在机器学习的应用中,我们通常需要通过几个步骤才能进行最终的预测,我们如何能够知道哪一部分最值得我们花时间和精力去改善呢?这个问题可以通过上限分析来回答。
回到我们的文字识别应用中,我们的流程图如下:

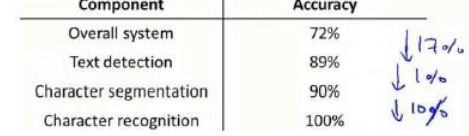
流程图中每一部分的输出都是下一部分的输入,上限分析中,我们选取一部分,手工提供 100%正确的输出结果,然后看应用的整体效果提升了多少。假使我们的例子中总体效果为 72%的正确率。
如果我们令文字侦测部分输出的结果 100%正确,发现系统的总体效果从 72%提高到了89%。这意味着我们很可能会希望投入时间精力来提高我们的文字侦测部分。
接着我们手动选择数据,让字符切分输出的结果 100%正确,发现系统的总体效果只提升了 1%,这意味着,我们的字符切分部分可能已经足够好了。
最后我们手工选择数据,让字符分类输出的结果 100%正确,系统的总体效果又提升了10%,这意味着我们可能也会应该投入更多的时间和精力来提高应用的总体表现。
本节目录1 问题描述2 滑动窗口3 获取大量数据集和人工数据4 上限分析1 问题描述图像文字识别应用所作的事是,从一张给定的图片中识别文字。这比从一份扫描文档中识别文字要复杂的多。为了完成这样的工作,需要采取如下步骤:1.文字侦测( Text detection) ——将图片上的文字与其他环境对象分离开来2.字符切分( Character segmentation) ——将文字分割成一个个单一的字符3.字符分类( Character classification) ——确定每一个字符是什么 可
吴恩达机器学习-12-大规模机器学习和图片文字识别OCR
本周是课程的最后一周,老师主要是介绍了两个方面的内容,一个是如何进行大规模的机器学习,另一个是关于图片文字识别OCR 的案例:
大规模机器学习
图片文字识别OCR
大规模机器学习(Large Scale Machine Learning)
在低方差的模型中,增加数据集的规模可以帮助我们获取更好的结果。但是当数据集增加到100万条的大规模的时候,我们需要考虑:大规模的训练集是否真的有必要。获取1.
计算机可以从图像或视频流中获取信息的过程属于计算机视觉领域。
文本识别服务是计算机视觉的一部分。也是当前最火的人工智能应用,文本识别服务可以识别收据、名片、文档照片等含文字的图片,将其中的文本信息提取出来。打开相机就可以轻松将图片或者实景中的文字转换为文字信息。
在寄快递场景下,通过识别上传的图片,能快速将收件人姓名、电话、收件人地址等重要信息填入对应位置
结合翻译功能做到实时拍照翻译,面对原本看不懂的菜单,看不懂的路标等等,使用这个功能,让用户在异国也不用担心看不懂文字,我们已经写好了
什么是OCR?
光学字符识别(Optical Character Recognition, OCR),是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。简而言之,检测图像中的文本资料,并且识别出文本的内容。
那么有哪些应用场景呢?
其实我们日常生活中处处都有ocr的影子,比如在疫情期间身份证识别录入信息、车辆车牌号识别、自动驾驶等。
18.应用实例:图片文字识别(Application Example: Photo OCR)
文章目录18.应用实例:图片文字识别(Application Example: Photo OCR)18.1 问题描述和流程图18.2 滑动窗口18.3 获取大量数据和人工数据18.4 上限分析:哪部分管道的接下去做
18.1 问题描述和流程图
       图像...
机器学习是一种通过算法和模型来让计算机从数据中学习和识别模式的领域。在机器学习中,文字识别是一个重要的应用领域,它能够将图像或文本中的文字信息转化为计算机可理解和处理的形式。
Matlab是一种功能强大的科学计算软件,它提供了许多用于机器学习和文字识别的工具和函数。
在文字识别中,Matlab可以使用图像处理和机器学习的方法来识别图像中的文字。首先,通过Matlab的图像处理工具,可以将图像进行预处理,如图像灰度化、二值化等,以便文字的轮廓和特征更加明显。
然后,可以使用Matlab的机器学习工具箱来训练一个模型,使其能够从图像中准确识别文字。通过提供标签的数据集,训练模型可以学习文字的特征和模式,并能够对新的图像进行准确的分类和预测。
Matlab还提供了许多常用的机器学习算法,如决策树、支持向量机和深度学习等,这些算法可以根据文字识别的需求灵活选择和使用。
总结而言,机器学习在文字识别中具有很大的应用潜力。Matlab作为一种强大的科学计算软件,提供了丰富的工具和函数,可以实现高效和准确的文字识别任务。通过结合机器学习和Matlab的能力,我们能够更好地处理和分析文字信息,为各种应用场景提供更好的解决方案。







