


机器学习软件的三个层次

ML/AI 被新的应用程序和工业界迅速采用。在之前的文章中我们提到,机器学习项目的目标是通过使用收集的数据和应用机器学习算法来构建统计模型。然而,构建成功的基于 ML 的软件项目仍然很困难,因为每个基于 ML 的软件都需要管理三个主要资产: 数据 、 模型 和 代码 。
机器学习模型运维(MLOps)作为 DevOps 的扩展,围绕设计、构建和将 ML 模型部署到生产中建立有效的实践和流程。本文描述了基于机器学习的软件开发所涉及的基本技术方法,即 数据工程 、 机器学习模型工程 和 软件发布工程 。
我们建议记录您在整个流水线的每个步骤中学到的所有内容。
1 数据:数据工程流水线
我们之前提到过任何机器学习工作流的基本部分是 数据 。收集好的数据集对 ML 模型的质量和性能有巨大的影响。著名的引文
“垃圾进,垃圾出(Garbage In, Garbage Out)”,
在机器学习上下文中意味着数据质量决定了机器学习模型的最好效果。因此,用于 ML 模型训练的数据会间接影响生产系统的整体性能。数据集的数量和质量通常是针对特定问题的,并且可以通过经验发现。
作为重要的一步,数据工程非常耗时。在机器学习项目中我们可能将大部分时间花在构建数据集、清理和转换数据。
数据工程流水线包括对可用数据的一系列操作。这些操作的最终目标是为 ML 算法创建训练和测试数据集。在下文中,我们将描述数据工程流水线的每个阶段,例如 数据摄取、探索和验证、数据整理(清洗)和数据划分 。
1.1 数据摄取
数据摄取 -使用各种系统、框架和格式收集数据,例如内部/外部数据库、数据集市、OLAP 多维数据集、数据仓库、OLTP 系统、Spark、HDFS 等。此步骤还可能包括模拟数据生成或数据增强,此步骤的最佳实践包括以下应最大限度自动化的操作:
-
数据源识别:查找数据并记录其来源(数据出处)。
-
空间估计:检查它将占用多少存储空间。
-
空间位置:创建一个有足够存储空间的工作空间。
-
获取数据:获取数据并将其转换为无需更改数据本身即可轻松操作的格式。
-
备份数据:始终处理数据副本并保持原始数据集不变。
-
隐私合规:确保敏感信息被删除或保护(例如,匿名)以确保 GDPR 等法规要求。
-
元数据目录:通过记录有关大小、格式、别名、上次修改时间和访问控制列表的基本信息,开始记录数据集的元数据。(进一步阅读: https:// dl.acm.org/doi/pdf/10.1 145/2882903.2903730?download=true )
-
测试数据:对测试集进行采样,将其放在一边,永远不要看它,以避免“数据窥探”偏见。如果您通过使用测试集选择特定类型的 ML 模型,您就会爱上这个。这会导致 ML 模型选择过于乐观,在生产中表现不佳,也即过度拟合。
1.2 探索与验证
探索和验证- 包括数据分析以获取有关数据内容和结构的信息。此步骤的输出是一组元数据,例如值的最大值、最小值、平均值。数据验证操作是用户定义的错误检测函数,它扫描数据集以发现一些错误。验证是通过运行数据集验证例程(错误检测方法)来评估数据质量的过程。例如, 对于“地址”属性,地址组件是否一致?正确的邮政编码是否与地址相关联?相关属性中是否存在缺失值? 此步骤的最佳实践包括以下操作:
