


02 语音情感识别数据集及特征提取

1 情感语音库
Belfast 英语情感数据库,是由Queen 大学对40 位录音人(18~69 岁,20 男20 女)的5 种情感(生气、悲伤、高兴、恐惧、中性)进行演绎得到的,每个段落包括7~8 个句子。
每条语音的命名的各位置对应的含义:
- Positions 1-2: 人的性别及年龄

- Positions 3-5: 对应的文本代码
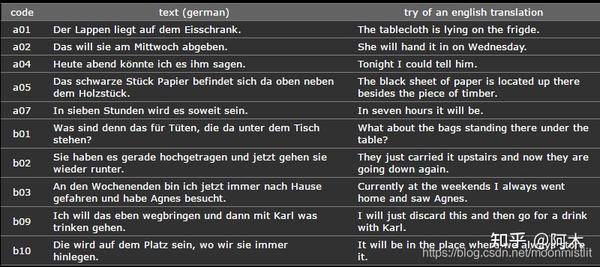
- Position 6: 文本情感:A:害怕,F:高兴,N:中性,T:悲伤,W:生气
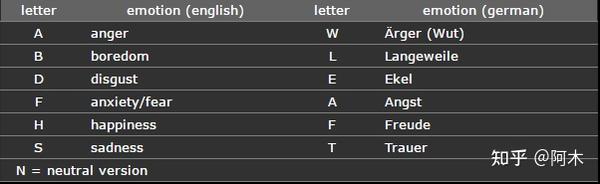

- Position 7: 不同朗读版本:a,b,c,d
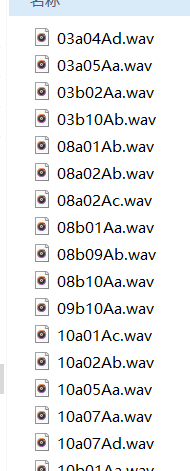
例如: 03a01Fa.wav :由03号朗读者朗读a01对应的文本,情绪为高兴“Freude” (Happiness).
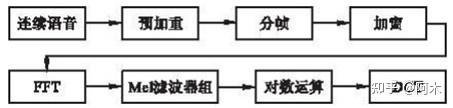
2 特征提取
2.1 短时能量及其衍生参数
主要用途:区分清音段和浊音段(浊音的E(i)值比清音的E(i)值大);区分声母和韵母的分界和无话段与有话段的分界
具体内容可参考: 阿木:语音识别 02 语音信号的时域、频域特性和短时分析技术
短时能量: E_n=\sum_{m=0}^{N-1}x_n^2(m)
y1=ys(1:L);
s1=enframe(y1,hamming(256),128);
[nframe1,~]=size(s1);
E=zeros(1,nframe1);
for i=1:nframe
Z(i)=sum(abs(sign(s(i,framesize:2)-s(i,framesize-1:1))))/2; % 过零率 %
for i=1:nframe1
E(i)=sum(s1(i,:).*s1(i,:)); % 短时能量 %
end短时抖动能量: E_s=\frac{\frac{1}{M-1}\sum_{n=1}^{M-1}|E_n-E_{n+1}|}{\frac{1}{M}\sum_{n=1}^ME_n}\times 100
x=0;
t=0;
for i
=1:(nframe1-1)
t=abs(E(i)-E(i+1))/(nframe1-1);
x=x+t;
E_shimmer=x/mean(E); % 这里感觉要乘100,不过都不乘100的话就不影响该特征的对比短时能量的线性回归系数: E_r=\frac{\sum_{n=1}^Mn·E_n-\frac{1}{M}\sum_{n=1}^Mn·\sum_{n=1}^ME_n}{\sum_{n=1}^Mn^2-\frac{1}{M}(\sum_{n=1}^M n)^2}
x1=0;x2=0;x3=0;x4=0;
for i=1:nframe1
t1=i*mean(E);
t2=i*E(i);
t3=i*i;
t4=i;
x1=x1+t1;
x2=x2+t2;
x3=x3+t3;
x4=x4+t4;
x4=x4*x4/nframe1;
s1=x2-x1;
s2=x3-x4;
E_Reg_coff=s1/s2;短时能量的线性回归系数均方误差: E_p=\frac{1}{M}\sum_{n=1}^M(E_n-(\mu_1-E_r-\mu_n)-E_r·n)^2
其中, \mu_n=\frac{1}{M}\sum_{n=1}^Mn
x=0;
for i=1:nframe1
t=E(i)-(mean(E)-s1/s2*x4/nframe1)-s1/s2*i;
x=x+t^2/nframe1;
E_Sqr_Err=x;250Hz以下短时能量与全部短时能量的比:
E_{250}/E=\frac{\sum_{n=1}^ME_{250,n}}{\sum_{n=1}^ME_{n}}\times 100
% 0-250hz所占比例 %
[s2,f1,~]=specgram(y1,256,fs);
sn=20*log10(abs(s2)+eps);
sn1=sn+min(sn(:));
n=round(length(f1)*250/max(f1(:)));
Eratio=sum(sum(sn1(1:n,:)))/sum(sn1(:));2.2 基音频率及其衍生参数
基频都是随时间变化的,基频的变化形成了语调,语调使得语音听起来抑扬顿挫、生动形象。
具体内容可参考: 阿木:语音识别 08 基音周期的估算方法
R_n(k)=\sum x_n(m)x_n(m+k)
