向量空间模型(Vector Space Model,VSM)是信息检索中最基础且最重要的文档相似度度量方法之一。VSM 的核心有两点:文档的表示方法和相似度计算方法。
对每个文档采用词袋(Bag of Words,BoW)假设,即用各个关键词在文档中的强度组成的矢量来表示该文档:
DF(m)为出现词m的文档总数目,N为总文档数目。
基于BoW的表示,可以计算相似度等。余弦距离可以不做归一化,欧氏距离不行。
在探索各种数据驱动的精细模型时,要先将它们与VSM 方法做比较。
梯度的几何意义是f在x点函数值上升最快的方向,因此它是一个与x维数相等的矢量。梯度下降更新公式
ϵ是学习率。
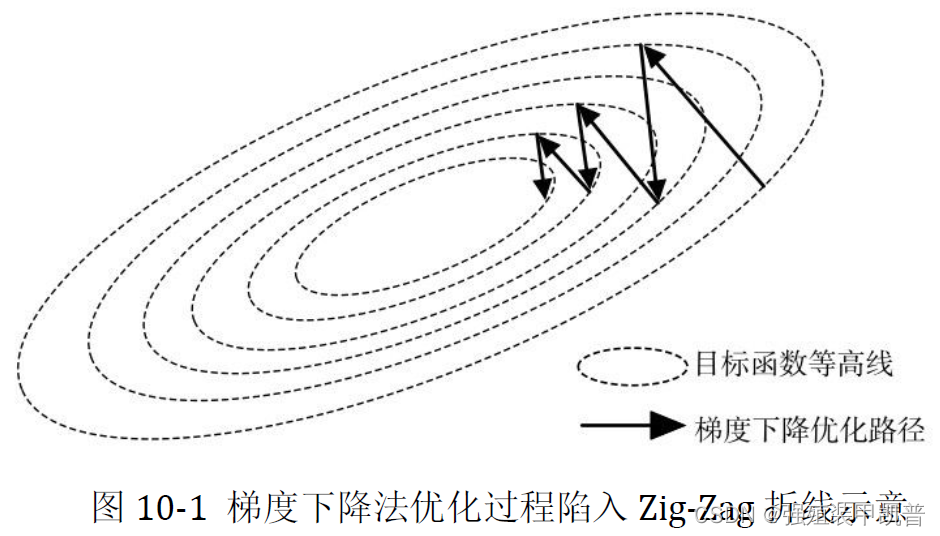
采用批处理模式的梯度下降法,当函数值对各个自变量归一化不够好时,优化过程会陷入Zig-Zag 折线更新的困境(不是圆)。在自变量维数很高时,这一问题尤为严重,因为我们无法一一检查各个自变量的意义,因此在某些维度上缩放尺度不一样是无法避免的。
二阶导是海森矩阵
\min_s m_k(s)=f(x_k)+\nabla^{\top}f(x_k)+\frac{1}{2}s^{\top}\nabla^2f(x_k)s \ \rm s.\rm t.\|s\|_2\le\delta_k
sminmk(s)=f(xk)+∇⊤f(xk)+21s⊤∇2f(xk)s s.t.∥s∥2≤δk
解得的s就是方向和步长。由于此过程没有对目标函数的一阶导和二阶导做近似,往往能够更准确地把握下降方向,因此有时能表现出比拟牛顿法更好的收敛性能。
对于置信半径
N1∑i=1Nu(xi)。
在给定充分统计量以后,最大似然估计过程与数据无关。根据充分统计量的形式,我们很容易得出,无论什么样的指数族分布,都只需要遍历一遍数据就可以得到最大似然解。
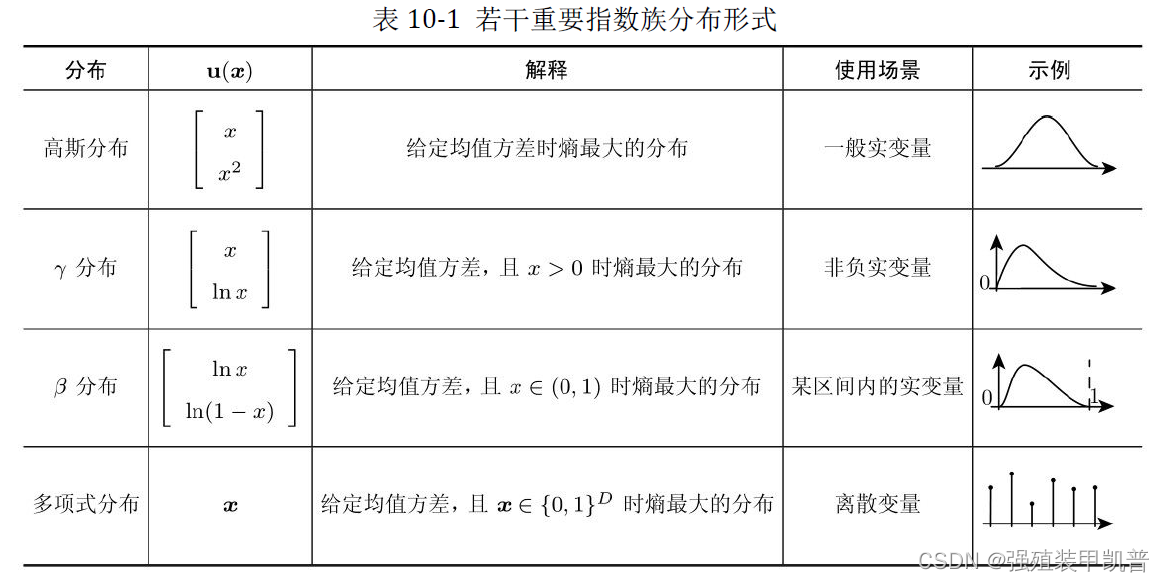
指数族分布的另一个重要特点——分布都是单模态(uni-modal)的,即分布从几何形态上看只有一个峰或者一个谷,实际的描述能力是有限的,并不适合于表达多种因素并存的随机变量。
