1. 内生性来源
内生性问题 (endogeneity issue) 是指模型中的一个或多个
解释变量与误差项存在相关关系
。换言之,如果 OLS 回归模型中出现 ,则模型存在内生性问题,以致于 OLS 估计量不再是一致估计。进一步,内生性问题主要由以下四种原因导致。
1.1 遗漏变量
在实证研究中,研究者通常无法控制所有能影响被解释变量的变量,因此遗漏解释变量 (omitted variables) 是很常见的事情。假设 OLS 模型中解释变量为
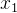 和
和
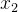 ,研究者遗漏的解释变量为
,研究者遗漏的解释变量为
如果遗漏的变量
对另一个解释变量
有影响,就会产生内生性问题。
1.2 选择偏差
选择偏差包括两种形式,即样本选择偏差 (sample selection bias) 和自选择偏差 (self-selection bias)。
样本选择偏差是指因
样本选择的非随机性
导致结论存在偏差,本质上也是一种遗漏变量问题 (Heckman,1979)。如果是采用类似 “抽签” 的随机方式获得的样本,其估计参数能很好地反映总体的性质。如果所抽取的方法不是随机的,那么无论样本容量有多大,根据这些样本数据估计的参数都不能准确反映总体的性质。
Heckma (1979) 在研究样本选择偏差的时候也意识到了自选择问题。他观察到直接比较管理培训生的工资和非培训生的工资也可能导致处理效应的有偏估计。存在自选择问题的模型中,可能存在某些
无法观测的变量同时影响了y 和x
。比如,在研究员工培训对工资的影响时,员工智力水平可能同时影响是否参加培训和员工工资。
1.3 双向因果
经济变量通常是相互依赖的,或者说是互为因果。上述现象也会导致内生性问题。比如,在估计需求曲线时,价格p 是需求模型中的内生解释变量
1.4 测量误差
当模型使用数据和真实数据存在误差,且满足 CEV 假定时,则会影响估计量的一致性,产生内生性问题。当只有一个解释变量时,CEV 假定下的测量误差将导致 OLS 估计量产生向 0 的偏误,也称为衰减偏误。当模型存在多个解释变量时,其中一个解释变量的测量误差导致 OLS 估计量发生方向不确定的偏移。
2. 内生性的解决方法
2.1 工具变量法
工具变量法 (IV) 可以解决遗漏变量、样本选择、双向因果和测量误差这四种违背经典线性回归假定情况的内生性问题。一般来讲,如果确定研究中
存在内生性问题,又无法确定产生原因
,可以考虑使用工具变量法。
工具变量法 (IV) 和 两阶段最小二乘法 (TSLS) 都属于 GMM。IV 只是 TSLS 的特例,即 IV 的工具变量个数和内生变量个数相等。当工具变量个数大于内生变量个数时,需要对各工具变量加以权重进行拟合,这时候就需要 TSLS。
相关参考文献:
-
Mauro P. Corruption and growth[J]. The quarterly journal of economics, 1995, 110(3): 681-712. -PDF-
-
沈坤荣, 李莉. 银行监管: 防范危机还是促进发展?——基于跨国数据的实证研究及其对中国的启示[J]. 管理世界, 2005, 10: 6-23. -Link-
-
何玉梅, 孙艳青. 不完全契约, 代理成本与国际外包水平——基于中国工业数据的实证分析[J]. 中国工业经济, 2011, 12: 57-60. -Link-
2.2 自然实验法
自然实验法指的是在研究中,因为某些外部事件使得研究对象被随机分成了实验组和对照组。其关键在于寻找一个影响被解释变量而不影响解释变量的
外部事件
。自然实验法本质上是一种观察实验,它是现场和实验室实验之外的另一种选择。
Fuchs-Schündeln 和 Hassan (2016) 将 “自然实验” 中的 “自然” 定义为 “研究人员没有有意识地设计要分析的情节,但仍然可以利用它来学习因果关系。”
也许二战后影响最大的自然实验是德国 1949 年的东西分裂和 1989 年的东西德合并。“柏林墙” 将大量的人口分为生活在不同经济环境下两部分,这相对于人的偏好、经济条件等其他因素是外生的。有很多宏观和微观经济研究是基于这一自然事件。例如:
-
Fuchs-Schündeln 和 Schündeln (2005) 首先利用这个实验研究了基于风险规避的职业自我选择,及其对预防性储蓄的影响;
-
Fuchs-Schündeln 和 Alesina (2007) 利用 “柏林墙” 研究经济政策的内生性偏好;
