|
|
|


在科学计算领域,Julia会代替Fortran和Matlab吗?
关注者
556
被浏览
405,788
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏

罗秀哲

一在物理系装x写代码的
简单来说,短期内不会,长期来说在编写新的程序上Julia代替Python,MATLAB以及Fortran是趋势。
下面我来仔细聊下这个日经问题
从实际问题出发
Julia解决了一个在科学计算(scientific computing)里很蛋疼的问题:如何让一个具有很强的一般性的程序(generic program)依然非常快。科学计算,所谓科学,是因为这类任务常常是为了 科学研究 进行的。而所谓研究一定会涉及到新的方法(否则还研究什么?),这意味着我们需要 非常灵活的代码来适应快速变化的需求 ,同时保证性能。
但是这不意味着高性能计算可以免费获得,Julia只是给你了可能性,一些高性能计算的知识依然是必要的。
不谦虚的展示下最近做的benchmark
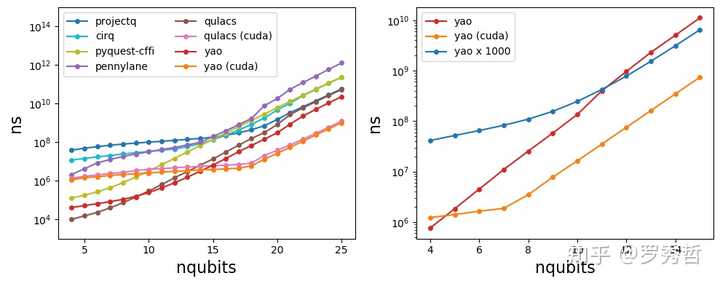

以上这是我们为做量子计算开发的 纯Julia框架Yao 和其它公司,个人的作品在性能上的比较。其中ProjectQ是首个实现量子霸权(quantum supremacy)模拟的软件,而qulacs是今年新出的由纯C++编写,手动调优的模拟器。可以看到完整的线路模拟(一个实际论文里常常会用到的尺寸,4-25比特)里我们有更好的性能。但是,我们在开发这个软件的时候,优先关注的是如何解决实际科研里的需求,性能一直是次要的。我们用 同一份核心代码 实现了针对线路的自动微分,符号计算,线路变换等等功能,最后才会去关注性能(详情可以参考我们最近的论文: https:// arxiv.org/pdf/1912.1087 7.pdf )。这是一个实际的科学计算场景会出现的需求: 性能重要吗?重要,性能不好可能跑不出结果。但是我们没时间去针对性地优化,因为今天优化完也许明天有了新方法,又不用这个代码了。这是和工业界相比的一个很大的区别,不存在针对某个具体的方法优化到极限这种情况。如果有那么不是因为要开始创业了,就是因为太闲了练练手。
Julia的很多主要package都有类似的benchmark。
而另外一个需求,我相信非常多的人遇到过:你和合作者想基于之前的一些工作做一个新东西。你的合作者写了一份代码,但是是TensorFlow写的,你的代码是PyTorch写的。于是你得把TensorFlow翻译成PyTorch:Python作为一个胶水语言,虽然它有很强的生态,但是不同的package之间兼容性是很差的,这是因为 为了能够在一个足够灵活的框架上实现高性能,在实现这些框架的时候往往在中间自带了一个完整的DSL编译器。
而在Julia里,很多package是可以恰好一起工作的。例如把Measurement塞进DifferentialEquations,就得到了带误差分析的微分方程求解器。把SymEngine塞到Yao里去就得到了量子线路的符号计算支持等等。
再者是 已经形成的可微分编程(Differentiable Programming)的生态 ,可能很多人听说过Zygote,这个可微分编程的编译器(扩展)。但是实际上它是一个非常简单的东西,其 实现原理我在之前的文章 里已经介绍过了。但是它作为一个“胶水”把整个Julia生态里的包都结合在一起了,这包括传统的机器学习,深度学习,Ray Tracer,也包括新兴的量子计算,微分方程等等。这是在Python,MATLAB和Fortran里都找不到的功能。
从技术角度来讲
实现同样的东西在Fortran或者MATLAB里可能会异常困难。
对特殊数组,矩阵的支持。由于缺乏统一的interface标准,配套的类型系统和编译基础设施,目前在Python,Fortran还是MATLAB里还不存在能够和Julia相媲美的矩阵/数组生态。而实际上,也只有Julia社区在语言设计的过程里认真考虑了这些问题。因为不同于其它语言的是在Julia社区科学计算是主流。
对异构计算,源码变换的支持。Julia是一个支持多级编程(staged programming)的语言,这意味着你可以通过宏来修改parsing过程,通过generated函数修改type inference以及SSA IR。所谓的自动微分,高级(指高级语言)CUDA编程都是通过这类机制实现的。而同样的功能在Python,Fortran或者MATLAB里可能就意味着要自己写一个新的编译器。其工程难度的差距是非常大的。虽然Python社区的Numba已经在这个方向上做出了非常突出的工作,但是受到语言本身的限制,依然无法完整的编译Python。
有人可能会说,是啊,但是这让Julia的语法和Python相比变得更复杂了。但是这些功能实际上甚至大部分开发者都不会用, 你可以选择不学,不用 。但是当真的需要的时候,懂了基本原理,上手也并不是很难。而相比之下,使用Python的ast模块自己重写部分解释器+编译器就显得麻烦多了。
主观来讲
作为一个从事科学计算的人 来讲(我自己平时会做凝聚态物理,量子计算相关的数值程序),越来越多的同行在看到我们使用Julia的效果以后开始使用Julia。这其中就包括 @LiTuX 所谓的 把祖传代码改成Julia 。而实际上效果并不是不好,而是非常好。例如我现在的老板最近在用Julia重写著名的量子蒙卡算法:随机序列展开(SSE)。它的实现原先是作者本人Sandvick写的Fortran(我最近听说他本人也开始写Julia了倒是),在这个年代,相比Fortran的问题大家多有讨论,可读性相对不好,不容易分享,作为静态编译语言不够灵活等问题。那为什么之前不用Python改写呢?因为在蒙卡算法里,for循环的性能是至关重要的,量子多体问题的计算量还没有到小到可以忽略这个overhead的程度。如果没有for循环,代码写起来会非常痛苦。
当然,也许你会说那为什么不用C++写然后再用Python作为脚本?不幸的是,这恰好是不适合这个解决方案的问题之一:因为根据具体问题需要不断调整更新策略,for循环这部分代码可能是经常需要改动的,用Python还不如写Fortran。
甚至包括在高性能计算里常常被提到的矩阵乘法(gemm),用Julia重写也能在保证一般性的前提下(不限制具体的元素类型)达到和手动调优接近的性能: https:// github.com/JuliaBLAS/Ju liaBLAS.jl
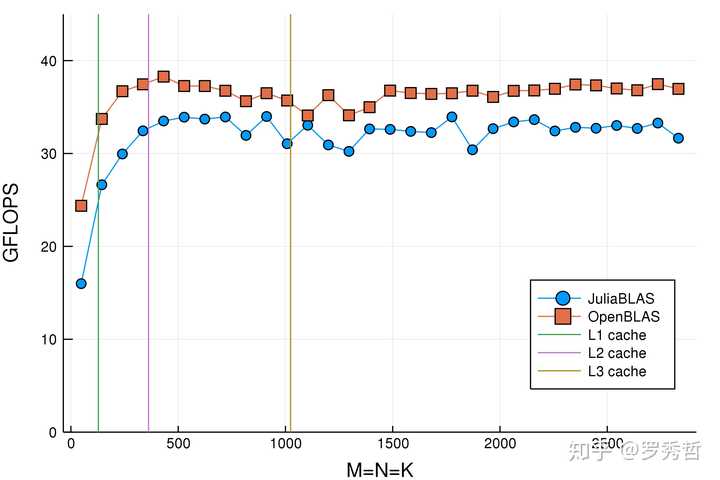