-
使用 RAD 工具:使用 Jupyter Notebook 是保存数据探索和实验记录的好方法。
-
属性分析:获取并记录有关每个属性的元数据,例如
-
姓名
-
记录数
-
数据类型(分类、数字、整数/浮点数、文本、结构化等)
-
数值测量(数值数据的最小值、最大值、平均值、中值等)
-
缺失值数量(或“缺失值比率” =缺失值数/记录数)
-
分布类型(高斯、均匀、对数等)
-
标签属性识别:对于有监督学习任务,识别目标属性。
-
数据可视化:构建价值分布的可视化表示。
-
属性相关性:计算和分析属性之间的相关性。
-
附加数据:识别对构建模型有用的数据(返回“数据摄取”)。
1.3 数据整理(清洗)
数据整理(清洗) ——数据准备步骤,我们以编程方式整理数据,例如,通过重新格式化或重新构造可能改变数据模式形式的特定属性。我们建议为数据流水线中的所有数据转换编写脚本或函数,以便在未来数据上重用所有这些功能。
-
转换:确定您可能想要应用的有希望的转换。
-
异常值:修复或删除异常值(可选)。
-
缺失值:填充缺失值(例如,零、平均值、中位数)或删除它们的行或列。
-
不相关的数据:删除那些没有为任务提供有用信息的属性(与特征工程相关)。
-
重构数据:可能包括以下操作(来自《数据整理原理》一书)
-
通过移动列重新排序记录字段
-
通过提取值创建新记录字段
-
将多个记录字段组合成一个记录字段
-
通过删除记录集过滤数据集
-
通过聚合和数据透视改变数据集的粒度和与记录关联的字段。
1.4 数据划分
数据划分 -将数据划分为训练 (80%)、验证和测试数据集,以在核心机器学习阶段使用以生成 ML 模型。
2 模型:机器学习流水线
ML 工作流程的核心是编写和执行机器学习算法以获得 ML 模型的阶段。模型工程流水线通常由数据科学团队使用,包括许多生成最终模型的操作。这些操作包括 模型训练、模型评估、模型测试和模型打包 。我们建议尽可能自动化这些步骤。
2.1 模型训练
模型训练 -将机器学习算法应用于训练数据以训练 ML 模型的过程。它还包括模型训练的特征工程和超参数调整。以下列表来自Aurélien Géron 的“Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow”
-
特征工程可能包括:
-
离散化连续特征
-
分解特征(例如,分类、日期/时间等)
-
添加特征转换(例如,log(x)、sqrt(x)、x2 等)
-
将特征聚合成有用的新特征
-
特征缩放:标准化或规范化特征
-
应该快速添加新功能,以便快速从功能构思到生产中运行的功能。进一步阅读“机器学习的特征工程。数据科学家的原则和技术”,作者:Alice Zheng,Amanda Casari
-
模型工程可能是一个迭代过程,包括以下工作流程:
-
每个 ML 模型规范(创建 ML 模型的代码)都应该经过代码审查并进行版本控制。
-
使用标准参数训练来自不同类别的许多 ML 模型(例如,线性回归、逻辑回归、K-Means、朴素贝叶斯、SVM、随机森林等)。
-
衡量和比较它们的表现。对于每个模型,使用N折交叉验证并计算 N 个性能度量的均值和标准差。