基音周期可以检测 R_n(k) 位置得出,其倒数即为基音频率F,将第i个浊音帧的基音频率表示为 F0_i ,语音中包含浊音总帧数为 M^* ,语音中总帧数为M。
% 基音频率 %
N=2048;R=4;
for i=1:nframe
k = 1:R:N/2; % N是FFT变换点数,R是乘的次数,f是采样频率 %
K = length(k);
X = fft (s(i,:), N);
X=abs(X); % 对X做绝对值,取到幅度 %
HPSx = X(k);
for r= R-1:-1:1
HPSx = HPSx.*X (1:r:r*K);
[~,I]=max(HPSx); % 取最大值点,I是对应下标 %
F(i)=I/N*fs; % 基音频率 %
%% 使F得最小值是有效(去除等值)
k=1;
for i=2:numel(F)
if(F(i)==F(1))
continue;
FF(k)= F(i);
k=k+1;
end一阶基音频率抖动: F0_{s1}=\frac{\frac{1}{M^*-1}\sum\limits_{i=1}^{M^*-1}|F0_i-F0_{i+1}|}{\frac{1}{M^*}\sum\limits_{i=1}^{M^*}F0_i}\times 100
x=0;
for i=1:(nframe-1)
t=abs(F(i)-F(i+1));
x=x+t;
F_Jitter1=100*x/(mean(F)*(nframe-1));二阶基音频率抖动: F0_{s2}=\frac{\frac{1}{M^*-2}\sum\limits_{i=2}^{M^*-1}|2F0_i-F0_{i-1}-F0_{i+1}|}{\frac{1}{M^*}\sum\limits_{i=1}^{M^*}F0_i}\times 100
x=0;
for i=2:(nframe-1)
t=abs(2*F(i)-F(i+1)-F(i-1));
x=x+t;
F_Jitter2=100*x/(mean(F)*(nframe-2));所有相邻帧中,满足 F(i)*F(i+1)!=0 的两帧可定义浊音间差分基音 dF=F(i)-F(i+1)
% 浊音帧差分基音 %
nf=1;
for i=1:(nframe-1)
if(F(i)*F(i+1)~=0)
dF(nf)=F(i)-F(i+1);
nf=nf+1;
end2.3 共振峰及其衍生参数
具体内容可参考: 阿木:语音识别 09 共振峰的估算方法
声道可以被看成一根具有非均匀截面的声管,在发音时将起共鸣器的作用。当声门处准周期脉冲激励进入声道时会引起共振特性,产生一组共振频率,这一组共振频率称为共振峰频率或简称为共振峰。 共振峰参数包括共振峰频率和频带的宽度(带宽),它是区别不同韵母的重要参数。 共振峰信息包含在语音频谱的包络中,因此 共振峰参数提取的关键是估计自然语音频谱包络,并认为谱包络中的极大值就是共振峰。
首先,用LPC法对语音信号进行解卷,得到声道响应的全极点模型参数为:
H(z) = \frac{1}{A(z)}
A\left( z \right) = 1 - \sum_{i=1}^{p}{a_{i}z^{-i}},i=1,2,...,p
然后,求出A(z)的复数根,即可得到共振峰参数。设 z_{i} = r_{i}e^{j\theta_{i}} 为其中一个根,则其共轭复值 z_{i} ^{*}= r_{i}e^{-j\theta_{i}} 也是A(z)的一个根,i对应的共振峰频率表示为 F_{i} ,则有
F_{i} = \frac{\theta_{i}}{2\pi T}
其中,T为采样周期。
第i个浊音帧的第1、3、5共振峰频率分别表示为 F1_{i},F2_{i},F3_{i}
第二共振峰比率为: F2_{i}/(F2_{i}-F1_{i})
共振峰频率抖动的计算方法与基音频率抖动计算方法一致。
% 估计共振峰 %
[fm,~] = formant_get(y,fs);
Fm1=fm(:,1);
Fm2=fm(:,2);
Fm3=fm(:,3);
%-----------------------------------------------------------------------
%逐帧提取共振峰
%-----------------------------------------------------------------------
function [formant_frame,bw_frame]=formant_get(speech,samplerate)
M=160;%帧移
%[speech,samplerate]=audioread('e.wav');
