

卷积神经网络(CNN)Python的底层实现——以LeNet为例

本文介绍了如何使用Python从底层实现一个简单但经典的卷积神经网络结构——LeNet,并用它完成MNIST手写数字识别任务。
具体的完整代码以及代码的使用方法,可以光顾我的Github
我的代码对算法实现方法比较直观,基本上是直接对着公式翻译过来,使用的也主要是函数式编程,只涉及基础的Python语法以及基础的Numpy使用。优点在于对于新手小白比较友好,缺点在于算法效率略低。
之前我写了三篇文章,分别介绍全连接神经网络反向传播理论,全连接神经网络底层Python实现,以及卷积神经网络的反向传播理论。这三篇文章涉及的知识点主要是为这篇卷积神经网络的实现打基础。避免这篇文章中需要牵扯太多的细节。
在这三篇文章中我分别介绍了:
- 全连接层反向传播的数学推导,随机梯度下降法进行训练的原理。
- MNIST数据集下载以及预处理的方法,全连接层反向传播以及随机梯度下降法的Python实现。
- 卷积神经网络中,卷积层以及池化层的反向传播数学推导。
对于上面提到的一些知识点,在这篇文章中会简要带过,如果读者朋友还不太熟悉可以参考我的文章或的别人写的教程。
MNIST数据集预处理:
要进行训练,首先需要准备好数据集,我们使用的仍是从Yann Lecun网站上下载下来的是idx格式的数据。
与之前文章中全连接神经网络对MNIST数据集处理方法略有不一样的是。图片需要存储为一个4维的张量,格式为:图片数×行数×列数×通道数。标签需要存储为一个3维的张量,格式为:标签数×类别数×1.
另外由于LeNet神经网络输入为32×32的图像,而原始的MNIST数据集图片大小为28×28,我们需要将MNIST图片先进行零填充,使它符合LeNet的输入要求。
# 零填充
def padding(image, zero_num):
if len(image.shape) == 4:
image_padding = np.zeros((image.shape[0],image.shape[1]+2*zero_num,image.shape[2]+2*zero_num,image.shape[3]))
image_padding[:,zero_num:image.shape[1]+zero_num,zero_num:image.shape[2]+zero_num,:] = image
elif len(image.shape) == 3:
image_padding = np.zeros((image.shape[0]+2*zero_num, image.shape[1]+2*zero_num, image.shape[2]))
image_padding[zero_num:image.shape[0]+zero_num, zero_num:image.shape[1]+zero_num,:] = image
else:
print("维度错误")
sys.exit()
return image_padding
train_image = padding(train_image,2)#对初始图像进行零填充,保证与LeNet输入结构一致60000*32*32*1
test_image = padding(test_image,2)最终我们得到的数据格式如下:
训练图片:60000×32×32×1,训练标签:60000×10×1
验证图片:10000×32×32×1,验证标签:10000×10×1
LeNet卷积神经网络前向传播:
LeNet包含两个卷积层,两个池化层以及三层全连接层。
输入是32×32×1的图片张量,经过6×5×5×1的卷积核卷积后,图片格式变为28×28×6。再经过最大池化,图片尺寸缩小一半,变为14×14×6。再经过16×5×5×6的卷积核卷积后,图片格式变为10×10×16。再经过一次最大池化,图片再缩小一半,变为5×5×16。
接下来是全连接神经网络了,不过需要先将图片张量拉直,变为400×1的列向量。再分别经过120个结点的隐藏层和84个结点的隐藏层后,输出到输出层的10个结点作为预测结果。
卷积的实现:
第一种实现卷积的方法是依据卷积计算的定义,直接去进行实现。即让卷积核在图片上移动,每移动一次,逐元素相乘再相加,得到输出图片的一个值。
def
conv(img, conv_filter):
'''img为三维张量[行,列,通道],conv_filter为四维张量[卷积核序号,行,列,通道],二者通道数应该一致
该函数实现对应通道的二维图片与二维卷积核进行相应地卷积后求和,得到输出的一个通道,
有多少卷积核即对应多少个输出通道 '''
if len(img.shape)!=3 or len(conv_filter.shape)!=4:
print("卷积运算所输入的维度不符合要求")
sys.exit()
if img.shape[-1] != conv_filter.shape[-1]:
print("卷积输入图片与卷积核的通道数不一致")
sys.exit()
# 初始化输出的特征图片,由于没有使用零填充,图片尺寸会减小
img_out = np.zeros((img.shape[0]-conv_filter.shape[1]+1, img.shape[1]-conv_filter.shape[2]+1, conv_filter.shape[0]))
for filter_num in range(conv_filter.shape[0]):