-
错误分析:分析 ML 模型产生的错误类型。
-
考虑进一步的特征选择和工程。
-
确定前三到五个最优的模型,首选会出现不同类型错误的模型。
-
使用交叉验证调整超参数。请注意,数据转换选项也是超参数。超参数的随机搜索优于网格搜索。
-
考虑集成方法,例如多数投票、bagging、boostig或stacking。组合 ML 模型应该比单独运行它们产生更好的性能。(进一步阅读周志华的《集成方法:基础与算法》)
2.2 模型评估
模型评估 -在将生产中的 ML 模型提供给最终用户之前,验证经过训练的模型以确保其满足原始业务目标。
2.3 模型测试
模型测试 ——一旦训练了最终的 ML 模型,就需要通过使用保留测试数据集来衡量其性能,以通过执行最终的“模型验收测试”来估计泛化误差。
2.4 模型打包
模型打包 -将最终 ML 模型导出为特定格式(例如 PMML、PFA 或 ONNX)的过程,它描述了业务应用程序要使用的模型。我们在下面的“ML 模型序列化格式”部分中介绍了 ML 模型打包。
2.5 不同形式的机器学习工作流程
操作 ML 模型可能会采用多种架构风格。在下文中,我们将讨论四种架构模式,这些模式分为两个维度:
-
ML 模型训练 和
-
ML 模型预测
为了简单起见,我们忽略了第三维 3. ML 模型类型 ,它表示机器学习算法的类型,例如有监督、无监督、半监督和强化学习。
我们执行ML 模型训练的方式有两种:
-
离线学习 (又名批处理或静态学习):模型是在一组已经收集的数据上训练的。部署到生产环境后,ML 模型在重新训练之前保持不变,因为模型会看到大量实时数据并变得陈旧。这种现象称为“模型衰减”,应仔细监测。
-
在线学习 (又名动态学习):随着新数据的到来,模型会定期被重新训练,例如作为数据流。对于使用时间序列数据(例如传感器或股票交易数据)来适应 ML 模型中的时间效应的 ML 系统,通常就是这种情况。
第二个维度是ML 模型预测,它表示 ML 模型进行预测的机制。这里我们也区分两种模式:
-
批量预测 :部署的 ML 模型根据历史输入数据进行一组预测。对于不依赖于时间的数据,或者当获得实时预测作为输出并不重要时,这通常就足够了。
-
实时预测 (又名按需预测):使用请求时可用的输入数据实时生成预测。
在确定了这两个维度之后,我们可以将机器学习模型运维分为四种 ML 架构模式:

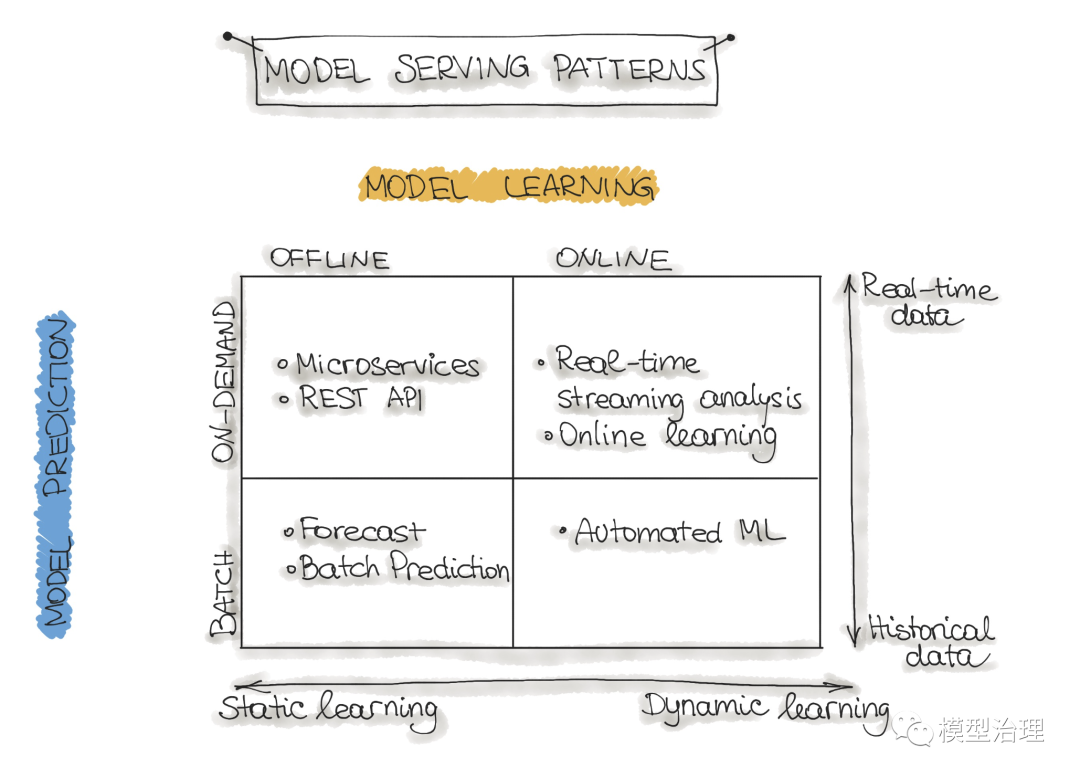
图源: https://www. quora.com/How-do-you-ta ke-a-machine-learning-model-to-production
下面我们将介绍模型架构模式,例如 预测(Forecast) 、 Web服务(Web-Service) 、 在线学习(Online Learning) 和 自动机器学习(AutoML) 。
预测
这种类型的机器学习工作流在学术研究或数据科学教育(例如,Kaggle 或 DataCamp)中广泛传播。这种形式用于试验 ML 算法和数据,因为它是创建机器学习系统的最简单方法。通常,我们获取一个可用的数据集,训练 ML 模型,然后在另一个(主要是历史)数据上运行这个模型,然后 ML 模型进行预测。这样,我们输出一个预测。这种 ML 工作流程不是很有用,因此在生产系统(例如移动应用程序)的行业环境中并不常见。
