


教你用Python爬虫爬哔哩哔哩网站弹幕

看过B站的小伙伴都知道,B站的灵魂那就是“弹幕”,视频越厉害弹幕就越多,还有一些高级弹幕效果更加酷炫,今天呢,小千就来教大家如何去利用Python开发一个爬虫来抓取我们想要的视频弹幕。
1.弹幕哪里找?
平常我们在看视频时,弹幕是出现在视频上的。实际上在网页中,弹幕是被隐藏在源代码中,以XML的数据格式进行加载的:
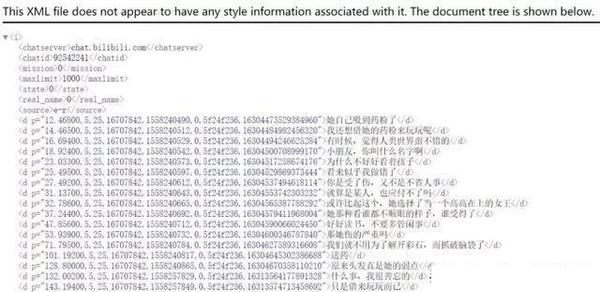

XML和JSON、YAML一样是一种通用的标记信息表达方式,可以简单的理解为一种记录数据的格式。XML和描述网页的语言HTML非常像,所以你会在截图中看到<d></d>这样的标签。
那么上图这个弹幕文件的url是什么呢?
它以一个固定的url地址+视频的cid+.xml组成。只要找到你想要的视频cid,替换这个url就可以爬取所有弹幕了(b站大部分网页给出的字幕限制是1000条)
一个视频的cid在哪里呢?右键网页,打开网页源代码,搜索cid”就能找到:
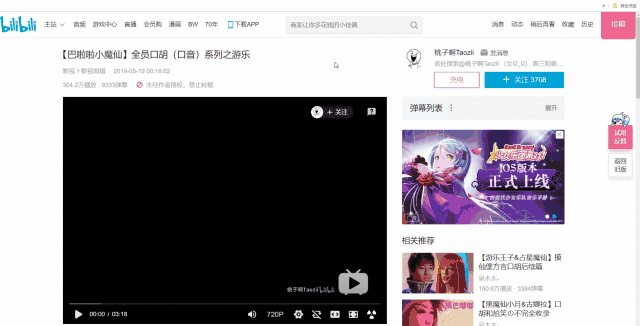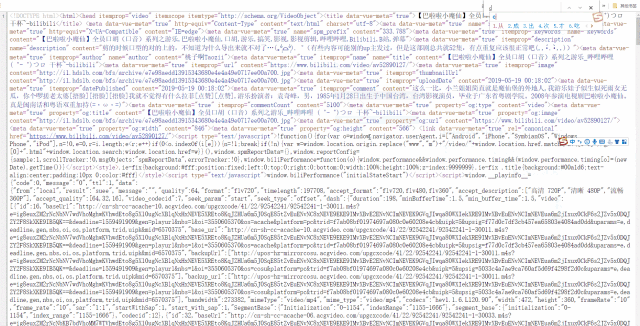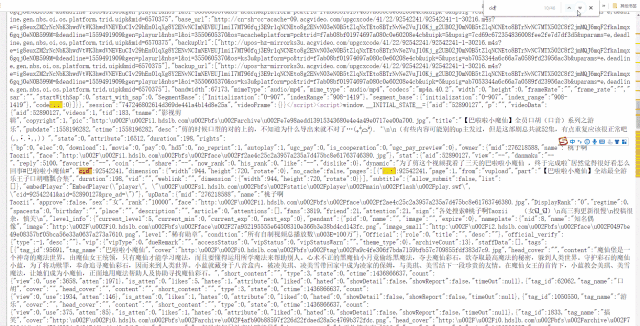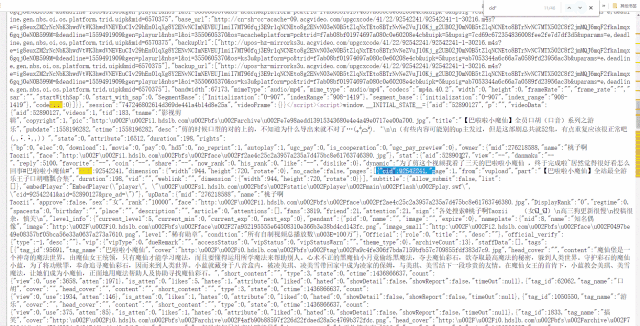

cid在网页源码中是一个很常见的词组,而我们要寻找的正确的cid都会写成"cid":xxxxxxxx的形式。为了缩小搜索范围,在后方加上一个引号会更快搜索到。
开始爬取
观察网页,可以发现,所有的弹幕都放在了<d>标签下,那么我们需要构建一个程序获取所有的<d>标签


