


SparkSQL数据分析项目---数据统计工作

前面我写了好多篇关于大数据的文章,这次就用真实的网站日志数据做一次分析,也是为了把前面所有的文章内容做一个汇总和复习。也能更深刻的理解如何使用SparkSQL进行离线统计和分析。
往期文章:
Spark生态圈 ; Spark环境部署篇 ;
SparkSQL基于真实数据的分析项目
*用户行为日志概述
注:为什么要记录用户的行为日志?记录下来的行为日志内容有包括了哪些?如何进行记录以及对这些记录进行统计分析的意义在哪里。
*离线数据处理架构
注:数据如何采集,采集之后如何清洗,对功能需求的一个统计和处理,最终把结果写到库里面去,然后通过可视化的方式进行一些展示。
*项目需求
*项目指标
*项目统计
*可视化分析展示
*Spark on Yarn
*性能调优
No. 1 用户行为日志概述
1、为什么要记录用户访问行为日志
注:用户行为日志:用户每次访问网站时所有的行为数据(访问、浏览、搜索、点击...)、用户行为轨迹、流量日志....
- 网站页面的访问量
- 网站的粘性
- 推荐(比如某宝某东,如果你最近关注或者和购买某些产品,他们会给你推荐相关产品,这个应该大部分人都有这个经历,然后会给你打上一个标签,比如你家最近在装修,你最近结婚,你最近买车了等等等等)
总而言之记录用户行为日志是为了让我们更好的分析网站运作情况,为什么要分析,那是因为任何一个网站他都有自己的目标,都有自己存在的意义和目的。其实说白了就是要赚钱。那么通过对网站各项数据的分析以及通过分析得到相应的可执行的建议或计划能够更加快速的达到网站的目的。所以说记录用户行为数据那是和赚钱息息相关的啊,你说重要不重要?当然赚钱是一个很大很复杂的目标,我们需要拆分成很多很多的小目标以及很多可执行的动作。后面我们再聊。
2、用户行为日志产生渠道
1)Nginx(网站web服务器所记录的web的访问日志)
2)Ajax(在页面中嵌入的一些JS的代码来获取用户访问记录,比如你鼠标的悬停位置,ajax可以把你这些动作信息发到后台)
3、用户行为日志内容
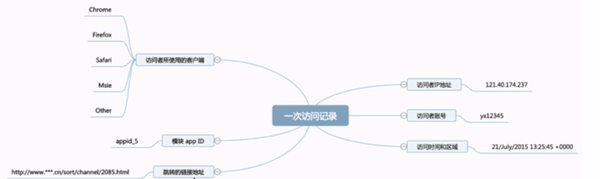
我们看看这张图,这是一次访问记录。在这个记录里面有哪些信息我们看。
1、你的IP地址
2、用户的账号
3、访问的时间和区域
4、用户使用的客户端(Chrome、Fiefox、safari、Msle、ios......)
5、你访问的模块
6、从哪里跳转过来的
以上是一个一般的用户日志内容,这些内容其实都是我们可以配置的,你只要在Nginx上作出相应的配置。
日志数据内容:
1)访问的系统属性: 操作系统、浏览器等等
2)访问特征:点击的url、从哪个url跳转过来的(referer)、页面上的停留时间等
3)访问信息:session_id、访问ip(访问城市)等
4、用户行为数据分析的意义
1、网站的眼睛
通过分析我们可以知道访问者来自哪里,用户在找什么东西,那些页面最受欢迎,用户是从哪里进来的就是我们的referer,比如你在百度做了一些推广,你付钱了,那么一个月到底从百度引流了多少,如果成本大于你的回报,那你还有必要再往百度投钱嘛?对不对。
2、网站的神经
为什么说网站分析是网站的神经,是因为网站用户行为分析它让你了解到网站的健康状况,网站页面的表现如何,页面布局合理吗?网站导航清晰吗?那个功能存在问题?哪里需要调整。
3、网站的大脑
网站数据分析让我们在完成目标的过程中合理的去分配资源和预算,比如我们说的广告的投入之类的,并通过优化不断提高网站表现,也就是说你要考虑投资回报率(ROI),在现有的情况下如何合理的分配预算和资源是很重要的。比如有些城市对某一类产品的访问量非常的高,那我们是不是要针对这个城市加大对某一类产品的推广力度从而达到回报最大化的一个目的。相反的如果这个城市对另外一类产品访问量很低或者说用户都不感兴趣,那我们是不是相应的要减小这一类产品在这个城市的推广力度呢?
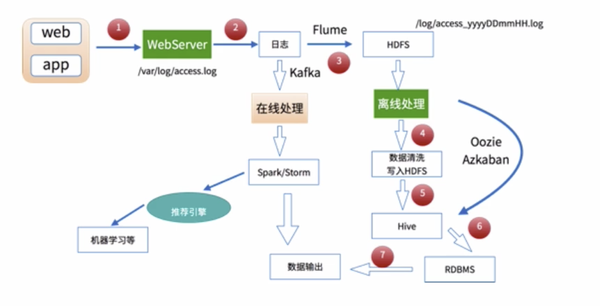
No. 2 离线数据处理架构
数据处理流程
1)数据采集
Flume: web日志写入到HDFS
2)数据清洗
脏数据
Spark、Hive、MapReduce 或者是其他的一些分布式计算框架
清洗完之后的数据可以存放在HDFS(Hive/Spark SQL)
3)数据处理
按照我们的需要进行相应业务的统计和分析
Spark、Hive、MapReduce 或者是其他的一些分布式计算框架
4)处理结果入库
结果可以存放到RDBMS、NoSQL
5)数据的可视化
通过图形化展示的方式展现出来:饼图、柱状图、地图、折线图
ECharts、HUE、Zeppelin
一般的日志处理方式,我们是需要进行分区的,
按照日志中的访问时间进行相应的分区,比如:d,h,m5(每5分钟一个分区)
No. 3 项目指标
在项目进行之前了解一些网站分析的基本知识。
1、用户识别
- IP数量曾是网站都关心的指标,也是最早使用的识别唯一用户的标志,被广泛提到的UV(unique visitors)也就是访问量最早就是通过IP来去重统计的。但是目前这种方法已经有很大的弊端,伪IP、代理、动态IP局域网共享同一个公网IP出口等等都会告饶获取IP地址的唯一性和准确性。当然IP地址仍然是最容易获取的信息。
- IP+UserAgent这种方法作为了一种改进的方法,因为使用相同的终端浏览网站,UserAgent信息是相对固定的,固定的操作系统,相对固定的浏览器,使用IP+UserAgent可以适当提高IP代理、公用IP这类情况下的用户辨识度,当然只要使用了伪IP、动态IP和VPN等IP变动情况同样无法避免弊端的存在。勇士UserAgent信息用户可以自定义啊,比如你做爬虫,你的UserAgent肯定是fake-useragent啊。
- Cookie被引入作为网站识别用户身份方式后,用户唯一身份定位的准确性有了一定提升,Cookie是网站以一小段文本形式存放在用户本地的终端信息,以便网站之后的读取。当然Cookie都有一定有效期限。当然这里就不展开讲Cookie了,不然从HTTP的无状态协议开始讲,再到什么session_id这个有点长。自己google吧,其实Cookie几乎能偶唯一对应到用户的访问终端,但是不想IP那么容易获取到,如果用户禁用Cookie,那么这种方法就失效,用户执行清理Cookie或者重装系统,Cookie同样会丢失。
- User ID这也是一个方法,其实就是网站要你注册,你注册了必然有一个身份ID咯,很多网站把这个用户ID写入Cookie以便用户下次访问直接判断身份,或者完成“自动登录功能”。这个我相信大部分人都有体会,比如知乎,你没有登录网站还是认识你啊。
2、网站分析中的一些基础指标
- IP地址:IP地址曾是每个网站都关心的指标,在早期网站统计中,IP可以表示网站流量也可以表示访问者数量,但是现在IP地址相对于Cookie来说统计IP地址衡量网站的流量指标已经不准确了,比如使用ADSL上网的用户电脑每个月会有很多不同的IP地址。当然IP地址还是需要的,比如获取地理位置。
- 浏览量PageView和唯一身份浏览量Unique PageView:PV的通俗解释就是页面被加载的次数,每次页面被加载,就被算作一次PV,比如你浏览了页面A,在浏览页面B,再回到A,那么这次访问的PV就是3,如果你打开页面又刷新页面或者重新加载,就会被算作另一次浏览量。UPV就是汇总由同一用户在同一会话期间生成的浏览量。唯一身份浏览量表示该页面被浏览(一次或者多次)期间的会话次数。简单的说,这个指标的计算取决于一个因素,就是是不爱属于同一个session,如果不是就被记做新的一次“唯一身份浏览量”。session是指用户一次访问过程。
- 访问次数Visits:在一定的时间范围内,网站的所有的访问者对网站访问的总的次数,即访问者人数*每个访问者的访问次数
- 绝对唯一访问者Visitors:在指定时间段内不重复(仅计数一次)的访问者人数。唯一身份访问者人数用Cookie确定。就是说在指定时间段内,A访问网站5次,B访问了1次,那么就有2个“绝对访问者人数”
- 网站停留时间Time on site和页面停留时间Time on page:这两个分别用来记录用户在网站或者网页上的停留时间,这样就可以根据用户停留的时间长短衡量网站和网页的表现
- 跳出率Bounce Rate和退出率Exit Rate:跳出指单页访问或访问者的次数,即在一次访问中访问者进入网站后只访问了一个页面就离开的数量;跳出率指某一范围内单页访问次数或者访问者于总访问次数的百分比,退出指访问者离开网站的次数,通常基于某一范围;退出率指某一范围内推出的访问者与综合访问量的百分比。那么如果访问者在访问中只浏览了一个页面就离开网站,那么即算一次跳出也算一次退出。
- 访问时长和访问深度:访问时长是在选定的时间范围内,不同时长的访问次数在网站获得的所有访问次数中的分布情况。访问深度是在选定范围内,不同浏览量的访问次数在网站获得的所有访问次数中的分布情况。
本次项目是比较简单的,可能不会涉及的很全面,但是尽量把基本的东西都涵盖到。
No. 4 项目
