

图像检索综述

图像检索概述
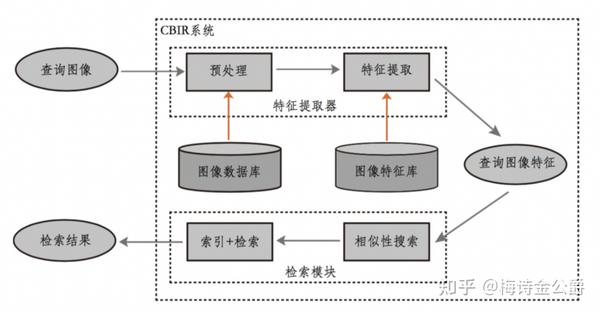
背景
CBIR:content-based image retrieval,基于内容的图像检索。20世纪90年代初,CBIR的研究才真正开始,研究人员根据纹理、颜色等视觉特征对图像构建索引,同时,也有很多算法和图像检索系统被提出,这期间,图像检索的策略主要集中在提取图像的全局描述符,但是全局描述符这种方法在诸如光照,形变,遮挡和裁剪这些情况下难以达到预想的效果,基于局部特征的图像检索算法应运而生。
检索任务分为实例图像检索和类别图像检索,前者是给定一张物体类型的待查询图片,查询出包含拍摄自不同角度、光照或有遮挡的,含有相同物体的图片,而类别图像检索的目标是检索出同类别的图片,本文介绍实例图像检索。

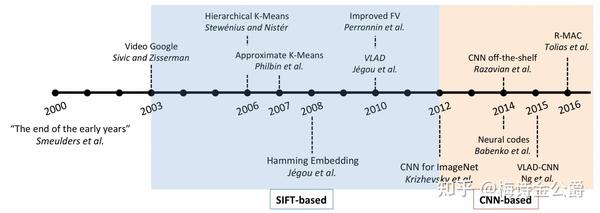
研究进展
SIFT-based:从2003年到2012年,图像检索主要是基于SITF方法展开研究,随着词袋模型(BoW)进入图像检索社区的视野,包括之后的VLAD,这十年都给图像检索任务带来了各种提升。
CNN-based:在2012年,Krizhevsky等人使用AlexNet神经网络模型在ImageNet 2012上识别率取得最高分,受此影响,图像检索从那以后的研究重心开始从SITF向卷积神经网络(CNN)的方法转移。

