


一个简单的Julia教程(一)


没有银弹,Julia的特性更多不会有Python好学(你看我写的这个教程的长度就知道了)。但是不用担心,上手是非常容易的。之前因为准备用户见面会(Julia User Meet Up)准备了一个教程,这个教程很大一部分来自于
但是因为不是所有的依赖都支持了1.0,所以这个教程会在下月更新一次。这里仅仅是介绍一些基本语法,帮助大家快速上手。这个教程以及集智俱乐部的视频
都可以 任意转载和修改 。不用联系我。但是希望注明出处,也希望可以帮忙宣传一下中文社区(当然这也并不是强制的)。
先列一些资料:
知乎上的话Julia有很多专栏,这个专栏更新的比较勤可以看看,也欢迎大家给这个专栏投稿:
然后书的话,我有意愿之后等中文社区人多一些组织一个开源图书的项目,但是这个可能最近还实现不了,一个是我精力有限,第二是人手不足。我自己的专栏Half Integer是当blog用的,因为我也使用很多别的语言和技术,不会单独分享Julia的内容,此外我也更倾向于写一些更干的东西。
然后如果你英文可以的话,有很多很棒的英文资料还有课程,我推荐你到这里看看:
有问题去哪里问
我首先推荐的是中文和英文的discourse论坛,它们的链接也都可以在官网找到,地址分别如下:
中文论坛:
英文论坛(这个人比较多):
然后你可以加Julia的其他社区:
也甚至可以直接去GitHub提交issue,整个Julia语言的开发都是在GitHub上的:
然后你也可以在知乎上提问,知乎上也有很多Julia的深度用户(虽然还很少)。
最后你也可以加我们中文社区的QQ群,但是这是最不推荐的,因为QQ没有代码高亮,也不能像slack一样支持各种方便技术讨论的特性。一般QQ主要用于讨论文档翻译工作的一些问题和社区建设。对于比较紧急的问题希望你可以在discourse(中英文皆可)上发了帖子之后把链接发到QQ群里来。
中文论坛的访问问题
中文论坛目前由于域名备案还没有完成(将会暂时挂靠在集智俱乐部名下)也还没有配置CDN,将会从香港跳转,可能第一次访问速度较慢,之后就好了,这是正常的我们也在慢慢解决这个问题。
Julia官方团队也在寻找怎么加速国内访问官网 julialang.org 的问题,我们日后也会考虑直接使用 julialang.org 。包括在境内维护镜像下载等。但是因为目前真的非常缺乏人手,也希望大家可以参与到社区建设里来。
关于中文社区
中文社区是受到Julia开发团队支持的众多本地化组织之一,非盈利是基本准则。值得自豪的是,在Julia只有0.3的时候在24个贡献者的努力下,就有了0.3的中文文档。1.0的中文文档也正在进行中,我们也利用Julia的文档系统尝试支持doc string。早期的成员里有Jiahao Chen,Yichao Yu,i2300等Julia团队的成员。
GitHub地址:JuliaCN
网址: juliacn.org / juliacn.com / juliacn.ac.cn
论坛地址: discourse.juliacn.com
JuliaCN目前暂时不接受任何个人捐赠(因为这可能并不合法),但是如果你愿意资助Julia语言的发展,可以通过官网的捐赠按钮进行捐赠官网的地址在这里: julialang.org 但是也希望 对Julia语言感兴趣的公司和机构能够帮助这样一个真正开源的,由社区成员自发组织起来的组织成长起来,虽然发起人已经不知道是谁了(并不是我),但是目前具体合作事宜都可以联系我或者在GitHub/discourse上发issue和帖子 。也非常希望有更多的机构可以赞助我们的(甚至是接下来的)活动和服务器等开支。如果有Julia的招聘岗位也欢迎来社区做广告。
写在前面
这两天的媒体报道可能让一些人有了恐慌,但是我现在有一个诚恳的建议就是如果你完全没有编程基础,时间也不多的话(时间多了不是想学啥学啥),我建议你先学一下Python,这并不冲突,因为Julia的语法本书和Python很像,1.0之后也专门增加了一些feature帮助你更好地从Python转向Julia。Julia刚刚有了第一个长期支持版本,这还不意味着这个语言已经 完全成熟 ,我想此时的Julia更像是彼时的Python 2.0,还有很长一段路要走,但是已经非常的有前景。
那么什么人我会建议学习Julia呢?或者Julia在什么场景下也许能够有优势呢?我个人的体验是以下这里一类:
- 之前使用Python但是因为性能问题,经常需要使用numba/Cython/C API/ctypes/etc.等方式进行优化的人。Julia或许能够帮助你解决两语言问题,并且获得可读性更好,更容易维护的代码。
- 之前使用MATLAB,但是被一些付费功能困扰的用户(MATLAB 2018也是不错的,但是要支持正版哈)
- 之前使用Fortran和R的用户,强烈建议使用Julia(可以结合着用也,FFI是很不错的)
- 之前使用Sage/Octave的用户,不妨尝试一下这个新玩意儿
- 之前使用Mathematica但是想开始做一些数值的用户,Mathematica不是不能做数值,也可以调用C/C++但是Julia不妨是相比其它工具更平滑的选择。