项目一:某网站某一天的日志统计分析
我们来看看日志长得什么样子
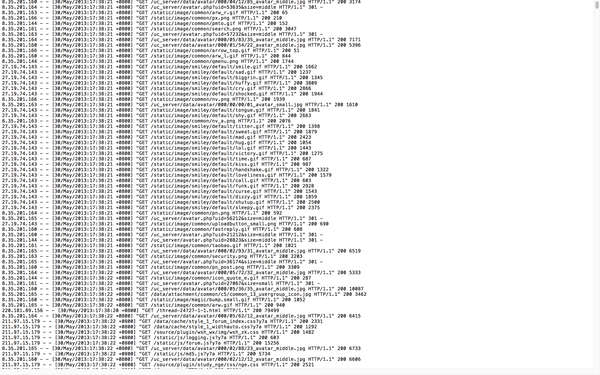
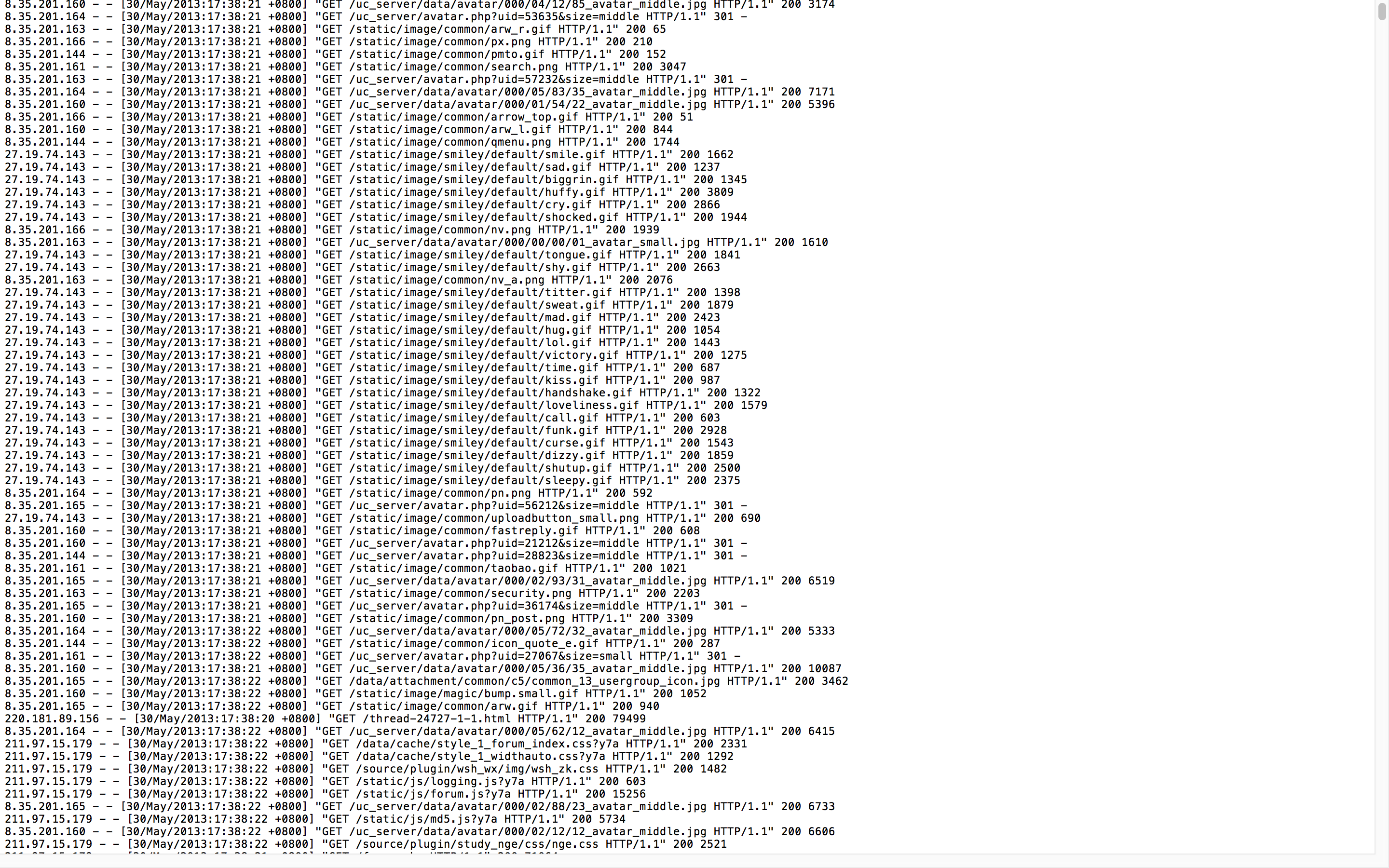
这份数据只是一部分,你可以把他上传到HDFS上面去,上传很简单,hadoop fs -put xxxxx.log /xxxxx/xxxx,当然放在本地也可以啊,不影响分析过程的。
scala读取也很简单
val access = spark.sparkContext.textFile("hdfs://localhost:8020/WEB_log/Apache_common/access_2013_05_30.log")hdfs://localhost:8020这一条你去hadoop下面的core-site.xml去查就知道了,第一个就是。
项目需求 :
1、IP地址
注:IP地址提取地理区域
2、浏览量PageView
3、访问网站的不同独立 IP 个数
4、注册用户数
5、跳出率Bounce Rate
6、统计访问量最高的url topN访问次数
7、按照地理区域统计访问量最高的url topN访问次数
8、按照流量统计访问量最高的url topN访问次数
1、数据清洗
*访问IP地址
*访问时间
*访问URL
*访问过程耗费流量
数据清洗我们分两步来清洗
1、对原始数据做基本的格式调整,提高可读性


我们看日志上有很多干扰项,比如分隔符号,时间格式、标点符号都不友好,我们需要把他”清理干净“,废话不多说,我们用scala编写代码来清洗。
1)首先我们写一个时间格式的工具:
package com.hadoop.spark
import java.text.SimpleDateFormat
import java.util.Locale
import java.util.Date
* 日期时间解析工具类
object DataUtils {
//输入文件日期时间格式
//[30/May/2013:17:38:20 +0800]
val YYYYMMDDHHMM_TIME_FORMAT = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss Z", Locale.ENGLISH)
//转换输入文件日期格式
val TAGET_FORMAT = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
*获取时间:yyyy-MM-dd HH:mm:ss
def parse(time:String) = {
TAGET_FORMAT.format(new Date(getTime(time)))
* 获取输入日志时间:long类型
def getTime(time:String) = {
try {
YYYYMMDDHHMM_TIME_FORMAT.parse(time.substring(time.indexOf("[") + 1,
time.lastIndexOf("]"))).getTime
} catch {
case e: Exception => {
我们来测试一下这个工具:
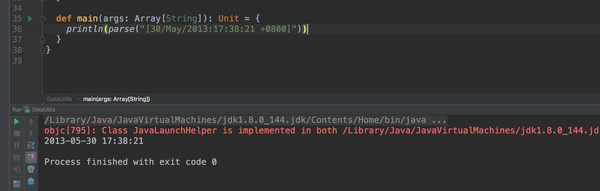
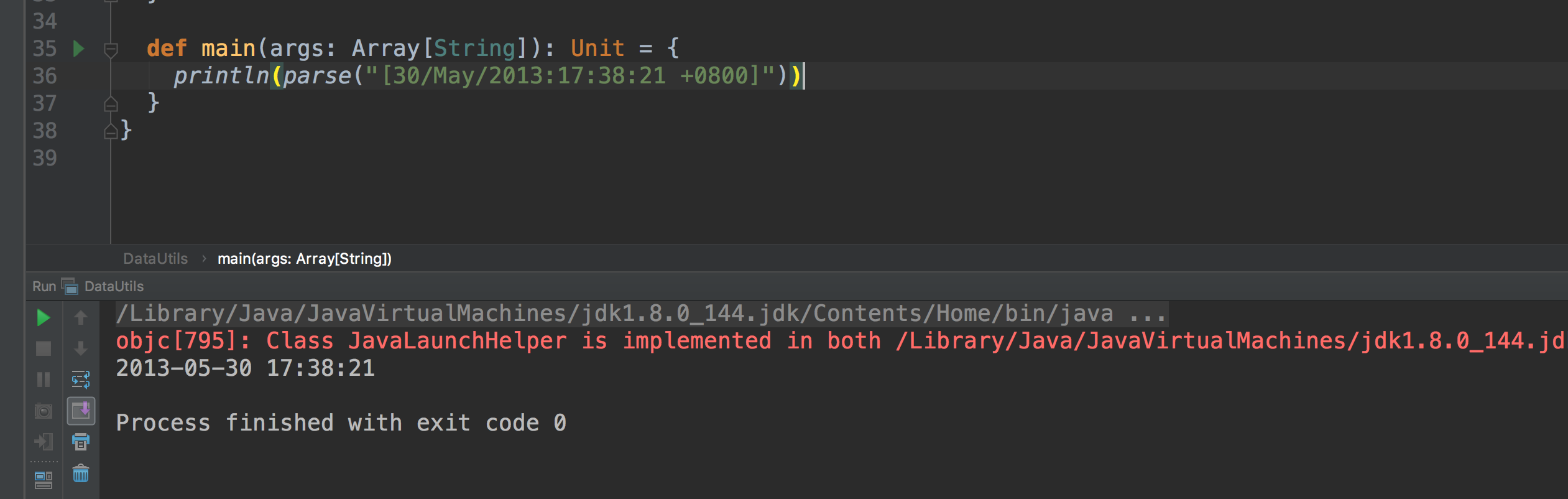
现在看格式是不是很友好,看着是不是很舒服了!好,那么说明这个工具类应该是没啥问题了。
接下来我们就要写清洗代码,首先我们知拿出IP和时间来看看,以下就是拿出IP和时间的代码
package com.hadoop.spark
import org.apache.spark.sql.SparkSession
* 第一步清洗:抽取我们所需要的指定列的数据
object SparkStatFormat {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("HiveMySQLApp")
.master("local[2]").getOrCreate()
val access = spark.sparkContext.textFile("file:///Users/chandler/Documents/data/test_data/access_2013_05_30.log")
//access.take(20).foreach(println)
access.map(line => {
val splits = line.split(" ")
val ip = splits(0)
*原始日志的第三个和第四个字段拼接就是完整的访问时间:
* [30/May/2013:17:38:20 +0800] ==> yyyy-MM-dd HH:mm:ss
val time = splits(3)+" "+splits(4)
(ip, DataUtils.parse(time))
}).take(10).foreach(println)
spark.stop()
}我们看看这个代码的测试结果如何
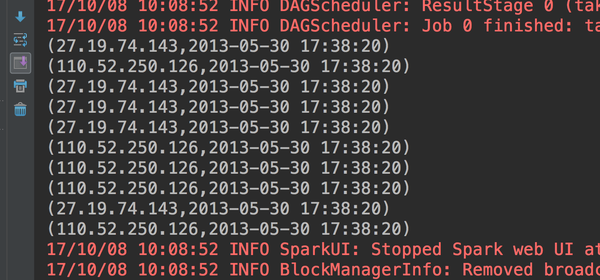
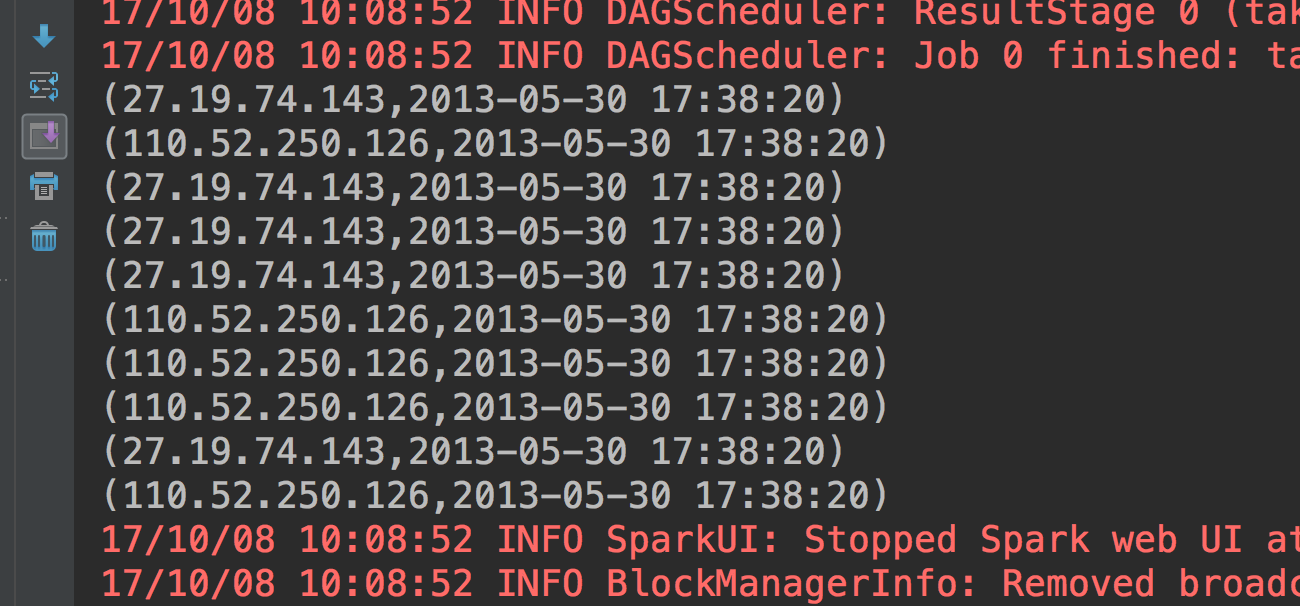
这个格式就很好了,那我们就进一步完善这个代码:
package com.hadoop.spark
import org.apache.spark.sql.SparkSession
* 第一步清洗:抽取我们所需要的指定列的数据
object SparkStatFormat {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("HiveMySQLApp")
.master("local[2]").getOrCreate()
val access = spark.sparkContext.textFile("hdfs://localhost:8020/WEB_log/Apache_common/access_2013_05_30.log")
access.map(line => {
val splits = line.split(" ")
//判断分割后的每一行日志是否长度为10,目的为过滤掉缺少列数据的日志,防止写入数据过程报数组越界的错误
if (splits.length == 10){
val ip = splits(0)
*原始日志的第三个和第四个字段拼接就是完整的访问时间:
* [30/May/2013:17:38:20 +0800] ==> yyyy-MM-dd HH:mm:ss
val time = splits(3)+" "+splits(4)
val time_format = DataUtils.parse(time)
val url = splits(6)
val status = splits(8).replaceAll(" ", "")
val traffic = splits(9).replaceAll("-", "0")
time_format + "\t" + url + "\t" + ip + "\t" + traffic + "\t" + status
}).saveAsTextFile("hdfs://localhost:8020/WEB_log/Apache_common/clean_data_1")
spark.stop()
这里我的数据都放在HDFS上面的,可以不放在上面,这个没关系的,看看这代码执行结果吧。


HDFS上已经有处理过的数据了,我们通过命令查看一下
hadoop fs -cat /WEB_log/Apache_common/clean_data/part-00000
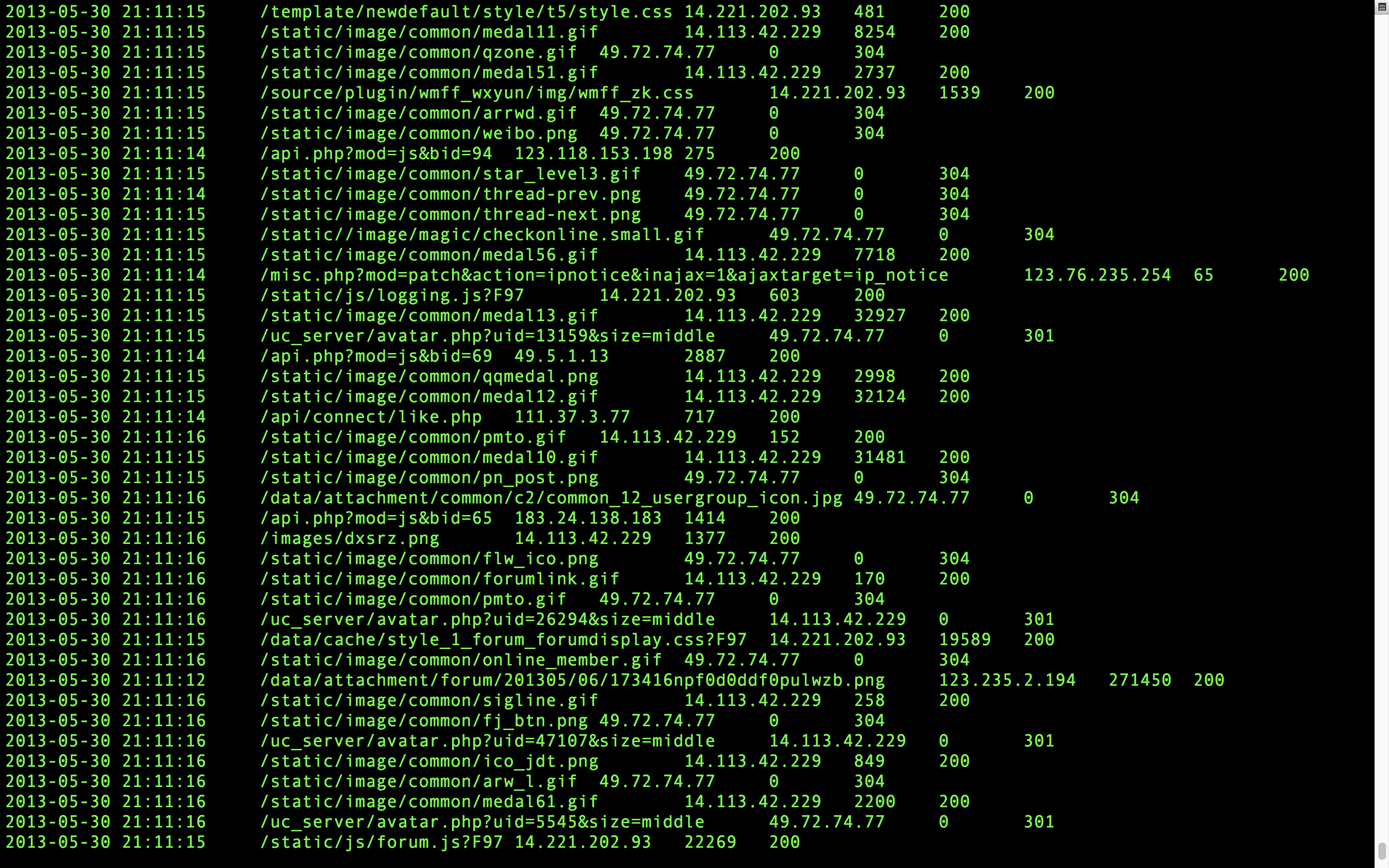
2、对第一步处理的数据再做处理,得到更详细的信息为我们所用。
一般的日志处理方式,我们是需要进行分区的,
按照日志中的访问时间进行相应的分区,比如:d,h,m5(每5分钟一个分区)
这次的这份数据是五个多小时的数据量,这次我们就按照这个时间来做,因为不管按照天分区还是按照分钟分区,处理方式还是一样的。
我们还是打开IDEA继续进行开发
首先新建一个package:com.ApacheCommon.log
那么我们要做哪些处理呢?我们根据前面写的项目需求来。
根据访问时间、访问URL、耗费的流量、访问IP地址信息,
得到URL、流量、ip、区域信息、访问时间、天、并且还要处理掉一些缺失值。
知道这些要求我们就可以写代码了,那么既然要得到城市信息,那肯定要写一个城市的解析工具类,写这个工具类之前,我们还需要取github上找工具,这里有一个 现成的 。
把这个clone下来,然后怎么办呢,不着急,先打开终端进入clone下来的这个文件的目录
mvn进行编译:
mvn clean package -DskipTests
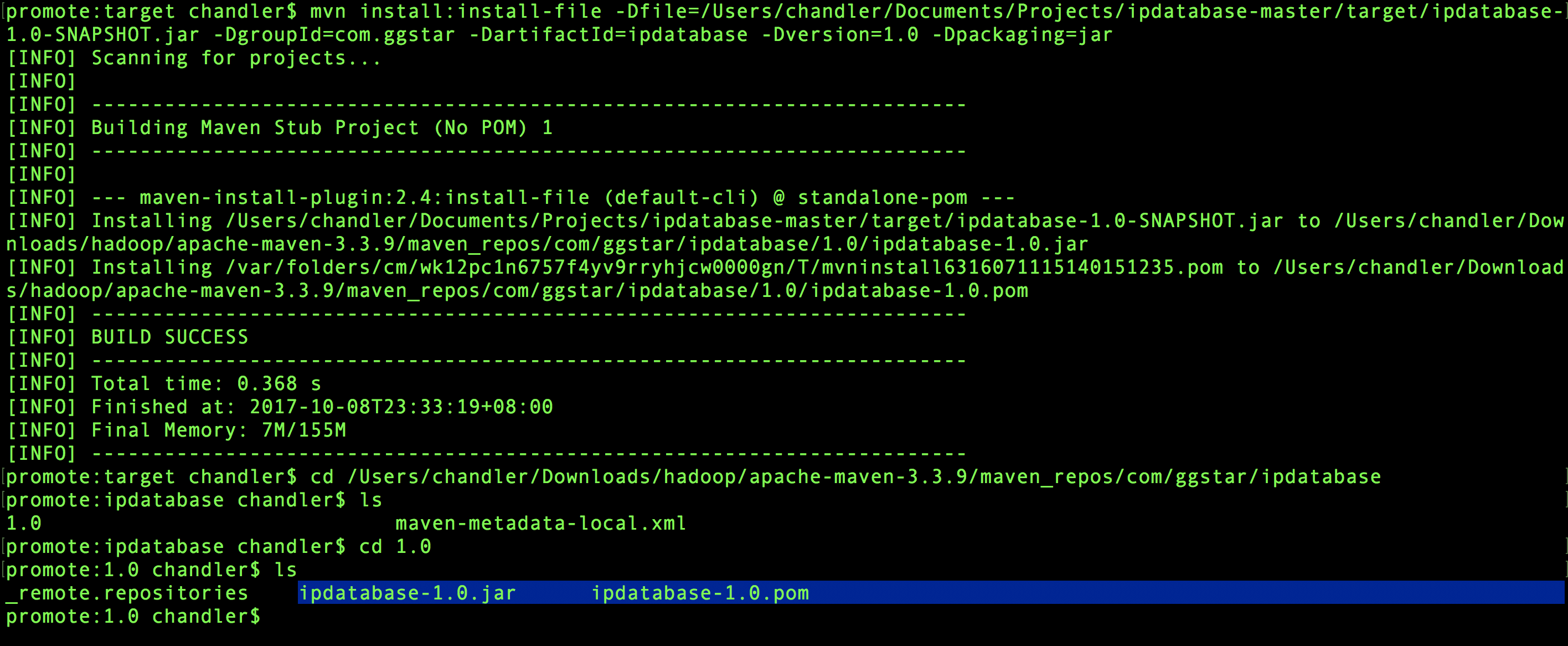
然后在目录文件会出现一个target文件,然后终端进去target安装jar包到自己的maven仓库