curr_filter = conv_filter[filter_num, :] # 取出第filter_num个卷积核参与卷积运算
conv_map = conv_(img[:, :, 0], curr_filter[:, :, 0]) # 将第filter_num个卷积核的第一个通道与图片第一个通道进行二维卷积预算
for ch_num in range(1, curr_filter.shape[-1]):
conv_map = conv_map + conv_(img[:, :, ch_num], curr_filter[:, :, ch_num]) # 对其它通道也进行二维卷积运算并加在第一个通道运算结果上
img_out[:, :, filter_num] = conv_map # 使第filter_num个卷积核运算结果成为输出图片的第filter_num个通道
return img_outconv函数将一个三维图片张量与一个四维卷积核张量进行卷积操作。就像之前文章说的,卷积神经网络中的卷积实际上是若干次二维卷积操作,在conv函数中调用了conv_函数,conv_函数用于实现二维卷积操作。
def conv_(img, conv_filter):
# 对二维图像以及二维卷积核进行卷积,不填充
filter_size = conv_filter.shape[0]
result = np.zeros((img.shape[0]-conv_filter.shape[0]+1, img.shape[1]-conv_filter.shape[1]+1))
for r in np.uint16(np.arange(0, img.shape[0]-conv_filter.shape[0]+1)):
for c in np.uint16(np.arange(0, img.shape[1]-conv_filter.shape[1]+1)):
curr_region = img[r: r+conv_filter.shape[0], c: c+conv_filter.shape[1]]
curr_result = curr_region * conv_filter
conv_sum = np.sum(curr_result)
result[r, c] = conv_sum
return result 尽管上面卷积的实现尽管非常直观,但缺点是计算效率低,在训练神经网络时会消耗大量的时间。为了提高的计算效率,我们可以将三维图片张量转为二维矩阵,四维卷积核张量也转为二维矩阵,将张量卷积操作转化为矩阵的乘法操作,以此大幅提高计算效率。具体转化方法见下图:
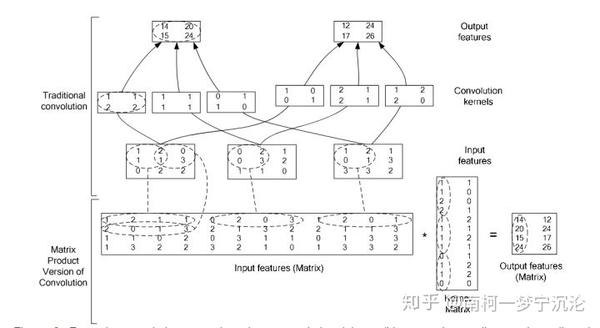

具体参见贾神的回答:
在 Caffe 中如何计算卷积? - 贾扬清的回答 - 知乎 https://www. zhihu.com/question/2838 5679/answer/44297845
下面给出第二个版本的卷积代码:
def conv(img, conv_filter):
if len(img.shape)!=3 or len(conv_filter.shape)!=4:
print("卷积运算所输入的维度不符合要求")
sys.exit()
if img.shape[-1] != conv_filter.shape[-1]:
print("卷积输入图片与卷积核的通道数不一致")
sys.exit()
img_h, img_w, img_ch = img.shape
filter_num, filter_h, filter_w, img_ch = conv_filter.shape
feature_h = img_h - filter_h + 1
feature_w = img_w - filter_w + 1
# 初始化输出的特征图片,由于没有使用零填充,图片尺寸会减小
img_out = np.zeros((feature_h, feature_w, filter_num))
img_matrix = np.zeros((feature_h*feature_w, filter_h*filter_w*img_ch))
filter_matrix = np.zeros((filter_h*filter_w*img_ch, filter_num))
# 将输入图片张量转换成矩阵形式
for i in range(feature_h*feature_w):
for j in range(img_ch):
img_matrix[i, j*filter_h*filter_w:(j+1)*filter_h*filter_w] = \
img[np.uint16(i/feature_w):np.uint16(i/feature_w+filter_h),np.uint16(i%feature_w):np.uint16(i%feature_w+filter_w),j].reshape(filter_h*filter_w)
# 将卷积核张量转换成矩阵形式
for i in range(filter_num):
filter_matrix[:,i] = conv_filter[i,:].reshape(filter_w*filter_h*img_ch)
feature_matrix = np.dot(img_matrix, filter_matrix)
for i
in range(filter_num):