如果你之前的工作仅仅使用Python就足以胜任, 那么不必着急,也不必恐慌 ,不妨在感兴趣的时候试试这个新东西,但是也完全可以等到Julia被大规模使用的时候再跟进。实际上从一开始像MXNet这样的深度学习框架就官方支持了,这些框架的Python用户转移过来也并不是什么难事,但是如果你本来就不担心自己程序的性能(很多时候这并不是一个大问题),那么其实不会体会到什么明显的不同和优势。但是这样说也并不完全正确,Julia语言的优势不仅仅在其性能,也在其语言本身的设计。
此外,也要再三声明,虽然Julia可以写出高性能的代码,但是写出高性能的代码这件事情本身就很困难。虽然写起来像Python,运行速度像C是我们的梦想,但是在现在这个阶段, 并不是随便写一段Julia代码就真的能达到C的。Julia只是给你提供了充分优化的空间,和(达到高性能代码的)相对容易的编程体验。
下载和安装Julia
Julia目前因为官网的服务器只有AWS s3(他们也很穷)。所以国内的一些地区下载速度很慢:
大家可以试一试,然后也可以去Julia Computing公司提供的Julia全家桶(你可以把它理解为Julia版本的Anaconda),最左边的JuliaPro是免费的:
之前浙大的LUG搭建了一个镜像,但是维护的同学最近有一些忙,所以目前还没有更新到1.0。但是其实你如果无法从以上途径下载,那么从境内的源里下载Julia 0.6也其实并不影响你先熟悉一些基本语法(这是这个教程的主要目的),境内的源的下载地址在这里:
我们也会尽快更新。
然后还有一个叫做Julia Box的云服务很方便可以使用,里面有很多教程,都是jupyter notebook,打开即用,全部都是在线的不用安装。但是唯一的缺点就是国内可能不一定能够正常访问到。
使用什么编辑器
Julia语言的社区不够大,此外由于不是像rust这样的静态编译语言,也不是像CPython这样的解释型编译器,在启动的时候有比较明显的overhead,这个问题一直在优化(REPL的启动时间已经从曾经的1.0s到了现在的0.2s,依然和IPython这样的有明显差距),有PL的朋友私下和我说是LLVM的JIT不是那么好(像nodejs的V8这个问题就不是很明显)
所以在这个阶段选择一个合适的开发工具是非常必要的。目前支持最好,bug最少的是Atom上的Juno插件,如果你下载Julia Pro那么会自带这个编辑器。如果你想选择手动安装,那么可以在这里下载Atom:
然后安装方法在这里有介绍:
或者我也推荐你安装IJulia之后,使用jupyter notebook和jupyter lab进行开发。
其它的平台也有支持,例如Jetbrain的各个IDE都可以使用由 @考古学家千里冰封 等开发的插件。VS code也有Julia插件,以及Vim也是有支持的。但是他们都还没有支持逐行执行和单独执行某一块代码的功能,这对于本身被设计得很像Mathematica的Julia来说没有执行一个cell的支持开发起来会时常被JIT的预热时间所困扰。
然后为了克服JIT的预热,避免重复启动编译器。如果你不重新定义(re-define)类型的话,可以试试 Revise.jl :
这是一个用于热加载Julia代码的工具,1.0已经支持方法(method)的删除了。所以也能够方便你的开发。
其实和Python一样,在我日常使用中,作为动态语言,以及因为语法本身适合分块执行,我其实很少会用到断点和专门的debugger,此外虽然有相关的包,在1.0的编译器里也为未来加入debugger提供了相关功能,但是目前还没有完善,你也许可以试试(但是我暂时不推荐):
我怎么知道我要用什么包
Julia有一个由社区维护的网站用来帮助你从1900多个包里找出符合你需求的Julia包:
一般来说用比较新的,star比较多的包会好一些。然后如果你觉得某个包不错,也请在GitHub上给一个star。
基本操作
当你下载好了Julia之后,不论是Julia Pro还是单独的Julia编译器,你都可以先打开一个REPL(交互式编程环境),类似于IPython之于Python,Julia的REPL支持了基本的代码高亮,文档查看等功能。但是Julia的REPL更强大(这件事稍后再说)。
Windows/Mac用户:
双击Julia的三色图标,就能打开REPL。在Atom里面的话在左上角有Julia一栏,点击里面的open terminal即可。
Linux用户:
下载好以后去找到bin文件夹,然后把它加入你的 PATH 环境变量里去,以后就可以在命令行里直接通过 `julia` 命令启动REPL。
树莓派用户和超算用户:
我相信你们是专业的,请阅读官网的教程吧。注意超算用户不用要求管理员安装也可以安装到自己的用户目录下的,设置好环境变量即可。然后有一些超算(比如中国科学技术大学的超算中心)Julia编译器是很早就装好的,但是可能使用module load加载。
运行Julia的程序总的来说可以有三种方式(其实原理上它们都基本是等价的)
- 执行一个Julia脚本,和其它Julia语言一样,你可以用如下命令执行Julia脚本,一般来说Julia脚本都以 `.jl` 作为扩展名。