mvn install:install-file -Dfile=/Users/chandler/Documents/Projects/ipdatabase-master/target/ipdatabase-1.0-SNAPSHOT.jar -DgroupId=com.ggstar -DartifactId=ipdatabase -Dversion=1.0 -Dpackaging=jar
然后我们进入项目,pom.xml里面要添加dependency了。
<dependency>
<groupId>com.ggstar</groupId>
<artifactId>ipdatabase</artifactId>
<version>1.0</version>
</dependency>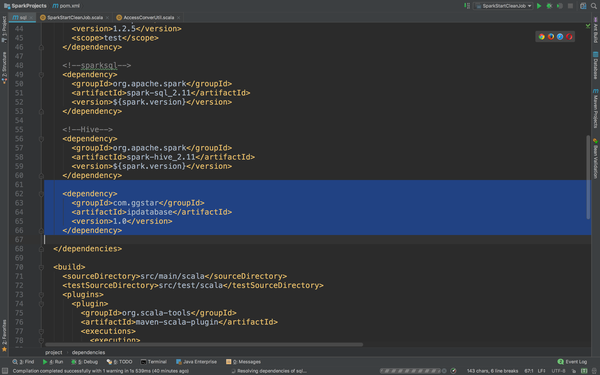
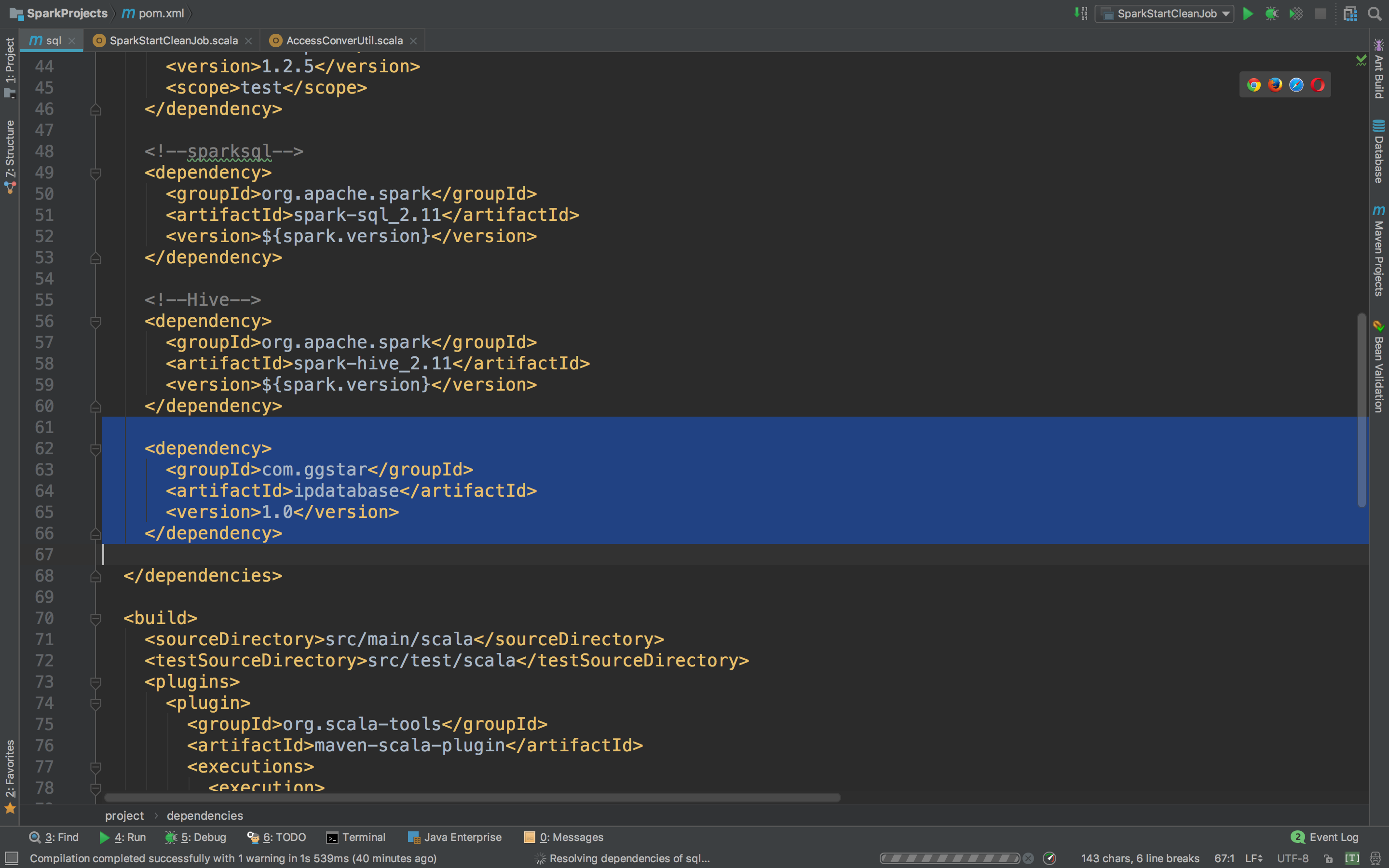
好了,我们写这个工具类:
package com.ApacheCommon.log
import com.ggstar.util.ip.IpHelper
* 解析IP工具类
object IpUtils {
def getCity(ip:String) = {
IpHelper.findRegionByIp(ip)
}我们可以试试看,能不能识别,在工具类下面写main方法print看看
package com.ApacheCommon.log
import com.ggstar.util.ip.IpHelper
* 解析IP工具类
object IpUtils {
def getCity(ip:String) = {
IpHelper.findRegionByIp(ip)
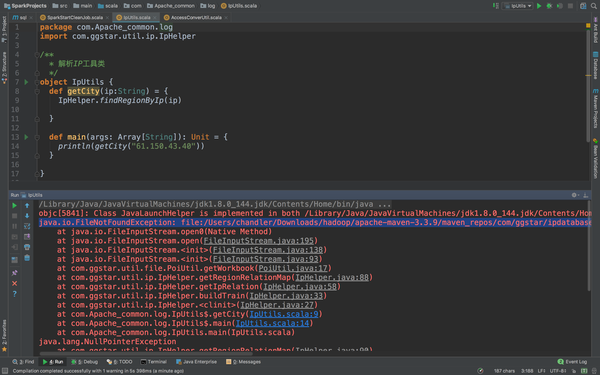
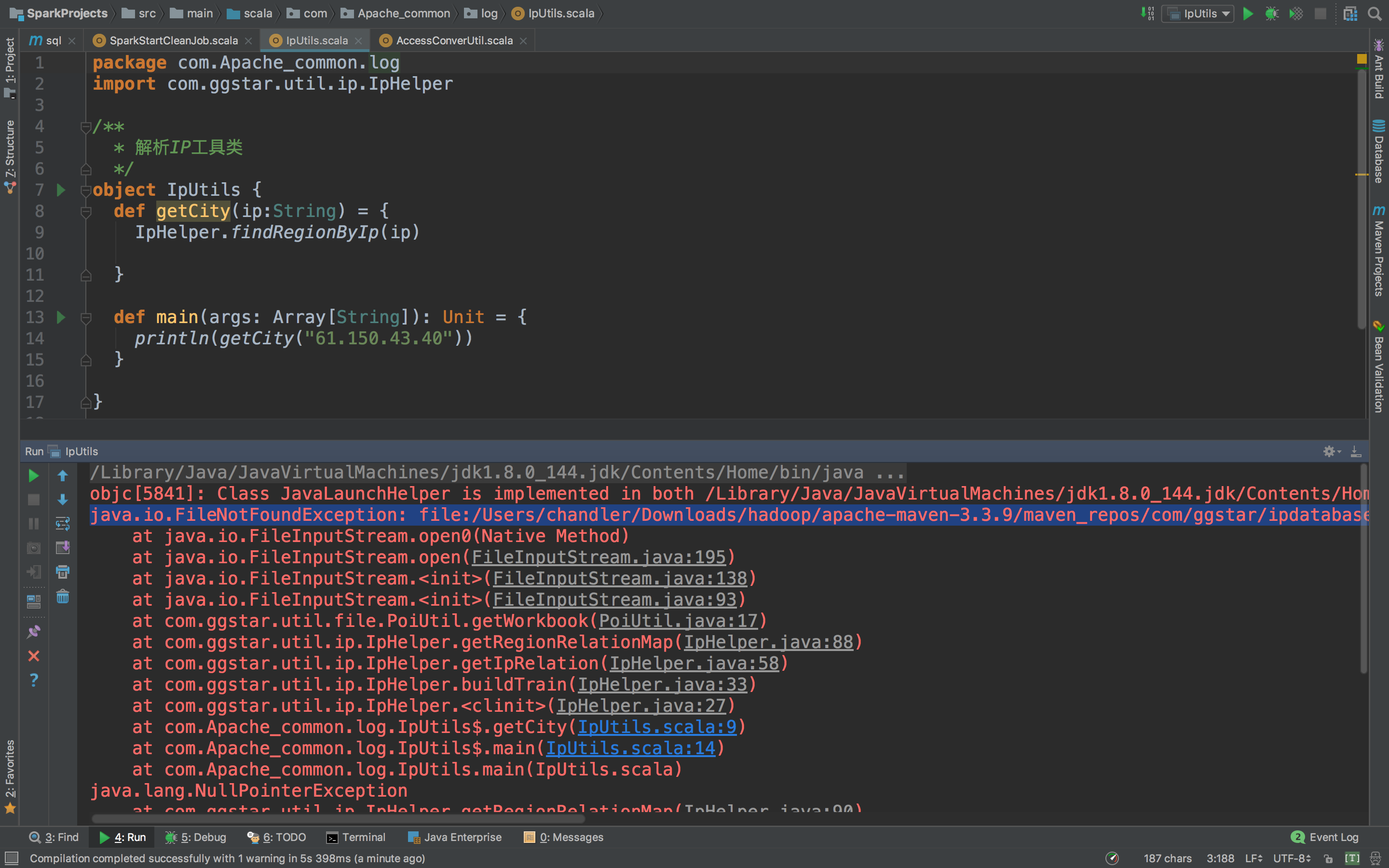
def main(args: Array[String]): Unit = {
println(getCity("27.19.74.143"))
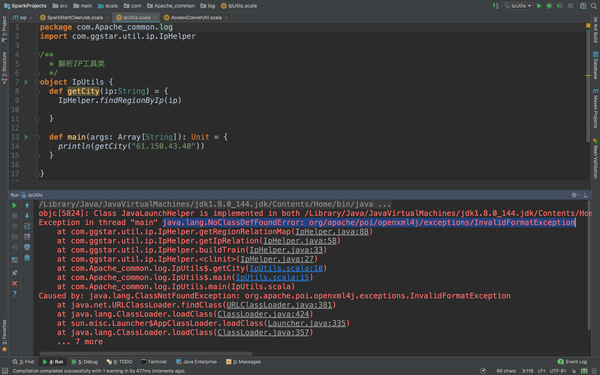
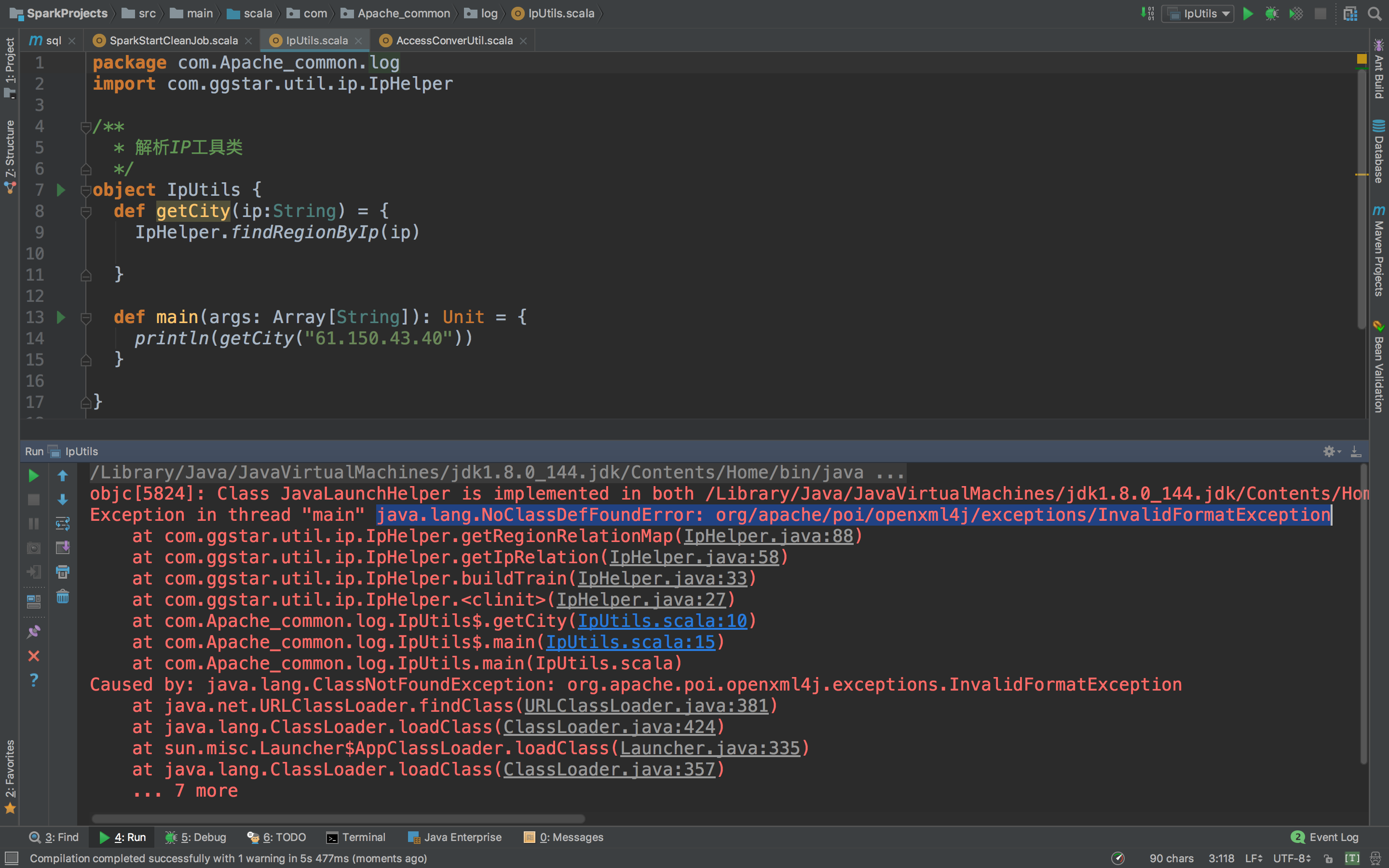
哎!报错了,这是说没有poi,poi-ooxml,怎么解决呢,只要复制粘贴就能解决。
先去ipdatabase目录下打开pom.xml,然后复制这两个dependency
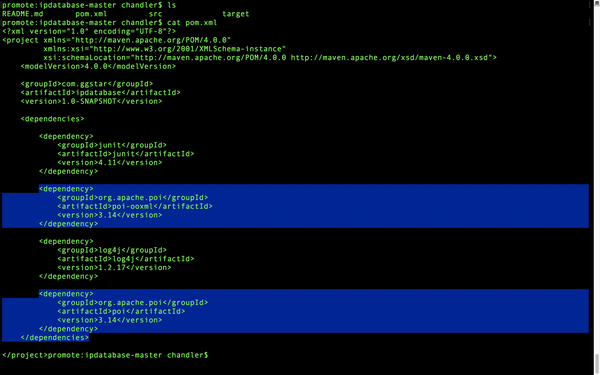
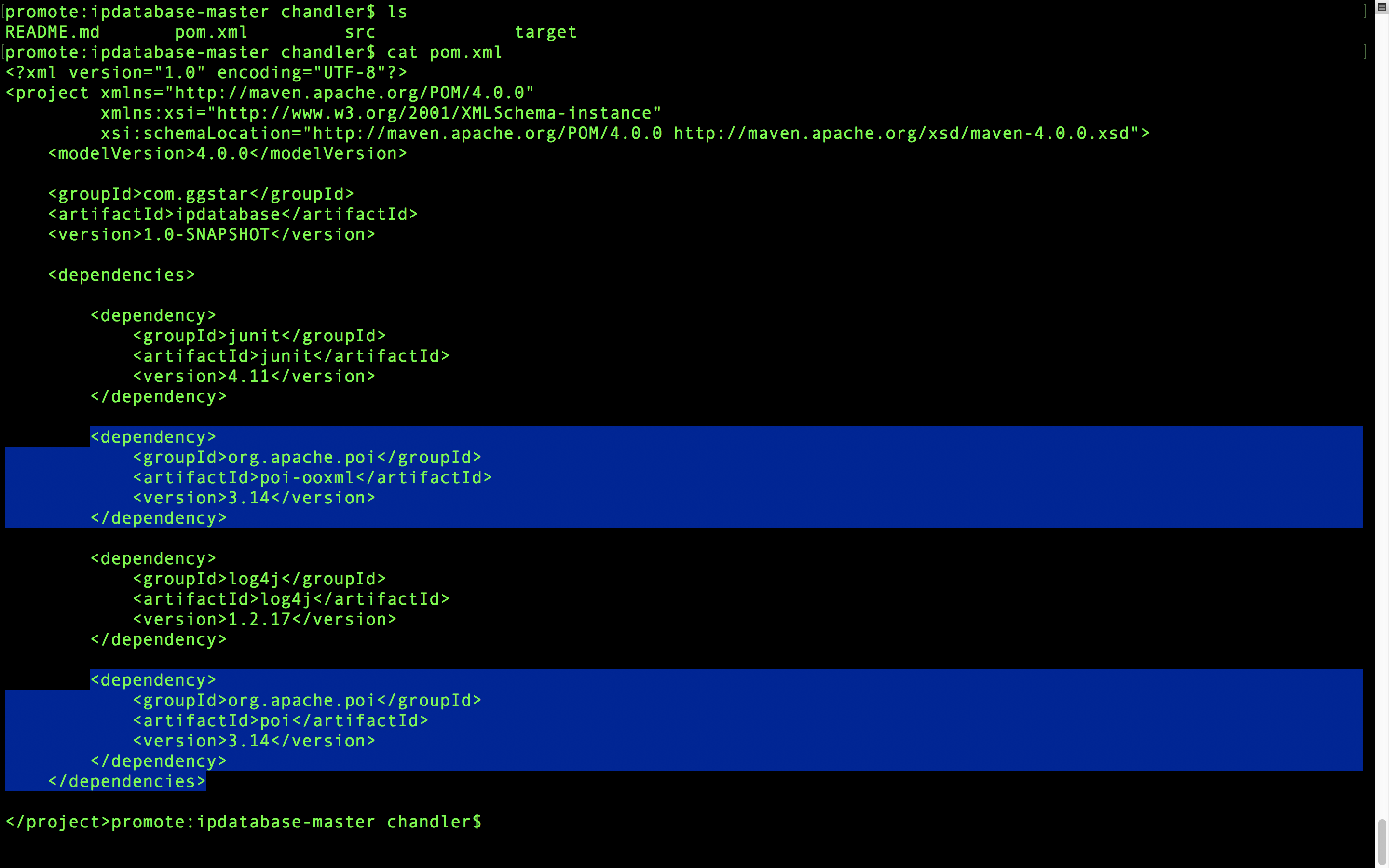
然后进入到项目的pom.xml,在dependencies里面粘贴
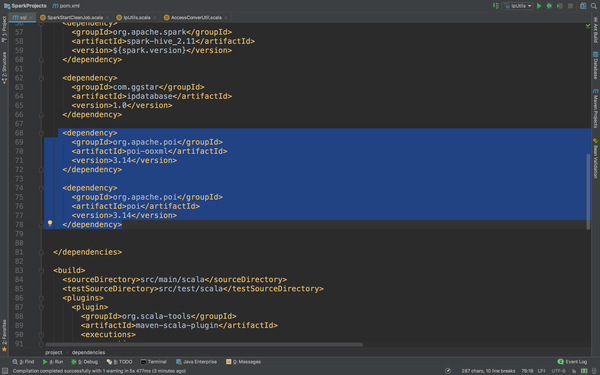
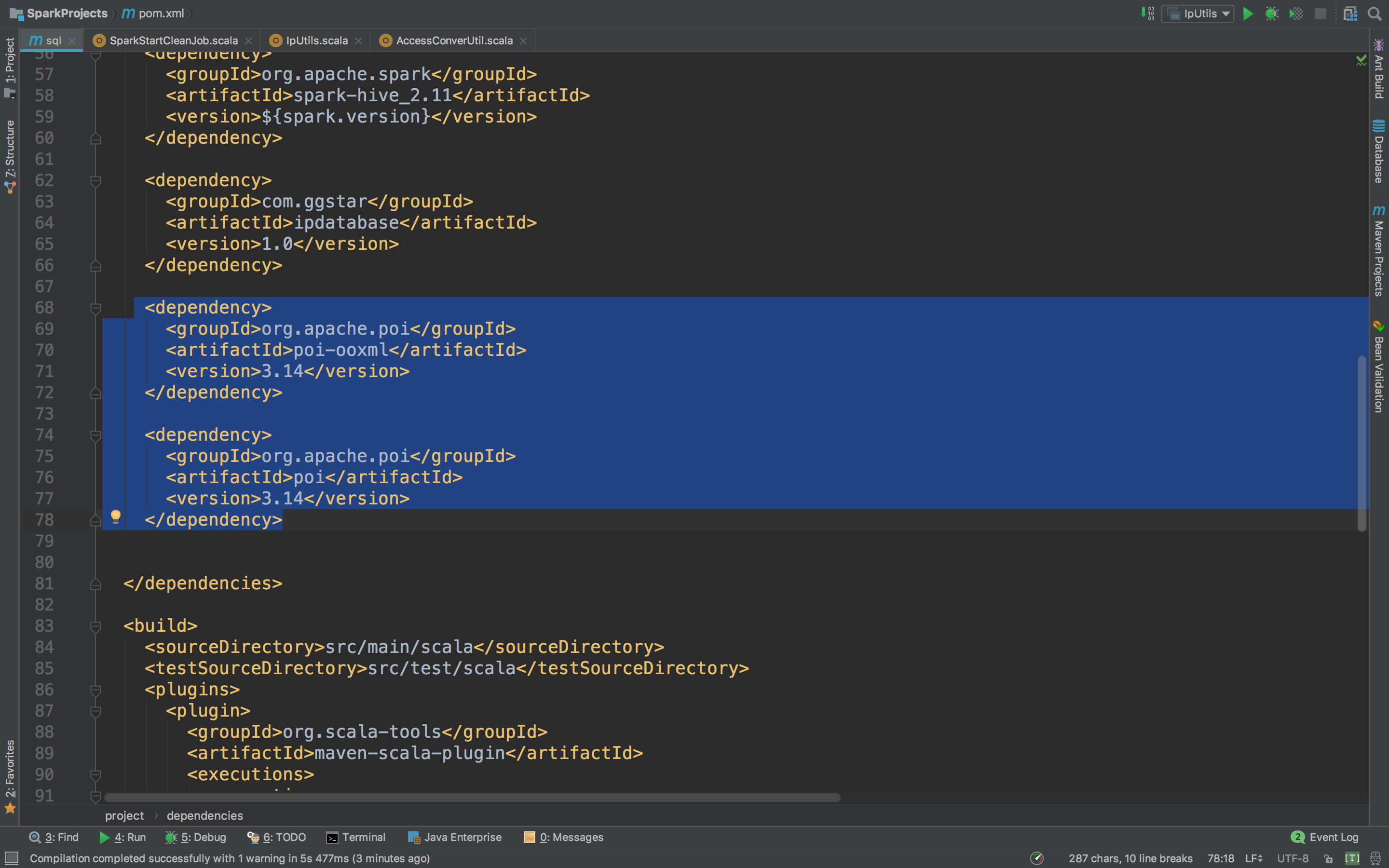
然后再运行看。
看到还有错误,不着急,我们少了两个东西没有复制进来。我们看到项目目录下的resources文件夹,没有就在这个位置新建并且mark成Root。
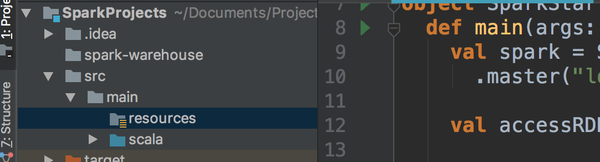
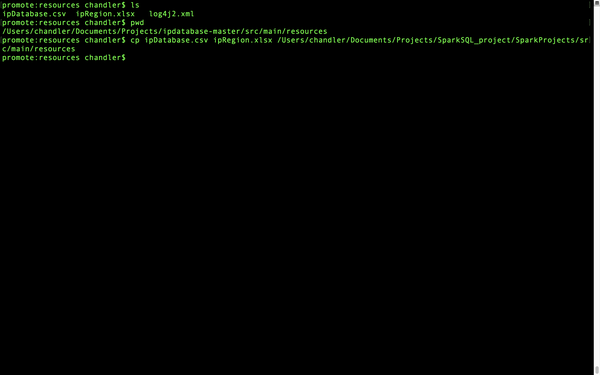
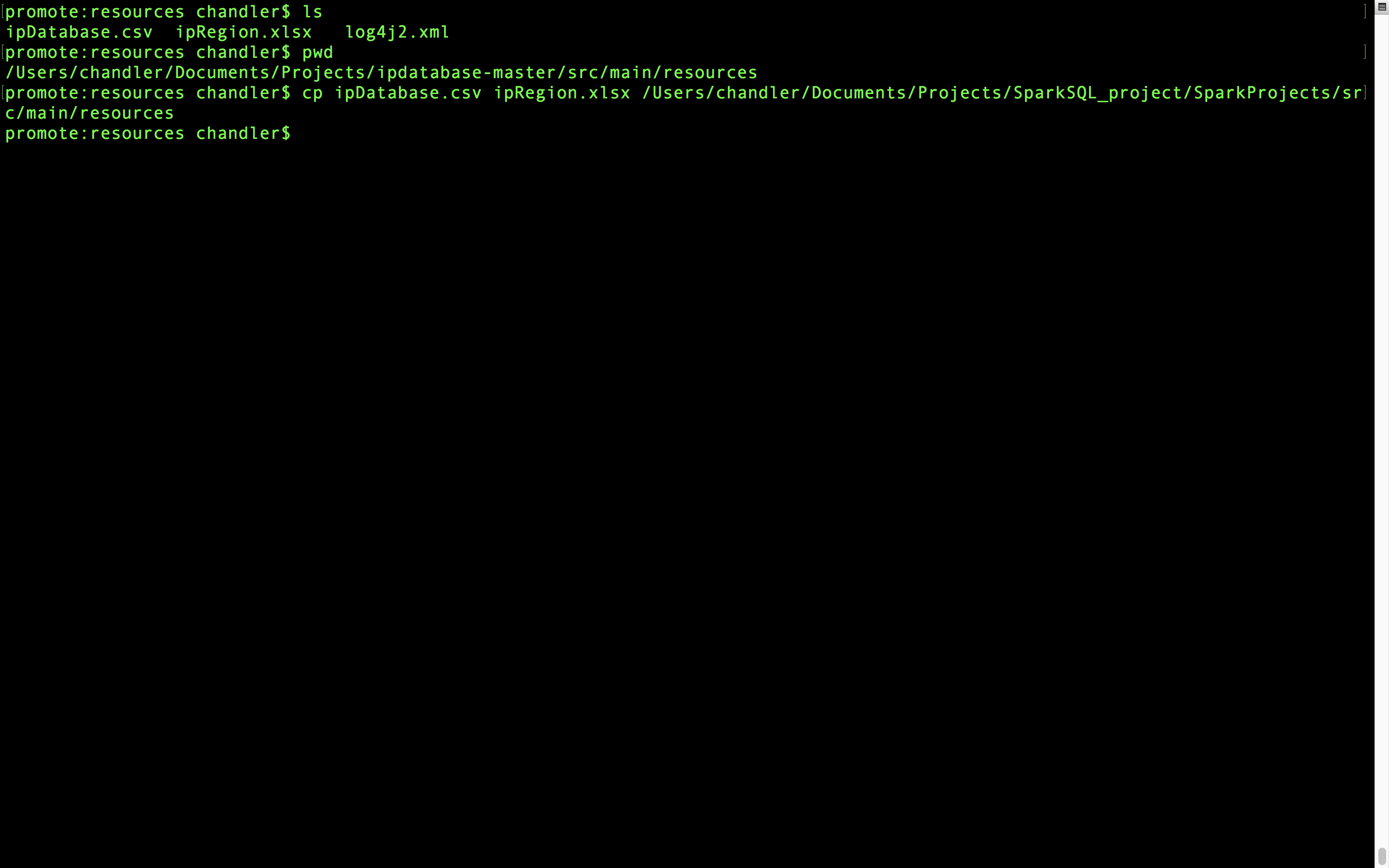
然后我们进入ipdatabase目录下的src/main/resources下,把里面的两个文件拷贝到项目的resources文件夹下面。
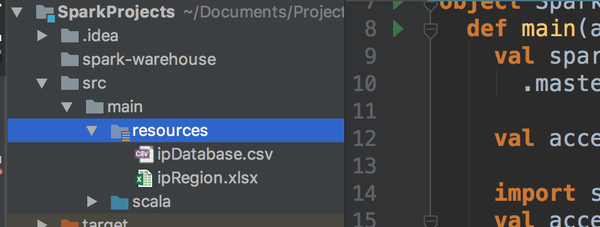
现在我们再运行看看呢。
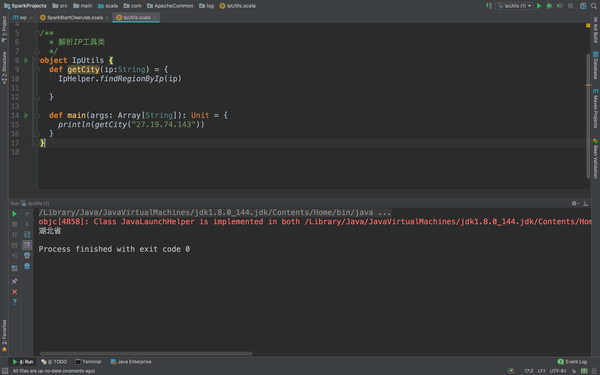
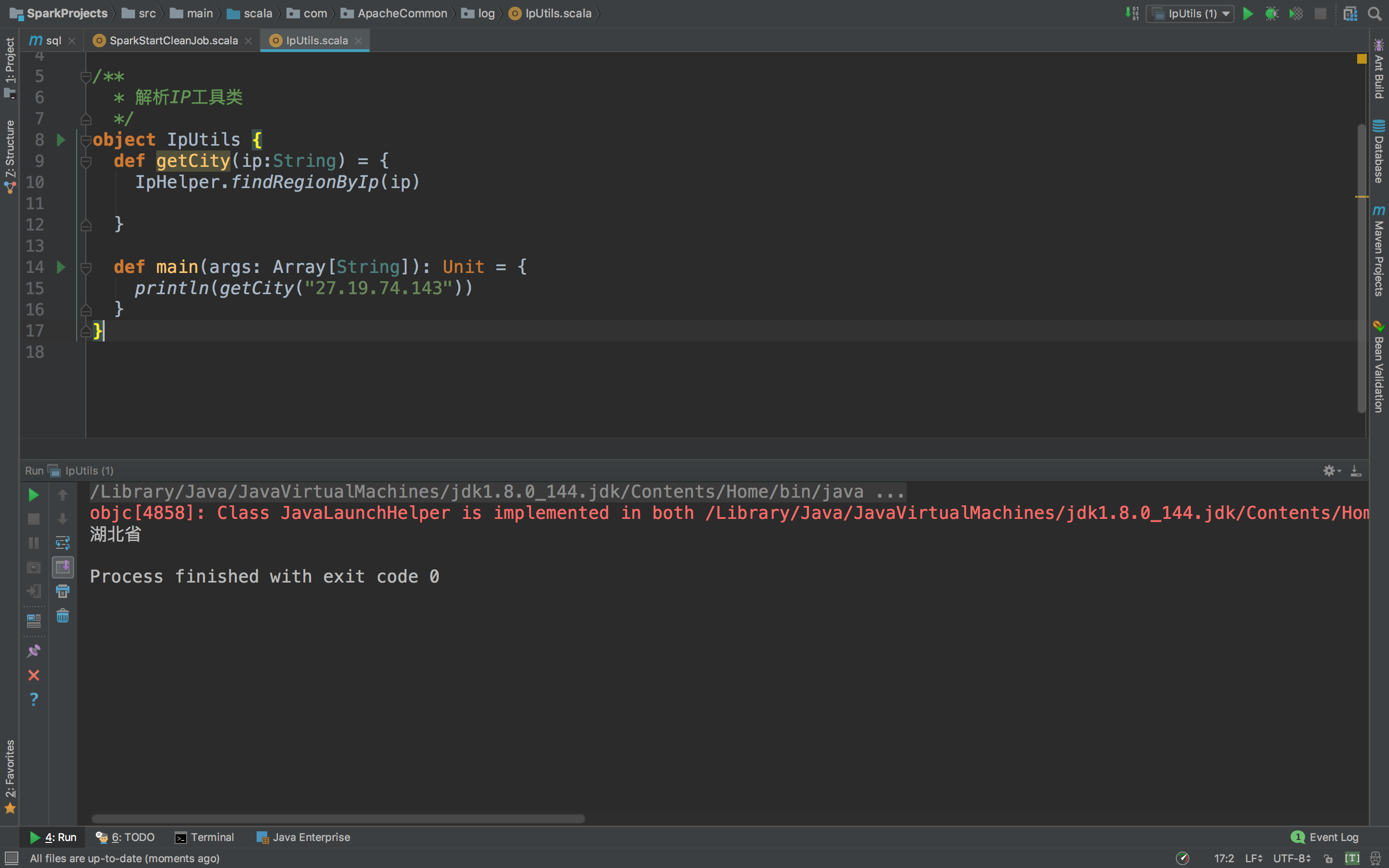
很完美!是不是,这里可能会有人问这么定位到市、区、县什么的,这个嘛,也不难,打开手机,进入某宝APP,搜索IP地址库,你会发现一片天地。很便宜。
好了,现在我们使用Spark完成我们的数据清洗工作,上代码
package com.ApacheCommon.log
import org.apache.spark.sql.{SaveMode, SparkSession}
* 使用Spark完成我们的数据清洗工作
object SparkStartCleanJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("SparkStartCleanJob")
.master("local[2]").getOrCreate()
//把我们第一步清洗的log读进来
val accessRDD = spark.sparkContext.textFile("hdfs://localhost:8020/WEB_log/Apache_common/clean_data_1/part-00000")
//导入隐式转换
import spark.implicits._
val accessDF = accessRDD.map(_.split("\t")).map(line => if(line.length==5) {
Info(
line(1), line(3).toLong, line(2), IpUtils.getCity(line(2)), line(0), line(0).substring(0,10).replaceAll("-", "")
)} else {
Info("", 0, "", "", "", "")
}).toDF()
//测试用代码
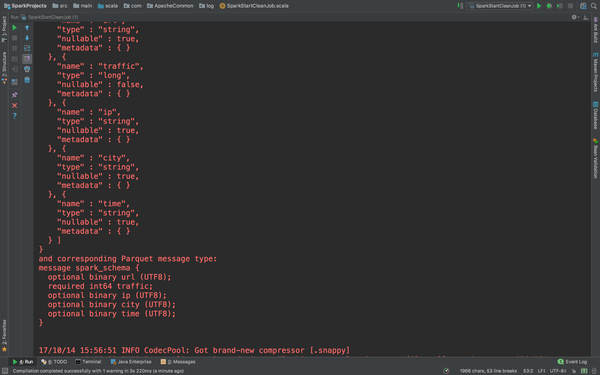
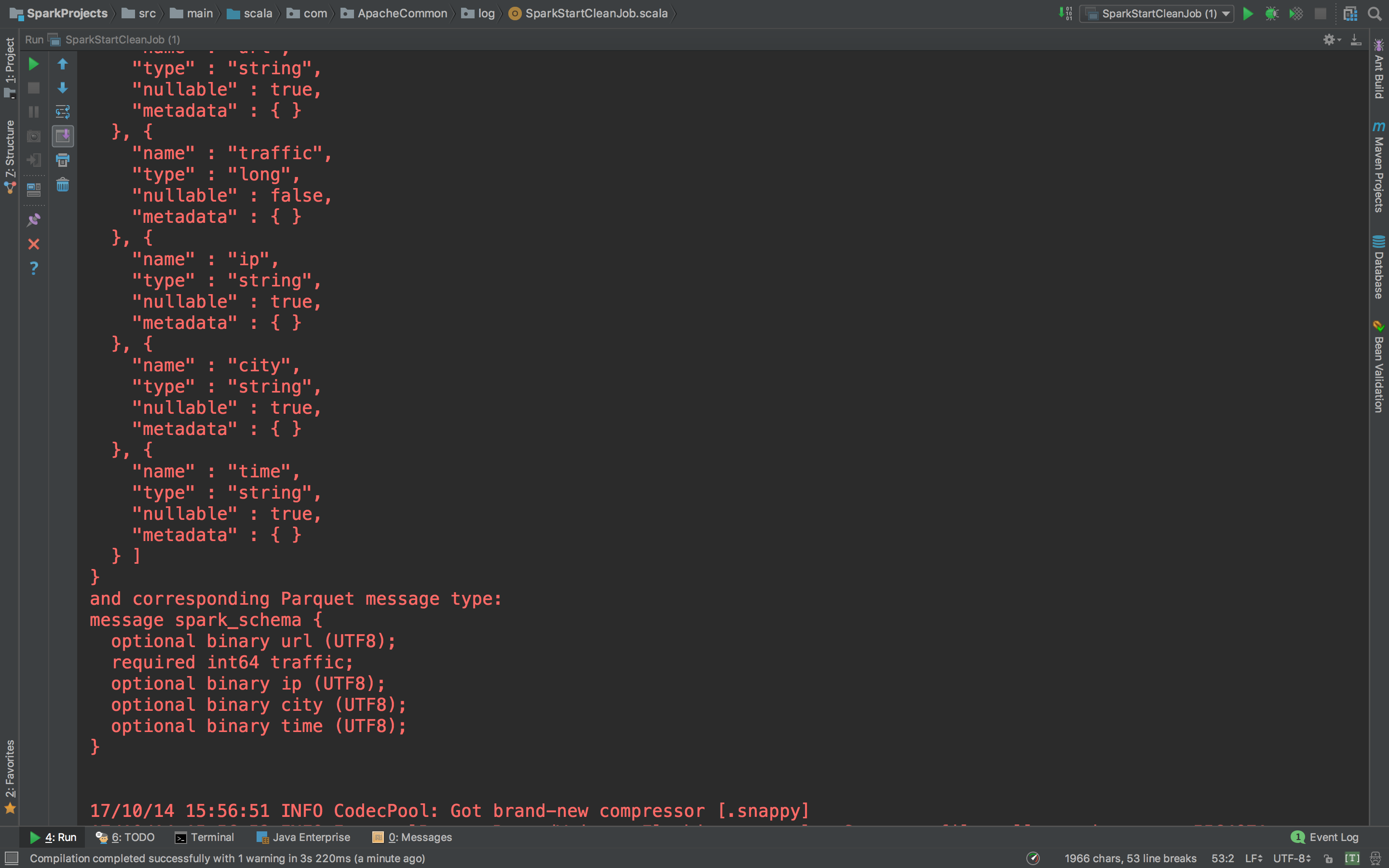
accessDF.printSchema()
accessDF.show(false)
spark.stop()
case class Info(url: String, traffic: Long, ip: String, city: String, time: String, day: String)
先测试一下看看
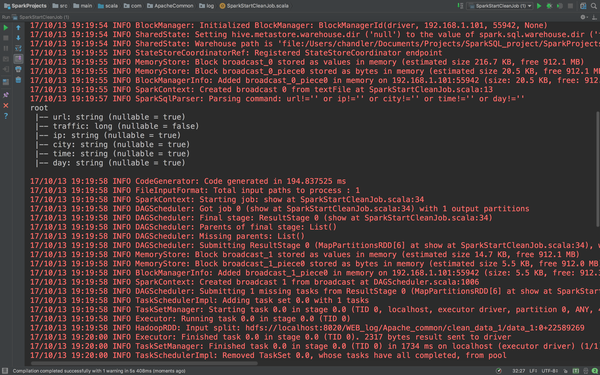
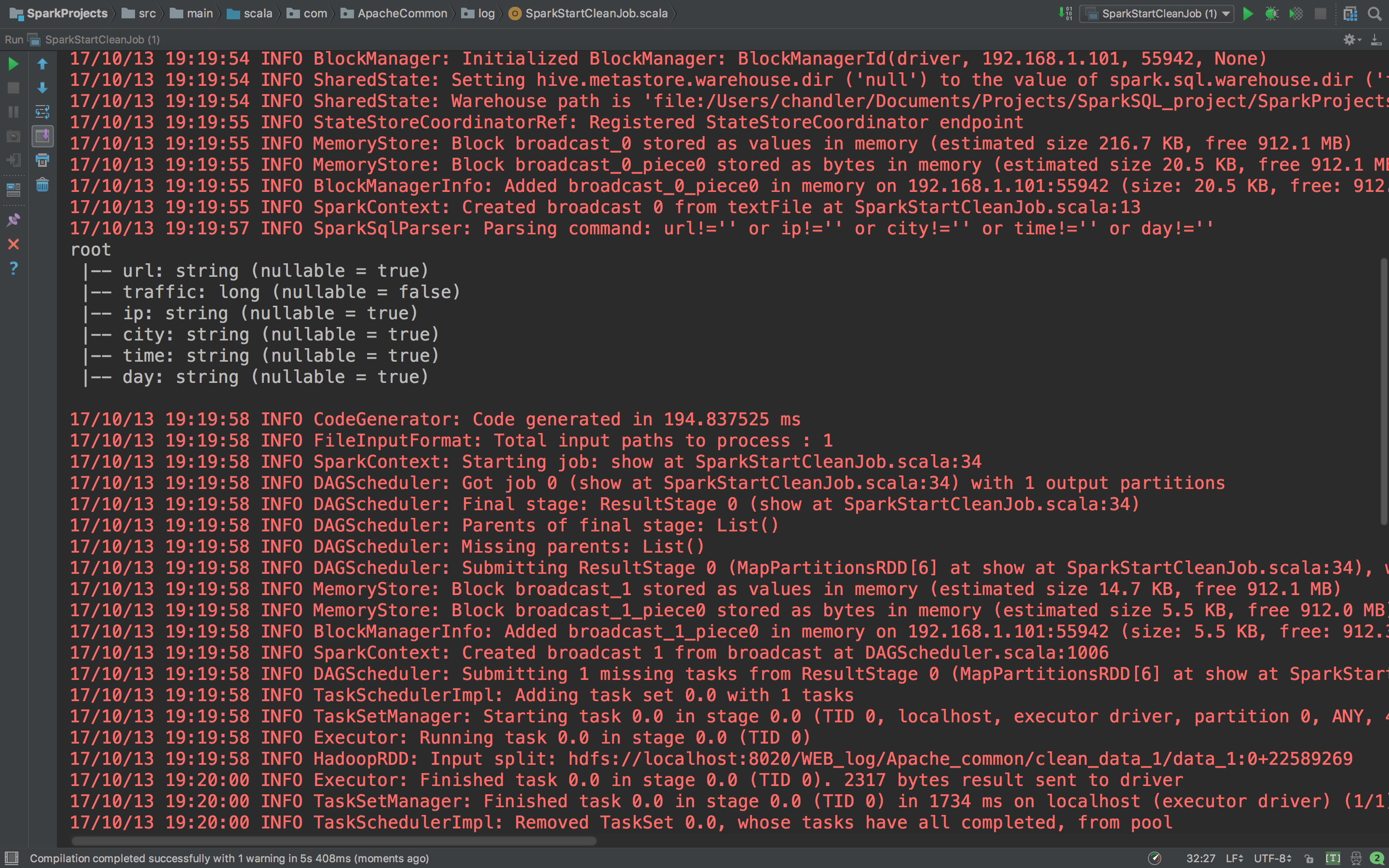
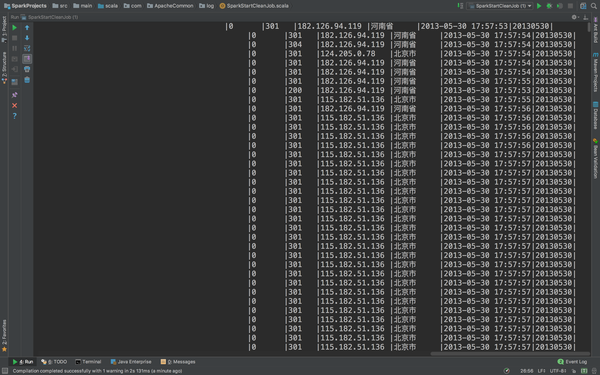
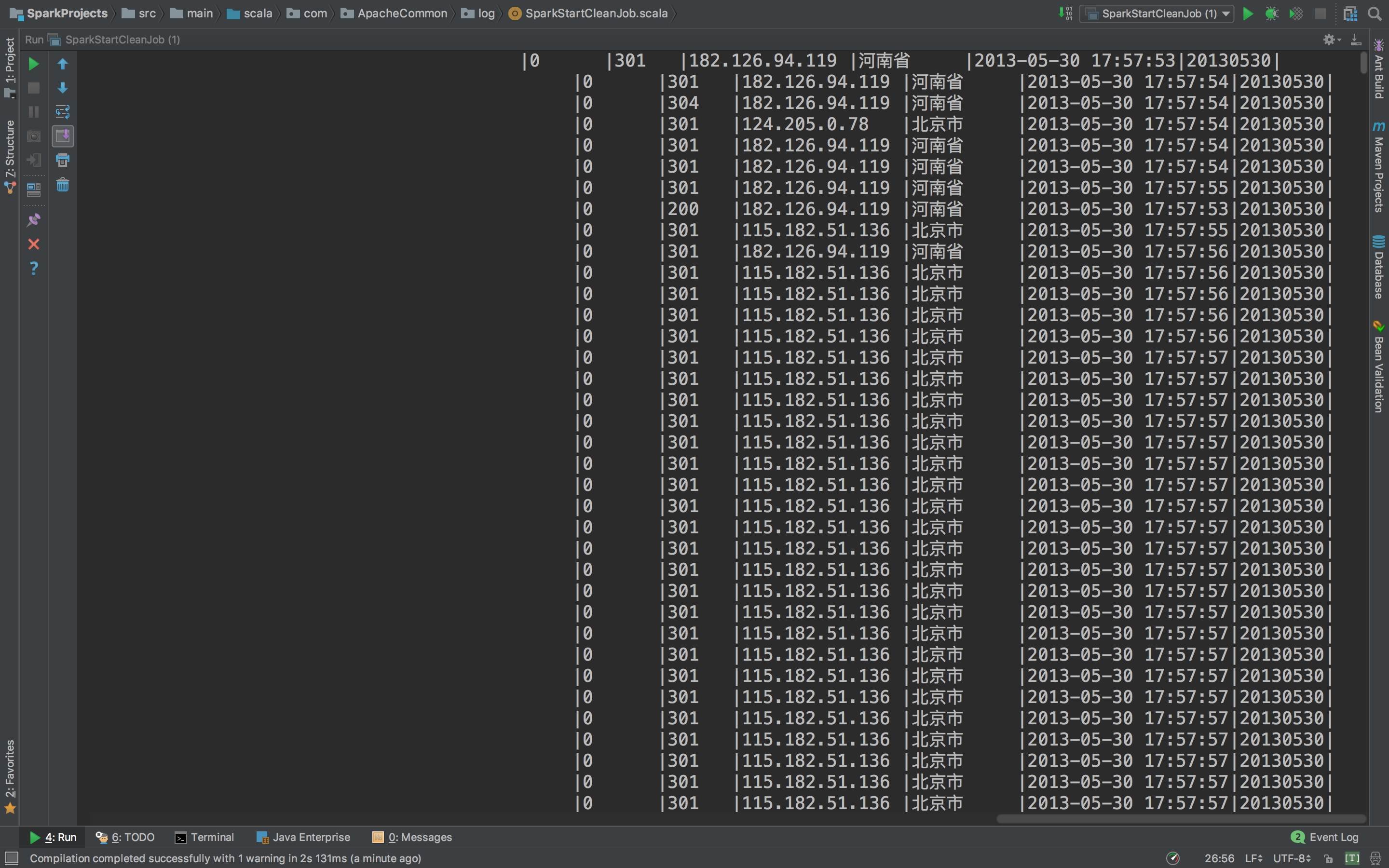
这个就非常好了。正常输出了缺失值的数据,Schema信息,和数据。下面我们完善它。
首先我们之前第一部清清洗的数据输出到hdfs被分割为两份,就是part-0000和part-00001,我们把他合并一下,在终端操作一些就可以了,以下是操作命令:
hadoop fs -cat /WEB_log/Apache_common/clean_data_1/part-00000 /WEB_log/Apache_common/clean_data_1/part-00001 | hadoop fs -appendToFile - /WEB_log/Apache_common/clean_data_1/data_1把两个文件合并为data_1这一个文件就可以,看看合并成功没有
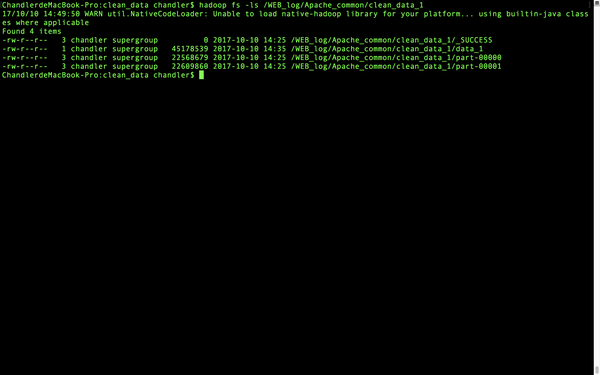
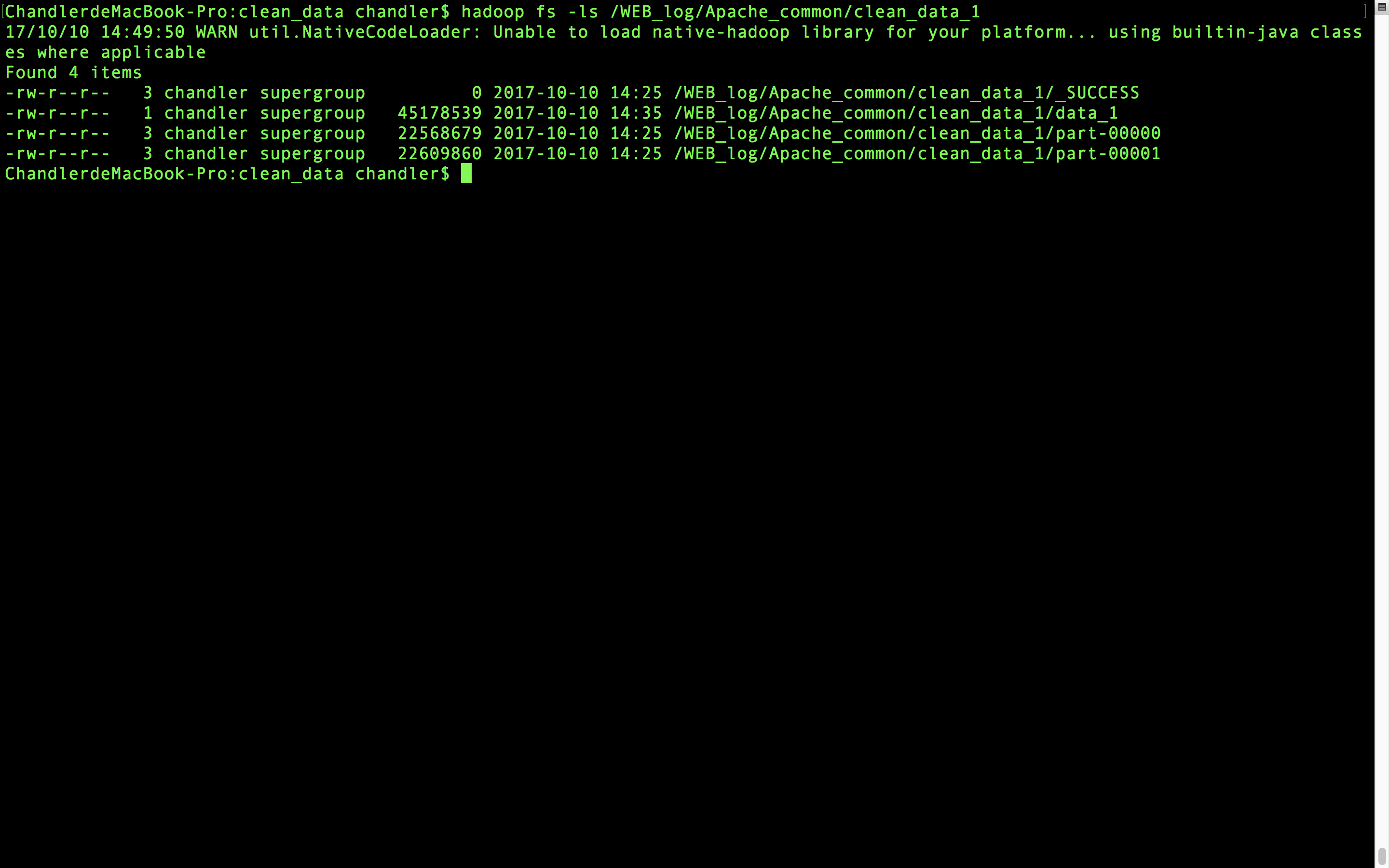
合并好了,cat一下看看内容吧
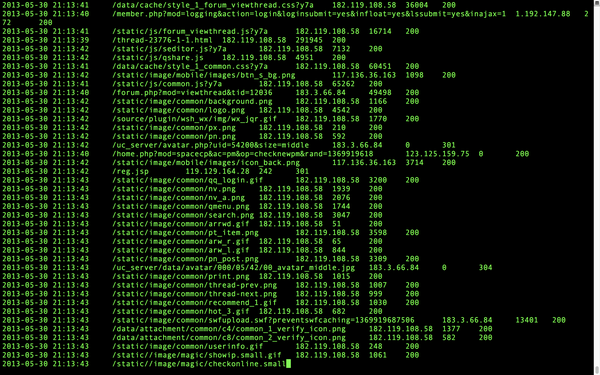
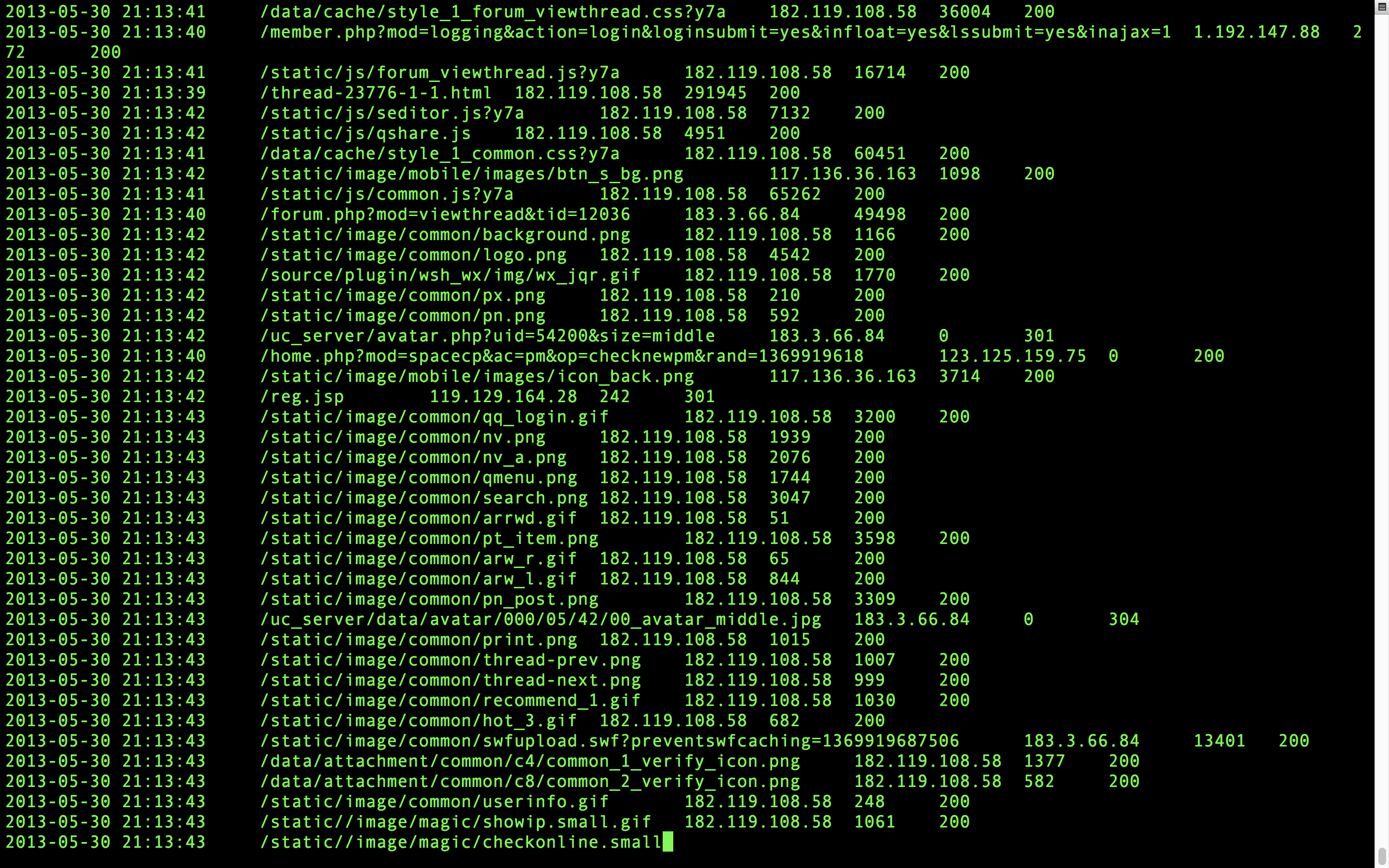
非常好,现在就完成合并了。
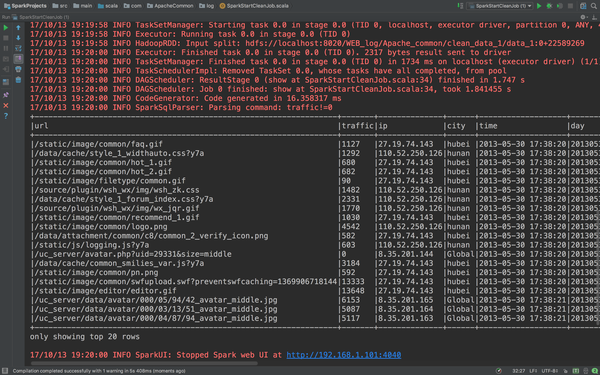
下面开始对一些缺失值做处理,首先是url='' or ip='' or city='' or time='' or day=''的情况,看看有哪些数据。
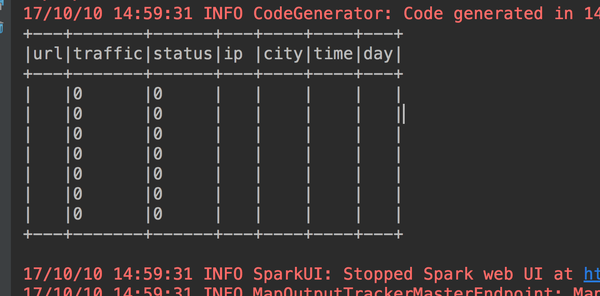
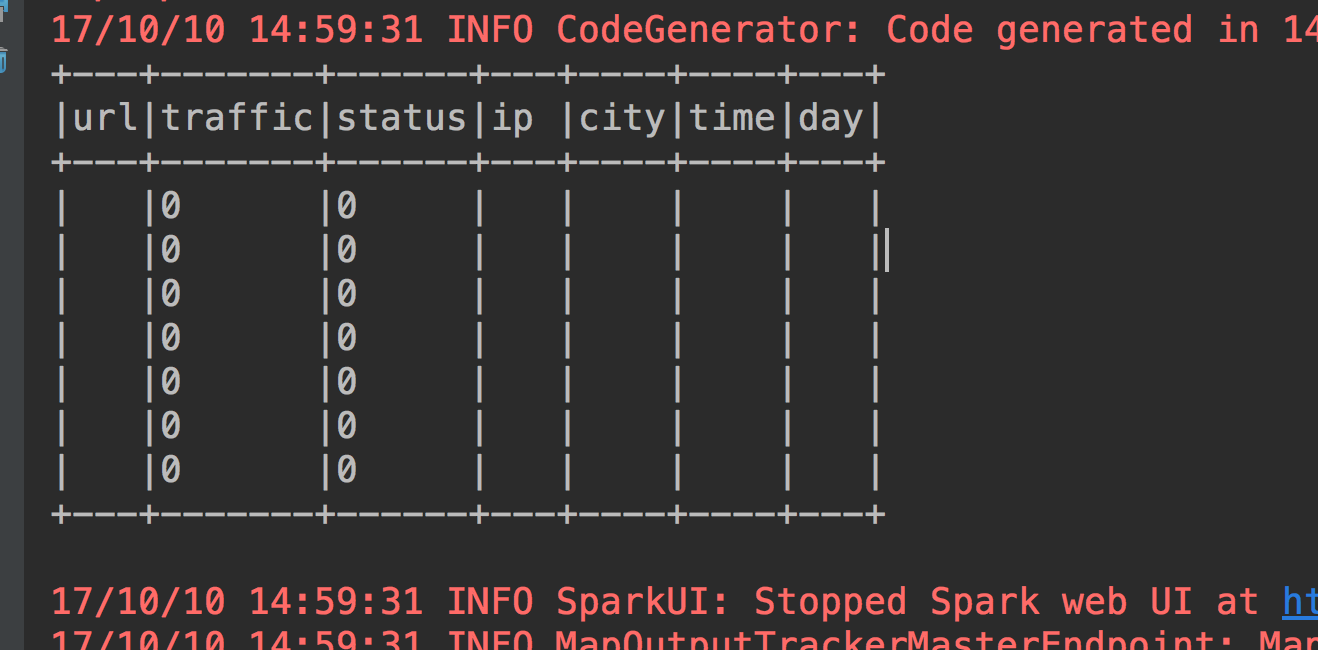
有7条空数据,那其实这7条数据可以直接丢掉了。那么就用scala的filter来处理掉
val accessDFclean = accessDF.filter("url!='' or ip!='' or city!='' or time!='' or day!=''")
accessDFclean.filter("url==''").show()我们再看看show的结果
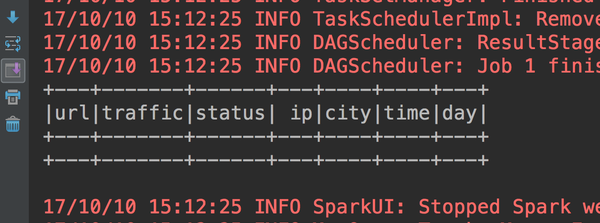
7条数据已经被过滤掉了。
下面再看看traffic缺失情况。
这个有一定数量,当然最好是想办法去处理缺失值,但是对于这里几十万的数据量来说,也可以丢掉。索性就丢掉吧。当然如果要处理也可以,下面介绍一下几种方法。
