- 本文使用的微信PC版本为
V2.6.4,如果你用的是最新的V3.x,你可能看不到/mp/profile_ext链接,虽然新版本链接被屏蔽了,但是这个接口依然可以调通。。。 - 微信官网没有
V2.6.4了,可以在本公众号 java-tech 回复 wx264 下载。 - charles调测时需要打开电脑代理。
- py调测报错:
ssl.SSLError: [SSL: WRONG_VERSION_NUMBER] wrong version number,请关闭本地代理。
声明:本文仅供技术研究,请勿用于非法采集。
a. 通过微信订阅号在发布文章,可以查找公众号的文章,方式见微信链接。,阅读数、点赞数、评论数仍无法抓取。
b. 通过搜狗微信搜索微信公众号,但是文章篇幅仍然后有限制,点赞、阅读数、和评论数无法抓取。
c. 通过“中间人方式”对数据进行拦截,过滤解析后进行抓取。
这里就时利用第三种c方式对数据进行抓取。
1. 安装代理AnProxy,在手机端安装CA证书,启动代理,设置手机代理;...
微信公众号已经成为生活的一部分了,虽然里面有很多作者只是为了蹭热点,撩读者的 G 点,自己从中获得一些收益;但是不乏好的订阅号,像刘大的码农翻身、曹大的caoz的梦呓等订阅号非常值得阅读。
平时有时候看到一些好的公众号,也会不自觉去查看该公众号的历史文章,然而每次都看不完,下一次再从微信里面打开历史文章,又需要从头翻起。而且对于写了很多年的大号,每次还翻不到底。有一些平台提供了相关...
因为微信的cookies和app_msg会过期
这篇文章主要是提供自动获取cookies和app_msg的过程
实现了cookies和app_msg的获取很容易就实现公众号的自动采集
只需要先登录微信pc端就可以
一.目前的流程
1.使用微信公众平台,进行扫码登录,获取公众号历史文章链接
2.开启mitmproxy代理
3.使用pywinauto模块实现微信pc端自动对文件传输助手发送公众号文章url并点击,从而实现获取微信pc端cookies和appmsg_token
1、通过登录微信公众号平台,在里面去搜索要爬取的公众号,通过抓包等方式获取相应的接口;
2、通过安卓模拟器的方式去抓包;
3、通过搜狗的微信模块(https://weixin.sogou.com/)
4、其他等方式...
这里使用第一种方式去爬取数据,当然了,首先你要有一个微信公众号账号。
微信公众号 : https://mp.weixin.qq.com
1.登录微信公众号
2.进入创作管理-图文素材-图文模板-编辑-添加引用-查找公众号文章
MPSpider:一个强大的微信公众号文章抓取框架
项目地址:https://gitcode.com/ksky521/mpspider
MPSpider 是一款基于 Python 的高效、灵活的微信公众号文章爬虫框架,它允许开发者轻松地抓取和解析微信公众号的历史文章数据,从而进行数据分析、内容挖掘或构建自定义的微信公众号信息平台。
MPSpider 提供了一个清晰的 API 设计,让开发...
之前虽然做过网页爬取,但微信爬取一直没做过,因为我一直不知道网页可以进微信公众平台,只用过微信客户端进微信公众号。既然可以通过网页进微信公众平台,那么爬取微信公众号文章就流程上就没太多难度了。