SIFT由检测器和描述符组成,但在图像检索中,我们只把描述符提出来进行后续使用,在OpenCV的是实现中,对于每一个SITF特征点,默认会生成128维向量,BOW通常是将一张图像里面的所有SIFT特征转换成固定长度的直方图(向量),这样,就可以直接计算两个向量距离来判断相似度了。
基于CNN的图像检索通常会直接使用预训练好的CNN模型或微调后应用于特定的检索任务,这些方法一般只将图像输入到网络中一次就可以获取描述符,一些基于图像块的方法则是将图像多次输入到网络中,这和SIFT方法的习惯有些类似。
传统图像检索
SIFT算法
在介绍SIFT算法以前,先介绍一下常见的传统特征提取算法:
LBP(Local Binary Patterns)、HOG(Histogram of Oriented Gradient)、Haar
LBP:
- 首先将检测图像划分为16*16的小区域(cell)。
- 对于每个cell中的一个像素,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数,即得到该窗口中心像素点的LBP值。
- 遍历整张图像后,就会得到一张新的图像(LBP值),该图像就为提取出的纹理图。
特点:具有旋转不变性和灰度不变性
以上是原始的LBP算法,也有改进算法:圆形LBP算法,详见
https:// zhuanlan.zhihu.com/p/47 1318486
HOG:
- 图像预处理
对图像进行灰度处理,采用Gamma校正法对输入图像进行颜色空间的标准化,目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰。
2. 计算图像梯度
使用一维的sober算子分别计算每个像素点的水平以及竖直方向的梯度,这一步主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。
3. 计算梯度直方图
图像切分为8*8大小的cell,在每个cell中计算梯度直方图,统计每个cell的梯度直方图(不同梯度的个数),即可形成每个cell的descriptor。
4. 图像HOG特征向量
将2*2 cell组成一个block,一个block内所有cell的特征descriptor串联起来便得到该block的HOG特征descriptor。
详见: https:// zhuanlan.zhihu.com/p/44 5740963
什么是SITF算法?
SIFT
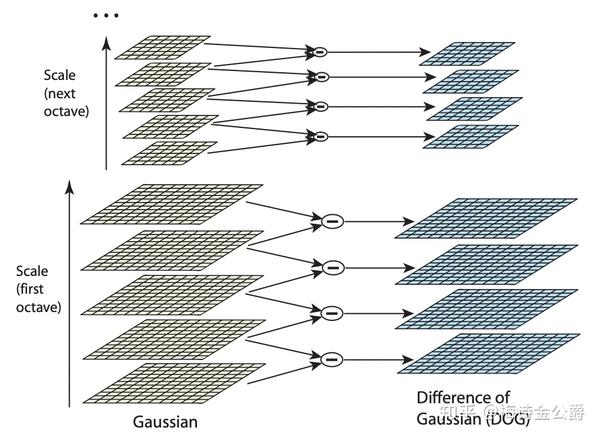
- 提取关键点:关键点是一些十分突出的不会因光照、尺度、旋转等因素而消失的点,比如角点、边缘点、暗区域的亮点以及亮区域的暗点。此步骤是搜索所有尺度空间上的图像位置,通过高斯微分函数来识别潜在的具有尺度和旋转不变的兴趣点。其主要步骤可以分为建立高斯金字塔、生成DOG高斯差分金字塔和DOG局部极值点检测
- 定位关键点并确定特征方向:在每个候选的位置上,通过一个拟合精细的模型(三维二次函数)来确定位置和尺度,关键点的选择依据于它们的稳定程度。
- 基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向,所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。
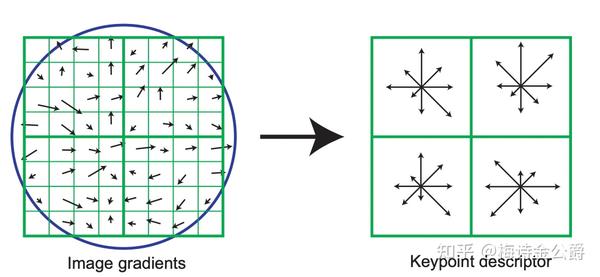
- 通过以上步骤,每一个关键点拥有三个信息:位置、尺度以及方向。接下来就是为每个关键点建立一个描述符,用一组向量将这个关键点描述出来,使其不随各种变化而改变,比如光照变化、视角变化等。这个描述子不但包括关键点,也包含关键点周围对其有贡献的像素点,并且描述符应该有较高的独特性,以便于提高特征点正确匹配的概率。 SIFT描述子是关键点邻域高斯图像梯度统计结果的一种表示。通过对关键点周围图像区域分块,计算块内梯度直方图,生成具有独特性的向量,这个向量是该区域图像信息的一种抽象,具有唯一性。Lowe建议描述子使用在关键点尺度空间内4*4的窗口中计算的8个方向的梯度信息,所以SIFT的描述符是4*4*8=128维向量表征。
详见原论文:
https://www. cs.ubc.ca/~lowe/papers/ ijcv04.pdf
部分截图:


如果看论文比较吃力,可以结合中文技术博客,详见: https:// blog.csdn.net/qq_403699 26/article/details/88597406
关于SIFT的实现,网上已经有不少版本了,其中Imutils( https:// github.com/jrosebr1/imu tils )有较多的图像特征提取算法实现
SIFT特征提取代码(PYTHON)
示例代码:


结果:


在局部手工特征提取的方法中,还有基于SIFT衍生出来的SURF、PCA-SIFT、ROOTSIFT算法以及ORB等算法,本文不在赘述。
BOVW
BOVW(Bag Of Visual Word)模型,是现在一种用于图像检索的一种方法,它最早用于对于文章内容的检索,原理是将文本看作是单词的集合,不考虑其中的语法,上下文等,通过建立词典,对每个单词出现次数进行统计,以便得到文本内容的分类。计算机视觉的专家从中获得灵感,将其用于图像的检索中,就有了Bag Of Visual Word (也可以叫Bag of Features)。
根据上面的介绍,我们知道一张图片提取的SITF特征是n*128维的矩阵,即有n个SIFT特征点,显然,我们不能直接去特征点粒度的去比较两个图片相似度,那样计算复杂度太高。如果一张图片能用一个一维向量表示出来,那直接计算两个向量的相似度是最直观的做法。以下是SIFT+BOVW的方法步骤:
- 利用SIFT算法从不同类别的图像中提取特征向量,这些向量代表的是图像中局部不变的特征点


2. 将所有特征点向量集合到一块,利用K-Means算法聚类,合并词义相近的视觉词汇,构造一个包含K个词汇的单词表
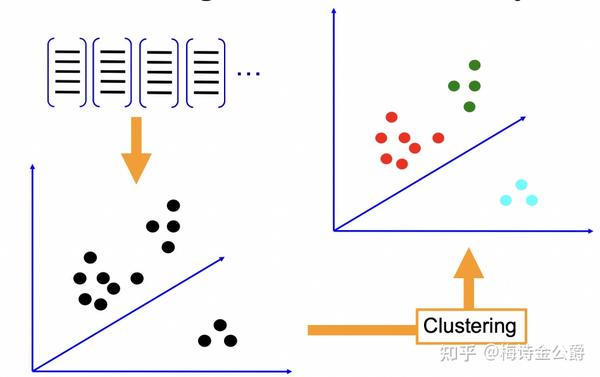

3. 统计单词表中每个单词在图像中出现的次数,从而将图像表示成为一个K维数值向量
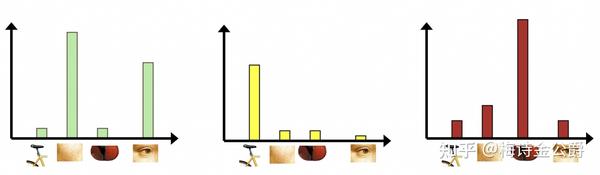

相关: http:// vision.stanford.edu/tea ching/cs131_fall1718/files/14_BoW_bayes.pdf
根据以上的介绍,聚类K的不同选取,会决定最后生成的的向量的大小,我们将K个词汇表叫做编码本。根据编码本的大小,可分为小型、中型和大型编码本。其中,对于中大型编码,为了平衡效率和准确率,还会使用倒排索引、二进制签名等方法。
倒排索引
如前所述,对于大型图像检索系统,必然会造成性能问题,通常会引入倒排索引、二进制签名的方法。
由于下面会涉及到TF-IDF,先简单介绍下其概念,TF-IDF是一种用于信息检索的常用加权技术,在文本检索中,用以评估词语对于一个文件数据库中的其中一份文件的重要程度。词语的重要性随着它在文件中出现的频率成正比增加,但同时会随着它在文件数据库中出现的频率成反比下降。
引入倒排后,图像检索的步骤如下:
- 提取图像的SIFT特征
- 将所有特征集合起来进行K-Means聚类
- 求出各个聚类的聚类中心并存入文件(编码本)
- 根据TF-IDF转化成视觉单词(visual words)的频率直方图
- 构造特征到图像的倒排表,通过倒排表快速索引相关图像
- 根据索引结果进行直方图匹配
以上实现代码: https:// github.com/FancyXun/CBI R/tree/master/CBIR_master
除了BOW,还有FV (Fisher Vector)、VLAD等编码算法,感兴趣的可以参考
https:// blog.csdn.net/wzmsltw/a rticle/details/52040010
https:// blog.csdn.net/LiGuang92 3/article/details/85416407
深度学习图像检索
未完待续
欢迎关注微信公众号:小径分岔的庄园