a.删除含有缺失值的个案
有简单删除法和权重法。简单删除法是对缺失值进行处理的最原始方法。它将存在缺失值的个案删除。如果数据缺失问题可以通过简单的删除小部分样本来达到目标,那么这个方法是最有效的。
b.可能值插补缺失值
(1)均值插补: 数据的属性分为定距型和非定距型。如果缺失值是定距型的,就以该属性存在值的平均值来插补缺失的值;如果缺失值是非定距型的,就根据统计学中的众数原理,用该属性的众数(即出现频率最高的值)来补齐缺失的值。
(2)极大似然估计: 最大似然是一个有效且实用的处理随机缺失数据的方法,且对于大样本来说是最合适的,但它有一个限制条件:它需要包含所有缺失变量的联合概率的模型。因此比较适合于线性模型和对数线性模型。
(3)K最近邻居法 : 先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的K个样本,将这K个值加权平均来估计该样本的缺失数据。
(3)多重插补: 多值插补的思想来源于 贝叶斯估计 ,认为待插补的值是随机的,它的值来自于已观测到的值。具体实践上通常是估计出待插补的值,然后再加上不同的噪声,形成多组可选插补值。根据某种选择依据,选取最合适的插补值。
本文就以均值插补的方法简单的完成这个缺失数据的处理,其实有时间的话还是应该去试试下面三种方法的,毕竟涉及的内容和知识比较丰富,预测缺失值的准确性也是比较高的,本篇文章就不细说了,对于KNN,之前我有一篇文章,可以作为KNN这个算法学习的一个案例。 文章地址
现在我们的数据基本上就可以为我们的项目服务了。当然先把这一步数据清洗的完整代码写上来:
package com.ApacheCommon.log
import org.apache.spark.sql.{SaveMode, SparkSession}
import org.apache.spark.sql.functions._
* 使用Spark完成我们的数据清洗工作
object SparkStartCleanJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("SparkStartCleanJob")
.master("local[2]").getOrCreate()
//把我们第一步清洗的log读进来
val accessRDD = spark.sparkContext.textFile("hdfs://localhost:8020/WEB_log/Apache_common/clean_data_1/data_1")
//导入隐式转换
import spark.implicits._
val accessDF = accessRDD.map(_.split("\t")).map(line => if(line.length==5) {
Info(
line(1), line(3).toLong, line(2), IpUtils.getCity(line(2)), line(0), line(0).substring(0,10).replaceAll("-", "")
)} else {
Info("", 0, "", "", "", "")
}).toDF()
//测试用代码
//查看缺失值
//accessDFclean.filter("url=='' or ip=='' or city=='' or time=='' or day==''").show()
//查看traffic正常的数据个数
//println(accessDFclean.filter("traffic==0").count())
//查看schema信息
//accessDF.printSchema()
//打印前20条数据
//accessDF.show(false)
//accessDFclean.filter("traffic > 0").filter("traffic < 50000").orderBy("traffic").show(false)
//accessDFclean.filter("traffic > 0").filter("traffic < 50000").describe("traffic").show(false)
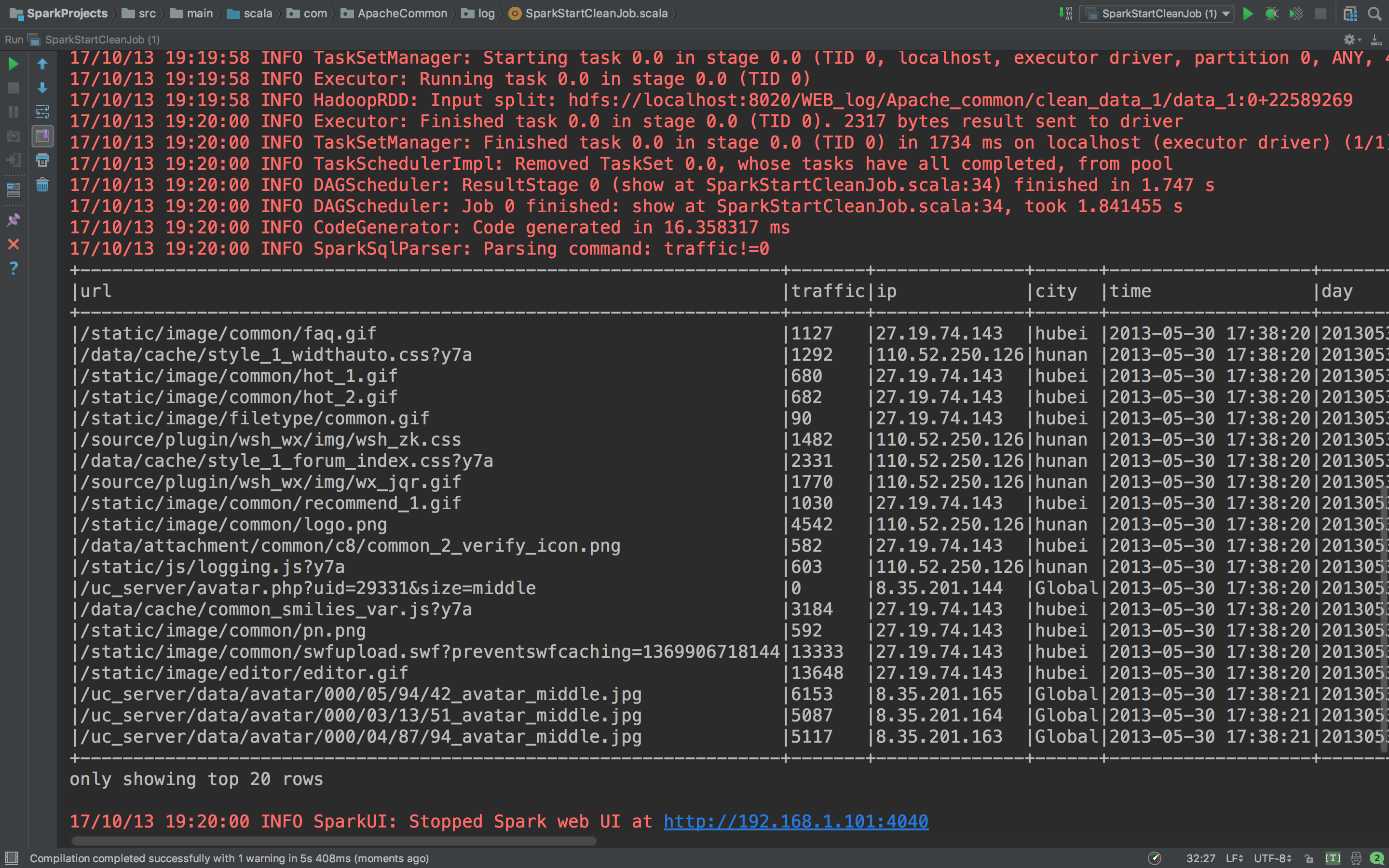
val accessDFclean = accessDF.filter("url!='' or ip!='' or city!='' or time!='' or day!=''")
val accessdataframe = accessDFclean.filter("traffic!=0")
//以csv的格式写入到本地
//accessdataframe.coalesce(1).write.format("csv")
//.mode(SaveMode.Overwrite).partitionBy("day").save("/Users/chandler/Desktop/log_test")
//以parquet的格式将清洗过的数据按照day分区存入HDFS里面去,注意coalesce表示输出为一个文件,这也是一个调优点
accessdataframe.coalesce(1).write.format("parquet").mode(SaveMode.Overwrite)
.partitionBy("day").save("hdfs://localhost:8020/WEB_log/Apache_common/claen_data_2")
spark.stop()
case class Info(url: String, traffic: Long, ip: String, city: String, time: String, day: String)
再来看看hdfs上面有没有。
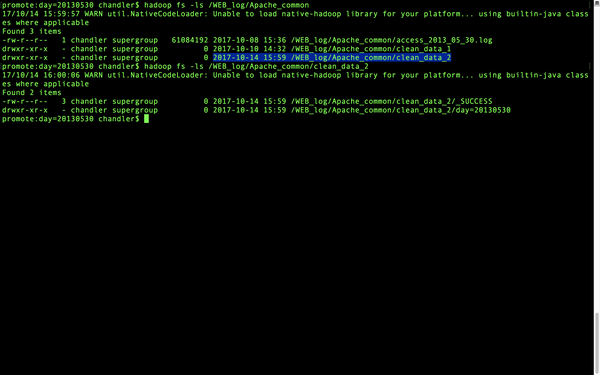
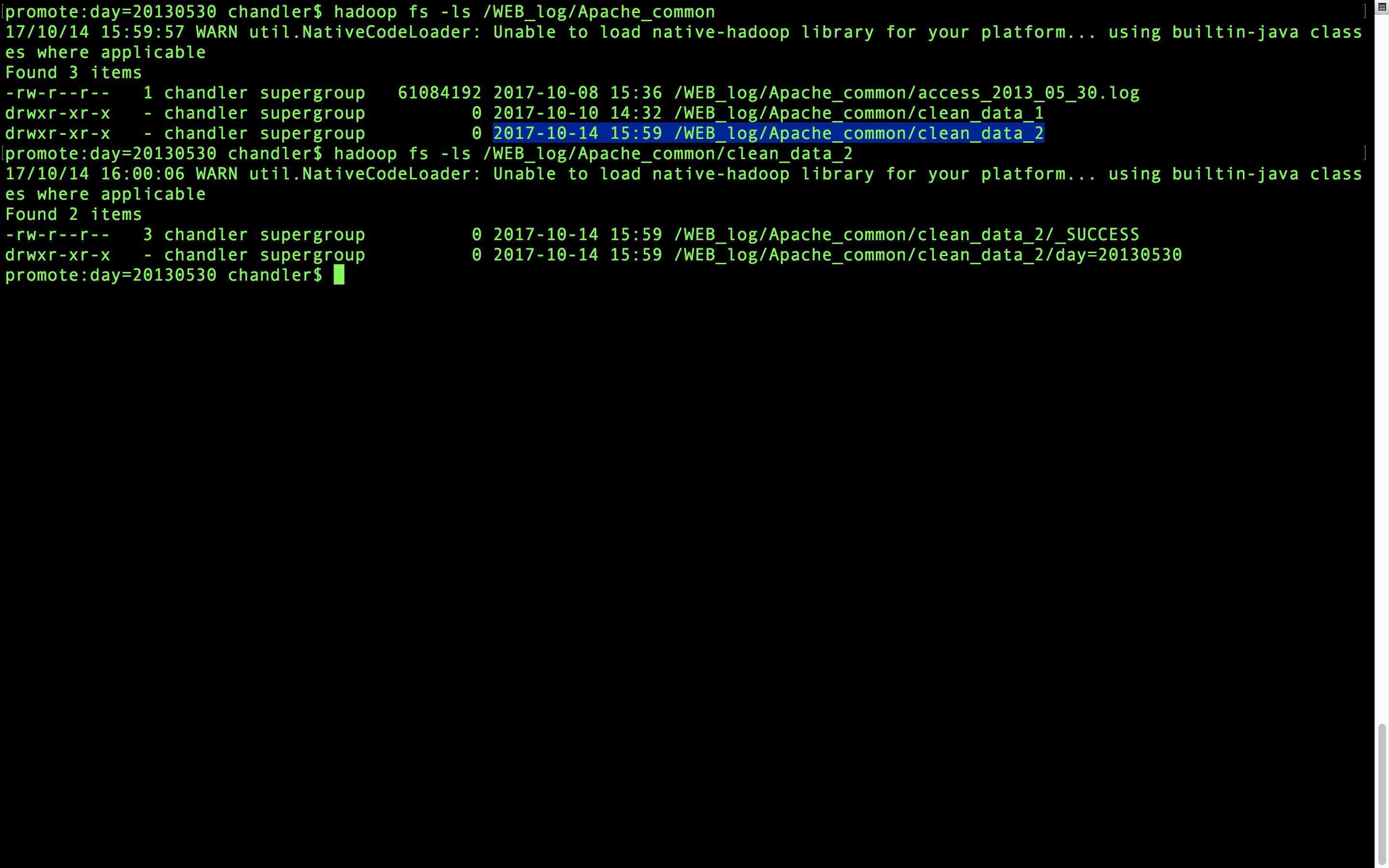
HDFS上面也有了。我们后面要做统计
2、数据统计
在用Scala做统计之前,先浪一把我又导出了一个csv文件,怎么导出上面代码里面有,被我注释了,看注释说明。那么到处了csv之后,当然在excel里面做了简单的清洗工作,因为就是一天的数据,就把时间改成整点了。改也很方便,excel里面你要么写函数,要么就直接使用分列功能。函数不会的话,百度、google都有。csv文件大致就这样。
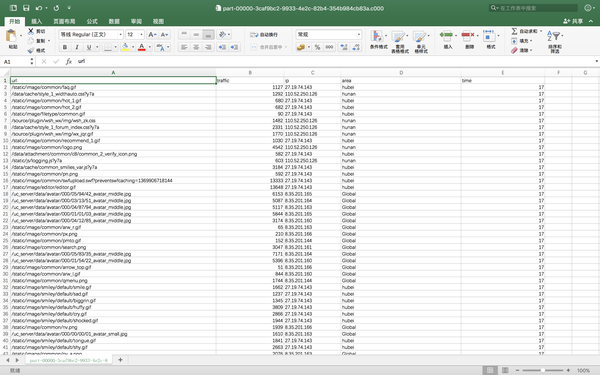
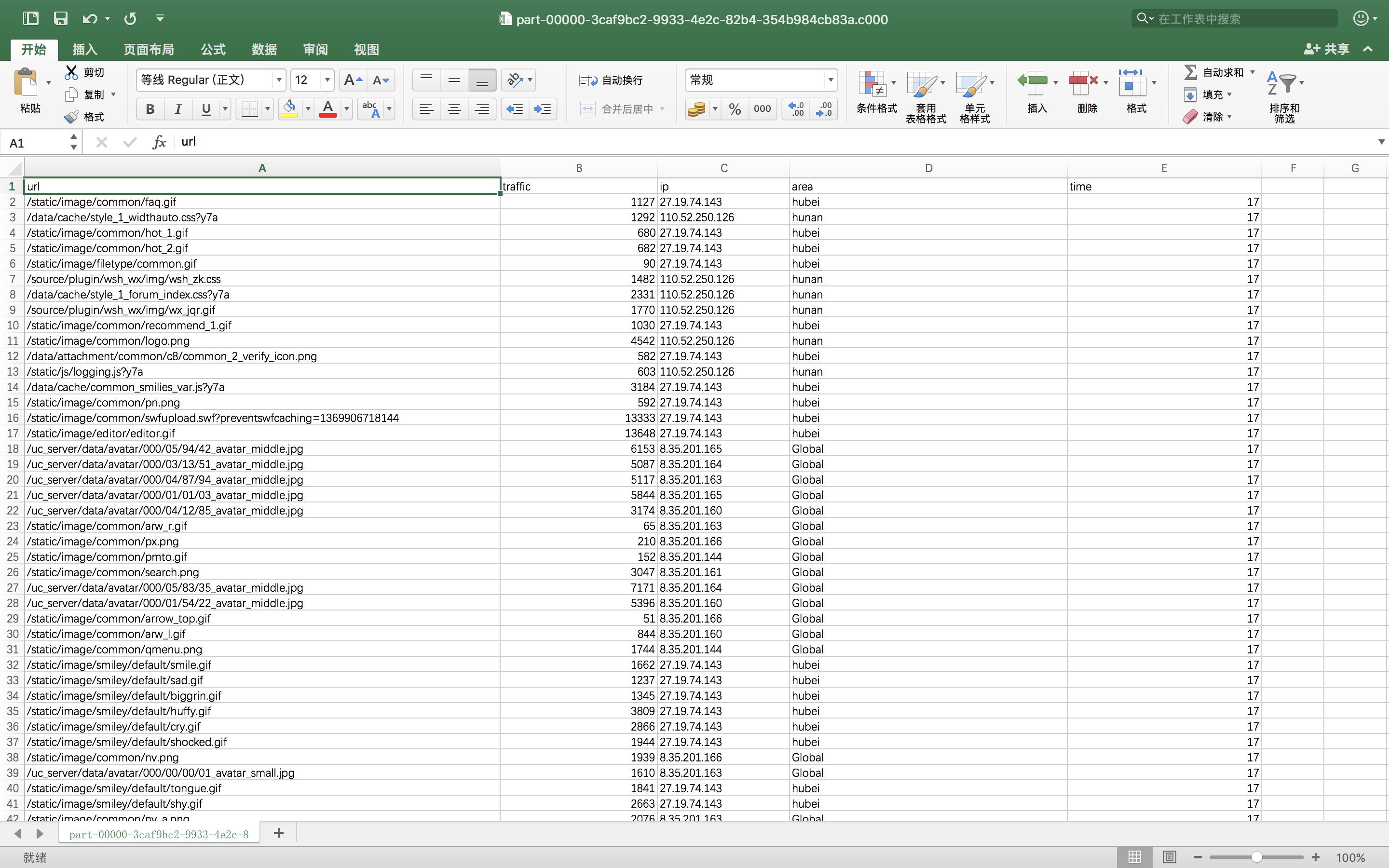
然后可以弄一个透视表看看情况如何。
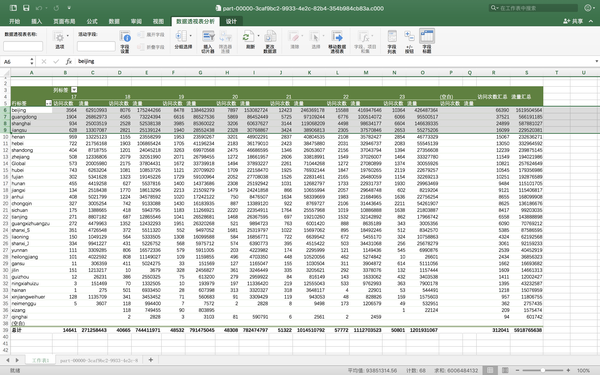
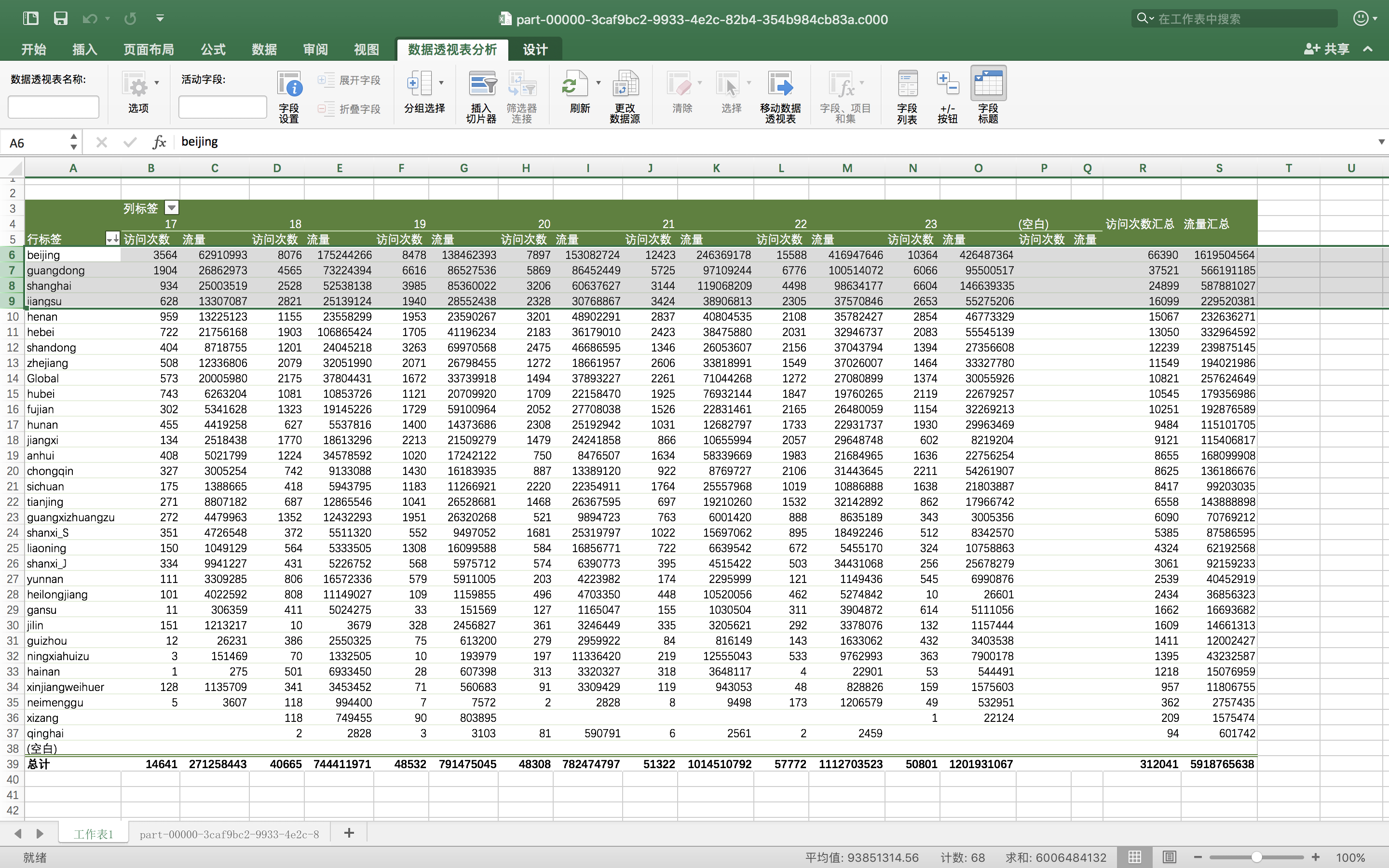
看看,啥事都离不开北上广,连个数据访问量都是北上广最高,第四名是江苏。都是富裕的地方啊。哪个Global是指的国外,这个因为我在scala的ip地址解析函数当中把源码改了,所有中文改成拼音,国外统一就是Global。
咱们用这份数据再玩点有趣的,把这个csv导入pandas里面,咱们画个图看看。
首先上代码:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
path = "/Users/chandler/Desktop/log_test/day=20130530/part-00000-3caf9bc2-9933-4e2c-82b4-354b984cb83a.c000.csv"
df = pd.read_csv(path)
log = pd.DataFrame(df)
# 按时间字段对网站流量进行求和汇总
log_times = log.groupby('time')['traffic'].agg(sum)
# 创建一个一维数组赋值给a
a = np.array([1, 2, 3, 4, 5, 6, 7])
# 创建柱状图,数据源为按时间汇总的网站流量,设置颜色,透明度和外边框颜色
plt.bar([1, 2, 3, 4, 5, 6, 7], log_times, color='#000000', alpha=0.8, align='center', edgecolor='white')
# 设置x轴标签
plt.xlabel('Time')
# 设置y周标签
plt.ylabel('Traffic')
# 设置图表标题
plt.title('Traffic from 17:38 to 23:59')
# 设置图例的文字和在图表中的位置
plt.legend(['Traffic'], loc='upper left')
# 设置背景网格线的颜色,样式,尺寸和透明度
plt.grid(color='#95a5a6', linestyle='--', linewidth=1, axis='y', alpha=0.4)
