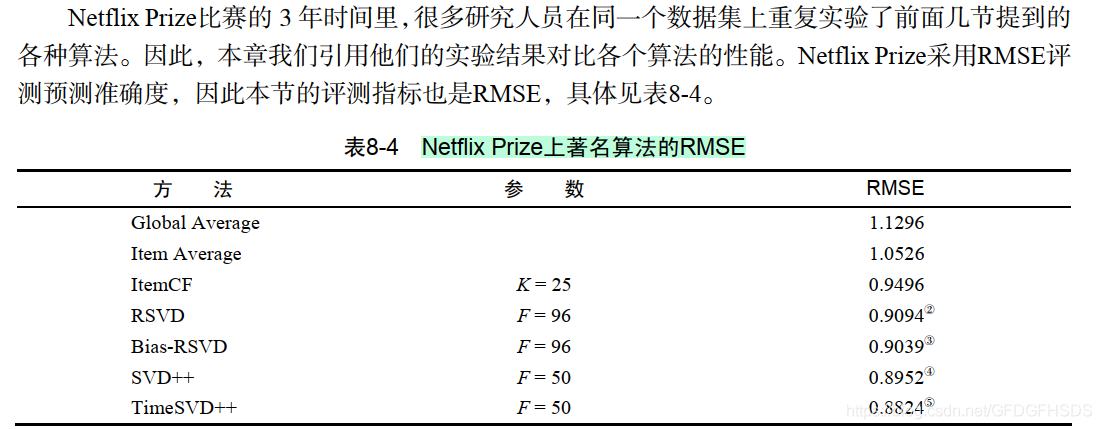
1.传统的SVD分解对于如何补全一个矩阵,历史上有过很多的研究。一个空的矩阵有很多种补全方法,而我们要找的是一种对矩阵扰动最小的补全方法。那么什么才算是对矩阵扰动最小呢?一般认为,如果补全后矩阵的特征值和补全之前矩阵的特征值相差不大,就算是扰动比较小。所以,最早的矩阵分解模型就是从数学上的SVD(奇异值分解)开始的。给定m个用户和n个物品,和用户对物品奇异值分解将矩阵分解为奇异值和奇异向量...
在上一篇奇异值分解原理浅析中,简单分析了
SVD
的矩阵分解原理。本文侧重分享下
SVD
算法
及其变种在推荐领域中的应用,
SVD
算法
最初是在Netflix竞赛中大放异彩,目前
SVD
及其变种主要包括Funk
SVD
、Bias
SVD
、
SVD
++
以及
time
SVD
。
Funk
SVD
算法
传统
的
SVD
矩阵分解要求矩阵必须是dense的,即不能有缺失值。而在实际的
推荐系统
中,User-
Item
评分矩阵RRR通常是非常...
关于
FM
和F
FM
的知识有很多,比如召回层或者排序层亦或者是多路召回、统一召回。这些内容以后也会写相应的文章来进行详细的讲解,在这篇文章中只是将这两种
算法
的基本原理以及公式讲清楚就足够了。
一、POLY2模型
在进行
FM
以及F
FM
模型讲解之前,先讲解一下POLY2模型。前面的文章讲过逻辑回归,虽然这是一个非常优秀的
算法
,但是仅仅依靠单一特征来进行判定的情况下,就会造成信息损失的问题,所以我们还需要进行多维度特征交叉。针对特征交叉问题POLY2模型进行特征的暴力组合来解决这类问题。数学形式如下所示:
原论文地址
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.379.1951&rep=rep1&type=pdf
本文地址:https://www.cnblogs.com/kyxfx/articles/9414823.html
一直没有找到完整的
Time
SVD
++
译文,就自己翻译了一下。
推荐算法
之
FM
1.模型原理2. 延伸2.1 对比MLP+Embedding2.2 领域信息Field3.
FM
的Tensorflow实现3. 参考
1.模型原理
FM
出现之前的
传统
的处理方法是人工特征工程加上线性模型(如逻辑回归Logistic Regression)。为了提高模型效果,关键技术是找到到用户点击行为背后隐含的特征组合。如男性、大学生用户往往会点击游戏类广告,因此 “男性且是大学生且是游戏类” 的特征组合就是一个关键特征。但这本质仍是线性模型,其假设函数表示成内积形式一般为:
ylinear=
推荐系统
算法
系列(一):
FM
算法
一、
FM
算法
背景
在计算广告和
推荐系统
中,CTR预估是非常重要的一个环节,判断一个商品的是否进行推荐需要根据CTR预估的点击率来进行。
在进行CTR预估时,除了单特征外,往往要对特征进行组合,对于特征组合来说,业界现在通用的做法主要有两大类:
FM
系列与Tree系列。实际工程中通常是高维稀疏矩,直接特征交叉会导致计算量过大,特征权值更新缓慢。
而
FM
的优势就是对这两...
TF-IDF
SVD
算法
是一种文本特征提取和降维的方法。TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本表示方法,用于衡量一个词语在文档中的重要程度。
SVD
(Singular Value Decomposition)是一种矩阵分解方法,可以将原始特征矩阵分解成三个矩阵的乘积,从而实现降维的目的。
TF-IDF
算法
首先计算每个词语在文档中的词频(TF),即某个词在文档中出现的次数。然后,通过计算逆文档频率(IDF),衡量这个词语在整个文集中的重要性。IDF的计算公式为$log(\frac{N}{n})$,其中N是文档总数,n是包含该词语的文档数。最后,将TF和IDF相乘得到TF-IDF权重。
在得到TF-IDF权重矩阵后,可以使用
SVD
算法
进行降维。
SVD
将原始的TF-IDF矩阵分解成三个矩阵的乘积:$A = U \Sigma V^T$,其中U和V是正交矩阵,$\Sigma$是对角矩阵。通过选择较小的k值,可以将原始矩阵A降维成k维,从而减少特征的数量。
TF-IDF
SVD
算法
在文本挖掘和信息检索等领域有广泛的应用,可以用于文本聚类、文本分类、相似度计算等任务。