[begin,last]=voicemark(speech);
%提取共振峰频率和带宽
[s,s_bw,~]=pick_peak(speech,samplerate);
%对频率和带宽进行平滑
[formant_frame,bw_frame]=smoothing(s,s_bw);
%%开始对共振峰进行处理,静音段置0
%------------首先判断分帧后哪些帧是非静音段
frame_num=size(formant_frame,1);
frame_begin=0;%起始帧
frame_last=0;%结束帧
%%%%%确定起始帧
for i=1:frame_num
if begin<=(i-1)*M+1
break;
frame_begin=frame_begin+1;
%%%%%确定结束帧
for i=1:frame_num
if last<=(i-1)*M+1
break;
frame_last=frame_last+1;
%根据起始帧和结束帧对共振峰数据进行处理
for i=1:frame_begin-1
formant_frame(i,:)=zeros(1,4);
for i=frame_last:frame_num
formant_frame(i,:)=zeros(1,4);
frame_last=frame_last-1;
formant_frame = formant_frame(frame_begin:frame_last,:);
%------------------------------------------------------------
% 共振峰 %
x1=0;
x2=0;
x3=0;
for i=1:(numel(Fm1)-1)
t1=abs(Fm1(i)-Fm1(i+1));
t2=abs(Fm2(i)-Fm2(i+1));
t3=abs(Fm3(i)-Fm3(i+1));
x1=x1+t1;x2=x2+t2;x3=x3+t3;
Fm1_Jitter1=100*x1/(mean(Fm1)*(numel(Fm1)-1));% 前三个共振峰的一阶抖动 %
Fm2_Jitter1=100*x2/(mean(Fm2)*(numel(Fm1)-1));
Fm3_Jitter1=100*x3/(mean(Fm2)*(numel(Fm1)-1));
Fm2R=Fm2./(Fm2-Fm1);
nFm=[max(Fm1);min(Fm1);mean(Fm1);var(Fm1);Fm1_Jitter1;max(Fm2);min(Fm2);mean(Fm2);var(Fm2);Fm2_Jitter1;max(Fm3);min(Fm3);mean(Fm3);var(Fm3);Fm3_Jitter1;max(Fm2R);min(Fm2R);mean(Fm2R)];% 共振峰相关特征 %
2.4 mfcc
具体内容可参考: 阿木:语音识别 03 语音信号在其他变化域的分析技术和特性
% MFCC %
MFCCs=melcepst(y,fs,'0d'); % MFCC及其一阶差分系数 %
function c=melcepst(s,fs,w,nc,p,n,inc,fl,fh)
if nargin<2 fs=11025; end
if nargin<3 w='M'; end
if nargin<4 nc=12; end
if nargin<5 p=floor(3*log(fs)); end
if nargin<6 n=pow2(floor(log2(0.03*fs))); end
if nargin<9
fh=0.5;
if nargin<8
fl=0;
if nargin<7
inc=floor(n/2);
if any(w=='R')
z=enframe(s,n,inc);
elseif any (w=='N')
z=enframe(s,hanning(n),inc);
z=enframe(s,hamming(n),inc);
f=rfft(z.');
[m,a,b]=melbankm(p,n,fs,fl,fh,w);
pw=f(a:b,:).*conj(f(a:b,:));
pth=max(pw(:))*1E-6;
if any(w=='p')
y=log(max(m*pw,pth));
ath=sqrt(pth);
y=log(max(m*abs(f(a:b,:)),ath));
c=rdct(y).';
nf=size(c,1);
nc=nc+1;
if p>nc
c(:,nc+1:end)=[];
elseif p<nc
c=[c zeros(nf,nc-p)];
if ~any(w=='0')