# 设置数据分类名称
plt.xticks(a, ('17:38~18:00', '18:00~19:00', '19:00~20:00', '20:00~21:00', '21:00~22:00', '22:00~23:00', '23:00~23:59'))
# 展示图表
plt.show()我们看看这个直方图
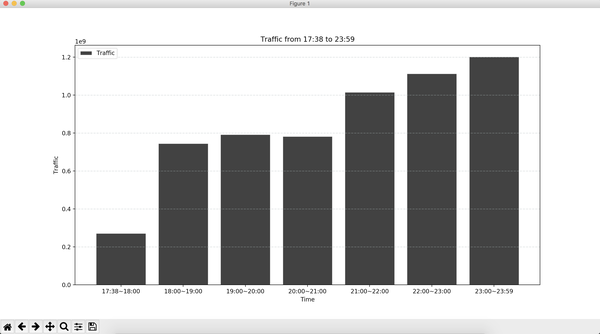
夜猫子你们好。为什么大家非得深夜上网不睡觉呢????身体很重要,身体不好怎么去撩妹?怎么敲代码?怎么做分析?
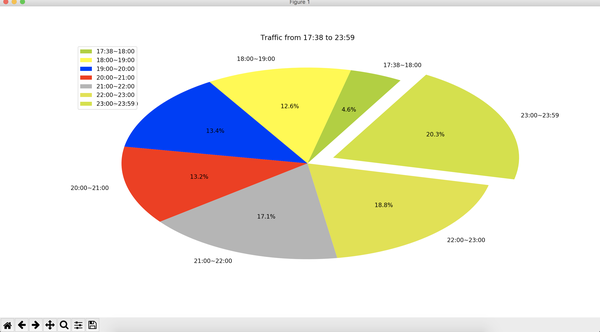
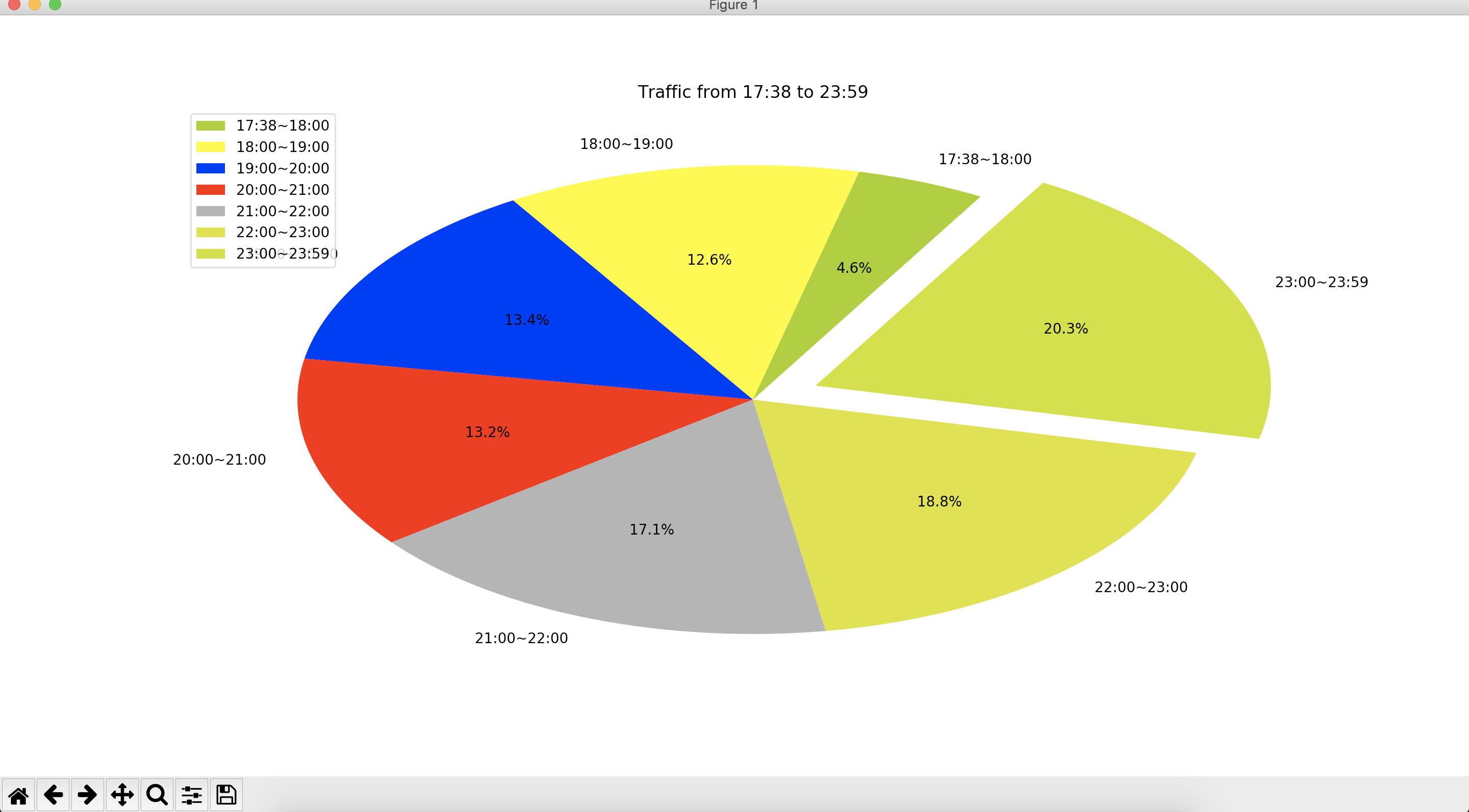
再整一个饼图。
# 设置饼图中每个数据分类的颜色
colors = ["#99CC01", "#FFFF01", "#0000FE", "#FE0000", "#A6A6A6", "#D9E021", "#C7E011"]
# 设置饼图中每个数据分类的名称
name=['17:38~18:00', '18:00~19:00', '19:00~20:00', '20:00~21:00', '21:00~22:00', '22:00~23:00', '23:00~23:59']
# 创建饼图,设置分类标签,颜色和图表起始位置等
plt.pie(log_times, labels=name, colors=colors, explode=(0, 0, 0, 0, 0, 0, 0.15), startangle=60, autopct='%1.1f%%')
# 添加图表标题
plt.title('Traffic from 17:38 to 23:59')
# 添加图例,并设置显示位置
plt.legend(['17:38~18:00', '18:00~19:00', '19:00~20:00', '20:00~21:00', '21:00~22:00', '22:00~23:00', '23:00~23:59'], loc='upper left')
# 显示图表
plt.show()
再来看看散点图
data = df[['time', 'traffic', 'area']]
plt.scatter(data['traffic'], data['time'], alpha=0.3)
plt.title('Traffic from 17:38~23:59')
plt.show()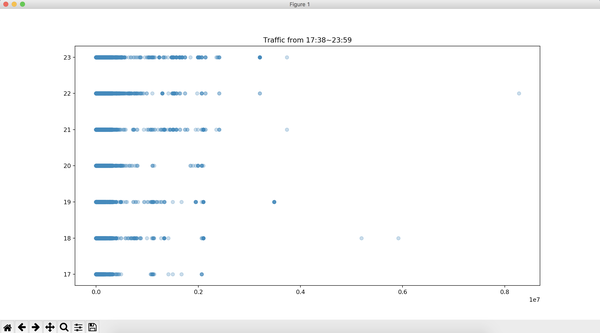
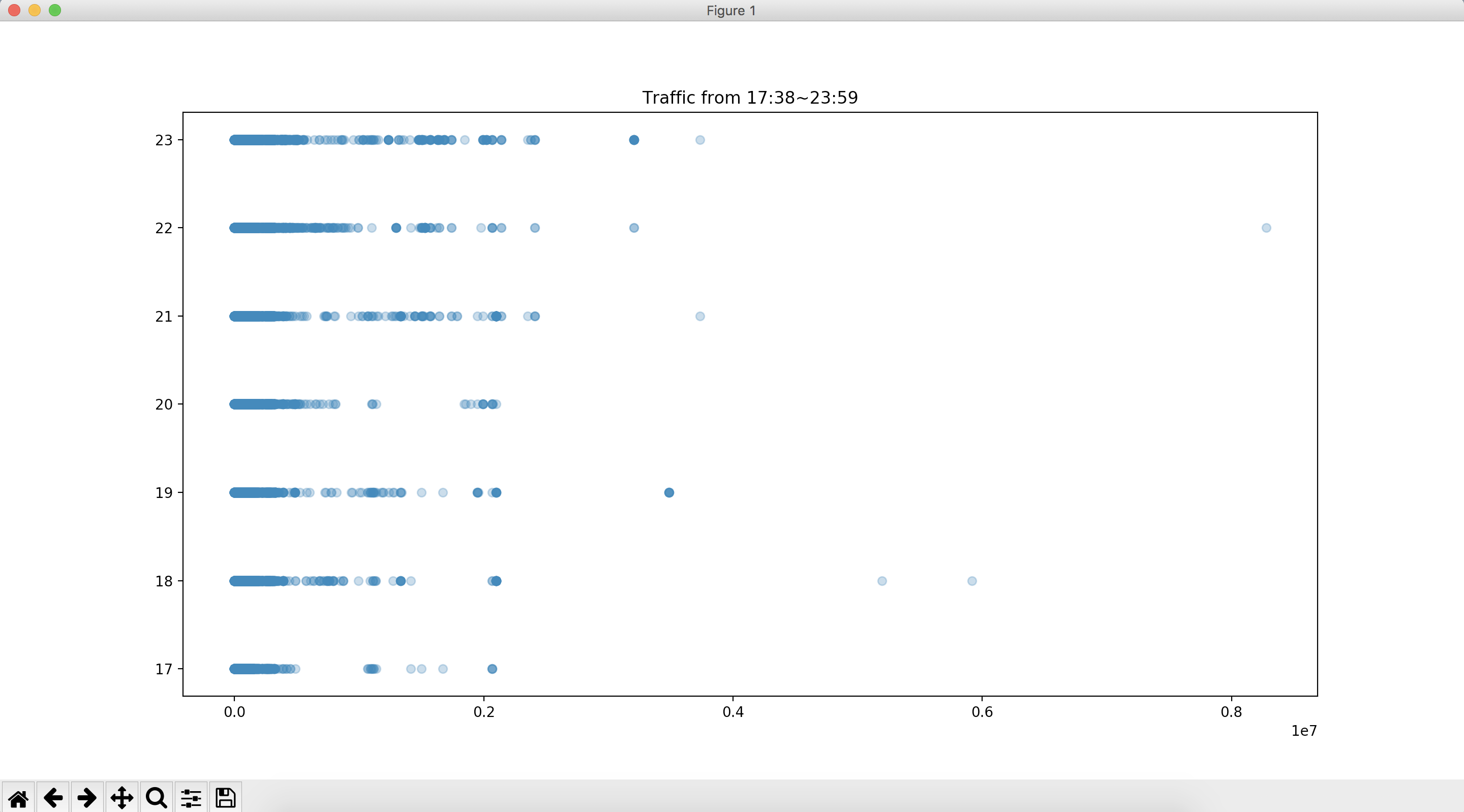
看吧,其实还是有很多异常值的,如果画箱线图会更明显,是个高度偏正态分布,因为这个数据我自己都忘记什么时候来的了,就在电脑里,我看是日志,正好拿来做这个项目,any how!这篇文章主要目的还是在操作上面,关于缺失值以及异常值的处理那也算是个大学问了,缺失值上面有讲到,异常值也是有处理方法的,可以考虑转换。如果不是很偏就认为是正态分布也是可以的。好了,也不多扯了,pandas和excel就玩到这里吧,下面回归大数据相关操作和统计了。
我们上面说到,已经把第二步清洗好的数据以parquet的格式存储到HDFS上面了,那么我们再单独创建一个叫做StatisticsJob的scala的类来做相关统计。先把基本的代码写好。
package com.ApacheCommon.log
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{count, sum}
* 统计Spark作业
object StatisticsJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("StatisticsJob")
.master("local[2]").getOrCreate()
val accessdataframe = spark.read.format("parquet").load("hdfs://localhost:8020/WEB_log/Apache_common/claen_data_2")
accessdataframe.printSchema()
accessdataframe.show(false)
spark.stop()
运行看看parquet读进来有没有问题。
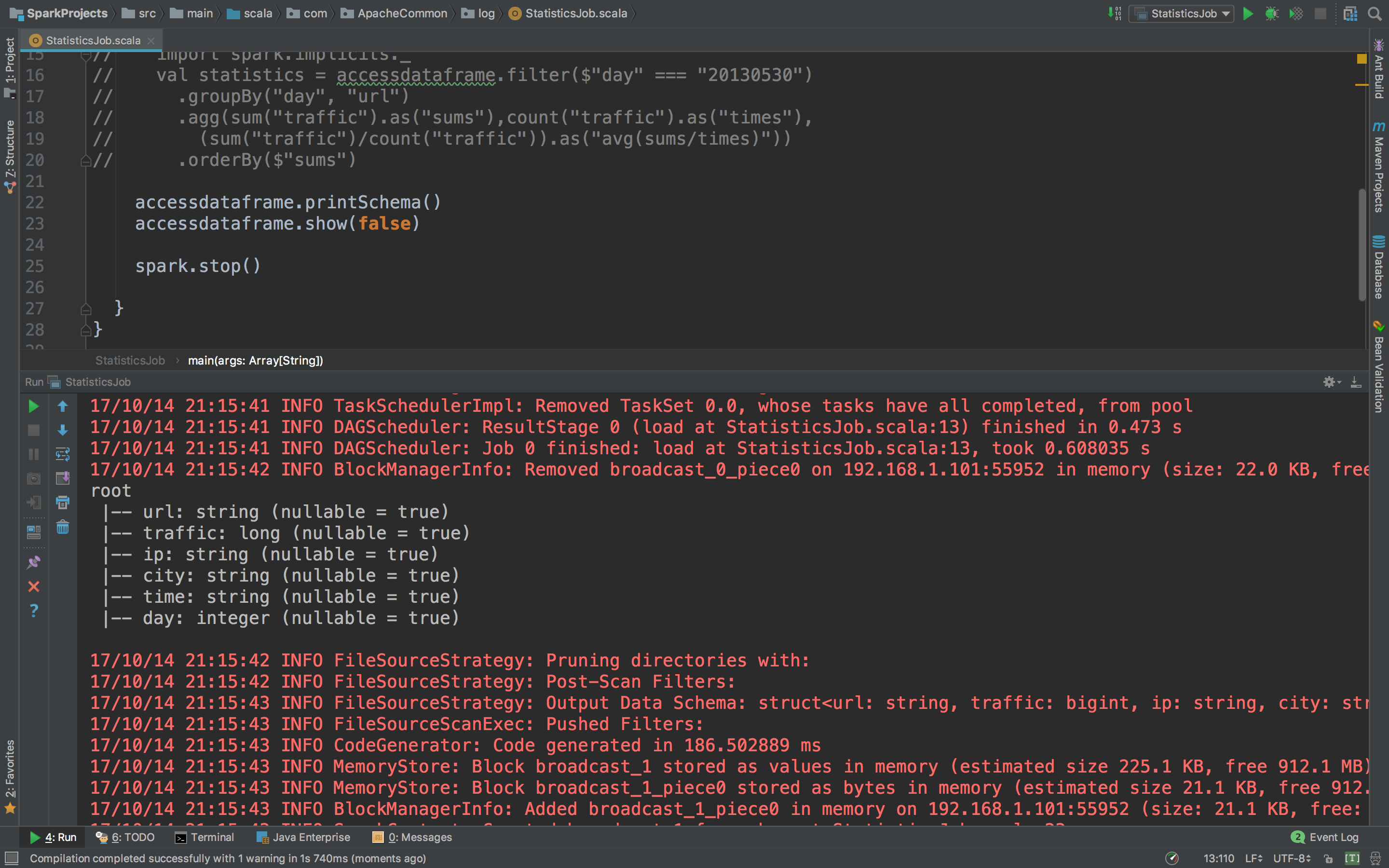
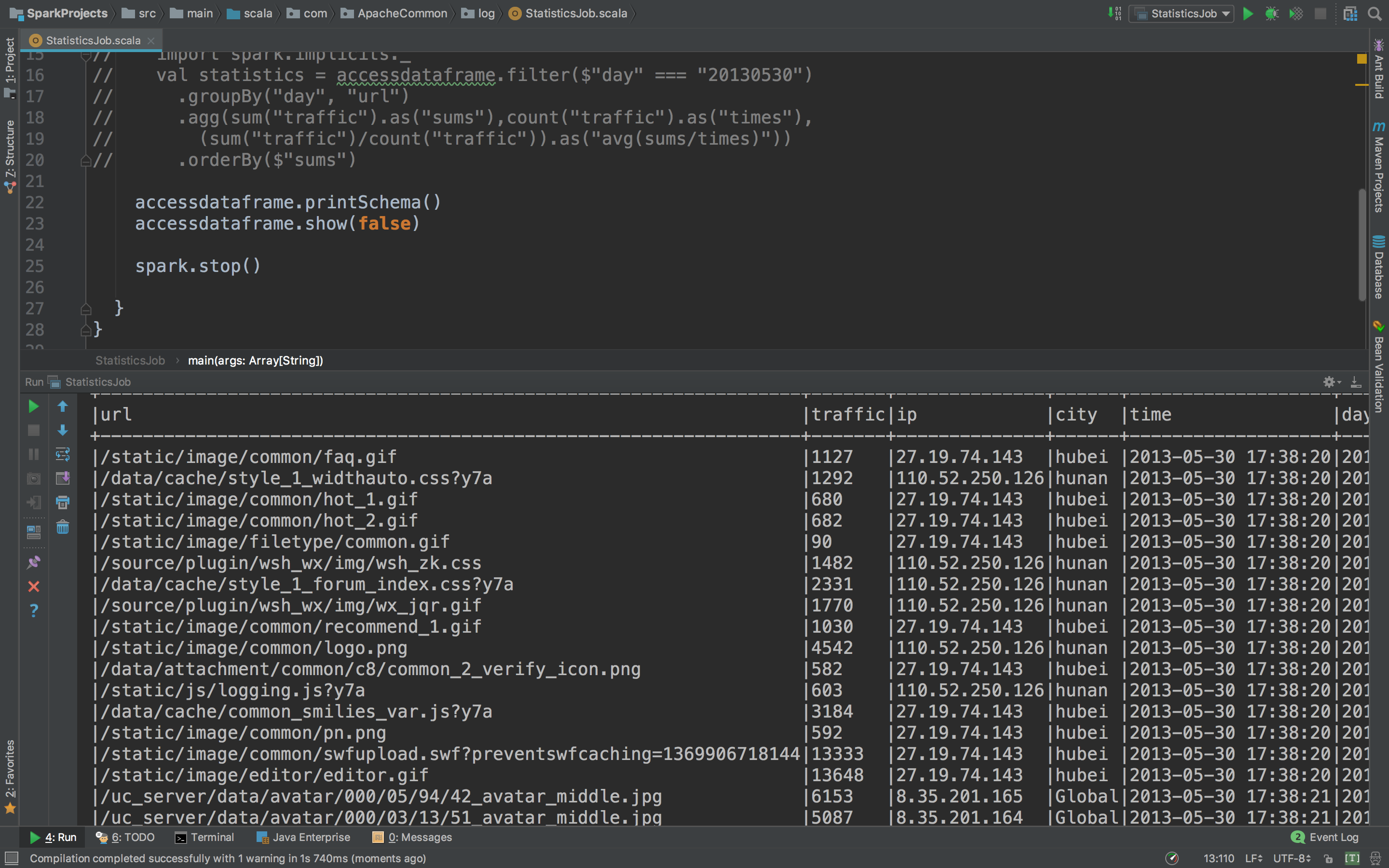
读进来了,但是!仔细观察Schema最后一个day怎么会是integer??wtf???这个day不应该是string类型吗?这里要注意,spark是有一个参数可以控制它的,默认情况下spark会给我们自动推导格式,我们只要把这个关闭就好了。怎么关闭呢?spark官网上有这一段。


把这个禁用,那么所有的就被当作是字符串类型,要的就是这个字符串类型,这也是一个调优点,把代码改一下。
package com.ApacheCommon.log
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{count, sum}
* 统计Spark作业
object StatisticsJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("StatisticsJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled", "false")
.master("local[2]").getOrCreate()
val accessdataframe = spark.read.format("parquet").load("hdfs://localhost:8020/WEB_log/Apache_common/clean_data_2")
accessdataframe.printSchema()
accessdataframe.show(false)
spark.stop()
}在运行一下就对了。
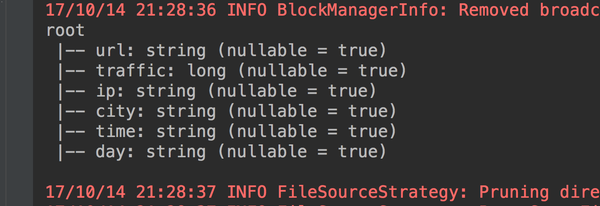
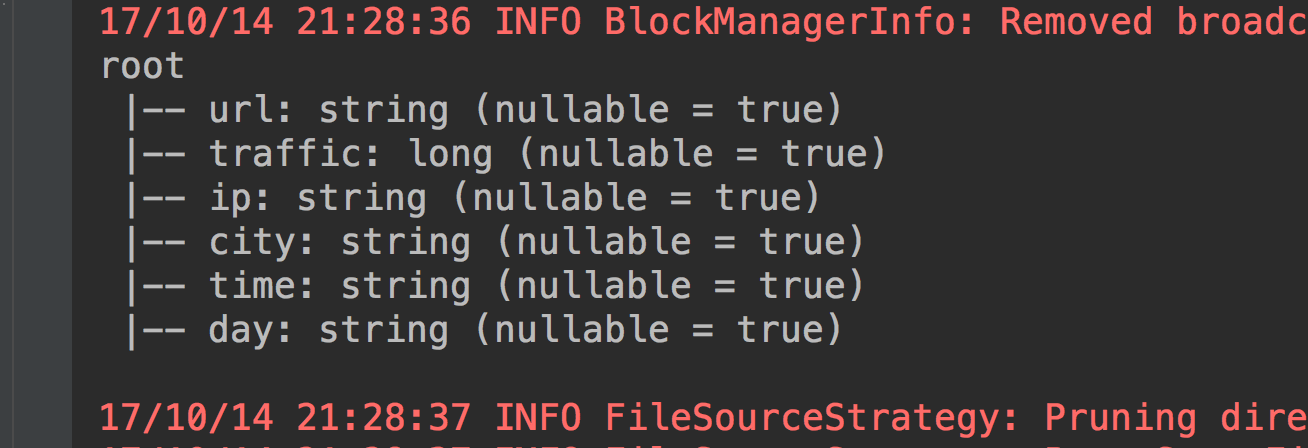
下面就正式开始进行统计。
首先看看我们的项目需求:
1、IP地址
注:IP地址提取地理区域
2、浏览量PageView
3、访问网站的独立 IP 个数
4、注册用户数
5、跳出率Bounce Rate
6、统计访问量最高的url topN访问次数
7、按照地理区域统计访问量最高的url topN访问次数
8、按照流量统计访问量最高的url topN访问次数
需求还挺多,看着确实多,一个一个来吧。
a、计算url的PV和流量
所以可以先写这样一段代码,按照day和url字段进行groupBy再利用sum函数和count函数计算PV和流量
package com.ApacheCommon.log
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{count, sum}
* 统计Spark作业
object StatisticsJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("StatisticsJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled", "false")
.master("local[2]").getOrCreate()
val accessdataframe = spark.read.format("parquet").load("hdfs://localhost:8020/WEB_log/Apache_common/clean_data_2")
import spark.implicits._
// 按照url进行统计每个url的总流量和访问次数
val statistics_url = accessdataframe.filter($"day" === "20130530")
.groupBy("day", "url")
.agg(sum("traffic").as("traffic_sums"),count("traffic").as("page_view"),
(sum("traffic")/count("traffic")).as("avg(traffic_sums/page_view)"))
.orderBy($"traffic_sums")
statistics_url.orderBy(statistics_url("traffic_sums").desc).show(false)
spark.stop()
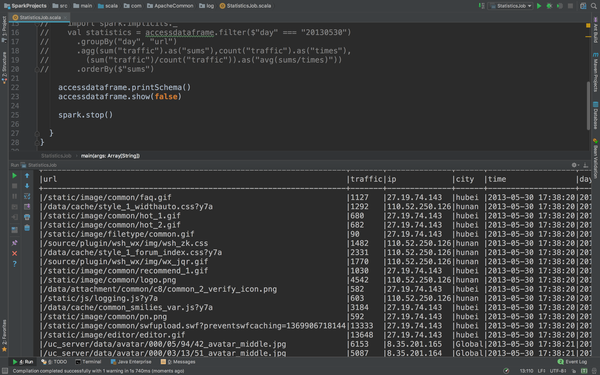
}看看结果怎么样。
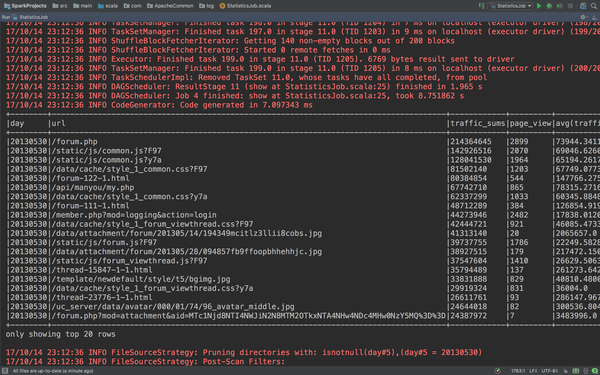