-
Redding 和 Sturm (2008) 研究了市场准入的重要性;
-
Burchardi 和 Hassan (2013) 研究了社会关系对经济的影响。
除此之外,在永久收入假设的背景下,Fuchs-Schündeln (2008) 认为德国统一对东德人来说是一个巨大的、积极的、永久性的收入冲击,分析了生命周期消费模型的有效性,得出了关于东德人和西德人的储蓄行为的三个类型化特征,并发现强有力的证据支持理性的、前瞻性的储蓄的行为。
相关参考文献:
-
Fuchs-Schündeln N, Hassan T A. Natural experiments in macroeconomics[M]//Handbook of macroeconomics. Elsevier, 2016, 2: 923-1012. -PDF-
-
Fuchs-Schündeln N, Schündeln M. Precautionary savings and Self-Selection: Evidence from the german reunification “Experiment”[J]. The Quarterly Journal of Economics, 2005, 120(3): 1085-1120. -PDF-
-
Alesina A, Fuchs-Schündeln N. Goodbye Lenin (or not?): The effect of communism on people's preferences[J]. American Economic Review, 2007, 97(4): 1507-1528. -PDF-
-
Redding S J, Sturm D M. The costs of remoteness: Evidence from German division and reunification[J]. American Economic Review, 2008, 98(5): 1766-97. -PDF-
-
Burchardi K B, Hassan T A. The economic impact of social ties: Evidence from German reunification[J]. The Quarterly Journal of Economics, 2013, 128(3): 1219-1271. -PDF-
-
Fuchs-Schundeln N. The response of household saving to the large shock of German reunification[J]. American Economic Review, 2008, 98(5): 1798-1828. -PDF-
2.3 处理效应模型
在经济学中评估项目或政策实施效果是一类很重要的研究,此类研究又被称为项目效应评估或政策效应分析。上述研究主要使用的是处理效应模型。它包含一个
内生的指示变量
,通常和自然科学实验一样分为实验组和对照组 (D=1 或 0),由于实验组和对照组成员初始条件不同,会产生选择偏差 (selection bias)。
处理效应模型与 TSLS 两阶段最小二乘法的区别在于,由于
内生解释变量是虚拟变量
,处理效应模型第一阶段回归不使用 OLS 回归,而是使用 Logit 或 Probit 回归计算出 hazard ratio,在第二段回归中加入 hazard ratio 调整偏误。Imbens 和 Wooldridge (2009) 总结了评估政策和项目的因果效应的研究方法和历史。
Angrist (1994) 提出了
局部平均处理效应
local average treatment (LATE),框架类似于 Rubin (1974, 1990) 和 Heckman (1990)。Angrist (1990) 曾使用越南时期的兵役抽签 Draft Lottery 来估计退伍军人地位对收入的影响,工具变量是随机分配到出生日期的抽签号码(号码被用于确定征兵的优先级,于是服兵役的概率与抽签号码有关)。是否服兵役形成了实验组和对照组。他认为退伍军人身份的平均影响是那些本来会以低抽签号码服兵役的男性,而不是以高抽签号码服兵役的男性。
胡吉祥等 (2011) 研究国有企业上市对绩效的影响时,将公开上市视为对于企业实施的一个处理,按参与上市与否将企业划分为处理组和控制组, 通过估计上市的 ATE 或处理组中的 ATT 来衡量上市对国有企业绩效的效果。