julia script.jl这个执行出来是没有报错高亮的,需要颜色请用以下命令执行
julia --color=yes script.jl2. 如果直接启动Julia会进入到REPL里去
julia你会看到
_
_ _ _(_)_ | Documentation: https://docs.julialang.org
(_) | (_) (_) |
_ _ _| |_ __ _ | Type "?" for help, "]?" for Pkg help.
| | | | | | |/ _` | |
| | |_| | | | (_| | | Version 1.0.0 (2018-08-08)
_/ |\__'_|_|_|\__'_| |
|__/ |
julia>也可以在这里运行Julia命令。
在REPL里面可以直接查文档,按 ?就会跳到help模式,在0.7之后(包括1.0),按 ] 就会进入pkg模式,在这个模式下按 ?就会显示相关文档
(v1.0) pkg> ?
Welcome to the Pkg REPL-mode. To return to the julia> prompt, either press backspace
when the input line is empty or press Ctrl+C.
Synopsis
pkg> [--env=...] cmd [opts] [args]
Multiple commands can be given on the same line by interleaving a ; between the
commands.
Environment
The --env meta option determines which project environment to manipulate. By default,
this looks for a git repo in the parents directories of the current working directory,
and if it finds one, it uses that as an environment. Otherwise, it uses a named
environment (typically found in ~/.julia/environments) looking for environments named
v$(VERSION.major).$(VERSION.minor).$(VERSION.patch),
v$(VERSION.major).$(VERSION.minor), v$(VERSION.major) or default in order.
Commands
What action you want the package manager to take:
help: show this message
status: summarize contents of and changes to environment
add: add packages to project
develop: clone the full package repo locally for development
rm: remove packages from project or manifest
up: update packages in manifest
test: run tests for packages
build: run the build script for packages
pin: pins the version of packages
free: undoes a pin, develop, or stops tracking a repo.
instantiate: downloads all the dependencies for the project
resolve: resolves to update the manifest from changes in dependencies of developed
packages
generate: generate files for a new project
preview: previews a subsequent command without affecting the current state
precompile: precompile all the project dependencies
gc: garbage collect packages not used for a significant time
activate: set the primary environment the package manager manipulates查看具体某个命令的文档可以
(v1.0) pkg> ?add
add pkg[=uuid] [@version] [#rev] ...
Add package pkg to the current project file. If pkg could refer to multiple different
packages, specifying uuid allows you to disambiguate. @version optionally allows
specifying which versions of packages. Versions may be specified by @1, @1.2, @1.2.3,
allowing any version with a prefix that matches, or ranges thereof, such as
@1.2-3.4.5. A git-revision can be specified by #branch or #commit.
If a local path is used as an argument to add, the path needs to be a git repository.
The project will then track that git repository just like if it is was tracking a
remote repository online.
Examples
pkg> add Example
pkg> add Example@0.5
pkg> add Example#master
pkg> add Example#c37b675
pkg> add https://github.com/JuliaLang/Example.jl#master
pkg> add git@github.com:JuliaLang/Example.jl.git
pkg> add Example=7876af07-990d-54b4-ab0e-23690620f79a安装包在0.7之后都用pkg模式来安装,因为这个更方便,但是和0.6一样,如果你想使用代码来安装也是可以的,但是在0.7之后需要加载 Pkg 模块(0.6不用)
using Pkg然后安装你想要的包
Pkg.add("Example")Julia的REPL扩展性很强,比较有名的比如OhMyREPL


甚至还可以在Julia的REPL里把C++当成动态语言来写,按 < 键进入C++模式(Julia的C++ FFI:Cxx.jl,暂时还没更新到1.0,需要0.6)
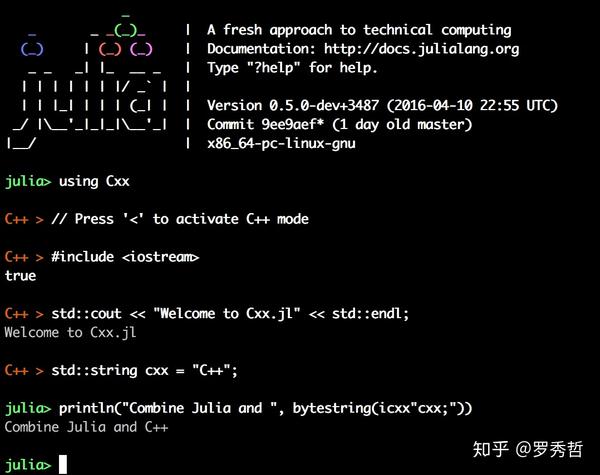
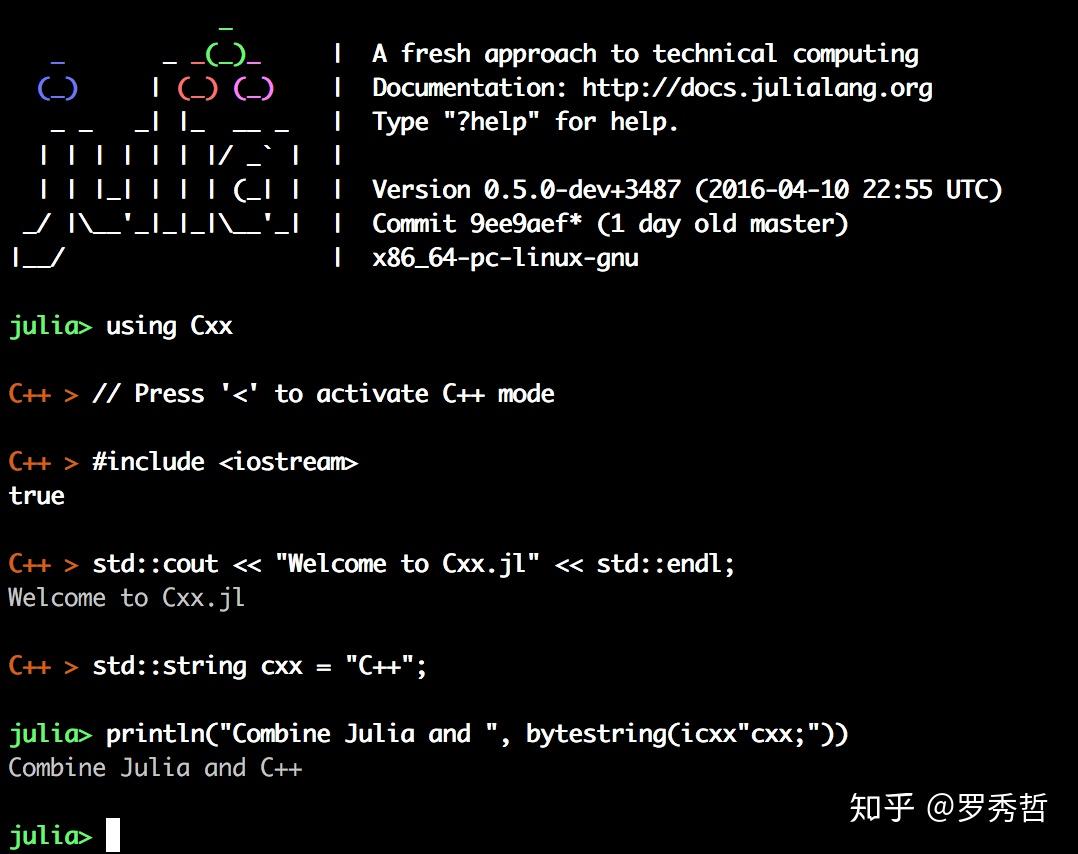
3. 第三种方式就是在Atom这样支持cell的编辑器里(notebook也是类似的),在Atom中在某一行按 shift+enter 会单独执行这一行,结果会打印在这一行的后面。如果有多行的结果你可以用鼠标点击以下,就会展开。如果你选中了很多行,那么就会执行你选中的部分,结果显示在选中的部分最后。
notebook里面的使用方法也是shift + enter和Python等其它语言类似。
下面的部分你可以在以上三种方式里的任意一种里执行。
本教程只是帮助熟悉语法,想要掌握Julia还请认真阅读手册(中文手册还在翻译中):
基本语法
正如所有的经典教程一样,我们先来学习怎么写hello world:
在Julia里面写hello world可以这样写
> println("Hello World")注意 在Julia里为了保证声明可以帮助你区分类型,String是需要双引号的,字符使用单引号。
Julia的字符串继承了Perl的字符串差值,正则表达式等,Stefan的评价是他觉得Perl的字符串处理是最漂亮的,于是就抄了过来。
> name = "Roger"
> println("Hello $name")这里name是一个变量,Julia和Python一样,不需要声明变量,因为所有的变量都只是给值绑定了一个名字而已。然后对于变量插入,可以直接使用 $ 符号。
这将打印出
Hello Roger当然对于比较长的表达式你也可以使用括号
> println("1 + 1 = $(1 + 1)")这将打印出
1 + 1 = 2
我们上面提到了怎么绑定一个变量名:
> x = "Roger"Julia的变量名除了ASCII字符以外,还可以使用包括但不限于UTF-8的unicode,比如甚至是中文
> 你好 = "Hello!"还可以是Emoji,输入 `\:smile` 然后再按 `tab`
> = "smile"别忘了这是一个为科学家们打造的语言,还可以利用LaTeX来输入特别的数学符号,在notebook或者REPL里输入 `\` + `epsilon` 按 `tab` 键
> ϵ = 2.2Julia还利用了LLVM的一些常数(无限精度):
> π
π = 3.1415926535897...
函数声明
我们写一个非常简单的求和函数,它会对一个向量 A 求和
function mysum(A)
s = 0.0 # s = zero(eltype(A))
for a in A
s += a
end函数声明使用 function 关键字开头搭配 end 关键字,所有的Julia函数都会返回函数声明的最后一行,这其实是一种函数式语言的特性。return关键字往往只用于在运行过程中返回。也许一开始你对这个 end 不是很喜欢,或许会问为什么不像Python一样呢?为什么不用 {} 呢?别着急后面在元编程的部分告诉你 end 的好处。
然后 for 循环也是一样的,使用for关键字,然后可以搭配 in 来遍历一个数组(是不是几乎和Python一样?),但是别忘记了所有的代码块都最后要写一个end
当然 in 关键字可以单独使用,用于判断某个集合类(collection,例如一个数组)里面是否包含某个元素
> 1 in [1, 2, 3]
true
注释方式和Python一样,也使用 #,而多行注释使用
#=
=#但是除此之外,Julia是有类型的,也可以标注类型(而不是声明),而对于短小的函数声明也可以更加的贴近数学语言。例如我们想要判断某个数字是奇数还是偶数
is_even(x::Int) = x % 2 == 0Julia使用 :: 来标注类型 (学过Python3的朋友可能知道Python也有类似的类型标注但是是:)
这个时候如果输入了,例如浮点数那么就会报错
> is_even(2.0)
MethodError: no method matching is_even(::Float64)
Closest candidates are:
is_even(!Matched::Int64) at In[3]:1
Stacktrace:
[1] top-level scope at none:0然后多写文档是个好习惯,让我们给is_even和mysum加上文档,对于已经定义过的东西,可以直接这样加文档
"""
is_even(x::Int) -> Bool
判断一个整数 `x` 是否是偶数
is_even
mysum(A) -> Number
对 `A` 求和。
mysum但是也可以在声明的时候加
"""
is_even(x::Int) -> Bool
判断一个整数 `x` 是否是偶数
is_even(x::Int) = x % 2 == 0
mysum(A) -> Number
对 `A` 求和。
function mysum(A)
s = 0.0 # s = zero(eltype(A))
for a in A
s += a
endJulia的文档系统使用 Documenter.jl ,所有文档都用markdown编写,这种markdown是Julia flavor的,具体细则非常简单还请参见:
Julia里的分支判断也很简单,和很多语言都非常像
if cond1
# blabla
elseif cond2
# blabla
# blabla
end多维数组
Julia也有原生支持的多维数组(而不是List)甚至有非常完善的Array Interface。这表现为Julia拥有大量的针对不同情况设计的数组类型,例如:可共享数组,供并行计算使用;静态数组,适合给小的数组加速;稀疏数组,实现上目前只有稀疏矩阵;分布式数组,用于分布式计算;CUDA数组CuArray,用于在N卡上计算,等等,就不一一列举了它们之中除了自带的数组(类似于numpy的多维数组)以外都在外部支持的包里,而所有的这些数组都适用了同样的Interface。他们在使用体验上几乎没有差别。
比如可以产生一个随机数组
> rand(10)这将得到一个向量,里面有10个元素,每个元素的类型是默认的Float64类型。
产生一个随机矩阵(跟随你的直觉就好)
> rand(10, 20)产生一个三维的张量
> rand(10, 20, 30)...
那么如果要声明Int类型的数组呢?
> rand(Int, 10)
> rand(Int, 10, 20)
> rand(Int, 10, 20, 30)那么如何声明初始化为0的数组呢?现在告诉你函数名称是 zeros 和MATLAB以及numpy完全一样,看了上面 rand 的用法,猜猜这个怎么用?
那么如果我需要更复杂的构造呢?Python的List有一个很著名的List Comprehension方法,Julia也有。
> [i for I in 1:10]这将获得
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]和Python的List Comprehension是不是一样?但是等等,还不止如此,Julia对多维数组的支持是非常好的,Comprehension对于多维数组也可以用,用逗号分隔即可
[(i, j) for i in 1:5, j in 1:6]
5×6 Array{Tuple{Int64,Int64},2}:
(1, 1) (1, 2) (1, 3) (1, 4) (1, 5) (1, 6)
(2, 1) (2, 2) (2, 3) (2, 4) (2, 5) (2, 6)
(3, 1) (3, 2) (3, 3) (3, 4) (3, 5) (3, 6)
(4, 1) (4, 2) (4, 3) (4, 4) (4, 5) (4, 6)