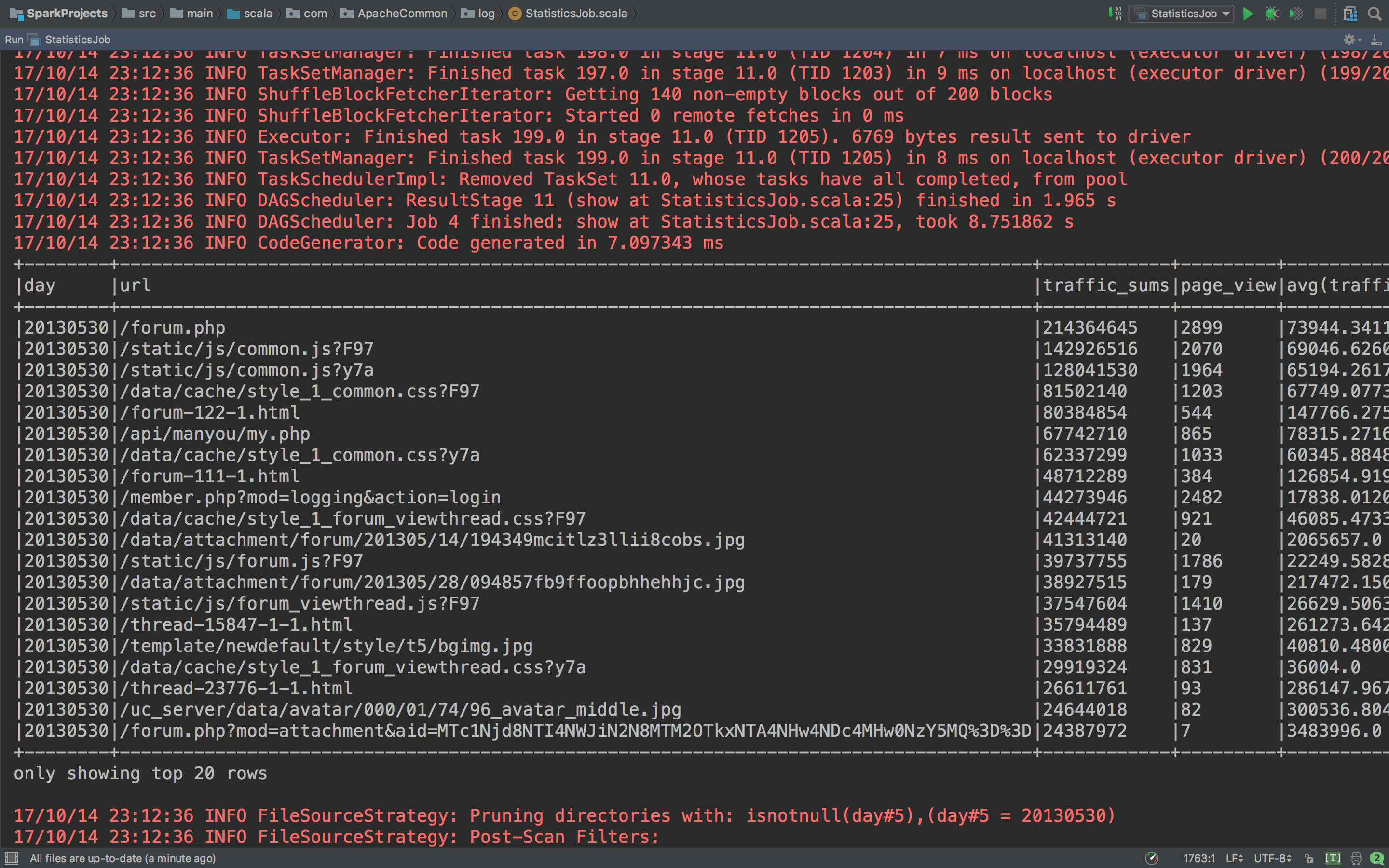
看看这张表,每个url的总的PageView以及总的流量一目了然。这里把代码稍微改一下,这样子写有点难看了。
package com.ApacheCommon.log
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions.{count, sum}
* 统计Spark作业
object StatisticsJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("StatisticsJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled", "false")
.master("local[2]").getOrCreate()
val accessdataframe = spark.read.format("parquet").load("hdfs://localhost:8020/WEB_log/Apache_common/clean_data_2")
urlStatistics(spark, accessdataframe)
spark.stop()
* 计算url的PV和流量
* @param spark
* @param accessdataframe
def urlPvTrafficStatistics(spark: SparkSession, accessdataframe: DataFrame): Unit = {
import spark.implicits._
// 按照url进行统计每个url的总流量和访问次数
val statistics_url_Pv_traffic = accessdataframe.filter($"day" === "20130530")
.groupBy("day", "url")
.agg(sum("traffic").as("traffic_sums"),count("traffic").as("page_view"),
(sum("traffic")/count("traffic")).as("avg"))
.orderBy($"traffic_sums")
statistics_url_Pv_traffic.orderBy(statistics_url("traffic_sums").desc).show(false)
}好了,因为想把数据写到mysql里面,那么必然的,还要写一个mysql的工具类。
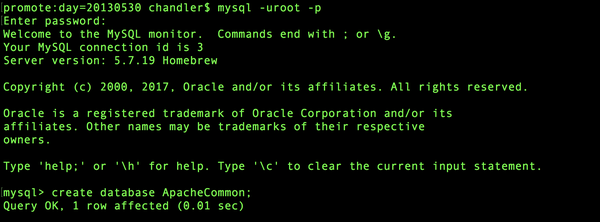
所以定义一个MySQLUtils。当然在这之前先去mysql创建一个database。
然后进入IDEA开发。
package com.ApacheCommon.log
import java.sql.DriverManager
* MySQL操作工具类
object MySQLUtils {
* 获取数据库连接
def getConnection() = {
DriverManager.getConnection("jdbc:mysql://localhost:3306/ApacheCommon", "root", "chuchu910408")
def main(args: Array[String]): Unit = {
println(getConnection())
我们看看能不能连接到mysql。


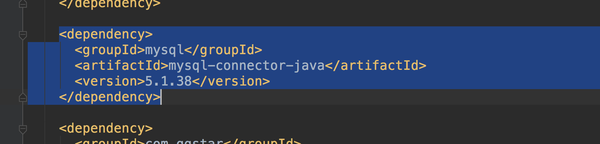
哎!报错了,这个肯定是mysql的connection没有导入,可以在项目右侧的maven的projects里面检查一下dependency,看看里面有没有mysql的connection,没有说明你没有导入。
导入很简单,在pom里面加上mysql的dependency就好了
我们再运行看看。


成功连接了,下面把mysql工具类完善一下。
package com.ApacheCommon.log
import java.sql.{Connection, DriverManager, PreparedStatement}
* MySQL操作工具类
object MySQLUtils {
* 获取数据库连接
def getConnection() = {
DriverManager.getConnection("jdbc:mysql://localhost:3306/ApacheCommon", "root", "chuchu910408")
* 释放MySQL数据库连接等资源
* @param connection
* @param pstmt
def release(connection: Connection, pstmt: PreparedStatement): Unit = {
try {
if(pstmt != null) {
pstmt.close()
} catch {
case e: Exception => e.printStackTrace()
} finally {
if(connection != null) {
connection.close()
def main(args: Array[String]): Unit = {
println(getConnection())
}好了,既然我们要把上面的统计数据存入到数据库,那肯定要创建表嘛。那就写sql语句创建一下咯。
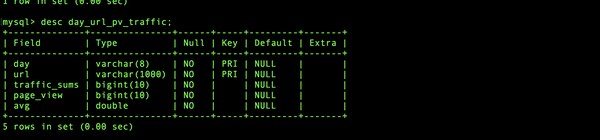
create table day_url_pv_traffic (
day varchar(8) not null,
url varchar(1000) not null,
traffic_sums bigint(10) not null,
page_view bigint(10) not null,
avg double not null,
primary key (day, url)
);
那么表创建好了,接下来创建一个模型类。当然还有创建DAO对数据库操作相关的。
首先是创建UrlPvTraffic模型类。
package com.ApacheCommon.log
//每个url的PV和traffic统计的实体类
case class UrlPvTraffic (day:String, url:String, traffic_sums:Long, page_view :Long, avg:Double)
然后创建DAO对象。
package com.ApacheCommon.log
import java.sql.{Connection, PreparedStatement}
import scala.collection.mutable.ListBuffer
*各个需求统计的DAO操作
object StatisticsDAO {
* 批量保存UrlPvTraffic到mysql数据库
* @param list
def insertDayUrlPvTraffic(list: ListBuffer[UrlPvTraffic]): Unit = {
var connection:Connection = null
var pstmt:PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //把自动提交关闭改为手动提交
val sql = "insert into day_url_pv_traffic(day, url, traffic_sums, page_view, avg) " +
"VALUES (?, ?, ?, ?, ?) " +
"ON DUPLICATE KEY UPDATE day=VALUES(day),url=VALUES(url), " +
"traffic_sums=VALUES(traffic_sums), page_view=VALUES(page_view), avg=VALUES(avg)"
pstmt = connection.prepareStatement(sql)
for(element <- list) {
pstmt.setString(1, element.day)
pstmt.setString(2, element.url)
pstmt.setLong(3, element.traffic_sums)
pstmt.setLong(4, element.page_view)
pstmt.setDouble(5, element.avg)
pstmt.addBatch()
pstmt.executeBatch() //执行批量处理(调优点)
connection.commit() //手动提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)


下面我们就回到我们统计的Job里面去把插入mysql的代码补充完整。还记得不?就是StatisticsJob这个类.