自己在网上找的一些python爬虫文章不太好用,就亲自写了一套,包括详细的页面附图和代码注释,代码复制下来后可以直接运行,供需要的同行参考交流。 爬取微信公众号文章之前,需要先申请微信公...
class LianjiaSpider(RedisSpider):
name = 'lianjia_spider'
allowed_domains = ['lianjia.com']
# 设定爬取的初始链接
def start_requests(self):
url = 'https://sh.lianjia.com/ershoufang/'
yield scrapy.Request(url=url, callback=self.parse)
# 解析二手房列表页
def parse(self, response):
# 获取下一页链接并加入Redis队列
next_page = response.css('div.page-box a.next::attr(href)').get()
if next_page is not None:
next_page_url = response.urljoin(next_page)
self.server.rpush('lianjia_spider:start_urls', next_page_url)
# 解析二手房信息
house_list = response.css('ul.sellListContent li.clear')
for house in house_list:
# 获取房屋名称和链接
name = house.css('div.title a::text').get()
link = house.css('div.title a::attr(href)').get()
# 获取房屋价格
price = house.css('div.totalPrice span::text').get()
# 获取房屋面积和户型
area = house.css('div.houseInfo a::text').getall()[1]
layout = house.css('div.houseInfo a::text').getall()[0]
# 输出房屋信息
print(name, link, price, area, layout)
5. 运行爬虫
$ scrapy runspider lianjia_spider.py
6. 启动Redis队列
$ redis-server
7. 启动Redis Spider
$ scrapy runspider lianjia_spider.py
运行后,Scrapy会将初始链接加入Redis队列,并从队列中获取链接进行爬取。当爬取到列表页时,会将下一页的链接加入Redis队列,从而实现了分布式爬取。爬取到的房屋信息会输出到控制台。



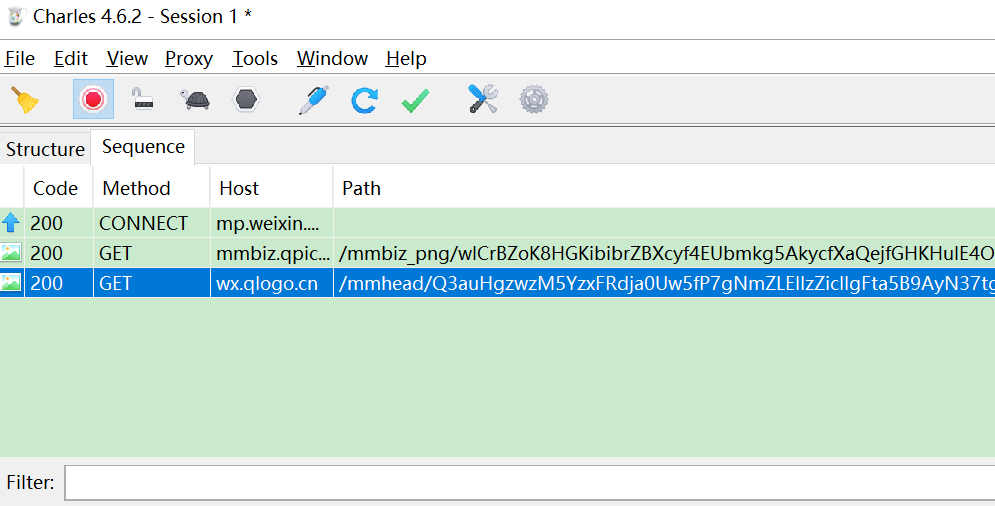
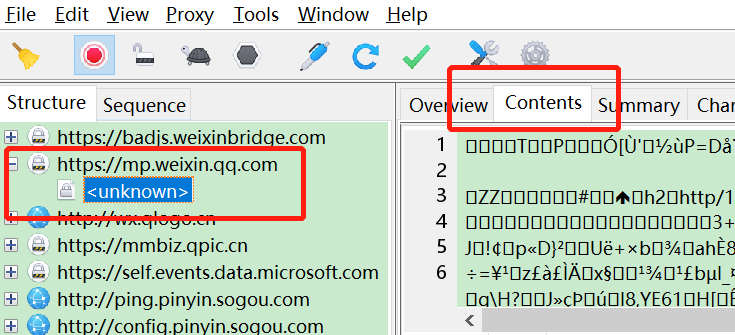
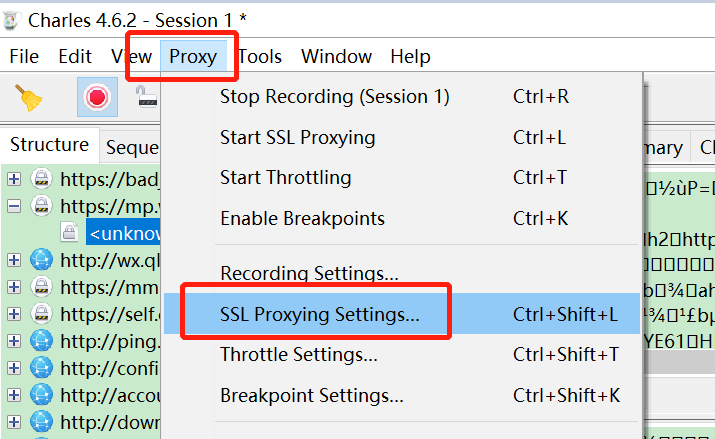
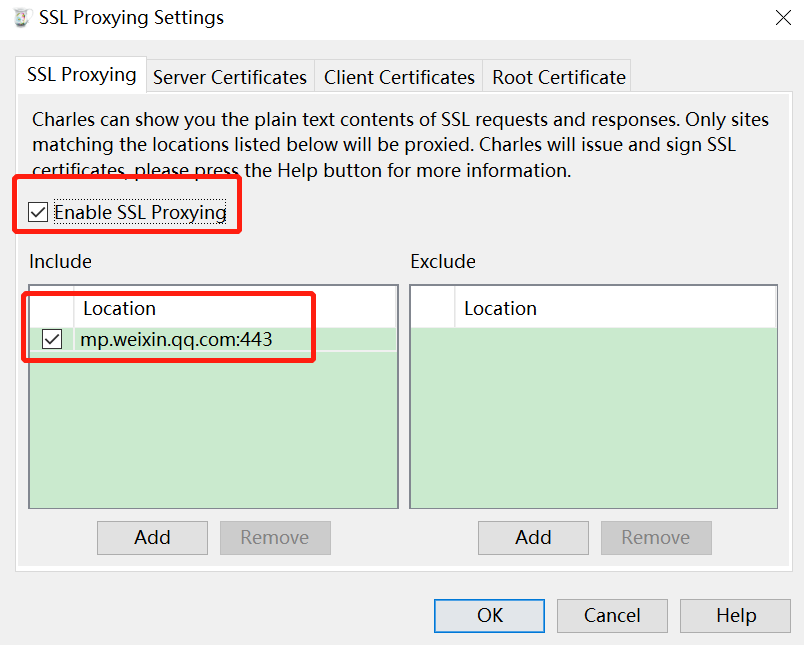
 注意:
如果微信PC提示访问链接不安全,请点击继续访问。
注意:
如果微信PC提示访问链接不安全,请点击继续访问。