最大似然准则是把模型的参数看成固定的,然后找到使得训练数据上似然值最大的参数,这是一种参数点估计(point estimation)的方法。这样的点估计方法在实际中如果遇到数据样本不足的情形,往往会产生比较大的估计偏差,就会用贝叶斯。
贝叶斯公式:
p(θ)。

概率统计模型有两个常见任务:一是参数估计(parameter estimation),二是预测(prediction)。其中第二项任务指的是给定一组训练数据X ,评估某新的观测数据o的概率。
在最大似然体系下,参数估计是根据似然值最大化得到的点估计,而预测过程就利用估计出来的参数计算似然值
p(o∣θ)即可。在贝叶斯体系下,参数的点估计被其后验分布所代替,也就意味着参数在估计结果中具有不确定性,于是在预测过程中,需要用积分的方式将参数的不同可能性都加以考虑,这是两者非常本质的区别。在最大后验概率(Maximum A Posterior,MAP)方法下,本质上仍然是点估计方法,只不过同样引入了先验部分对参数作规范化,因此,其参数估计形式上是对贝叶斯后验概率求极值,而预测过程则与最大似然情形一样。
对于先验分布的选择,这一点有两层含义:一是如何选择先验分布的形式,二是如何确定先验分布中的参数。后验分布才是在使用中最关键的,其形式如果过于复杂,会给实际应用带来很大困难。如果我们能够找到一种先验分布,使得相应的后验分布也具有同样的形式,无疑是方便的。满足这种条件的先验分布就称为共轭先验(conjugate prior)。
对于指数族分布的似然函数,共轭先验总是存在的。
- 对于高斯分布,如果仅仅考虑其均值的不确定性,对应的共轭先验仍然是高斯分布。
- 对于
γ分布,其对应的共轭先验称为维希特分布(Wishart distribution)。
- 对于多项式分布,其对应的共轭先验是狄利克雷分布(Dirichlet distribution)。
选择共轭的先验形式,从贝叶斯体系来看并没有太多理论上的必然性,这主要是为了满足工程上的方便性。
evidence是将模型参数积分后的似然值的期望,在似然值和先验部分的形式确定的前提下,evidence 仅仅是先验部分的函数。如果把evidence 认为是超参数对应的似然值,那么也可以用优化evidence的方式找到最优的超参数。这种根据数据来确定超参数的方法就称为经验贝叶斯。