就是上图这个类,好了,把原先的代码补充好。
package com.ApacheCommon.log
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions.{count, sum}
import scala.collection.mutable.ListBuffer
* 统计Spark作业
object StatisticsJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("StatisticsJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled", "false")
.master("local[2]").getOrCreate()
val accessdataframe = spark.read.format("parquet").load("hdfs://localhost:8020/WEB_log/Apache_common/clean_data_2")
urlPvTrafficStatistics(spark, accessdataframe)
spark.stop()
* 计算url的PV和流量
* @param spark
* @param accessdataframe
def urlPvTrafficStatistics(spark: SparkSession, accessdataframe: DataFrame): Unit = {
import spark.implicits._
// 按照url进行统计每个url的总流量和访问次数
val statistics_url_Pv_traffic = accessdataframe.filter($"day" === "20130530")
.groupBy("day", "url")
.agg(sum("traffic").as("traffic_sums"),count("traffic").as("page_view"),
(sum("traffic")/count("traffic")).as("avg"))
.orderBy($"traffic_sums")
* 将统计结果写到mysql中
try {
statistics_url_Pv_traffic.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[UrlPvTraffic]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val url = info.getAs[String]("url")
val traffic_sums = info.getAs[Long]("traffic_sums")
val page_view = info.getAs[Long]("page_view")
val avg = info.getAs[Double]("avg")
list.append(UrlPvTraffic(day, url, traffic_sums, page_view, avg))
StatisticsDAO.insertDayUrlPvTraffic(list)
} catch {
case e: Exception => e.printStackTrace()
}现在可以执行一下,看看能不能成功写进mysql中。
无任何报错,进去mysql看看。
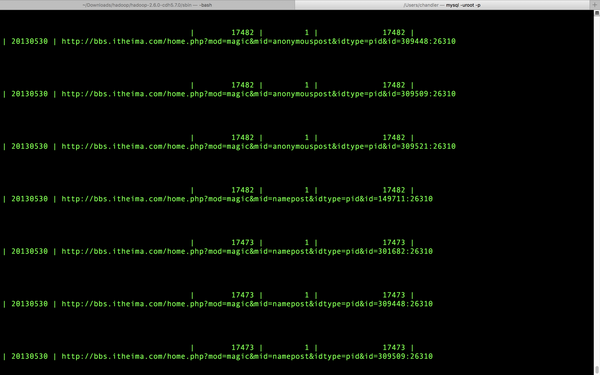
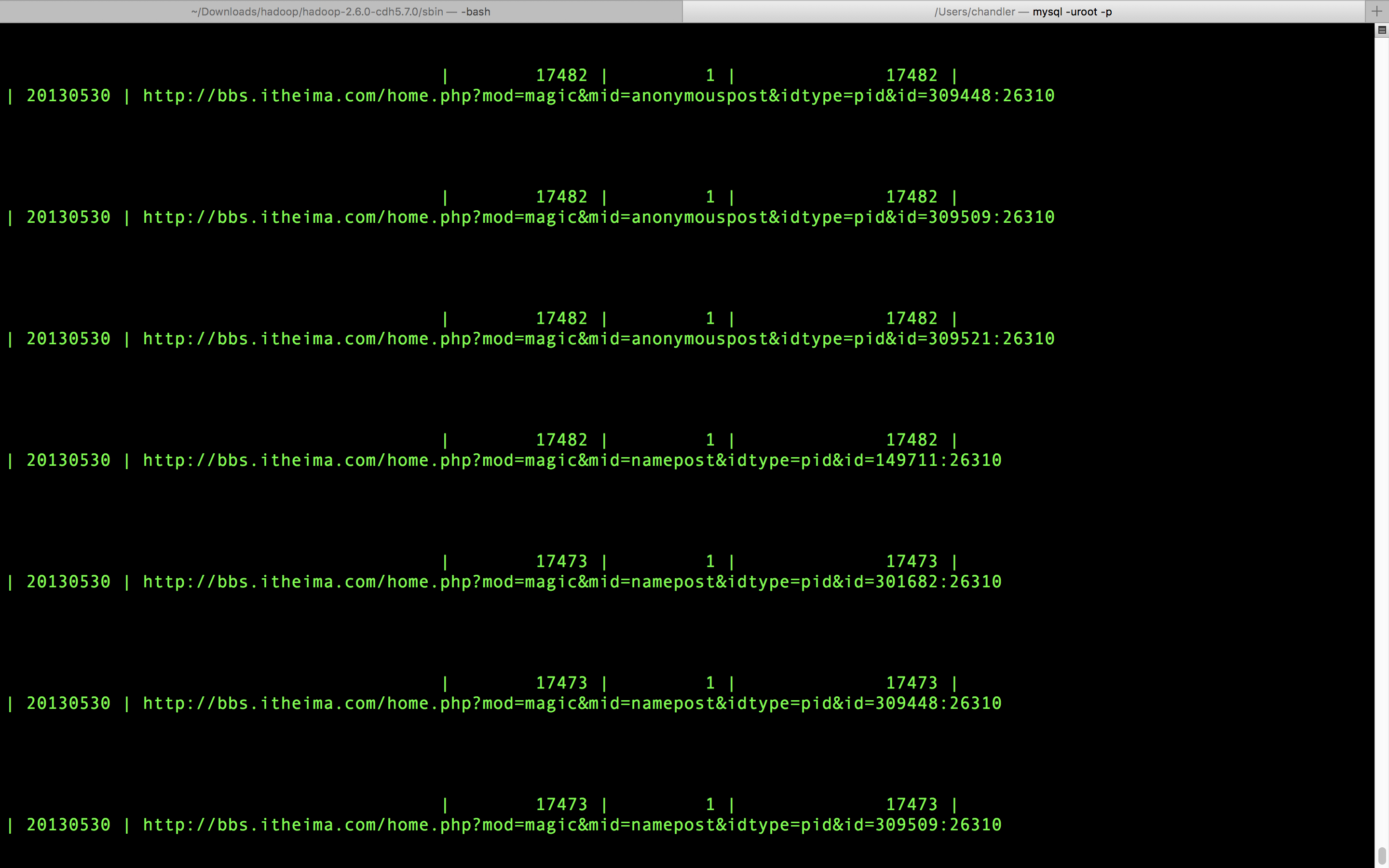
数据全进来了,但是这个看着真丑。要是想看的清爽一点,我推荐用图形客户端小工具navicat用来日常使用,真的超级好用,绝对的!至于安装和配置以及连接mysql也很简单,两三分钟的事情。可以看我 以前的一篇文章 ,有讲怎么配置。看看界面如何。
看看有没有很爽。因为我mysql里面东西太多了,比较乱。找一下ApacheCommon的数据。
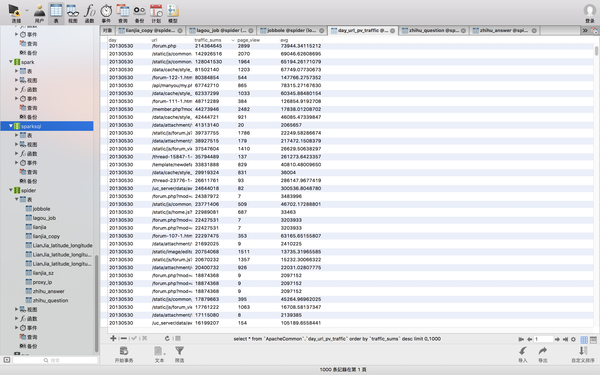
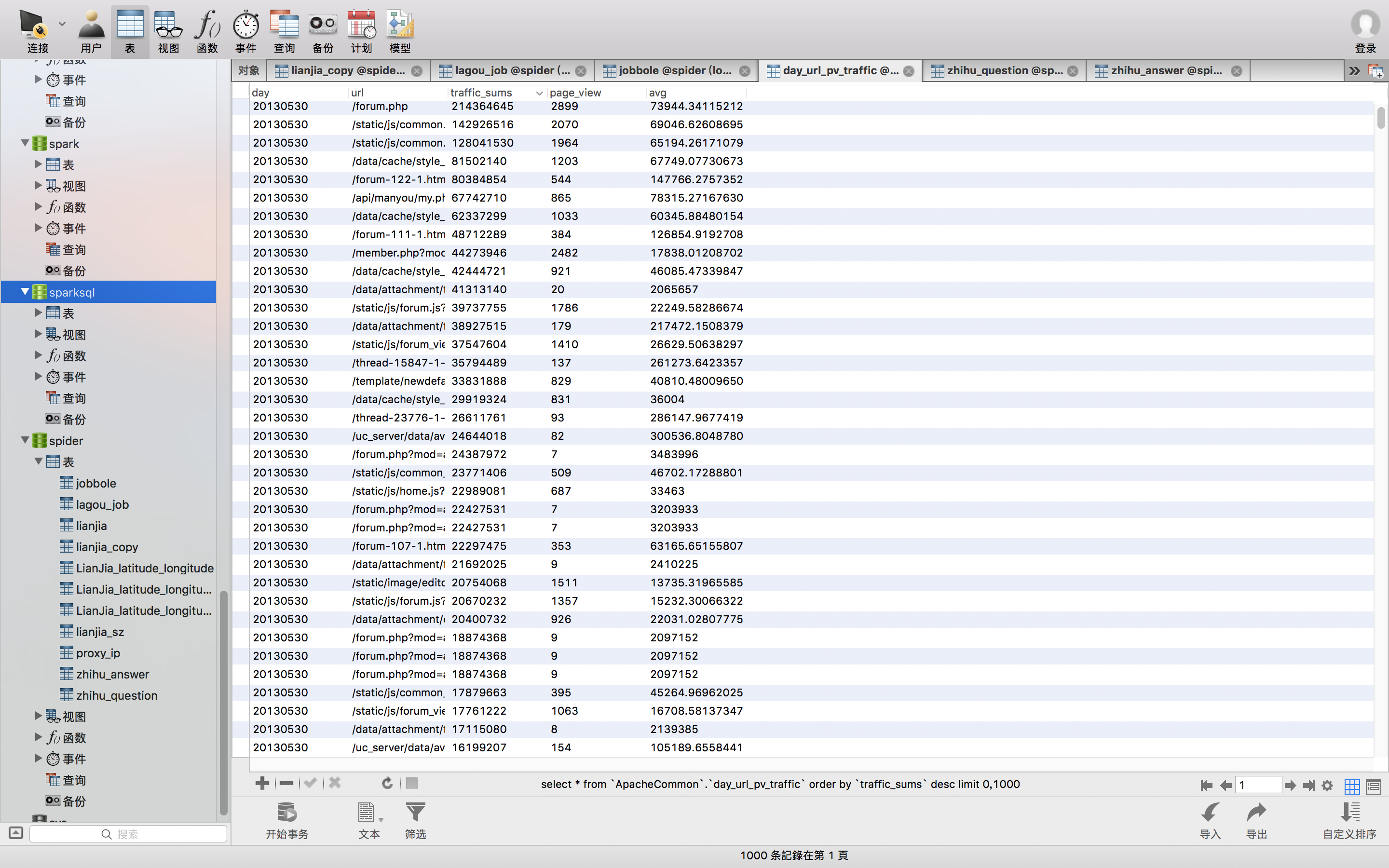
看着是不是很顺眼啊。到这里 计算url的PV和流量 代码搞定了。那也就意味着访问量PV、注册用户数、按照访问量PV统计url访问的topN、按照流量统计url访问的topN以及跳出率Bounce Rate就全搞定了。
剩下的就是IP地址、访问网站的独立 IP 个数、按照地理区域统计访问量最高的url topN访问次数。
b、计算按照地理区域统计访问量最高的url topN访问次数
开始写代码,然后先把表格show出来。先看看代码。下面的def是按照地理区域统计访问量最高的url topN访问次数的代码,上面的def是上一个是计算url的PV和流量。看注释吧。
package com.ApacheCommon.log
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions.{count, row_number, sum}
import scala.collection.mutable.ListBuffer
* 统计Spark作业
object StatisticsJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("StatisticsJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled", "false")
.master("local[2]").getOrCreate()
val accessdataframe = spark.read.format("parquet").load("hdfs://localhost:8020/WEB_log/Apache_common/clean_data_2")
//计算url的PV和流量
//urlPvTrafficStatistics(spark, accessdataframe)
//计算按照地理区域统计
urlAreaStatistics(spark, accessdataframe)
spark.stop()
* 计算url的PV和流量
* @param spark
* @param accessdataframe
def urlPvTrafficStatistics(spark: SparkSession, accessdataframe: DataFrame): Unit = {
import spark.implicits._
// 按照url进行统计每个url的总流量和访问次数
val statistics_url_Pv_traffic = accessdataframe.filter($"day" === "20130530")
.groupBy("day", "url")
.agg(sum("traffic").as("traffic_sums"),count("traffic").as("page_view"),
(sum("traffic")/count("traffic")).as("avg"))
.orderBy($"traffic_sums")
* 将统计结果写到mysql中
try {
statistics_url_Pv_traffic.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[UrlPvTraffic]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val url = info.getAs[String]("url")
val traffic_sums = info.getAs[Long]("traffic_sums")
val page_view = info.getAs[Long]("page_view")
val avg = info.getAs[Double]("avg")
list.append(UrlPvTraffic(day, url, traffic_sums, page_view, avg))
StatisticsDAO.insertDayUrlPvTraffic(list)
} catch {
case e: Exception => e.printStackTrace()
* 计算按照地理区域统计访问量最高的url topN访问次数
* @param spark
* @param accessdataframe
def urlAreaStatistics(spark: SparkSession, accessdataframe: DataFrame): Unit = {
import spark.implicits._
// 按照地理区域统计访问量最高的url topN访问次数
val url_city_statistics = accessdataframe.filter($"day" === "20130530")
.groupBy("day", "city", "url")
.agg(sum("traffic").as("traffic_sums"),
count("traffic").as("page_view"),
(sum("traffic")/count("traffic")).as("avg"))
.orderBy($"traffic_sums")
//window窗口函数在Spark SQL中的使用
url_city_statistics.select(
url_city_statistics("day"),
url_city_statistics("city"),
url_city_statistics("url"),
url_city_statistics("page_view"),
url_city_statistics("traffic_sums"),
row_number().over(
Window.partitionBy(url_city_statistics("city"))
.orderBy(url_city_statistics("page_view").desc)
).as("page_view_rank")
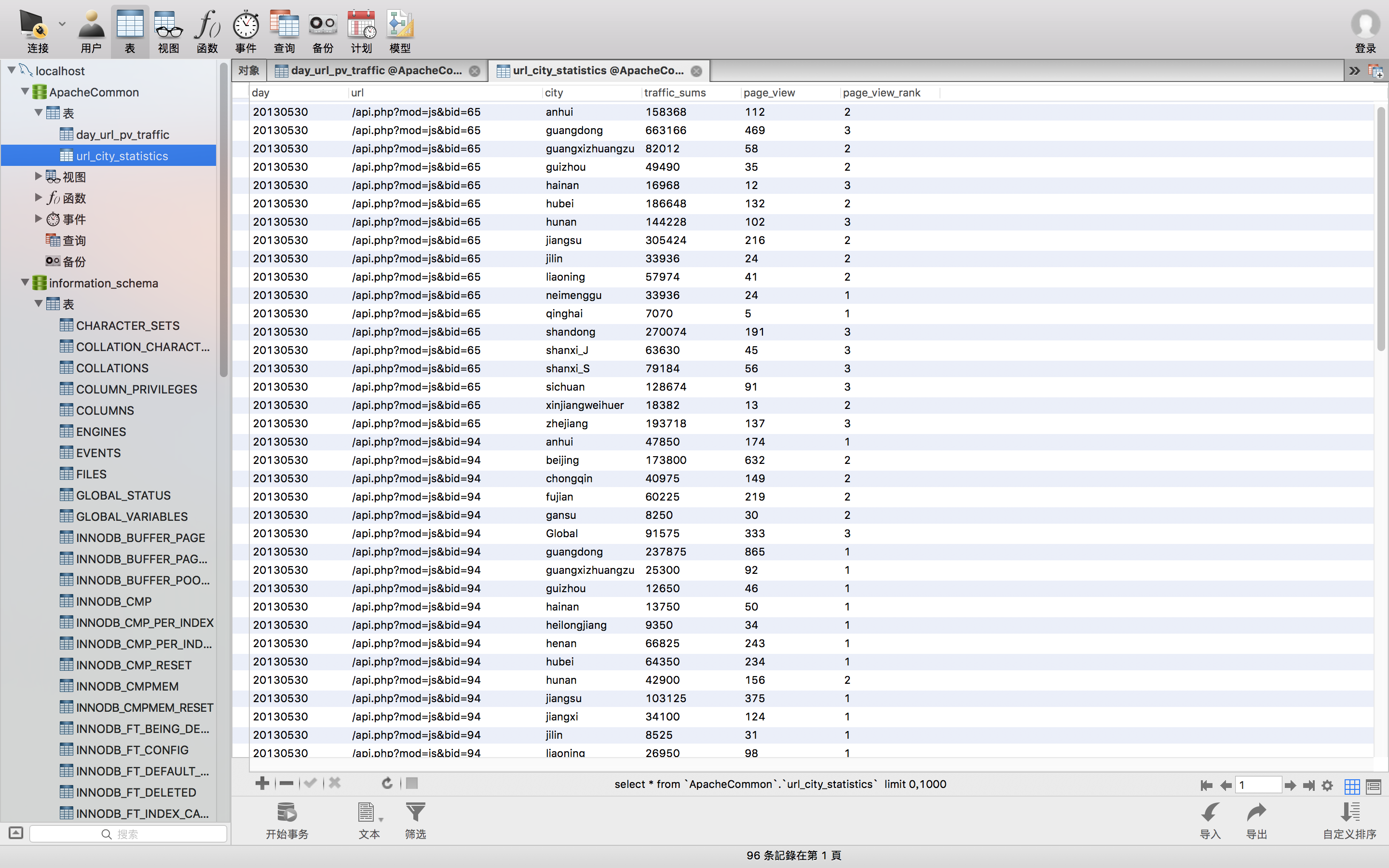
).filter("page_view_rank <= 3").show(100, false)
再看看运行的结果
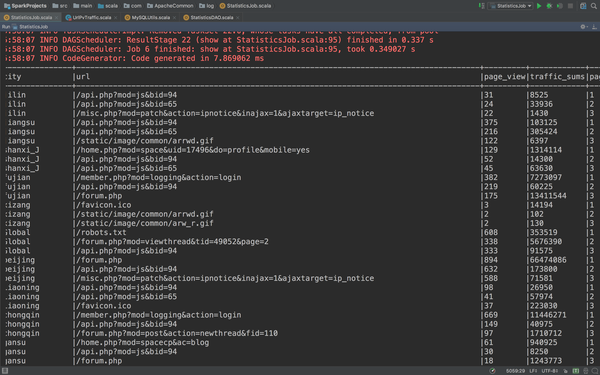
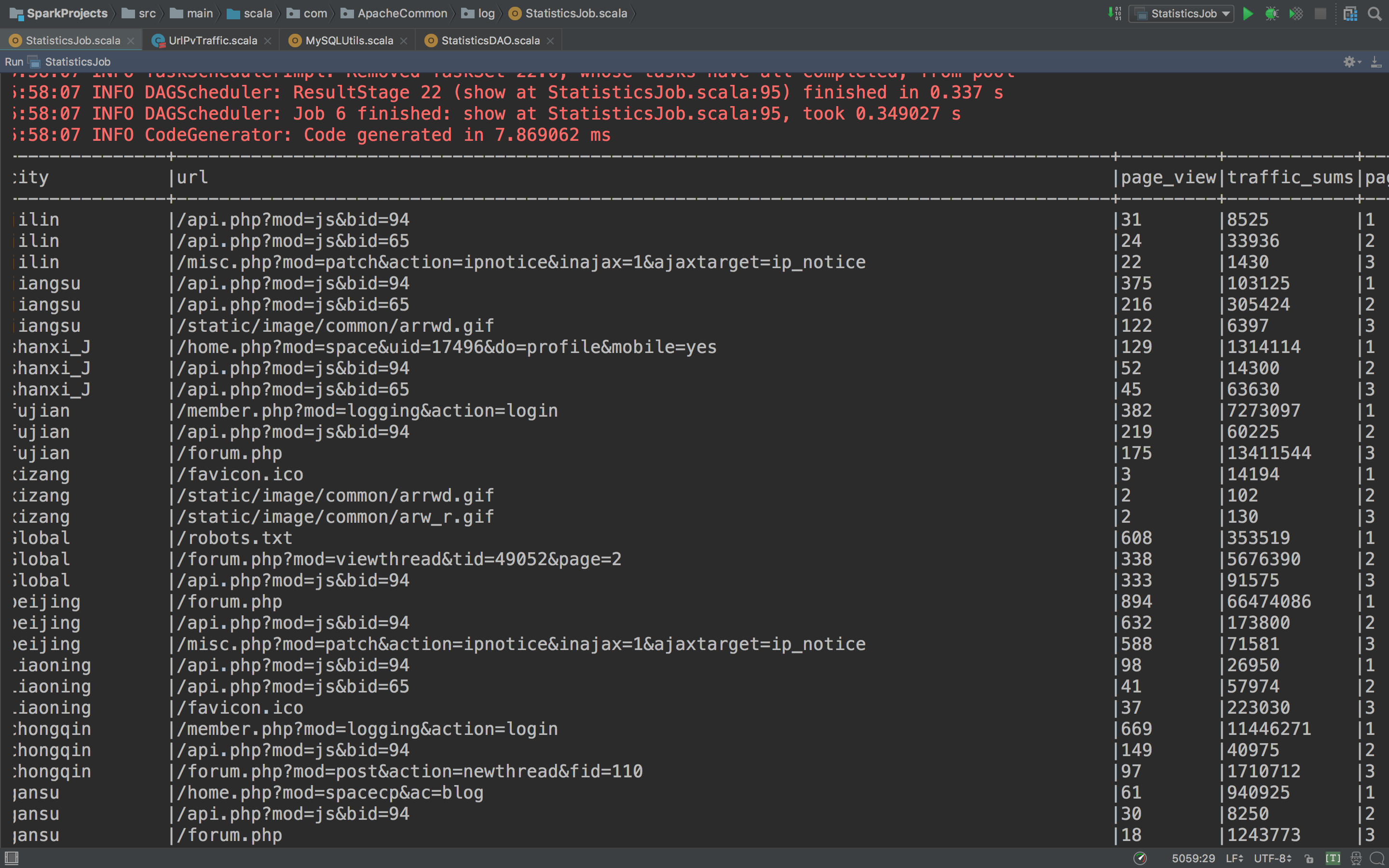
这个表格就可以使用了,接下来就是写入到mysql数据库。
还是一样的,先创建一个表到mysql里面。
create table url_city_statistics (
day varchar(8) not null,
url varchar(500) not null,
city varchar(20) not null,
traffic_sums bigint(10) not null,
page_view bigint(10) not
null,
page_view_rank int not null,
primary key (day, url, city)
);
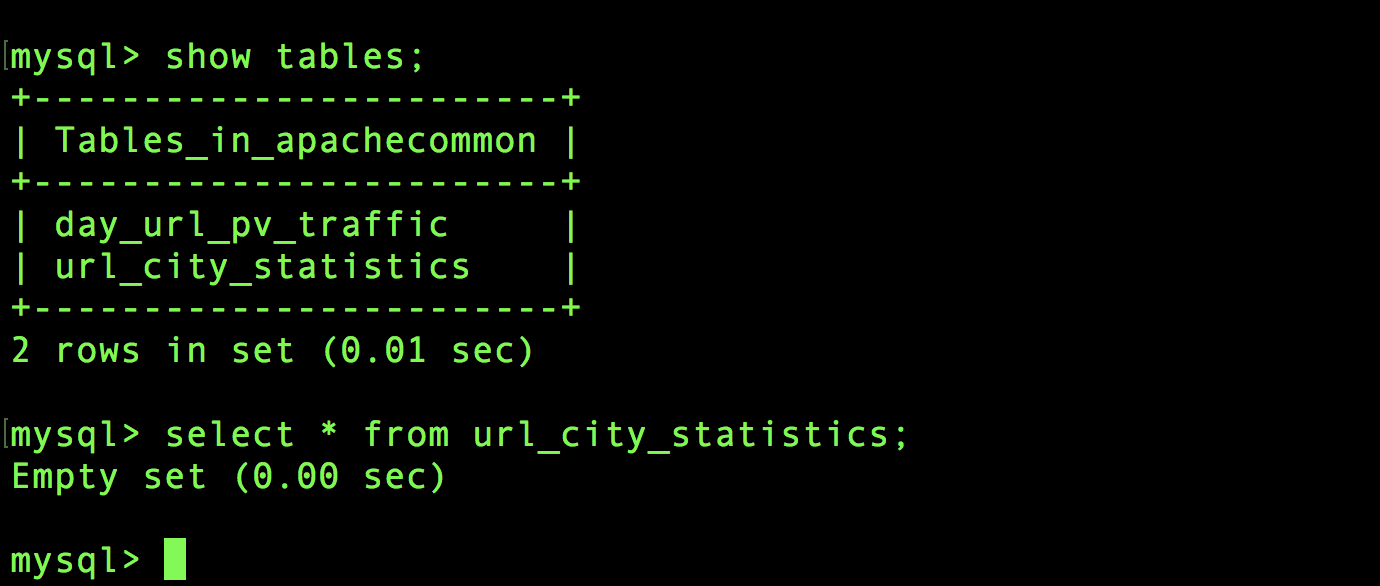
然后进入IDEA创建按照地理区域统计访问量最高的url topN访问次数的实体类。
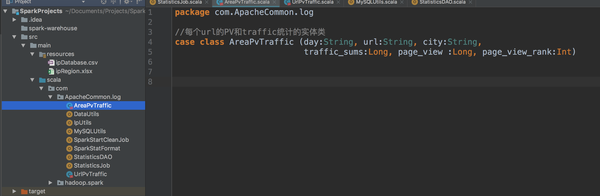
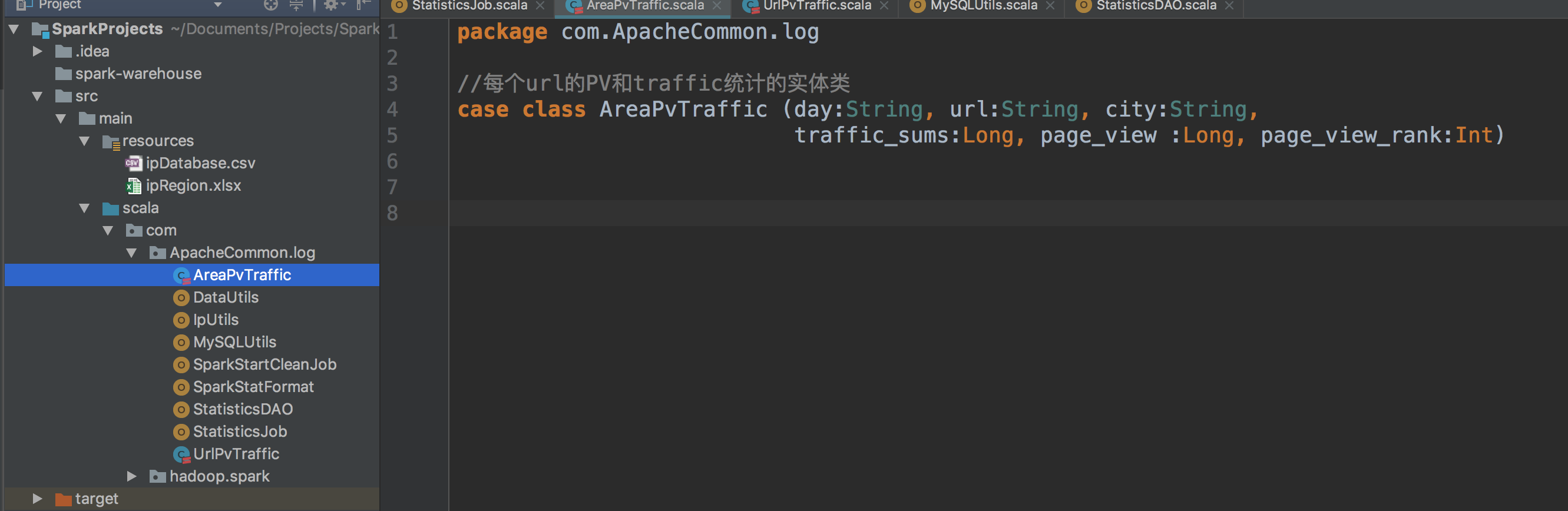
代码一样的,很短,就是图片上的。
然后在DAO中写插入的代码。下面的def是保存AreaPvTraffic到mysql数据库的代码,上面的是上一个插入代码。
package com.ApacheCommon.log
import java.sql.{Connection, PreparedStatement}
import scala.collection.mutable.ListBuffer
*各个需求统计的DAO操作
object StatisticsDAO {
* 批量保存UrlPvTraffic到mysql数据库
* @param list
def insertDayUrlPvTraffic(list: ListBuffer[UrlPvTraffic]): Unit = {
var connection:Connection = null
var pstmt:PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //把自动提交关闭改为手动提交
val sql = "insert into day_url_pv_traffic(day, url, traffic_sums, page_view, avg) " +
"VALUES (?, ?, ?, ?, ?) " +
"ON DUPLICATE KEY UPDATE day=VALUES(day),url=VALUES(url), " +
"traffic_sums=VALUES(traffic_sums), page_view=VALUES(page_view), avg=VALUES(avg)"
pstmt = connection.prepareStatement(sql)
for(element <- list) {
pstmt.setString(1, element.day)
pstmt.setString(2, element.url)
pstmt.setLong(3, element.traffic_sums)
pstmt.setLong(4, element.page_view)
pstmt.setDouble(5, element.avg)
pstmt.addBatch()
pstmt.executeBatch() //执行批量处理(调优点)
connection.commit() //手动提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
* 批量保存AreaPvTraffic到mysql数据库
* @param list
def insertDayCityPvTraffic(list: ListBuffer[AreaPvTraffic]): Unit = {
var connection:Connection = null
var pstmt:PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //把自动提交关闭改为手动提交
val sql = "insert into url_city_statistics(day, url, city, traffic_sums, page_view, page_view_rank) " +
"VALUES (?, ?, ?, ?, ?, ?) " +
"ON DUPLICATE KEY UPDATE day=VALUES(day),url=VALUES(url), " +
"city=VALUES(city), traffic_sums=VALUES(traffic_sums), " +
"page_view=VALUES(page_view), page_view_rank=VALUES(page_view_rank)"
pstmt = connection.prepareStatement(sql)
for(element <- list) {
pstmt.setString(1, element.day)
pstmt.setString(2, element.url)
pstmt.setString(3, element.city)
pstmt.setLong(4, element.traffic_sums)
pstmt.setLong(5, element.page_view)
pstmt.setInt(6, element.page_view_rank)
pstmt.addBatch()
pstmt.executeBatch() //执行批量处理(调优点)
connection.commit() //手动提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
这个下好了,就回到Job函数里面,完成最后写入mysql的代码。注意看注释,因为是整个Job的代码一起拷贝来的。
package com.ApacheCommon.log
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions.{count, row_number, sum}
import scala.collection.mutable.ListBuffer
* 统计Spark作业
object StatisticsJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("StatisticsJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled", "false")
.master("local[2]").getOrCreate()
val accessdataframe = spark.read.format("parquet").load("hdfs://localhost:8020/WEB_log/Apache_common/clean_data_2")
//计算url的PV和流量
//urlPvTrafficStatistics(spark, accessdataframe)
//计算按照地理区域统计
urlAreaStatistics(spark, accessdataframe)
spark.stop()
* 计算url的PV和流量
* @param spark
* @param accessdataframe
def urlPvTrafficStatistics(spark: SparkSession, accessdataframe: DataFrame): Unit = {
import spark.implicits._
// 按照url进行统计每个url的总流量和访问次数
val statistics_url_Pv_traffic = accessdataframe.filter($"day" === "20130530")
.groupBy("day", "url")
.agg(sum("traffic").as("traffic_sums"),count("traffic").as("page_view"),
(sum("traffic")/count("traffic")).as("avg"))
.orderBy($"traffic_sums")
* 将统计结果写到mysql中
try
{
statistics_url_Pv_traffic.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[UrlPvTraffic]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val url = info.getAs[String]("url")
val traffic_sums = info.getAs[Long]("traffic_sums")
val page_view = info.getAs[Long]("page_view")
val avg = info.getAs[Double]("avg")
list.append(UrlPvTraffic(day, url, traffic_sums, page_view, avg))
StatisticsDAO.insertDayUrlPvTraffic(list)
} catch {
case e: Exception => e.printStackTrace()
* 计算按照地理区域统计访问量最高的url topN访问次数
* @param spark
* @param accessdataframe
def urlAreaStatistics(spark: SparkSession, accessdataframe: DataFrame): Unit = {
import spark.implicits._
// 按照地理区域统计访问量最高的url topN访问次数
val url_city_statistics = accessdataframe.filter($"day" === "20130530")
.groupBy("day", "city", "url")
.agg(sum("traffic").as("traffic_sums"),
count("traffic").as("page_view"),
(sum("traffic")/count("traffic")).as("avg"))
.orderBy($"traffic_sums")
//window窗口函数在Spark SQL中的使用
val url_area_statistics = url_city_statistics.select(
url_city_statistics("day"),
url_city_statistics("url"),
url_city_statistics("city"),
url_city_statistics("traffic_sums"),
url_city_statistics("page_view"),
row_number().over(
Window.partitionBy(url_city_statistics("city"))
.orderBy(url_city_statistics("page_view").desc)
).as("page_view_rank")
).filter("page_view_rank <= 3")
* 将统计结果写到mysql中
try {
url_area_statistics.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[AreaPvTraffic]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val url = info.getAs[String]("url")
val city = info.getAs[String]("city")
val traffic_sums = info.getAs[Long]("traffic_sums")
val page_view = info.getAs[Long]("page_view")
val page_view_rank = info.getAs[Int]("page_view_rank")
list.append(AreaPvTraffic(day, url, city, traffic_sums, page_view, page_view_rank))
StatisticsDAO.insertDayCityPvTraffic(list)
} catch {
case e: Exception => e.printStackTrace()
然后运行看看咯。
没有报错。打开navicat看看mysql。
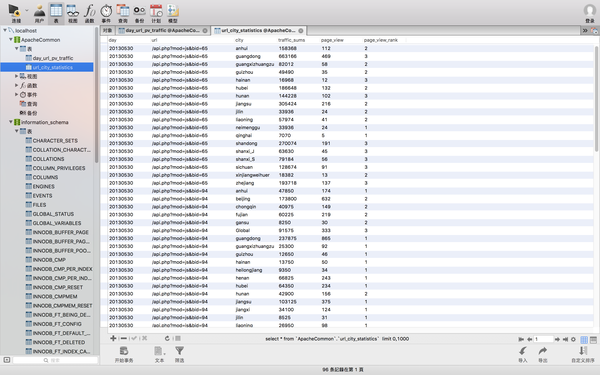
数据全进来了。到这里 按照地理区域统计访问量最高的url topN访问次数 也可以了。
还有一个关于ip的统计,这个也可以在写一个。也不难,基本都差不多。
c、ip地址相关统计
直接看运行结果。
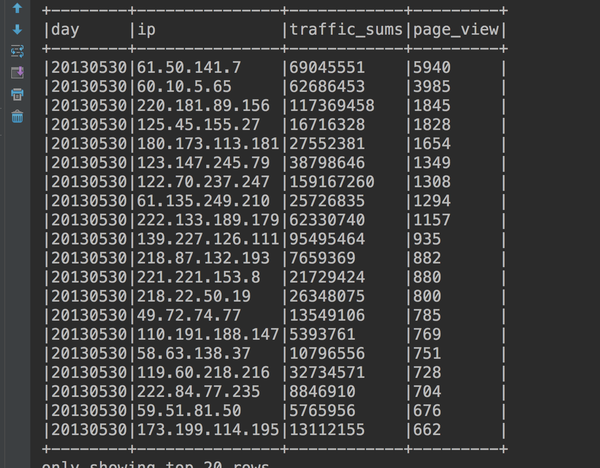
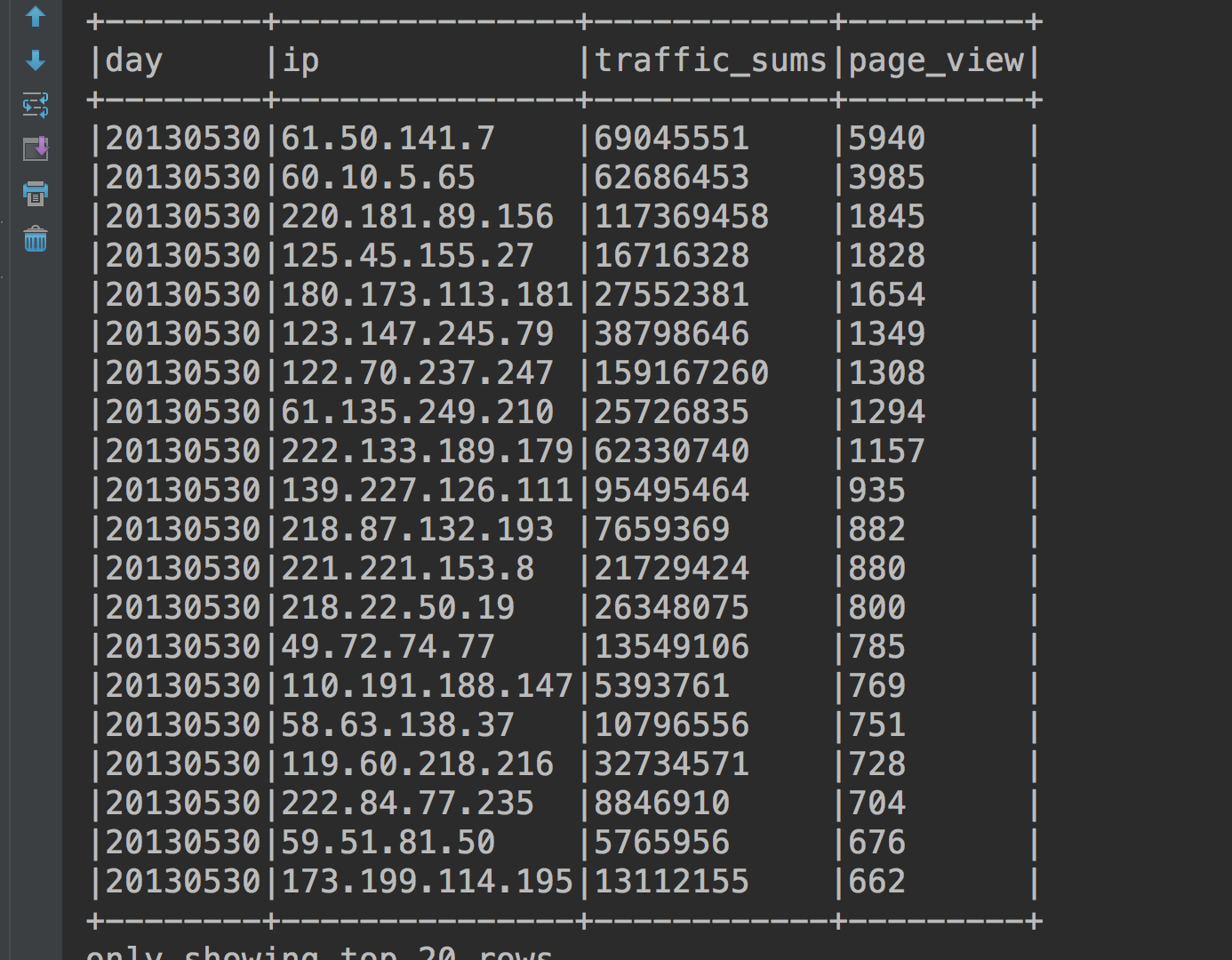
就这个表了,再看看代码。
package com.ApacheCommon.log
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions.{count, row_number, sum}
import scala.collection.mutable.ListBuffer
* 统计Spark作业
object StatisticsJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("StatisticsJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled", "false")
.master("local[2]").getOrCreate()
val accessdataframe = spark.read.format("parquet").load("hdfs://localhost:8020/WEB_log/Apache_common/clean_data_2")
//计算url的PV和流量
//urlPvTrafficStatistics(spark, accessdataframe)
//计算按照地理区域统计
//urlAreaStatistics(spark, accessdataframe)
//ip相关统计
IpAddressStatistics(spark, accessdataframe)
spark.stop()
* 计算url的PV和流量
* @param spark
* @param accessdataframe
def urlPvTrafficStatistics(spark: SparkSession, accessdataframe: DataFrame): Unit = {
import spark.implicits._
// 按照url进行统计每个url的总流量和访问次数
val statistics_url_Pv_traffic = accessdataframe.filter($"day" === "20130530")
.groupBy("day", "url")
.agg(sum("traffic").as("traffic_sums"),count("traffic").as("page_view"),
(sum("traffic")/count("traffic")).as("avg"))
.orderBy($"traffic_sums")
* 将统计结果写到mysql中
try {
statistics_url_Pv_traffic.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[UrlPvTraffic]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val url = info.getAs[String]("url")
val traffic_sums = info.getAs[Long]("traffic_sums")
val page_view = info.getAs[Long]("page_view")
val avg = info.getAs[Double]("avg")
list.append(UrlPvTraffic(day, url, traffic_sums, page_view, avg))
StatisticsDAO.insertDayUrlPvTraffic(list)
} catch {
case e: Exception => e.printStackTrace()
* 计算按照地理区域统计访问量最高的url topN访问次数
* @param spark
* @param accessdataframe
def urlAreaStatistics(spark: SparkSession, accessdataframe: DataFrame): Unit = {
import spark.implicits._
// 按照地理区域统计访问量最高的url topN访问次数
val url_city_statistics = accessdataframe.filter($"day" === "20130530")
.groupBy("day", "city", "url")
.agg(sum("traffic").as("traffic_sums"),
count("traffic").as("page_view"),