Web服务
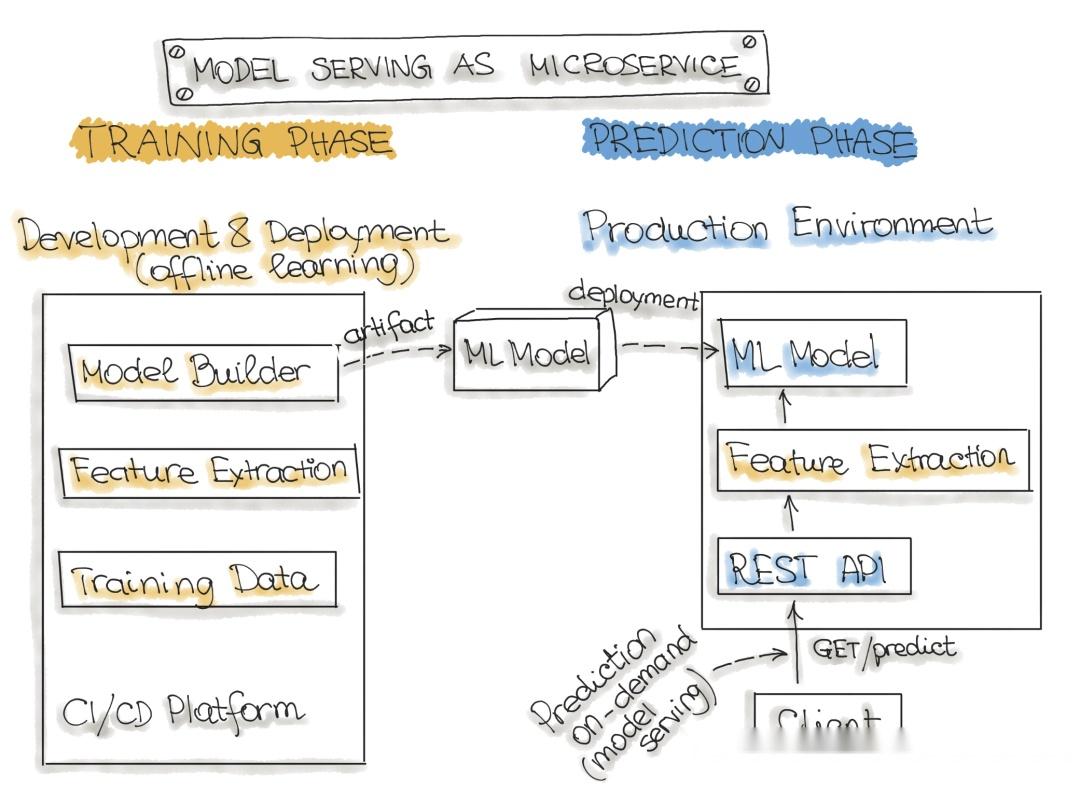
最常描述的 ML 模型部署架构是 Web 服务(微服务)。Web 服务获取输入数据并输出输入数据点的预测。该模型是根据历史数据离线训练的,但它使用实时数据进行预测。与预测(批量预测)的区别在于,ML 模型几乎实时运行,一次处理一条记录,而不是一次处理所有数据。Web 服务使用实时数据进行预测,但模型在重新训练并重新部署到生产系统之前保持不变。
下图说明了将训练模型包装为可部署服务的架构。请注意,我们在部署策略部分讨论了将经过训练的 ML 模型打包为可部署服务的方法。

在线学习
将机器学习嵌入生产系统的最动态方式是实施在线学习,也称为实时流式分析。请注意,在线学习可能是一个令人困惑的名称,因为核心学习或 ML 模型训练通常不在实时系统上执行。我们应该称之为增量学习;但是,在线学习这个术语已经在 ML 社区中确立。
在这种类型的 ML 工作流中,ML 学习算法不断地接收数据流,无论是作为单个数据点还是在称为 mini-batch 的小组中。系统会在新数据到达时即时了解新数据,因此机器学习模型正在逐步使用新数据进行重新训练。这种不断重新训练的模型可立即作为 Web 服务使用。
从技术上讲,这种类型的 ML 系统可以很好地与大数据系统中的 Lambda 架构配合使用。通常,输入数据是事件流,机器学习模型在数据进入系统时获取数据,提供预测并重新学习这些新数据。该模型通常会在 Kubernetes 集群或类似集群上作为服务运行。
在线学习系统在生产中的一大难点是,如果不良数据进入系统,ML 模型以及整个系统的性能将越来越下降。

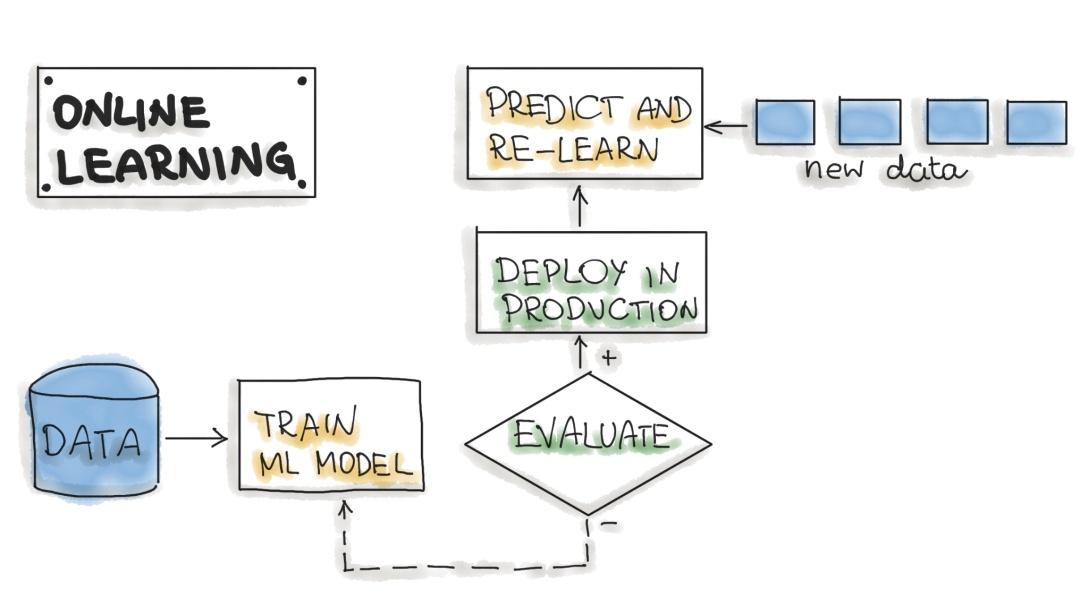
图源: https:// learning.oreilly.com/li brary/view/hands-on-machine-learning/9781492032632/ch01.html
自动机器学习
更复杂的在线学习版本是自动化机器学习或AutoML。
AutoML 受到了广泛关注,被认为是企业 ML 的下一个进步。AutoML 承诺在没有机器学习专业知识的情况下以最少的工作量训练 ML 模型。用户需要提供数据,AutoML 系统自动选择一种 ML 算法,例如神经网络架构,并配置选择的算法。
我们没有更新模型,而是在生产中执行整个 ML 模型训练管道,从而动态生成新模型。目前,这是实现 ML 工作流的一种非常实验性的方式。AutoML 通常由大型云提供商提供,例如Google或MS Azure。但是,使用 AutoML 构建的模型需要达到实际成功所需的准确度水平。
进一步阅读
-
AutoML:概述和工具: https://www. automl.org/automl/
2.6 ML 模型序列化格式
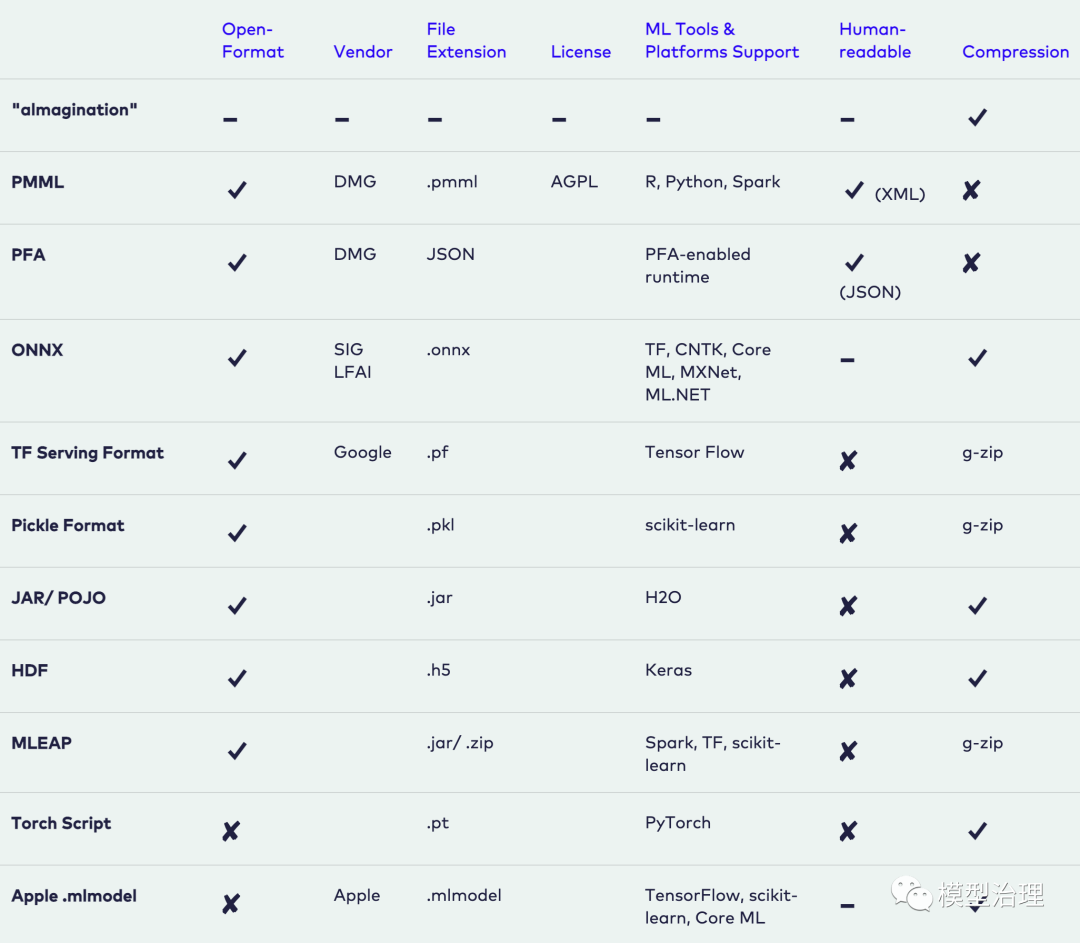