王德文等 (2008) 借助政府实施农村迁移劳动力就业服务和培训计划将农村迁移劳动力是否接受培训分为两组,使用平均处理效应模型应对劳动力是否参加培训存在的个人选择问题。
相关参考文献:
-
Imbens G W, Wooldridge J M. Recent developments in the econometrics of program evaluation[J]. Journal of economic literature, 2009, 47(1): 5-86. -PDF-
-
Angrist J, Imbens G. Identification and estimation of local average treatment effects[J]. 1995. -PDF-
-
Angrist J D. Lifetime earnings and the Vietnam era draft lottery: evidence from social security administrative records[J]. The American Economic Review, 1990: 313-336. -PDF-
-
胡吉祥, 童英, 陈玉宇. 国有企业上市对绩效的影响: 一种处理效应方法[J]. 经济学 (季刊), 2011, 10(3). -Link-
-
王德文, 蔡昉, 张国庆. 农村迁移劳动力就业与工资决定: 教育与培训的重要性[J]. 经济学 (季刊), 2008, 7(4). -Link-
2.4 Heckman 模型
Heckman 两阶段模型主要是针对性
解决样本选择偏误 (sample selection bias) 导致的内生性问题
。Heckman 模型解决的样本选择问题,是由于被解释变量
部分观测值的缺失/不可观测
导致的。而处理效应模型主要针对核心解释变量为内生虚拟变量的情况,并且处理效应模型中的 y 值都是可观测的。
Heckman 模型分两阶段,第一步使用 Probit 回归模型,并根据回归结果计算逆米尔斯比 (IMR),第二步是将 IMR 带入模型进行回归。Heckman (1979) 使用了 Heckman 模型估计女性劳动供给和工资率水平。该模型在近些年的研究也有不少应用,例如:
-
Weigelt (2013) 研究了客户公司如何在市场安排下从供应商的 IT 能力中获得性能收益,以及公司在 IT 业务内包和外包的不同情况下,供应商的 IT 能力和公司运营能力交互效应对公司业绩的影响。文章第一阶段采用 Probit 模型对公司 IT 业务内包或是外包发生的可能性进行估计,并从中得到 IMR;第二阶段将样本拆分为内包组和外包组进行分组回归,并加入 IMR 来修正样本自选择偏差;
-
石晓军和王骜然 (2017) 在研究双层股权制度对企业创新的影响时,为了处理部分企业没有 R&D 支出导致的样本偏差,使用 Probit 模型对是否进行 R&D 投入进行回归,并计算逆米尔斯比率比率。之后,将逆米尔斯比率带入模型进行回归;
-
陈作华和刘子旭 (2019) 在研究政企关系对民营企业特质风险的影响时,使用了 Heckman 法控制可能存在的自选择问题。由于民营企业建立的政企关系可能内生于其所处环境和自身特征,这些因素也可能影响企业的特质风险。他们使用了民营企业家是否参政议政建立虚拟变量,将政企关系作为被解释变量,可能影响政企关系的变量作为解释变量并进行 Probit 回归来估计民营企业建立政企关系的概率,从而得到逆米尔斯比率比率。
相关参考文献:
-
Heckman J J. Sample selection bias as a specification error[J]. Econometrica: Journal of the econometric society, 1979: 153-161. -PDF-
-
Weigelt C. Leveraging supplier capabilities: The role of locus of capability deployment[J]. Strategic Management Journal, 2013, 34(1): 1-21. -Link-
-
石晓军, 王骜然. 独特公司治理机制对企业创新的影响———来自互联网公司双层股权制的全球证据[J]. 经济研究, 2017, 52(1): 149-164. -Link-
-