而 今年Alan Edelman获Sidney Fernbach Award ,我想也是对Julia在这个方向发展的一种认可。
日经的历史依赖问题
首先MATLAB作为一个商业软件,会逐渐被开源软件在新功能上被替代,这无所谓是Python还是Julia和收费没什么关系。因为商业公司没法和开源社区的更新速度相比,license的问题也阻止了很多项目去用它。但是老的功能依然会被大规模使用。所以不存在兼容MATLAB的问题,Julia社区里也一直是以替代MATLAB为目标。
然后Fortran本身实际上有很多经典的代码,而由GNU的努力,Fortran95编译出来是可以兼容C ABI的,这也就意味着使用旧的Fortran代码只是解决下编译依赖的问题。但是Fortran free是趋势,连MKL现在都没libfortran依赖了。而对新的代码,使用Fortran之后的版本(例如2008),其社区要比Julia还小,功能有限,生态上也已经无法和Julia相比了。
至于Python,相比之下Julia的工具链确实还有待完善,教学资料和问题回答数量(比如stackoverflow)也相对较少。这无疑增加了入门的难度,但是有目共睹的是,因为不是什么技术上的难题这个方面随着1.0的发布在快速的改善。此外由于Julia可以调用所有的Python代码,不存在不兼容历史代码的问题。
而科学计算的生态上,Julia已经不输Python了。在科学计算常用的工具里,比如线性代数,相关的package质量和功能都要比Python里的多。这里简单整理了下矩阵相关的:
标准库
- LinearAlgebra:定义了几个常用的矩阵类型 Hermitian,Symmetric,Diagonal
特殊数组
- StaticArrays 栈上的静态数组:通过编译器提供高性能的小矩阵计算
- FillArrays 一些特殊的稀疏矩阵,例如零矩阵,全是某个数的矩阵等等
- InfiniteArrays 无穷维矩阵/数组
- BlockArrays 分块数组
- LazyArrays 懒惰求值的Array
- AxisArrays 每个维度可以带标签的数组(也就是PyTorch所谓的NamedTensor)
特殊矩阵(2维数组)
- ToeplitzMatrices
- BandedMatrices
- SpecialMatrices:这个包里实现了一些特殊矩阵包括 Cauchy,Circulant,Campanian,Frobenius等十一种特殊矩阵(太多了就不一一列举了)
- CovarianceMatrices
- LuxurySparse(这是我们自己开发的):PermMatrix(广义交换矩阵),各种静态数组和上面的特殊矩阵组合的一些特化的实现
针对分布式和多进程的数组
- 标准库里的:SharedArray,可以在进程中共享内存
- DistributedArray,分布式的(稠密)数组,支持一些基本操作例如分布式乘法
虽然这些package由不同作者独立开发,但是这些不同的矩阵类型都不需要用户专门记忆使用方式,它们互相兼容,共享interface,唯一需要知道的是相关的背景知识而已。其它工具例如自动微分,线性代数求解器,微分方程求解器等等也是类似的。这些都已经有了比Python生态里更快的速度,更多的功能。所以 在Julia能够更好地解决科学计算中的实际问题情况下,所谓的用户体验还需要时间积累,但是取代只是时间问题。因为没人会关心syntax和信仰。