有多种格式可以分发 ML 模型。为了实现可分发的格式,ML 模型应该存在并且应该作为可执行的独立资产。例如,我们可能想在 Spark 作业中使用 Scikit-learn 模型。这意味着 ML 模型应该在模型训练环境之外工作。在下文中,我们描述了 ML 模型的与语言无关和特定于供应商的交换格式。
与语言无关的交换格式
-
合并是导出 ML 模型的最简单方法。模型和运行所需的所有代码捆绑为一个包。通常,它是一个单一的源代码文件,可以在几乎任何平台上作为独立程序编译。例如,我们可以使用SKompiler创建 ML 模型的独立版本。这个 python 包提供了一个工具,用于将经过训练的 Scikit-learn 模型转换为其他形式,例如 SQL 查询、Excel 公式、可移植的分析格式 (PFA) 文件或 SymPy 表达式。最后一个可以翻译成多种语言的代码,例如 C、Javascript、Rust、Julia 等。合并是一个简单的概念,导出的 ML 模型是可移植的。使用一些简单的 ML 算法,例如逻辑回归或决策树,这种格式紧凑并且可能具有良好的性能,这对于受限的嵌入式环境很有用。但是,ML 模型代码和参数需要一起管理。
-
PMML 是一种基于 XML 的模型服务格式,文件扩展名为 .pmml。PMML 已由Data Mining Group (DMG)标准化。基本上, .ppml描述了 XML 中的模型和管道。PMML 并不支持所有的 ML 算法,并且由于许可问题,它在开源驱动工具中的使用受到限制。
-
PFA(用于分析的便携式格式)旨在替代 PMML。根据数据挖掘组 DMG的定义:“PFA 文档是一串 JSON 格式的文本,描述了称为评分引擎的可执行文件。每个引擎都有一个明确定义的输入、一个明确定义的输出,以及用于组合输入以在以表达式为中心的语法树中构造输出的函数”。PFA 功能包括 (1) 控制结构,例如条件、循环和用户定义的函数,(2) 用 JSON 表示,因此可以很容易地由其他程序生成和操作,(3) 细粒度的函数库支持可扩展性回调。要将 ML 模型作为 PFA 文件运行,我们需要一个支持 PFA 的环境。
-
ONNX (Open Neural Network eXchange) 是一种独立于 ML 框架的文件格式。创建 ONNX 是为了允许任何 ML 工具共享单一模型格式。微软、Facebook 和亚马逊等许多大型科技公司都支持这种格式。一旦 ML 模型以 ONNX 格式序列化,它就可以被支持 ONNX 的运行时库(也称为推理引擎)使用,然后进行预测。在这里,您将找到可以使用 ONNX 格式的工具列表。值得注意的是,大多数深度学习工具都支持 ONNX。
来源:开放标准模型 https:// github.com/adbreind/ope n-standard-models-2019
供应商特定的交换格式
-
Scikit-Learn 将模型保存为 pickle python 对象,文件扩展名为 .pkl。
-
H2O 允许您将已构建的模型转换为 POJO(普通旧 Java 对象)或 MOJO(优化的模型对象)。
-
SparkML 模型可以保存为 MLeap 文件格式并使用 MLeap 模型服务器实时提供服务。MLeap 运行时是一个可以在任何 Java 应用程序中运行的 JAR。MLeap 支持 Spark、Scikit-learn 和 Tensorflow,用于训练管道并将它们导出到 MLeap Bundle。