(sum("traffic")/count("traffic")).as("avg"))
.orderBy($"traffic_sums")
//window窗口函数在Spark SQL中的使用
val url_area_statistics = url_city_statistics.select(
url_city_statistics("day"),
url_city_statistics("url"),
url_city_statistics("city"),
url_city_statistics("traffic_sums"),
url_city_statistics("page_view"),
row_number().over(
Window.partitionBy(url_city_statistics("city"))
.orderBy(url_city_statistics("page_view").desc)
).as("page_view_rank")
).filter("page_view_rank <= 3")
* 将统计结果写到mysql中
try {
url_area_statistics.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[AreaPvTraffic]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val url = info.getAs[String]("url")
val city = info.getAs[String]("city")
val traffic_sums = info.getAs[Long]("traffic_sums")
val page_view = info.getAs[Long]("page_view")
val page_view_rank = info.getAs[Int]("page_view_rank")
list.append(AreaPvTraffic(day, url, city, traffic_sums, page_view, page_view_rank))
StatisticsDAO.insertDayCityPvTraffic(list)
} catch {
case e: Exception => e.printStackTrace()
* ip地址相关统计
* @param spark
* @param accessdataframe
def IpAddressStatistics(spark: SparkSession, accessdataframe: DataFrame): Unit = {
import spark.implicits._
// 按照地理区域统计访问量最高的url topN访问次数
val ip_statistics = accessdataframe.filter($"day" === "20130530")
.groupBy("day", "ip")
.agg(sum("traffic").as("traffic_sums"),
count("traffic").as("page_view")
).orderBy($"page_view".desc)
* 将统计结果写到mysql中
try {
ip_statistics.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[IpStatistics]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val ip = info.getAs[String]("ip")
val traffic_sums = info.getAs[Long]("traffic_sums")
val page_view = info.getAs[Long]("page_view")
list.append(IpStatistics(day, ip, traffic_sums, page_view))
StatisticsDAO.insertIpStatistics(list)
} catch {
case e: Exception => e.printStackTrace()
当然这之前还是要创建实体类和写insert进mysql的代码,还有先在mysql里面创建一张表。
实体类
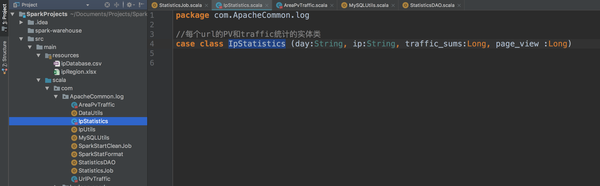
建表语句。
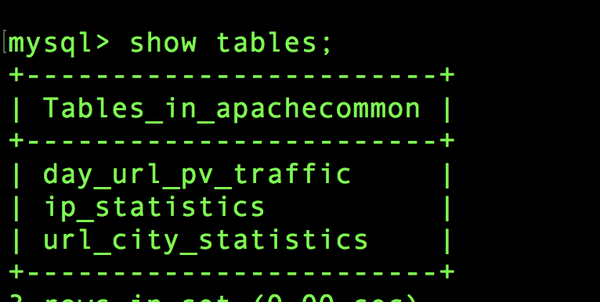
create table ip_statistics (
day varchar(8) not null,
ip varchar(100) not null,
traffic_sums bigint(10) not null,
page_view bigint(10) not null,
primary key (day, ip)
);
insert进入mysql的代码,就是DAO。
package com.ApacheCommon.log
import java.sql.{Connection, PreparedStatement}
import scala.collection.mutable.ListBuffer
*各个需求统计的DAO操作
object StatisticsDAO {
* 批量保存UrlPvTraffic到mysql数据库
* @param list
def insertDayUrlPvTraffic(list: ListBuffer[UrlPvTraffic]): Unit = {
var connection:Connection = null
var pstmt:PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //把自动提交关闭改为手动提交
val sql = "insert into day_url_pv_traffic(day, url, traffic_sums, page_view, avg) " +
"VALUES (?, ?, ?, ?, ?) " +
"ON DUPLICATE KEY UPDATE day=VALUES(day),url=VALUES(url), " +
"traffic_sums=VALUES(traffic_sums), page_view=VALUES(page_view), avg=VALUES(avg)"
pstmt = connection.prepareStatement(sql)
for(element <- list) {
pstmt.setString(1, element.day)
pstmt.setString(2, element.url)
pstmt.setLong(3, element.traffic_sums)
pstmt.setLong(4, element.page_view)
pstmt.setDouble(5, element.avg)
pstmt.addBatch()
pstmt.executeBatch() //执行批量处理(调优点)
connection.commit() //手动提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
* 批量保存AreaPvTraffic到mysql数据库
* @param list
def insertDayCityPvTraffic(list: ListBuffer[AreaPvTraffic]): Unit = {
var connection:Connection = null
var pstmt:PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //把自动提交关闭改为手动提交
val sql = "insert into url_city_statistics(day, url, city, traffic_sums, page_view, page_view_rank) " +
"VALUES (?, ?, ?, ?, ?, ?) " +
"ON DUPLICATE KEY UPDATE day=VALUES(day),url=VALUES(url), " +
"city=VALUES(city), traffic_sums=VALUES(traffic_sums), " +
"page_view=VALUES(page_view), page_view_rank=VALUES(page_view_rank)"
pstmt = connection.prepareStatement(sql)
for(element <- list) {
pstmt.setString(1, element.day)
pstmt.setString(2, element.url)
pstmt.setString(3, element.city)
pstmt.setLong(4, element.traffic_sums)
pstmt.setLong(5, element.page_view)
pstmt.setInt(6, element.page_view_rank)
pstmt.addBatch()
pstmt.executeBatch() //执行批量处理(调优点)
connection.commit() //手动提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
* 批量保存AreaPvTraffic到mysql数据库
* @param list
def insertIpStatistics(list: ListBuffer[IpStatistics]): Unit = {
var connection:Connection = null
var pstmt:PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //把自动提交关闭改为手动提交
val sql = "insert into ip_statistics(day, ip, traffic_sums, page_view) " +
"VALUES (?, ?, ?, ?) " +
"ON DUPLICATE KEY UPDATE day=VALUES(day),ip=VALUES(ip), " +
"traffic_sums=VALUES(traffic_sums), page_view=VALUES(page_view)"
pstmt = connection.prepareStatement(sql)
for(element <- list) {
pstmt.setString(1, element.day)
pstmt.setString(2, element.ip)
pstmt.setLong(3, element.traffic_sums)
pstmt.setLong(4, element.page_view)
pstmt.addBatch()
pstmt.executeBatch() //执行批量处理(调优点)
connection.commit() //手动提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
}好了,集齐龙珠,召唤神龙。看看运行怎样。
没有错误,去mysql里面看看数据进去没有。
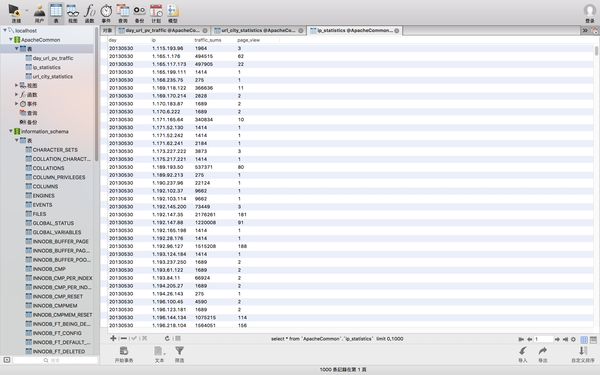
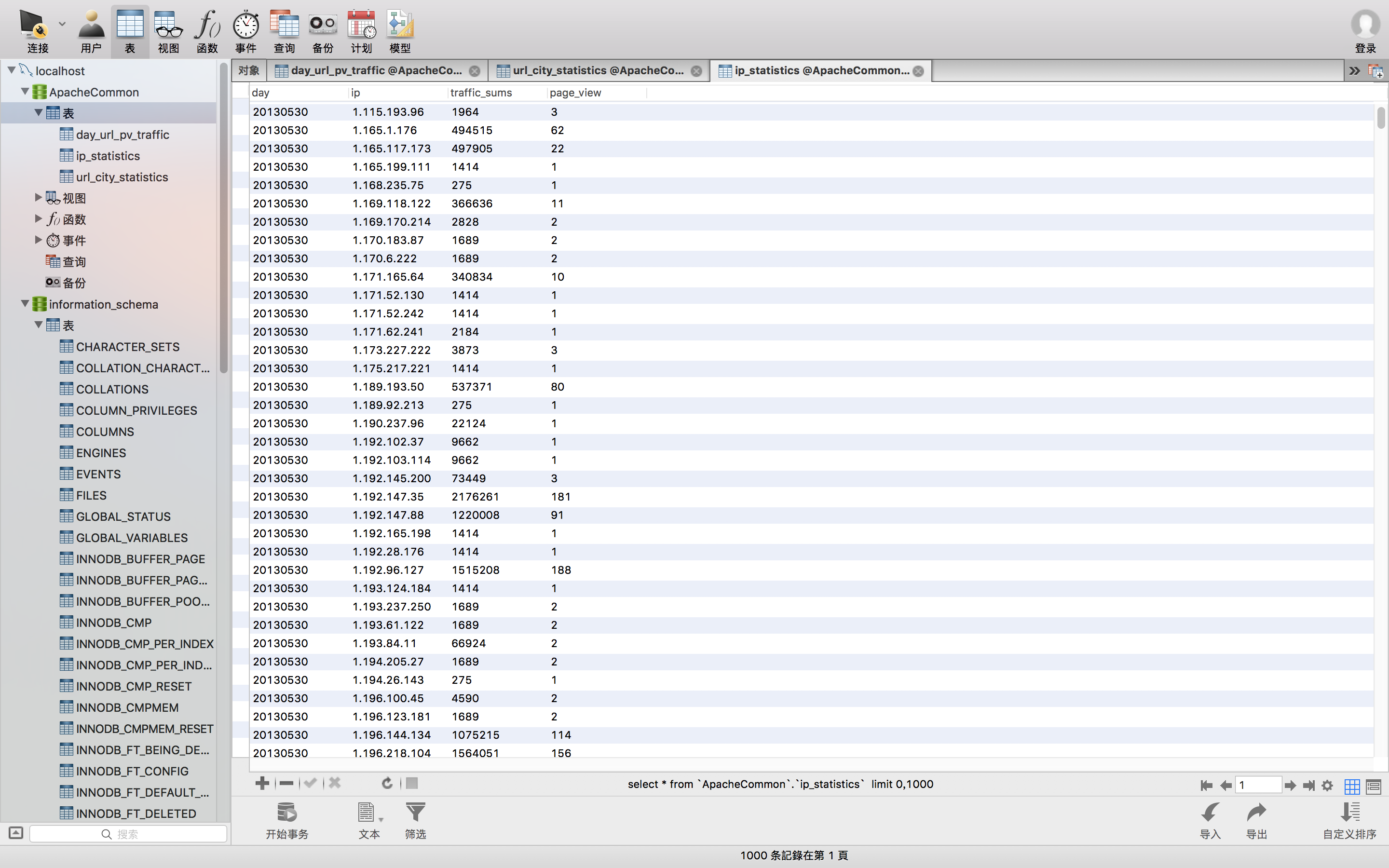
棒棒的有没有!
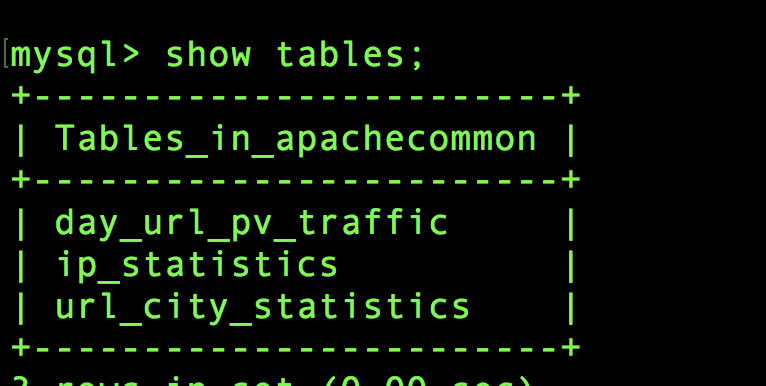
到此 ip地址相关统计也完成了 ,也意味着 数据统计 的工作做完了!
最后还要要测试一下,一次性跑这三个统计任务看看,但是跑之前,数据库里面已经有数据了,要把数据删除,那么怎么删除呢?我们要做的就是每执行一次之前要把当天的数据给他删除,再来跑才能保证数据是唯一的。不会有重复,所以在DAO层还需要添加一个delete方法。直接上代码。以下是完整的,重构之后的完善的DAO和Job代码
这是DAO层的代码。
package com.ApacheCommon.log
import java.sql.{Connection, PreparedStatement}
import scala.collection.mutable.ListBuffer
*各个需求统计的DAO操作
object StatisticsDAO {
* 批量保存UrlPvTraffic到mysql数据库
* @param list
def insertDayUrlPvTraffic(list: ListBuffer[UrlPvTraffic]): Unit = {
var connection:Connection = null
var pstmt:PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //把自动提交关闭改为手动提交
val sql = "insert into day_url_pv_traffic(day, url, traffic_sums, page_view, avg) " +
"VALUES (?, ?, ?, ?, ?) " +
"ON DUPLICATE KEY UPDATE day=VALUES(day),url=VALUES(url), " +
"traffic_sums=VALUES(traffic_sums), page_view=VALUES(page_view), avg=VALUES(avg)"
pstmt = connection.prepareStatement(sql)
for(element <- list) {
pstmt.setString(1, element.day)
pstmt.setString(2, element.url)
pstmt.setLong(3, element.traffic_sums)
pstmt.setLong(4, element.page_view)
pstmt.setDouble(5, element.avg)
pstmt.addBatch()
pstmt.executeBatch() //执行批量处理(调优点)
connection.commit() //手动提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
* 批量保存AreaPvTraffic到mysql数据库
* @param list
def insertDayCityPvTraffic(list: ListBuffer[AreaPvTraffic]): Unit = {
var connection:Connection = null
var pstmt:PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //把自动提交关闭改为手动提交
val sql = "insert into url_city_statistics(day, url, city, traffic_sums, page_view, page_view_rank) " +
"VALUES (?, ?, ?, ?, ?, ?) " +
"ON DUPLICATE KEY UPDATE day=VALUES(day),url=VALUES(url), " +
"city=VALUES(city), traffic_sums=VALUES(traffic_sums), " +
"page_view=VALUES(page_view), page_view_rank=VALUES(page_view_rank)"
pstmt = connection.prepareStatement(sql)
for(element <- list) {
pstmt.setString(1, element.day)
pstmt.setString(2, element.url)
pstmt.setString(3, element.city)
pstmt.setLong(4, element.traffic_sums)
pstmt.setLong(5, element.page_view)
pstmt.setInt(6, element.page_view_rank)
pstmt.addBatch()
pstmt.executeBatch() //执行批量处理(调优点)
connection.commit() //手动提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
* 批量保存AreaPvTraffic到mysql数据库
* @param list
def insertIpStatistics(list: ListBuffer[IpStatistics]): Unit = {
var connection:Connection = null
var pstmt:PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //把自动提交关闭改为手动提交
val sql = "insert into ip_statistics(day, ip, traffic_sums, page_view) " +
"VALUES (?, ?, ?, ?) " +
"ON DUPLICATE KEY UPDATE day=VALUES(day),ip=VALUES(ip), " +
"traffic_sums=VALUES(traffic_sums), page_view=VALUES(page_view)"
pstmt = connection.prepareStatement(sql)
for(element <- list) {
pstmt.setString(1, element.day)
pstmt.setString(2, element.ip)
pstmt.setLong(3, element.traffic_sums)
pstmt.setLong(4, element.page_view)
pstmt.addBatch()
pstmt.executeBatch() //执行批量处理(调优点)
connection.commit() //手动提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
* 删除指定日期的数据
def deleteData(day: String): Unit = {
val tables = Array("ip_statistics",
"day_url_pv_traffic",
"url_city_statistics")
var connection: Connection = null
var pstmt: PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
for(table <- tables) {
val deleteSQL = s"delete from $table where day = ?"
pstmt = connection.prepareStatement(deleteSQL)
pstmt.setString(1, day)
pstmt.executeUpdate()
} catch {
case e: Exception
=> e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
这是Job代码
package com.ApacheCommon.log
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions.{count, row_number, sum}
import scala.collection.mutable.ListBuffer
* 统计Spark作业
object StatisticsJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("StatisticsJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled", "false")
.master("local[2]").getOrCreate()
val accessdataframe = spark.read.format("parquet").load("hdfs://localhost:8020/WEB_log/Apache_common/clean_data_2")
//先删除指定日期的数据再执行插入数据,保证数据不重复
val day = "20130530"
StatisticsDAO.deleteData(day)
//计算url的PV和流量
urlPvTrafficStatistics(spark, accessdataframe, day)
//计算按照地理区域统计
urlAreaStatistics(spark, accessdataframe, day)
//ip相关统计
IpAddressStatistics(spark, accessdataframe, day)
spark.stop()
* 计算url的PV和流量
* @param spark
* @param accessdataframe
def urlPvTrafficStatistics(spark: SparkSession, accessdataframe: DataFrame, day: String): Unit = {
import spark.implicits._
// 按照url进行统计每个url的总流量和访问次数
val statistics_url_Pv_traffic = accessdataframe.filter($"day" === day)
.groupBy("day", "url")
.agg(sum("traffic").as("traffic_sums"),count("traffic").as("page_view"),
(sum("traffic")/count("traffic")).as("avg"))
.orderBy($"traffic_sums")
* 将统计结果写到mysql中
try {
statistics_url_Pv_traffic.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[UrlPvTraffic]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val url = info.getAs[String]("url")
val traffic_sums = info.getAs[Long]("traffic_sums")
val page_view = info.getAs[Long]("page_view")
val avg = info.getAs[Double]("avg")
list.append(UrlPvTraffic(day, url, traffic_sums, page_view, avg))
StatisticsDAO.insertDayUrlPvTraffic(list)
} catch {
case e: Exception => e.printStackTrace()
* 计算按照地理区域统计访问量最高的url topN访问次数
* @param spark
* @param accessdataframe
def urlAreaStatistics(spark: SparkSession, accessdataframe: DataFrame, day: String): Unit = {
import spark.implicits._
// 按照地理区域统计访问量最高的url topN访问次数
val url_city_statistics = accessdataframe.filter($"day" === day)
.groupBy("day", "city", "url")
.agg(sum("traffic").as("traffic_sums"),
count("traffic").as("page_view"),
(sum("traffic")/count("traffic")).as("avg"))
.orderBy($"traffic_sums")
//window窗口函数在Spark SQL中的使用
val url_area_statistics = url_city_statistics.select(
url_city_statistics("day"),
url_city_statistics("url"),
url_city_statistics("city"),
url_city_statistics("traffic_sums"),
url_city_statistics("page_view"),
row_number().over(
Window.partitionBy(url_city_statistics("city"))
.orderBy(url_city_statistics("page_view").desc)
).as("page_view_rank")
).filter("page_view_rank <= 3")
* 将统计结果写到mysql中
try {
url_area_statistics.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[AreaPvTraffic]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val url = info.getAs[String]("url")
val city = info.getAs[String]("city")
val traffic_sums = info.getAs[Long]("traffic_sums")
val page_view = info.getAs[Long]("page_view")
val page_view_rank = info.getAs[Int]("page_view_rank")
list.append(AreaPvTraffic(day, url, city, traffic_sums, page_view, page_view_rank))
StatisticsDAO.insertDayCityPvTraffic(list)
} catch {
case e: Exception => e.printStackTrace()
* ip地址相关统计
* @param spark
* @param accessdataframe
def IpAddressStatistics(spark: SparkSession, accessdataframe: DataFrame, day: String): Unit = {
import spark.implicits._
// 按照地理区域统计访问量最高的url topN访问次数
val ip_statistics = accessdataframe.filter($"day" === day)
.groupBy("day", "ip")
.agg(sum("traffic").as("traffic_sums"),
count("traffic").as("page_view")
).orderBy($"page_view".desc)
* 将统计结果写到mysql中
try {
ip_statistics.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[IpStatistics]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val ip = info.getAs[String]("ip")
val traffic_sums = info.getAs[Long]("traffic_sums")
val page_view = info.getAs[Long]("page_view")
list.append(IpStatistics(day, ip, traffic_sums, page_view))
StatisticsDAO.insertIpStatistics(list)