|
|
|


AliNLP分词插件(analysis-aliws)是阿里云Elasticsearch(ES)自带的一个系统默认插件。安装该插件后会在阿里云ES中集成对应的分析器和分词器,可用于文档的分析和检索。您还可以通过该插件的词库配置功能实现词典的热更新。
插件介绍
安装analysis-aliws插件后,阿里云ES默认会集成以下分析器和分词器。您可以使用这些分析器和分词器查询文档,也可以通过词库配置功能自定义更新分词词库。
-
分析器:aliws(不会截取虚词、虚词短语、符号)
-
分词器:aliws_tokenizer
说明
-
详细信息,请参见 使用aliws分析器查询文档 和 配置词库 。
-
如果您需要构造自定义分词器,请参见 自定义分词器构造说明 。
前提条件
已安装analysis-aliws插件(默认未安装)。安装方法,请参见 安装或卸载系统默认插件 。
使用限制
-
ES实例的内存要求4 GB及以上(生产环境中要求内存最低为8 GB)。如果内存不满足要求,请先升级集群,请参见 升配集群 。
-
5.x版本和8.x版本实例暂不支持安装analysis-aliws插件,请以控制台为准。
使用aliws分析器查询文档
-
登录目标阿里云Elasticsearch实例的Kibana控制台,根据页面提示进入Kibana主页。
登录Kibana控制台的具体操作,请参见 登录Kibana控制台 。说明 本文以阿里云Elasticsearch 6.7.0版本为例,其他版本操作可能略有差别,请以实际界面为准。
- 在左侧导航栏,单击 Dev Tools 。
-
在 Console 中,执行如下命令创建索引。
-
7.0以下版本
PUT /index "mappings": { "fulltext": { "properties": { "content": { "type": "text", "analyzer": "aliws" } -
7.0及以上版本
PUT /index "mappings": { "properties": { "content": { "type": "text", "analyzer": "aliws" }
以上示例创建了一个名称为 index 的索引,类型为 fulltext (7.x版本为 _doc )。包含了一个 content 属性,类型为 text ,并添加了 aliws 分析器。
预期结果如下。
{ "acknowledged": true, "shards_acknowledged": true, "index": "index" } -
-
执行如下命令,添加文档。
重要如下命令仅适用于Elasticsearch 7.0以下版本,7.0及以上版本需要将 fulltext 修改为 _doc 。
POST /index/fulltext/1 "content": "I like go to school." }以上示例创建了名称为 1 的文档,并设置了文档中的 content 字段的内容为 I like go to school. 。
预期结果如下。
{ "_index": "index", "_type": "fulltext", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 2, "failed": 0 "_seq_no": 0, "_primary_term": 1 } -
执行如下命令,查询文档。
重要如下命令仅适用于Elasticsearch 7.0以下版本,7.0及以上版本需要将 fulltext 修改为 _doc 。
GET /index/fulltext/_search "query": { "match": { "content": "school" }以上示例在所有 fulltext 类型的文档中,使用 aliws 分析器,搜索 content 字段中包含 school 的文档。
预期结果如下。
{ "took": 5, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 "hits": { "total": 1, "max_score": 0.2876821, "hits": [ "_index": "index", "_type": "fulltext", "_id": "2", "_score": 0.2876821, "_source": { "content": "I like go to school." }
配置词库
analysis-aliws插件支持词库配置,即上传自定义的词典文件 aliws_ext_dict.txt 。上传后节点能自动加载词典文件,实现词典的热更新操作(不会触发集群重启)。
重要
-
analysis-aliws插件安装后,系统不会自带默认词典文件 aliws_ext_dict.txt ,需要您手动上传。
-
在配置词库前,您需要先准备自定义的词典文件,并重命名为 aliws_ext_dict.txt 。
-
词典文件的内容中不能包含隐藏符号,例如以空格结尾的分词。
- 登录 阿里云Elasticsearch控制台 。
- 在左侧导航栏,单击 Elasticsearch实例 。
-
进入目标实例。
- 在顶部菜单栏处,选择资源组和地域。
- 在 Elasticsearch实例 中单击目标实例ID。
-
在左侧导航栏,选择 。
-
在 系统默认插件列表 中,单击 analysis-aliws 插件右侧 操作 列下的 词库配置 。
-
在 词库配置 页面下方,单击 配置 。
-
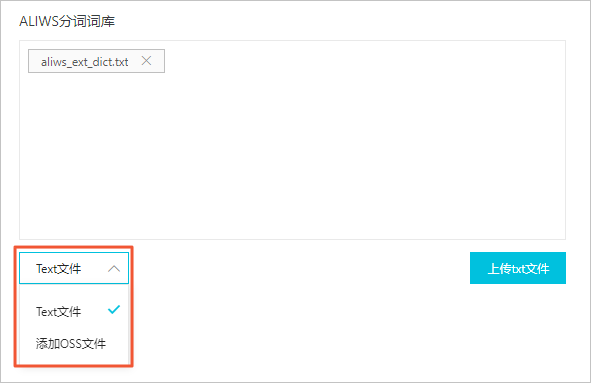
选择词典文件的上传方式,并按照以下说明上传词典文件。
重要analysis-aliws插件仅支持上传一个词典文件,且文件名必须为 aliws_ext_dict.txt 。如果您已经上传了 aliws_ext_dict.txt 文件并且需要更新词典文件,可单击 aliws_ext_dict.txt 右侧的 x ,删除已上传的 aliws_ext_dict.txt 词典文件并重新上传同名词典文件。
词典文件要求如下:
-
文件名:必须是aliws_ext_dict.txt。
-
文件格式:必须是UTF-8格式。
-
内容:每行一个词,前后不能有空白字符;需要使用UNIX或Linux的换行符,即每行结尾是
\n。如果是在Windows系统中生成的文件,需要在Linux机器上使用dos2unix工具将词典文件处理后再上传。
您可以通过 Text文件 和 添加OSS文件 两种方式上传词典文件:
-
Text文件 :单击 上传txt文件 ,选择一个本地文件进行上传。