陈作华, 刘子旭. 政企关系与企业特质风险[J]. 管理科学, 2019, 32(4): 48-61. -Link-
2.5 引入固定效应
固定效应模型在面板数据建模中被广泛使用。顾名思义,固定效应是不随时间或个体变化的因素,它是难以观测的。模型中之所以要加入固定效应,是因为这些因素可能与解释变量相关,如果包含在扰动项中则会产生内生性问题。
Flannery(2006)建立了公司向目标资本结构动态调整的模型。方程如下;
其中目标资本结构为:
方程整理后,加入公司固定效应:
在此之前,Fama 和 MacBeth 也进行过类似研究,但没有在方程中加入固定效应。除了控制个体的固定效应,研究中还经常引入时间的固定效应,即只与时间相关、不随个体变化的因素,如经济环境等。这样的模型被称为双向固定效应模型。例如:
-
曹廷求和张光利 (2020) 在研究公司自愿信息披露对股价崩盘风险的影响时,同时控制了了个体、时间 (季度和年度) 固定效应;
-
蔡庆丰等 (2020) 研究信贷可得性与企业创新的关系时,入了行业、年份和企业的固定效应;
-
高晶晶等 (2019) 探究影响农户化肥使用量高低的因素时,为了削弱内生性,模型中控制了年份和个体的固定效应。
需要说明的是,固定效应模型只能消除部分的内生性,因此它通常与工具变量法、倍分法等其他内生性处理方法混合使用。如工具变量需要与扰动项无关,且与内生解释变量强相关。前一个条件(外生性)往往很难满足。加入固定效应后,扰动项中部分内生因素被剔除,此时再引入工具变量时,外生性条件更容易被满足,工具变量的质量提高。
相关参考文献:
-
Flannery M J, Rangan K P. Partial adjustment toward target capital structures[J]. Journal of financial economics, 2006, 79(3): 469-506. -PDF-
-
曹廷求, 张光利. 自愿性信息披露与股价崩盘风险:基于电话会议的研究[J]. 经济研究, 2020, 55(11):191-207. -Link-
-
蔡庆丰, 陈熠辉, 林焜. 信贷资源可得性与企业创新: 激励还是抑制?——基于银行网点数据和金融地理结构的微观证据[J]. 经济研究, 2020. -Link-
-
高晶晶, 彭超, 史清华. 中国化肥高用量与小农户的施肥行为研究——基于 1995~ 2016 年全国农村固定观察点数据的发现[J]. 管理世界, 2019, 35(10): 12. -Link-
2.6 广义矩估计
动态面板模型是解释变量中包含被解释变量滞后项的模型,可以理解成过去会在某种程度上影响未来的模型。当用差分去除模型中的固定效应时,方程中滞后项的差分便与扰动项的差分相关,产生内生性 (短面板中难以消除,所以也称短面板偏误)。GMM 估计方法通过引入滞后两期及以上的滞后项作为工具变量,并尽可能地满足所有矩条件,得到一个较好的估计量。实质上,GMM 也是工具变量法。
GMM 包含多种形式。估计差分模型的为差分 GMM,采用水平方程的为水平 GMM,联立差分和水平方程的为系统 GMM。其中差分 GMM 和系统 GMM 使用更加广泛。田国强和李双建 (2020) 在研究经济不确定性对银行流动性创造的影响时,首先采用了不包含银行流动性滞后项的静态面板模型。后考虑到银行流动性具有自相关性,模型加入了流动性的滞后变量,采用差分和系统 GMM 估计排除动态面板偏误的影响。
相关参考文献:
-
Blundell R, Bond S. GMM estimation with persistent panel data: an application to production functions[J]. Econometric reviews, 2000, 19(3): 321-340. -PDF-
-
Flannery M J, Rangan K P. Partial adjustment toward target capital structures[J]. Journal of financial economics, 2006, 79(3): 469-506. -PDF-
-
田国强, 李双建. 经济政策不确定性与银行流动性创造:来自中国的经验证据[J]. 经济研究, 2020, 55(11):19-35. -Link-
-
张宗新, 缪婧倩. 基金流量与基金投资行为——基于动态面板数据模型的实证研究[J]. 金融研究, 2012, 4: 110-123. -Link-
2.7 断点回归