-
TensorFlow 将模型保存为 .pb 文件;这是协议缓冲区文件扩展名。
-
PyTorch 使用其专有的 Torch 脚本作为 .pt 文件来为模型提供服务。它们的模型格式可以从 C 应用程序中获得。
-
Keras 将模型保存为 .h5 文件,科学界将其称为以分层数据格式 (HDF) 保存的数据文件。这种类型的文件包含多维数据数组。
-
Apple 拥有其专有的文件格式,扩展名为 .mlmodel,用于存储嵌入在 iOS 应用程序中的模型。Core ML 框架原生支持 Objective-C 和 Swift 编程语言。在其他 ML 框架(例如 TensorFlow、Scikit-Learn 和其他框架)中训练的应用程序需要使用诸如 coremltools 和 Tensorflow 转换器之类的工具将其 ML 模型文件转换为 .mlmodel 格式以在 iOS 上使用。
下表总结了所有 ML 模型序列化格式:

进一步阅读:
3 代码:部署流水线
交付机器学习项目的最后阶段包括以下三个步骤:
-
模型服务 -在生产环境中部署 ML 模型的过程。
-
模型性能监控 -根据实时和未知数据(例如预测或推荐)观察 ML 模型性能的过程。特别是,我们对特定于 ML 的信号感兴趣,例如与先前模型性能的预测偏差。这些信号可以用作模型重新训练的触发器。
-
模型性能日志 -每个推理请求都会产生一个日志记录。
下面,我们讨论模型服务模式和模型部署策略。
3.1 模型服务模式
当我们在生产环境中提供 ML 模型时,应考虑三个组件。推理是让模型摄取数据以计算预测的过程。这个过程需要一个模型、一个执行的解释器和输入数据。
将 ML 系统部署到生产环境包括两个方面,首先部署用于自动再训练的流水线和 ML 模型部署。其次,提供对未知数据进行预测的 API。
模型服务是将 ML 模型集成到软件系统中的一种方式。我们区分了将 ML 模型投入生产的五种模式: 模型即服务(Model-as-Service) 、 模型即依赖(Model-as-Dependency) 、 预计算(Precompute) 、 按需模型(Model-on-Demand) 和 混合服务(Hybrid-Serving) 。请注意,上述模型序列化格式可能用于任何模型服务模式。
以下分类显示了这些方法:

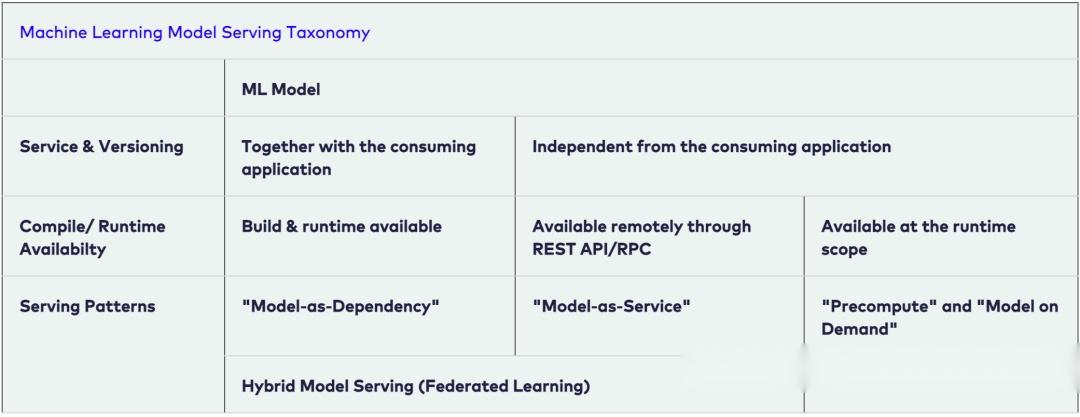
现在,我们介绍这几种模型服务模式。
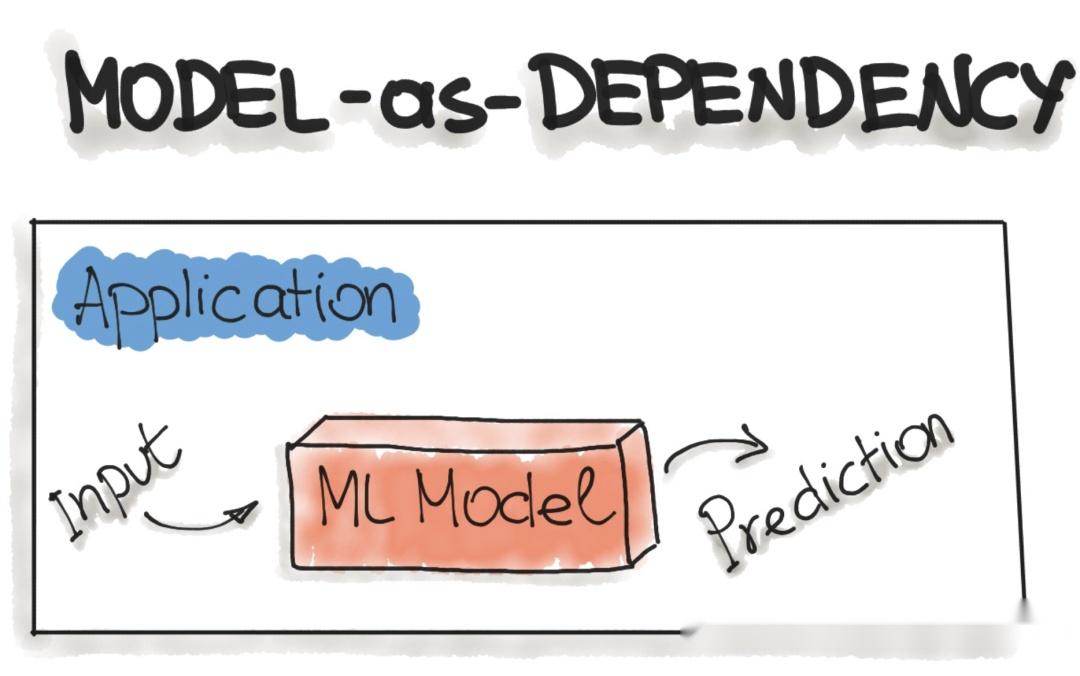
模型即服务
模型即服务是将 ML 模型包装为独立服务的常见模式。我们可以将 ML 模型和解释器包装在一个专用的 Web 服务中,应用程序可以通过 REST API 请求或作为 gRPC 服务使用。此模式可用于各种 ML 工作流,例如预测、Web 服务和在线学习。

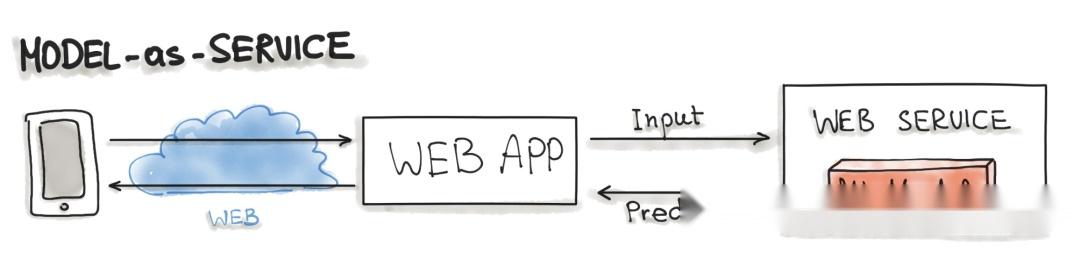
模型即依赖