c(:,1)=[];
if any(w=='e')
c=[log(sum(pw)).' c];
% calculate derivative
if any(w=='D')
vf=(4:-1:-4)/60;
af=(1:-1:-1)/2;
ww=ones(5,1);
cx=[c(ww,:); c; c(nf*ww,:)];
vx=reshape(filter(vf,1,cx(:)),nf+10,nc);
vx(1:8,:)=[];
ax=reshape(filter(af,1,vx(:)),nf+2,nc);
ax(1:2,:)=[];
vx([1 nf+2],:)=[];
if any(w=='d')
c=[c vx ax];
c=[c ax];
elseif any(w=='d')
vf=(4:-1:-4)/60;
ww=ones(4,1);
cx=[c(ww,:); c; c(nf*ww,:)];
vx=reshape(filter(vf,1,cx(:)),nf+8,nc);
vx(1:8,:)=[];
c=[c vx];
if nargout<1
[nf,nc]=size(c);
t=((0:nf-1)*inc+(n-1)/2)/fs;
ci=(1:nc)-any(w=='0')-any(w=='e');
imh = imagesc(t,ci,c.');
axis('xy');
xlabel('Time (s)');
ylabel('Mel-cepstrum coefficient');
map = (0:63)'/63;
colormap([map map map]);
colorbar;
end
2.5 特征构建
选取上述四类特征及其衍生参数,构成140维语音情感特征参数用于识别,具体参数含义如下表所示:
| 特征编号 | 特征名称 |
|---|---|
| 1~4 | 短时能量的最大值、最小值、均值、方差 |
| 5~7 | 短时能量抖动、线性回归系数、线性回归系数的均方误差 |
| 8 | 0~250Hz频段能量占总能量的百分比 |
| 9~12 | 基音频率最大值、最小值、均值、方差 |
| 13~14 | 基音频率的一阶抖动、二阶抖动 |
| 15~18 | 浊音帧差分基音的最大值、最小值、均值、方差 |
| 19~23 | 第一共振峰频率的最大值、最小值、均值、方差、一阶抖动 |
| 24~28 | 第二共振峰频率的最大值、最小值、均值、方差、一阶抖动 |
| 29~33 | 第三共振峰频率的最大值、最小值、均值、方差、一阶抖动 |
| 34~36 | 第二共振峰频率比率的最大值、最小值、均值 |
| 37~88 | 0~12阶mfcc的最大值、最小值、均值、方差 |
| 89~140 | 0~12阶mfcc一阶差分的最大值、最小值、均值、方差 |
feature(1:7,1)=[max(E);min(E);mean(E);var(E);E_shimmer;E_Reg_coff;E_Sqr_Err];% 短时能量相关特征 %
feature(8,1)=Eratio;
feature(9:14,1)=[max(F);min(FF);mean(F);var(F);F_Jitter1;F_Jitter2];% 基音频率相关特征 %
feature(15:18,1)=[max(dF);min(dF);mean(dF);var(dF)];% 浊音帧差分基音 %
feature(19:(size(nFm)+18),1)=nFm;% 20-37 %
for i=1:size(MFCCs,2)
feature(37+4*(i-1):37+4*i-1,1)=[max(MFCCs(:,i));min(MFCCs(:,i));mean(MFCCs(:,i));var(MFCCs(:,i))];% mel倒谱系数及其一阶差分相关特征 %
end归一化函数:
function m=mapzo(x)
xmin=min(x);xmax=max(x);
for i=1:length(x)
m(i)=(x(i)-xmin)/(xmax-xmin);
end提取特征main函数:
%% 提取该文件夹下的语音文件的特征
clear all
close all
wavefilename = '*.wav';
dr = dir(wavefilename);
hapVec=zeros(140,length(dr));
for i = 1:length( dr )
disp(i)
disp(dr(i).name);
hapVec(:,i)=featvector(dr(i).name);%利用函数featvector提取特征