断点回归的思路是研究某一断点处的政策效应,因为在特定断点处,实验组和对照组可以认为是本质上差异不大的。
Cattaneo (2015) 研究州议员选举中的在任者优势时,认为在任者可能拥有更高的知名度、阻止反对党的能力和信息优势,可能帮助其在选举中获胜。但是这其中存在内生性问题,即在任者可能本来就具有更强的能力,拥有更高的胜选机会。因此,文中选择以得票率等于50% 为断点,断点附近的选举中候选人之间得票比率相差较小,表示其能力相差不大,由此剔除了内生因素。
田文佳等 (2019) 研究工业用地出让价格与官员晋升激励程度的关系时,认为官员为了晋升,可能会压低地块出让价格来吸引企业投资,达到提高经济绩效的效果。模型以官员任职时间作为晋升激励大小的代理解释变量,用工业用地出让对其回归。为了消除不可测的地理因素对地块本身价值的影响,文章使用城市边界附近的地块作为样本,设计了断点回归。
断点回归分为清晰断点回归和模糊断点回归,区别是断点是否能完全分割实验组和对照组。上述官员晋升激励的研究中,城市边界能完全区分地块所述城市,因此为清晰断点回归。
刘生龙等 (2016) 研究 1986 年义务教育法的出台对教育经济回报率的影响,认为出生日期在 1971 年 9 月之后的样本会受到义务教育法影响 (15 岁),之前的则不会,因此可以作为断点。而考虑到不是所有人都严格完成九年义务教育,该断点并不能完全分开是否受影响的人群,所以文章采用模糊断点回归,采用两阶段最小二乘法估计。
相关参考文献:
-
Cattaneo M, Frandsen B, Titiunik R. Randomization inference in the regression discontinuity design: An application to the study of party advantages in the US Senate[J]. Journal of Causal Inference, 2014, 3(1), 1-24. -PDF-
-
田文佳, 余靖雯, 龚六堂. 晋升激励与工业用地出让价格——基于断点回归方法的研究[J]. 经济研究, 2019, 10. -Link-
-
刘生龙, 周绍杰, 胡鞍钢. 义务教育法与中国城镇教育回报率: 基于断点回归设计[J]. 经济研究, 2016, 2: 154-167. -Link-
2.8 倾向得分匹配模型
倾向得分匹配模型 (propensity score matching,PSM) 类似于多元线性回归。不过多元线性回归 (MR) 的无偏估计依赖于函数形式的正确设定,否则会出现函数形式误设 (functional form misspecification,FFM) 导致估计量有偏。PSM 模型通过匹配可以减少对函数形式的依赖,放松对多元回归模型的线性假设,进而缓解 FFM 问题。
关于 PSM 方法有三个误区:
-
一是 PSM 方法并没有从根本上解决由选择偏差或遗漏变量导致的内生性问题,更不能代替 Heckman 和 IV 等方法用于解决自选择、遗漏变量等问题;
-
二是 PSM 不能被称为 “准实验”,也无法模拟实验条件;
-
三是 PSM 的外部有效性问题。在 “共同支撑假设 (Common Support)”无法满足或很牵强的情况下,PSM 会系统排除缺乏对照组的样本,进而使得样本代表性变差,影响结果的外部有效性。
关于 PSM 更多详细介绍,请参考连享会推文「Stata:PSM-倾向得分匹配分析的误区」。
徐尚昆等 (2020) 在研究企业家在国有企业的工作经历对其企业成长的影响时,为了排除有能力的人 “更有可能进入国有企业工作” 这一自选择偏误,使用了临近匹配和核匹配两种 PSM。不过在这一研究中,作者也强调了 PSM 只能缓解由于可观测变量带来的内生性问题,无法处理最为关键的不可观测变量带来的内生性。
相关参考文献:
-
徐尚昆, 郑辛迎, 杨汝岱. 国有企业工作经历, 企业家才能与企业成长[J]. 中国工业经济, 2020, 1. -Link-
1. 内生性来源内生性问题 (endogeneity issue) 是指模型中的一个或多个解释变量与误差项存在相关关系。换言之,如果 OLS 回归模型中出现,则模型存在内生性问题,以致于 OLS 估计量不再是一致估计。进一步,内生性问题主要由以下四种原因导致。1.1 遗漏变量在实证研究中,研究者通常无法控制所有能影响被解释变量的变量,因此遗漏解释变量 (omitted variables) 是很常见的事情。假设 OLS 模型中解释变量为和,研究者遗漏的解释变量为如果遗漏的变量...