-
添加OSS文件 :输入Bucket名称和文件名称,单击 添加 。
请确保Bucket与阿里云Elasticsearch实例在同一区域下。且源端(OSS)的文件内容发生变化后,需要重新上传词典文件才能生效,不支持自动同步更新。
-
-
单击 保存 。
保存后,不会触发集群重启,但会触发集群变更使词典文件生效,此过程需要10分钟左右。
说明如果您需要获取已经上传过的词库文件,可在配置前单击对应文件的
 图标进行下载。
图标进行下载。
测试分析器
执行如下命令,测试aliws分析器。
GET _analyze
"text": "I like go to school.",
"analyzer": "aliws"
}预期结果如下。
{
"tokens" : [
"token" : "i",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
"token" : "like",
"start_offset" : 2,
"end_offset" : 6,
"type" : "word",
"position" : 2
"token" : "go",
"start_offset" : 7,
"end_offset" : 9,
"type" : "word",
"position" : 4
"token" : "school",
"start_offset" : 13,
"end_offset" : 19,
"type" : "word",
"position" : 8
}测试分词器
执行如下命令,测试aliws_tokenizer分词器。
GET _analyze
"text": "I like go to school.",
"tokenizer": "aliws_tokenizer"
}预期结果如下。
{
"tokens" : [
"token" : "I",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
"token" : " ",
"start_offset" : 1,
"end_offset" : 2,
"type" : "word",
"position" : 1
"token" : "like",
"start_offset" : 2,
"end_offset" : 6,
"type" : "word",
"position" : 2
"token" : " ",
"start_offset" : 6,
"end_offset" : 7,
"type" : "word",
"position" : 3
"token" : "go",
"start_offset" : 7,
"end_offset" : 9,
"type" : "word",
"position" : 4
"token" : " ",
"start_offset" : 9,
"end_offset" : 10,
"type" : "word",
"position" : 5
"token" : "to",
"start_offset" : 10,
"end_offset" : 12,
"type" : "word",
"position" : 6
"token" : " ",
"start_offset" : 12,
"end_offset" : 13,
"type" : "word",
"position" : 7
"token" : "school",
"start_offset" : 13,
"end_offset" : 19,
"type" : "word",
"position" : 8
"token" : ".",
"start_offset" : 19,
"end_offset" : 20,
"type" : "word",
"position" : 9
}自定义分词器构造说明
-
analysis-aliws插件分词完成后,还会经过filter处理,包括:去词根filter、LowerCaseFilter、PorterStemFilter和StopFilter。如果您的自定义分词器上也需要使用这些filter,可在自定义分词器中加入analysis-aliws插件的分词器aliws_tokenizer,并根据业务需要增加filter配置,示例如下。其中 stopwords 内可以添加您业务所需配置的停用词。
PUT my-index-000001 "settings": { "analysis": { "filter": { "my_stop": { "type": "stop", "stopwords": [ "analyzer": { "my_custom_analyzer": { "type": "custom", "tokenizer": "aliws_tokenizer", "filter": [ "lowercase", "porter_stem", "my_stop" }说明如果您不需要filter,可自行删除filter配置。
-
aliws_tokenizer支持通过synonym构造自定义分词器,配置方式与IK分词器一致,详细信息请参见 使用同义词 。
常见问题
-
使用aliws分词器进行单词分词后,单词结尾字母缺失。例如:对
iPhone、Chinese进行分词得到的结果是Iphon、chines,结尾的e没有了。-
原因 :aliws在分词后有去词根的filter操作,导致结尾的
e被去掉了。 -
解决方案 :执行下面命令自定义analysis为:my_custom_analyzer,去掉filter部分。
PUT my-index1 "settings": { "number_of_shards": 1, "analysis": { "analyzer": { "my_custom_analyzer": { "type": "custom", "tokenizer": "aliws_tokenizer" } -
验证 :执行如下命令,测试分词效果是否符合预期。
GET my-index1/_analyze "analyzer": "my_custom_analyzer", "text": ["iphone"] }
-
相关文档
-
查看阿里云ES支持的插件,请参见 插件配置概述 。
-
调用API安装系统预置插件,请参见 InstallSystemPlugin 。
-
调用API更新analysis-aliws插件的词典文件,请参见 UpdateAliwsDict 。
-
调用API获取指定阿里云ES实例的插件列表。请参见 ListPlugins 。