第一步,导入requests库,使用request.get方法访问弹幕url:
import requests
#获取页面数据html
url=r'https://comment.bilibili.com/78830153.xml'
r=requests.get(url)#访问url
r.encoding='utf8'第二步,导入BeautifulSoup库,使用lxml解析器解析页面:
from bs4 import BeautifulSoup
#解析页面
soup=BeautifulSoup(r.text,'lxml')#lxml是常用的解析器,需要提前使用pip工具安装lxml库
d=soup.find_all('d')#找到所有页面的d标签
#print(d)这样操作后,所有藏在d标签里的弹幕内容就被python抓取到了 :
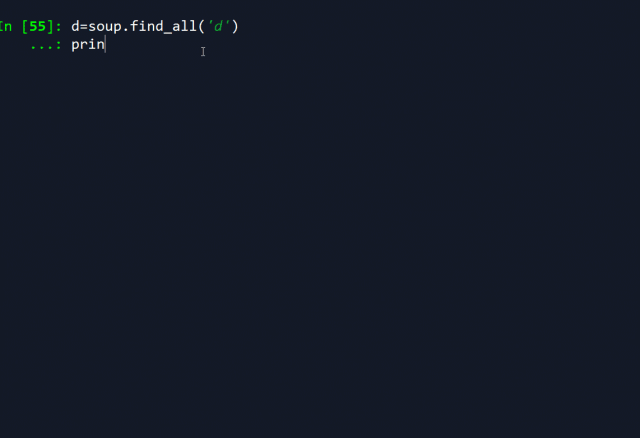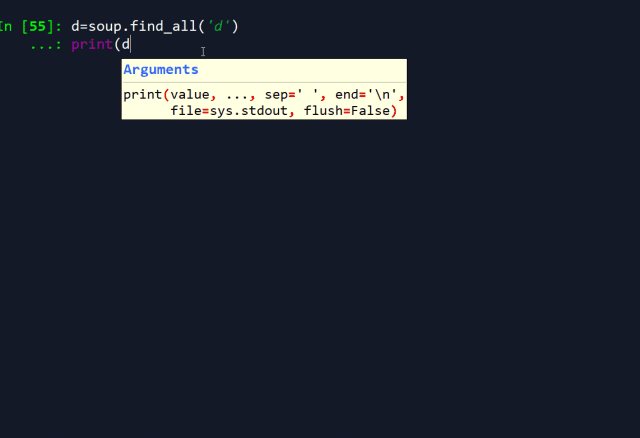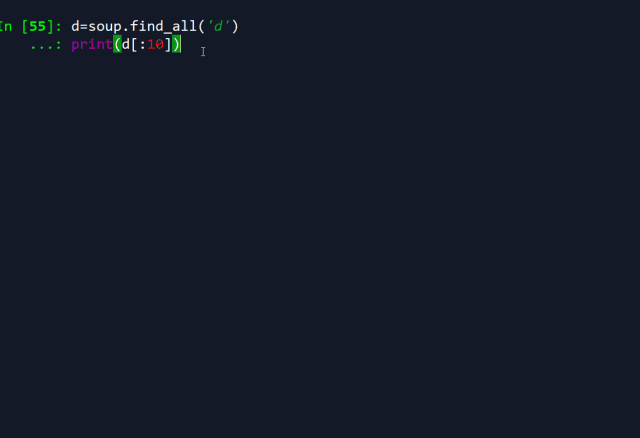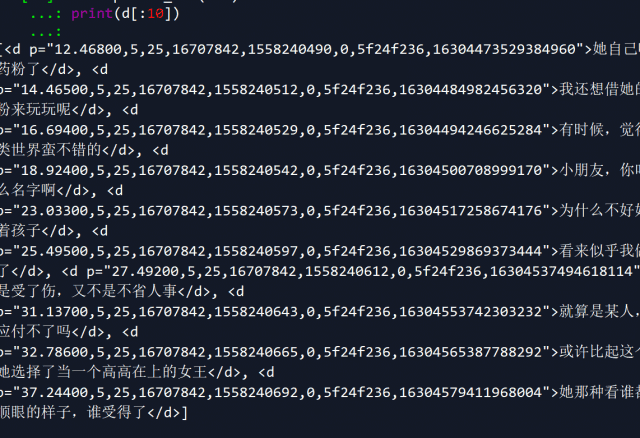

解析完成后,接下来第三步就是运用Python基础函数中的for函数,将单条数据装进字典,再将所有字典装进一个列表:
#解析弹幕,将弹幕、网址、时间整理为字典,最后加和成列表,共1000条数据
dlst=[]
for i in d:
danmuku={}#将单条数据装进字典
danmuku['弹幕']=i.text
danmuku['网址']=url
danmuku['时间']=datetime.date.today()#需要先导入datetime库