img_out[:,:,i] = feature_matrix[:,i].reshape(feature_h, feature_w)
return img_out
最大池化的实现:
在进行最大池化操作时,不仅需要找出每个区域的最大值,还需要同时记录下最大值在区域中所处的位置,确保之后delta误差反向传播的正确进行。
def pool(feature, size=2, stride=2):
'''最大池化操作
同时输出池化后的结果以及用于记录最大位置的张量,方便之后delta误差反向传播'''
pool_out = np.zeros([np.uint16((feature.shape[0]-size)/stride+1),
np.uint16((feature.shape[1]-size)/stride+1),
feature.shape[2]])
pool_out_max_location = np.zeros(pool_out.shape) # 该函数用于记录最大值位置
for ch_num in range(feature.shape[-1]):
r_out = 0
for r in np.arange(0, feature.shape[0]-size+1, stride):
c_out = 0
for c in np.arange(0, feature.shape[1]-size+1, stride):
pool_out[r_out, c_out, ch_num] = np.max(feature[r:r+size, c:c+size, ch_num])
pool_out_max_location[r_out, c_out, ch_num] = np.argmax(feature[r:r+size, c:c+size, ch_num]) #记录最大点位置
c_out += 1
r_out += 1
return pool_out, pool_out_max_location找最大值用np.max函数,找最大值位置用np.argmax函数
LeNet前向传播实现:
在前向传播中,我们只需要将卷积函数,池化函数,全连接操作进行相应地堆叠即可。只要定义好了基本的模块单元,要实现什么样结构的神经网络都可以。
我们先定义ConvNet类,初始化各层的参数,方便类中其它的方法使用或者修改。
class ConvNet(object):
def __init__(self):
2层卷积,2层池化,3层全连接'''
self.filters = [np.random.randn(6, 5, 5, 1)]
self.filters_biases = [np.random.randn(6,1)]
self.filters.append(np.random.randn(16, 5, 5, 6))
self.filters_biases.append(np.random.randn(16,1))
self.weights = [np.random.randn(120,400)]
self.weights.append(np.random.randn(84,120))
self.weights.append(np.random.randn(10,84))
self.biases = [np.random.randn(120,1)]
self.biases.append(np.random.randn(84,1))
self.biases.append(np.random.randn(10,1))再依据LeNet结构,写出前向传播的函数:
def feed_forward(self, x):
#第一层卷积
conv1 = add_bias( conv(x, self.filters[0]), self.filters_biases[0] )
relu1 = relu(conv1)
pool1, pool1_max_locate = pool(relu1)
#第二层卷积
conv2 = add_bias( conv(pool1, self.filters[1]), self.filters_biases[1])
relu2 = relu(conv2)
pool2, pool2_max_locate = pool(relu2)
straight_input = pool2.reshape(pool2.shape[0] * pool2.shape[1] * pool2.shape[2], 1)
#第一层全连接
full_connect1_z = np.dot(self.weights[0], straight_input) + self.biases[0]
full_connect1_a = relu(full_connect1_z)
#第二层全连接
full_connect2_z = np.dot(self.weights[1], full_connect1_a) + self.biases[1]
full_connect2_a = relu(full_connect2_z)
#第三层全连接(输出)
full_connect3_z = np.dot(self.weights[2], full_connect2_a) + self.biases[2]
full_connect3_a = soft_max(full_connect3_z)
return full_connect3_a限于篇幅,就不将relu函数和卷积层中add_bias函数的实现代码放出来,直接根据定义来写即可,但需要重点说一下softmax函数:
def soft_max(z):
tmp = np.max(z)
z -= tmp # 用于缩放每行的元素,避免溢出,有效
z = np.exp(z)
tmp = np.sum(z)
z /= tmp
return zsoftmax函数写的时候不能直接按照定义来写,而需要增加一步先对每个元素进行缩放,即减去最大值后,再代入公式,不然一定会发生溢出,从而导致无法训练。
LeNet卷积神经网络反向传播训练
反向传播算法主要涉及各层delta误差的计算以及得到某层delta误差后如何计算该层参数的导数。关于LeNet全连接层部分的实现方法,与我之前全连接神经网络的实现文章中一致,在此不再重复。我们在此主要介绍卷积层以及池化层反向传播的实现。
卷积层中delta误差的反向传播
卷积层delta误差反向传播公式如下:
\delta^l =\delta^{l+1}* ROT180(w^{l+1})\odot\sigma'(z^l)
我看了下我的源代码,没有为这个计算单独写函数,而是直接用一行语句实现的
delta_pool1 = conv(padding(delta_conv2, self.filters[1].shape[1]-1),\
rot180(self.filters[1]).swapaxes(0,3))公式与我们写的代码有两点不一样。一是公式为了简洁,忽略了 \delta^{l+1} 的零填充,因为 \delta^{l+1} 本身尺寸就比 \delta^l 小,为了卷积后与 \delta^l 尺寸一致,需要先进行零填充。 二是公式是针对于二维卷积,我们实际上进行的是张量卷积运算,由于之前写过conv函数,所以可以直接拿过来用。但就像矩阵乘法中需要转置一样,我们需要对卷积核第0维和第3维进行互换。
rot180度本质上将一个二维矩阵上下颠倒一次再左右颠倒,numpy中有对应的函数np.flipud和np.fliplr:
def rot180(conv_filters):
rot180_filters = np.zeros((conv_filters.shape))
for filter_num in range(conv_filters.shape[0]):
for img_ch in range(conv_filters.shape[-1]):
rot180_filters[filter_num,:,:,img_ch] = np.flipud(np.fliplr(conv_filters[filter_num,:,:,img_ch]))
return rot180_filters池化层中delta误差的反向传播:
由于我们LeNet中使用的是最大池化,因此反向传播时将delta误差误差放到前向传播时记录的最大位置处,其它点置零即可。
def pool_delta_error_bp(pool_out_delta, pool_out_max_location, size=2, stride=2):
# 池化层delta误差反向传播
delta = np.zeros([np.uint16((pool_out_delta.shape[0]-1)*stride+size),
np.uint16((pool_out_delta.shape[1]-1)*stride+size),
pool_out_delta.shape[2]])
for ch_num in range(pool_out_delta.shape[-1]):
for r in range(pool_out_delta.shape[0]):
for c in range(pool_out_delta.shape[1]):
order = pool_out_max_location[r,c,ch_num]
m = np.uint16(stride*r+order//size)
n = np.uint16(stride*c+order%size)
delta[m, n, ch_num] = pool_out_delta[r,c,ch_num]
return delta计算卷积核的导数
\frac {\partial C}{\partial w^l} = \frac {\partial C}{\partial z^l} \frac{\partial z^l}{\partial w^l}= \delta^l * a^{l-1}
每对一个通道的输入图片和一个通道的输出图片的delta误差进行二维卷积,我们就得到一个二维卷积核的导数。
我们将 原图通道数×卷积结果通道数 个二维卷积核的导数重新进行组合成4维张量,即可得到整个卷积核的导数。
def conv_cal_w(out_img_delta, in_img):
#由卷积前的图片以及卷积后的delta计算卷积核的梯度
nabla_conv = np.zeros([out_img_delta.shape[-1], in_img.shape[0]-out_img_delta.shape[0]+1,
in_img.shape[1]-out_img_delta.shape[1]+1, in_img.shape[-1]])
for filter_num in range(nabla_conv.shape[0]):
for ch_num in range(nabla_conv.shape[-1]):
nabla_conv[filter_num,:,:,ch_num] = conv_(in_img[:,:,ch_num], out_img_delta[:,:,filter_num])