This chapter discusses how applied researchers in corporate finance can address endogeneity concerns. We begin by reviewing the sources of endogeneity— omitted variables, simultaneity, and measurement error— and their implications for inference. We then discuss in detail a number of econometric techniques aimed at addressing endogeneity problems including: instrumental variables, difference-in-differences estimators, regression discontinuity
design, matching methods, panel data methods, and higher order moments estimators. The unifying themes of our discussion are the emphasis on intuition and the applications to corporate finance.
遗漏变量是指可能与解释变量相关的变量,本来应该加以控制,但却没有控制的变量。这些变量最后进入了误差项,从而导致误差项与解释变量相关,进而导致了
内生性
问题
。
联立性是指一个计量方程中的核心解释变量A对被解释变量B产生影响,反过来,被解释变量B又对A产生影响。
如果B对A有正向的影响,正向冲击就会导致A增加,从而导致核心解释变量A与误差项正相关。
如果B对A有负向的影响,正向
对于在作用域中的变量,作用域决定了它的可见性和“存在时间”。
作用域是由花括号的位置决定的。Java用一对大括号作为语句块的范围,称为作用域,在作用域定义的变量,只能在该作用域结束前使用。
在JAVA中,变量作用域分为四个等级:类级,对象实例级,方法级,块级。
类级变量称为全局变量或者静态变量,需要用static关键字修饰。类级变量在类定义后就已经存在,占用内存空间,可以通过类名访问,不需要实例化。
对象实例级变量,是成员变量,实例化后才分配内存空间,才能访问。成员变量定义在方法之外,类之内的。成员变量随
这期推送简单介绍一下样本选择模型和处理效应模型,其中样本选择模型是一般意义上的Heckman两步法,后者则借鉴了Heckman两步法的构建思想,但又不完全等同于前者。模型介绍之后,将利用help文件中的示例数据与代码简单演示一下这两个模型在Stata中的具体操作,然后简单评述一下现阶段文献中对这两个模型的理解与应用情况,最后结合一篇论文的公开数据与代码进行结果复盘与二次验证。
Note:Note:Note: 1、下划线字体为链接,可点击跳转;2、推文中的公式与代码块均可左右滑动;3、该文首发于微信公众号D
面板数据的
内生性
问题
是指面板数据模型中存在的
内生性
(即内部因果关系)的困扰。
内生性
可能会导致估计结果偏误和无效性。为了
解决
这个
问题
,Stata提供了一些命令和方法。
1. 第一种方法是使用工具变量(Instrumental Variables, IV)来
解决
内生性
问题
。在Stata中,可以使用命令ivregress或者ivreg2来进行工具变量回归分析。这些命令可以帮助你估计一个内生变量对一个外生变量的影响,同时控制其他相关变量。
2. 第二种方法是进行固定效应模型(Fixed Effects Model)或随机效应模型(Random Effects Model)估计。Stata提供了命令xtreg用于面板数据的固定效应和随机效应模型估计。这些命令可以帮助你控制个体固定效应或者随机效应,并
解决
内生性
问题
。
3. 此外,Stata还提供了其他一些面板数据模型估计命令,如xtivreg、xtivreg2等,可以用于处理更复杂的面板数据模型,包括同时存在
内生性
和工具变量的情况。
需要注意的是,选择合适的方法来
解决
面板数据
内生性
问题
需要根据具体
问题
和模型的特点进行判断和选择。在使用这些Stata命令时,建议查阅相关文档和学习资料,以确保正确地应用这些命令来
解决
内生性
问题
。
2301_76990854:

