
DPDK-收包完整过程

本篇博客作为自己了解dpdk收包过程的一个记录。在写时发现已经有很多写DPDK收包过程的博客了,但还是决定自己写一遍。
DPDK收包分为两个阶段,首先是DMA将数据包从网卡搬运到内存,然后是调用dpdk提供的接口rte_eth_rx_burst去取。但是具体是怎么做的呢?简单大致的过程如图1所示。
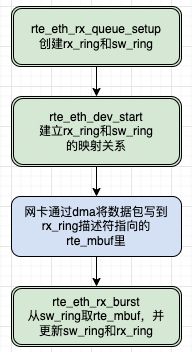
本文将按如下顺序进行展开。首先会简单介绍dma的环形缓存区,接着会介常规linux dma的收发包过程,然后会结合源码介绍dpdk的双环形缓存区设计,最后结合源码给出dpdk收包的过程。
1、DMA搬运数据包过程
网卡DMA控制器通过环形队列与CPU交互,环形队列由一组控制寄存器和一块物理上连续的缓存构成。主要的控制寄存器有Base, Size, Head和Tail。通过设置Base寄存器,可以将分配的一段物理连续的内存地址作为环形队列的起始地址,通告给DMA控制器。同样通过Size寄存器,可以通告内存快的大小。Head寄存器往往对软件只读,它表示硬件当前访问的描述符单元。而Tail寄存器则由软件来填写更新,通知DMA控制器当前已准备好被硬件访问的描述符单元。这一段话来自《深入浅出DPDK》的描述。
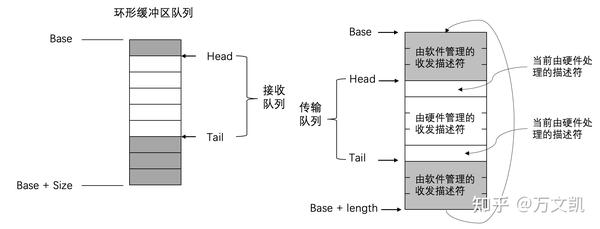

下面我们结合图3先简单看下Linux中DMA收包的过程,后面再给出dpdk的收包过程。
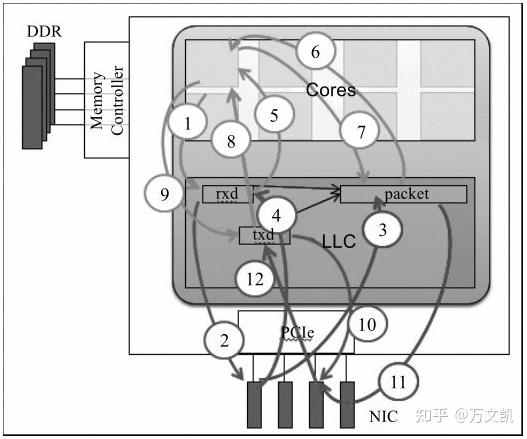

详细过程如下:
1、cpu填充地址到接收侧描述符,也就是将存放sk_buff的物理地址填写到Rx ring;
2、网卡读取接收侧描述符获取缓冲区地址;
3、网卡收到数据包后,根据2中读到的缓冲区地址,将数据包的内容通过dma写到缓冲区;
4、网卡回写接收侧描述符更新状态,表示数据包已写完;
5、cpu读取接收侧描述符以确定数据包接收完毕;
6、cpu读取包内容做转发判断;
7、cpu填充更改包内容,做发送准备,比如调换ip地址和mac地址;
8、cpu读取发送侧描述符,检查是否有发送完成标志;
9、cpu将准备发送的缓冲区地址填写到发送侧描述符,也就是将sk_buff的地址填写到Tx ring;
10、网卡读取发送侧描述符中的地址;
11、网卡根据描述符中地址,读取缓冲区的数据内容进行发送;
12、网卡写发送侧描述符,更新发送已完成标记。
上述步骤1-6为接收过程,步骤7-12为发送过程。步骤1-12这段描述也copy自《深入浅出DPDK》。
但是,这里我要补充的是,图2中的rxd和txd就是我们图1中介绍的环形缓冲区,分别叫做Rx ring和Tx ring,也统一叫做DMA ring buffer。
DMA ring buffer的创建在驱动初始化阶段,这块内存由网卡与处理器共享,详细描述见《Linux设备驱动程序》第15章内存直接访问。这也就解释了为啥cpu可以写和读Rx/Tx ring中的描述符,网卡也可以。
2、DPDK收包
在上文描述了linux dma收包过程,那么使用dpdk收包会有啥不同呢?要弄清楚dpdk的收包过程,需要先清楚dpdk的双环形缓存区设计。
2.1 DPDK双环形缓冲区结构
dpdk收包会用到两个ring,一个是rx ring,一个是sw ring,rx ring存放的是数据包的dma地址,sw ring存放的是rte_mbuf的地址,rx ring和sw ring是一一映射的。
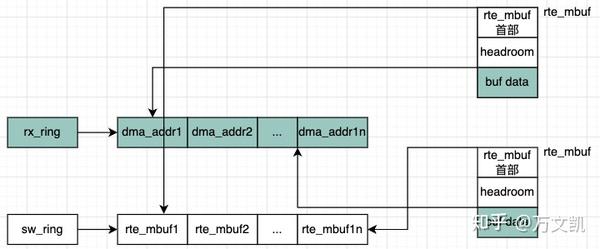

如图4所以,rx_ring里面的每个描述符中的地址填的是rte_mbuf的buf data地址,而sw_ring的每个描述符存放的是rte_mbuf的地址,也就是说当dma拿到dma_addr1后,然后将数据包写到dma_addr1指向的地址,实际是写到了rte_mbuf的data buffer里。
而rx_ring是一个环形,sw_ring也是一个环形,这就是《深入浅出DPDK》第6章中描述的双环形缓冲区,见图5。

这里有一个问题,就是 rx_ring和sw_ring是啥时候初始化的以及建立映射关系的?
拿ice driver举例,先看一个结构体struct ice_rx_queue,rx_ring和sw_ring成员是我们后面的重点关注对象。
@dpdk-stable-20.11.3/drivers/net/ice/ice_rxtx.h
struct ice_rx_entry {
struct rte_mbuf *mbuf;
struct ice_rx_queue {
struct rte_mempool *mp; /* mbuf pool to populate RX ring */
volatile union ice_rx_flex_desc *rx_ring;/* RX ring virtual address */
rte_iova_t rx_ring_dma; /* RX ring DMA address */
struct ice_rx_entry *sw_ring; /* address of RX soft ring */
uint16_t nb_rx_desc; /* number of RX descriptors */
}rx_ring和sw_ring是ice_rx_queue结构体成员。 rx_ring和sw_ring的初始化 都是在dpdk应用程序中调用rte_eth_rx_queue_setup函数时进行的,这个函数最后调用了ice_rx_queue_setup。
@dpdk-stable-20.11.3/drivers/net/ice/ice_rxtx.c
int ice_rx_queue_setup(struct rte_eth_dev *dev,
uint16_t queue_idx,
uint16_t nb_desc,
unsigned int socket_id,
const struct rte_eth_rxconf *rx_conf,
struct rte_mempool *mp)
struct ice_pf *pf = ICE_DEV_PRIVATE_TO_PF(dev->data->
dev_private);
struct ice_adapter *ad =
ICE_DEV_PRIVATE_TO_ADAPTER(dev->data->dev_private);
struct ice_vsi *vsi = pf->main_vsi;
struct ice_rx_queue *rxq;
const struct rte_memzone *rz;
uint32_t ring_size;
uint16_t len;
int use_def_burst_func = 1;
/* Allocate the rx queue data structure */
rxq = rte_zmalloc_socket(NULL, //创建rxq,rxq的类型为ice_rx_queue
sizeof(struct ice_rx_queue),
RTE_CACHE_LINE_SIZE,
socket_id);
/* Allocate the maximun number of RX ring hardware descriptor. */
len = ICE_MAX_RING_DESC;
* Allocating a little more memory because vectorized/bulk_alloc Rx
* functions doesn't check boundaries each time.
len += ICE_RX_MAX_BURST;
/* Allocate the maximum number of RX ring hardware descriptor. */
ring_size = sizeof(union ice_rx_flex_desc) * len;
ring_size = RTE_ALIGN(ring_size, ICE_DMA_MEM_ALIGN);
/* 创建rx_ring */
rz = rte_eth_dma_zone_reserve(dev, "rx_ring", queue_idx,
ring_size, ICE_RING_BASE_ALIGN,
socket_id);
/* Zero all the descriptors in the ring. */
memset(rz->addr, 0, ring_size);
/* 设置rx_ring的dma地址和虚拟地址。*/
rxq->rx_ring_dma = rz->iova;
rxq->rx_ring = rz->addr;
/* always reserve more for bulk alloc */
len = (uint16_t)(nb_desc + ICE_RX_MAX_BURST);
/* Allocate the software ring. */
rxq->sw_ring = rte_zmalloc_socket(NULL, //创建sw_ring
sizeof(struct ice_rx_entry) * len,
RTE_CACHE_LINE_SIZE,
socket_id);
}根据上面的分析,我们知道了rx_ring和sw_ring是在调用rte_eth_rx_queue_setup进而调用ice_rx_queue_setup时创建的, 但是我们不知道这两个ring是啥时候建立的映射。
rx_ring和sw_ring映射关系的建立发生在rte_eth_dev_start调用栈里,具体调用关系为rte_eth_dev_start-->ice_dcf_dev_start-->ice_dcf_start_queues-->ice_dcf_rx_queue_start-->alloc_rxq_mbufs,看看源码吧。
@dpdk-stable-20.11.3/drivers/net/ice/ice_dcf_ethdev.c
static int
alloc_rxq_mbufs(struct ice_rx_queue *rxq)
volatile union ice_rx_flex_desc *rxd;
struct rte_mbuf *mbuf = NULL;
uint64_t dma_addr;
uint16_t i;
for (i = 0; i < rxq->nb_rx_desc; i++) {
mbuf = rte_mbuf_raw_alloc(rxq->mp); //申请一个mbuf
if (unlikely(!mbuf)) {
PMD_DRV_LOG(ERR, "Failed to allocate mbuf for RX");
return -ENOMEM;
rte_mbuf_refcnt_set(mbuf, 1);
mbuf->next = NULL;
mbuf->data_off = RTE_PKTMBUF_HEADROOM;
mbuf->nb_segs = 1;
mbuf->port = rxq->port_id;
//获取rte_mbuf data buff的dma地址
dma_addr =
rte_cpu_to_le_64(rte_mbuf_data_iova_default(mbuf));
rxd = &rxq->rx_ring[i];
//填充rx_ring的描述符,其实就是rte_mbuf data buff的dma地址,当网卡收到数据包后直接通过
//dma往这个地址写,所以数据包就存放rte_mbuf里面了。
rxd->read.pkt_addr = dma_addr;
rxd->read.hdr_addr = 0;
#ifndef RTE_LIBRTE_ICE_16BYTE_RX_DESC
rxd->read.rsvd1 = 0;
rxd->read.rsvd2 = 0;
#endif
//填充sw_ring,结合图4,这样sw_ring和rx_ring就建立起了映射关系
rxq->sw_ring[i].mbuf = (void *)mbuf;
return 0;
}简单的说就是rte_eth_rx_queue_setup函数创建rx_ring和sw_ring,然后rte_eth_dev_start建立rx_ring和sw_ring之间的映射关系。
2.2 dpdk收包过程
花了很大篇幅来说明网卡的收包原理,以及解释dpdk底层相关的知识,现在终于可以说说dpdk是怎么收包的了。
dpdk提供的收包接口为rte_eth_rx_burst。这个函数最后其实调用了ice_recv_pkts函数。
@dpdk-stable-20.11.3/drivers/net/ice/ice_rxtx.c
uint16_t ice_recv_pkts(void *rx_queue, struct rte_mbuf **rx_pkts, uint16_t nb_pkts)
struct ice_rx_queue *rxq = rx_queue;
volatile union ice_rx_flex_desc *rx_ring = rxq->rx_ring; //重点关注
volatile union ice_rx_flex_desc *rxdp;
union ice_rx_flex_desc rxd;
struct ice_rx_entry *sw_ring = rxq->sw_ring; //重点关注
struct ice_rx_entry *rxe;
struct rte_mbuf *nmb; /* new allocated mbuf */
struct rte_mbuf *rxm; /* pointer to store old mbuf in SW ring */
uint16_t rx_id = rxq->rx_tail;
uint16_t nb_rx = 0;
uint16_t nb_hold = 0;
uint16_t rx_packet_len;
uint16_t rx_stat_err0;
uint64_t dma_addr;
uint64_t pkt_flags;
uint32_t *ptype_tbl = rxq->vsi->adapter->ptype_tbl;
struct rte_eth_dev *dev;
while (nb_rx < nb_pkts) { //期望接收nb_pkts个数据包
rxdp = &rx_ring[rx_id]; //rx_id是rx_ring新包的起始id,因为rx_ring是一个环
rx_stat_err0 = rte_le_to_cpu_16(rxdp->wb.status_error0);
/* Check the DD bit first */
if (!(rx_stat_err0 & (1 << ICE_RX_FLEX_DESC_STATUS0_DD_S)))
break;
/* allocate mbuf */
nmb = rte_mbuf_raw_alloc(rxq->mp); //申请一个新的rte_mbuf,用于回填rx_ring和sw_ring
if (unlikely(!nmb)) {
dev = ICE_VSI_TO_ETH_DEV(rxq->vsi);
dev->data->rx_mbuf_alloc_failed++;
break;
//rxdp指向一个rx_ring,现在rxd也指向了这个rx_ring
rxd = *rxdp; /* copy descriptor in ring to temp variable*/
nb_hold++;
//rx_id是sw_ring新包的起始id,因为sw_ring是一个环
rxe = &sw_ring[rx_id]; /* get corresponding mbuf in SW ring */
rx_id++; //rx_ring和sw_ring的下一个地址
if (unlikely(rx_id == rxq->nb_rx_desc))
rx_id = 0; //表示到了ring的尾部,重新开始从ring的头部开始取rte_mbuf
//保存sw_ring里面的rte_mbuf指针,这个rte_mbuf里面是有数据的
rxm = rxe->mbuf;
//给sw_ring里面回填新的描述符,也就是新申请的rte_mbuf指针,用于下一轮收包
rxe->mbuf = nmb;
//计算新申请的rte_mbuf data buff的dma地址
dma_addr =
rte_cpu_to_le_64(rte_mbuf_data_iova_default(nmb));
* fill the read format of descriptor with physic address in
* new allocated mbuf: nmb
rxdp->read.hdr_addr = 0;
//更新rx_ring里面的描述符地址
rxdp->read.pkt_addr = dma_addr;
/* calculate rx_packet_len of the received pkt */
rx_packet_len = (rte_le_to_cpu_16(rxd.wb.pkt_len) &
ICE_RX_FLX_DESC_PKT_LEN_M) - rxq->crc_len;
//填充收到的rte_mbuf里面的相关字段,这个应该很熟悉了
/* fill old mbuf with received descriptor: rxd */
rxm->data_off = RTE_PKTMBUF_HEADROOM;
rte_prefetch0(RTE_PTR_ADD(rxm->buf_addr, RTE_PKTMBUF_HEADROOM));
rxm->nb_segs = 1;
rxm->next = NULL;
rxm->pkt_len = rx_packet_len;
rxm->data_len = rx_packet_len;
rxm->port = rxq->port_id;
rxm->packet_type = ptype_tbl[ICE_RX_FLEX_DESC_PTYPE_M &
rte_le_to_cpu_16(rxd.wb.ptype_flex_flags0)];
ice_rxd_to_vlan_tci(rxm, &rxd);
rxq->rxd_to_pkt_fields(rxq, rxm, &rxd);
pkt_flags = ice_rxd_error_to_pkt_flags(rx_stat_err0);
rxm->ol_flags |= pkt_flags;
/* copy old mbuf to rx_pkts */
rx_pkts[nb_rx++] = rxm;
rxq->rx_tail = rx_id;
* If the number of free RX descriptors is greater than the RX free
* threshold of the queue, advance the receive tail register of queue.
* Update that register with the value of the last processed RX
* descriptor minus 1.
nb_hold = (uint16_t)(nb_hold + rxq->nb_rx_hold);
if (nb_hold > rxq->rx_free_thresh) {
rx_id = (uint16_t)(rx_id == 0 ?
(rxq->nb_rx_desc - 1) : (rx_id - 1));
/* write TAIL register */
ICE_PCI_REG_WC_WRITE(rxq->qrx_tail, rx_id);
nb_hold = 0;