Model-as-Dependency 可能是打包 ML 模型最直接的方法。打包的 ML 模型被视为软件应用程序中的依赖项。例如,应用程序通过调用预测方法并传递值来使用 ML 模型,就像传统的jar依赖项一样。这种方法执行的返回值是由先前训练的 ML 模型执行的一些预测。Model-as-Dependency 方法主要用于实现预测模式。

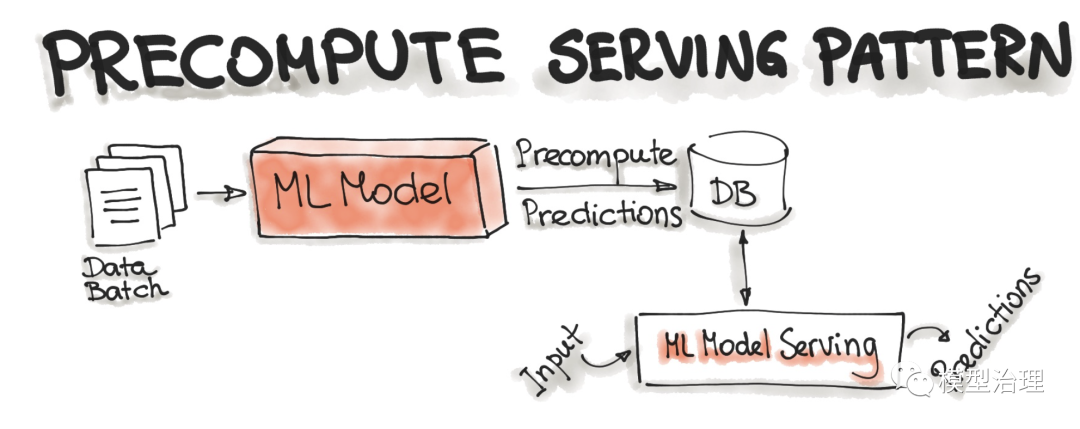
预计算服务模式
这种类型的 ML 模型服务与预测工作流密切相关。使用预计算服务模式,我们使用已经训练好的 ML 模型并预计算传入批次数据的预测。结果预测被保存在数据库中。因此,对于任何输入请求,我们都会查询数据库以获得预测结果。

进一步阅读:将 ML 投入生产 https://www. slideshare.net/mikiobra un/bringing-ml-to-production-what-is-missing-amld-2020
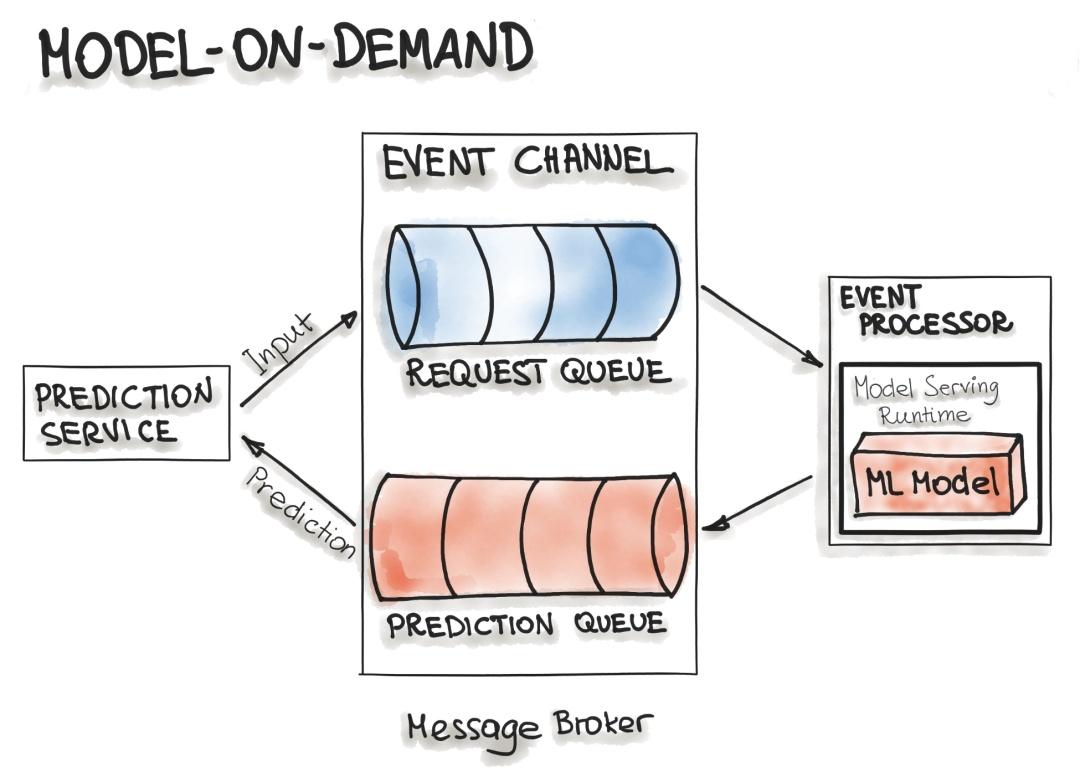
按需模型
Model-on-Demand 模式也将 ML 模型视为在运行时可用的依赖项。这种 ML 模型与 Model-as-Dependency 模式相反,它有自己的发布周期,并且是独立发布的。
消息代理架构通常用于这种按需模型服务。消息代理拓扑架构模式包含两种主要类型的架构组件:代理组件和事件处理器组件。代理组件是包含事件流中使用的事件通道的中心部分。包含在代理组件中的事件通道是消息队列。我们可以想象这样的架构包含输入和输出队列。消息代理允许一个进程在输入队列中写入预测请求。事件处理器包含服务运行时的模型和 ML 模型。此过程连接到代理,从队列中批量读取这些请求并将它们发送到模型以进行预测。模型服务进程对输入数据运行预测生成并将结果预测写入输出队列。之后,排队的预测结果被推送到发起预测请求的预测服务。

进一步阅读:
-
事件驱动架构 https:// learning.oreilly.com/li brary/view/software-architecture-patterns/9781491971437/ch02.html
-
用于实时机器学习端点的 Web 服务与流式传输 https:// towardsdatascience.com/ web-services-vs-streaming-for-real-time-machine-learning-endpoints-c08054e2b18e
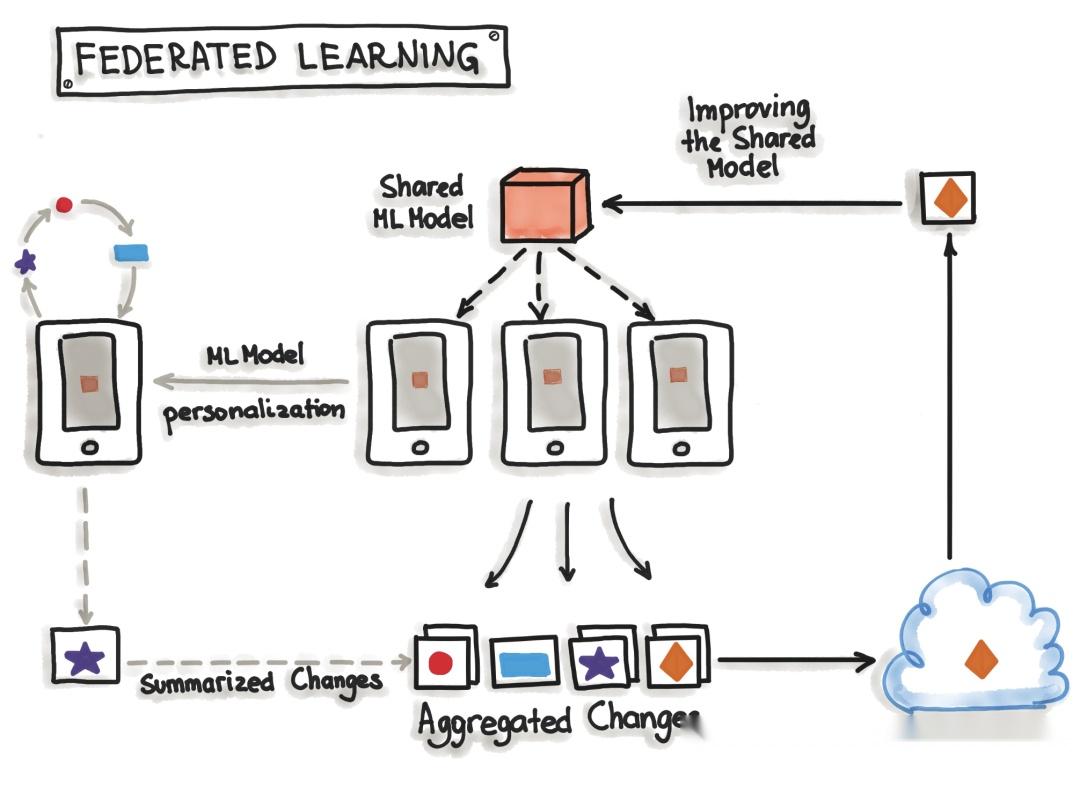
混合服务(联邦学习)
联邦学习,也称为混合服务,是向用户提供模型的另一种方式。它的方式是独一无二的,不仅有一个模型可以预测结果,而且还有很多。确切地说,除了保存在服务器上的模型之外,存在的模型数量与用户数量一样多。
让我们从服务器上独一无二的开始模型。服务器端的模型只用真实世界的数据训练一次。它为每个用户设置初始模型。此外,它是一个相对通用的训练模型,因此适合大多数用户。另一方面是用户侧模型,这是真正独特的模型。由于移动设备硬件标准的提高,设备可以训练自己的模型。这些设备将为自己的用户训练自己的高度个性化的模型。
有时,设备会将其已经训练好的模型数据(不是个人数据)发送到服务器。在那里,服务器模型将被调整,因此整个用户社区的实际趋势将被模型覆盖。该模型被设置为所有设备都在使用的新初始模型。由于对用户没有任何不利影响,当服务器模型得到更新时,这只发生在设备空闲、连接到 WiFi 并充电时。此外,测试是在设备上完成的,因此来自服务器的新采用的模型被发送到设备并测试功能。
这样做的最大好处是,用于训练和测试的数据是高度个性化的,不会离开设备,同时仍会捕获所有可用数据。通过这种方式,可以训练高度准确的模型,而不必在云中存储大量(可能是个人)数据。但是没有免费的午餐,正常的机器学习算法是在功能强大的硬件上使用同质的大型数据集构建的,这些硬件始终可用于训练。对于联邦学习,移动设备功能较弱,训练数据分布在数百万台设备上,而这些设备并不总是可用于训练。正是为此 TensorFlow Federated ( TFF)被提出来 。TFF 是为联邦学习创建的轻量级 TensorFlow。

图源: https:// ai.googleblog.com/2017/ 04/federated-learning-collaborative.html
3.2 部署策略
在下文中,我们将讨论将经过训练的模型包装为可部署服务的常用方法,即将 ML 模型作为Docker 容器部署到云实例和作为无服务器函数。
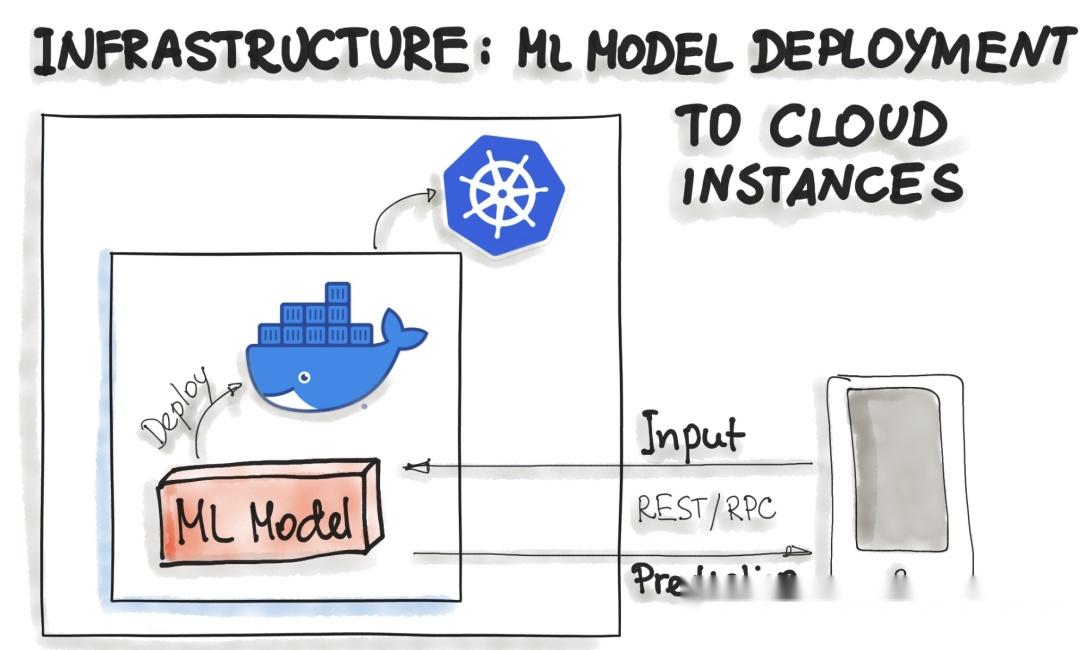
将 ML 模型部署为 Docker 容器
到目前为止,ML 模型部署还没有标准的、开放的解决方案。由于 ML 模型推理被认为是无状态的、轻量级的和幂等的,容器化成为交付的事实标准。这意味着我们部署了一个包含 ML 模型推理代码的容器。对于本地、云或混合部署,Docker 被认为是事实上的标准容器化技术。
一种普遍存在的方法是将整个 ML 技术堆栈(依赖项)和用于 ML 模型预测的代码打包到 Docker 容器中。然后 Kubernetes 或替代方案(例如 AWS Fargate)进行编排。然后,可以通过 REST API 使用 ML 模型功能,例如预测(例如,作为Flask 应用程序实现)

将 ML 模型部署为无服务器函数
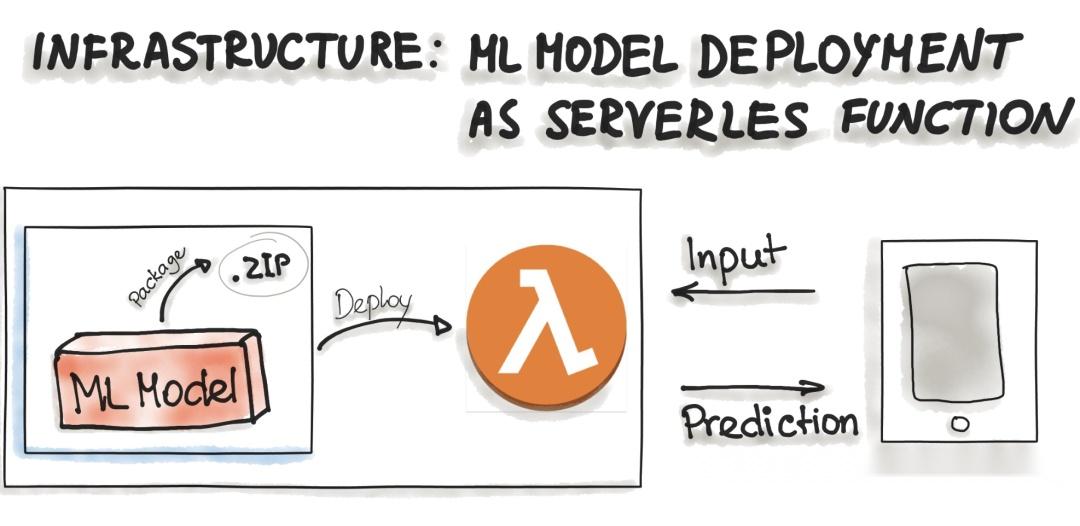
各种云供应商已经提供了机器学习平台,您可以使用他们的服务部署你的模型。例如 Amazon AWS Sagemaker、Google Cloud AI Platform、Azure Machine Learning Studio 和 IBM Watson Machine Learning 等等。商业云服务还提供 ML 模型的容器化,例如 AWS Lambda 和 Google App Engine servlet 主机。
为了将 ML 模型部署为无服务器函数,应用程序代码和依赖项被打包到 .zip 文件中,具有单个入口点功能。然后,此功能可由 Azure Functions、AWS Lambda 或 Google Cloud Functions 等主要云提供商管理。但是,应注意已部署制品的可能限制,例如制品的大小。

本文翻译自: https:// ml-ops.org/content/thre e-levels-of-ml-software