(5, 1) (5, 2) (5, 3) (5, 4) (5, 5) (5, 6)这将得到一个由Tuple构成的矩阵,那你已经看到了Julia里面元组使用括号来声明。而除了这种元组还有一种称为命名元组(NamedTuple)的东西,这是1.0的新特性
info = (name="Roger", age="0", wechat="不告诉你")你可以直接通过 . 算符来访问
> info.name
"Roger"
> info.age
> info.wechat
"不告诉你"广播(broadcast)
多维数组的广播是一个很重要的特性,也是Julia多维数组的标准接口(Interface)任何Julia的数组都可以使用广播。Julia从MATLAB学来了 . 算符。任何被点算符作用的函数和其它算符都可以被广播。例如
> sin.(A)将广播sin函数到A的每一个元素。什么是广播简单来说就是将一个函数作用在多维数组,元组,标量的每一个元素上去。这有点像是函数式编程里map的概念,但是不完全一样。
广播运算对任何函数都是支持的,比如
> foo.(A, B, c)这里A和B时两个数组,c是一个标量那么foo将会以 foo(a, b, c) 的形式作用在每一个A,B的元素a, b 上。
类型 —— 一切都是对象
和很多其它的面向对象语言一样,Julia里所有的东西都是对象,或者说是某个类型的实例,但非 `class` 的实例,Julia没有 `class`,但是有更轻量级的类型。
定义一个复数类型 复数是很多数值计算和数据分析算法都会用到的类型,然而一般的处理器上并不是自带复数类型的,我们往往使用两倍精度的浮点数来模拟一个复数,例如在 `C` 语言里,双精度的复数可以写作:
double _Complex a;或者在 `C++` 中,双精度的复数可以写作:
std::complex<double> a;在 `Python` 里,没有显示类型,但是我们可以使用 `j`:
In [1]: 1 + 1.j
Out[1]: (1+1j)Julia里有自带的 Complex类型,和Python类似,用 im 表示虚数单位
1 + 1im
Complex是纯Julia实现的数值类型。所以我们用这个作为例子来看看怎么定义一个类型
struct MyComplex
real::Float64
imag::Float64
# 一个复数就是 MyComplex 类型的一个实例,也就是一种对象
a = MyComplex(1.0, 2.0)
而实际上和
C
/
C++
一样,Julia的复数类型也是纯Julia实现的,我们这里会简单地实现一个复数类型
MyComplex
。Julia的类型使用
struct
关键字,然后用
end
表示这一段表达式的结束。每个Julia类型有一个默认的构造函数,这个构造函数的变量即为类型声明的成员。
但是仅仅声明了类型还远远不够,我们还需要对复数定义复数运算,方便起见我们这里仅重载
*
算符:
(a + b \cdot i) (c + d \cdot i) = (ac - bd) + (ad + bc)i
首先我们需要将要重载的东西从
Base
模块中拿出来(而不是自己声明一个新的,为什么?留给大家之后思考,这对你理解什么是Julia的多重派发很有帮助),在Julia里,
运算符
只是一种特殊的函数,并不会被特别对待
import Base: *
*(a::MyComplex, b::MyComplex) = MyComplex(a.real * b.real - a.imag * b.imag, a.real * b.imag + a.imag * b.real)然后试试?
b = MyComplex(1.0, 3.0)
a * b
现在输出不是很好看,我们重载一下
show
方法把默认打印出来的字符串修改一下,这里字符串里的
$
是字符串插入,可以将一个Julia表达式的输出转换为字符串(
String
类型)然后插入到字符串里。
import Base: show
show(io::IO, ::MIME"text/plain", x::MyComplex) = print(io, "$(x.real) + $(x.imag)im")
任意精度的复数类型
我们已经有了一个简单的复数类型,但是实际上真正在用的时候,我们可能会需要不同精度的复数类型,例如使用
32
位浮点精度的复数类型。为了能够使用不同的复数类型,我们需要使用参数类型,而复数的实部和虚部都是实数,我们还需要限制其类型范围
struct MyComplex2{T <: Real}
real::T
imag::T
end这里Real是自带的抽象类型,我们之后会讲什么是抽象类型。而T则是一个参数。参数类型也有默认的构造函数。
MyComplex2{Float32}(1.0f0, 2.0f0)
但是实际上你还可以定义一些自己的构造函数,在 Julia 里因为是没有
class
的,除了
构造函数
以外的方法都不能写在类型声明内部。而一旦你在类型声明中声明了一个自己的构造函数,
默认的构造将被覆盖
。比如试试下面这个例子
struct MyComplex3{T <: Real}
real::T
imag::T
MyComplex3(real::T) where {T <: Real} = new{T}(real, 0)
MyComplex3(1.0)
什么时候用内部构造函数,什么时候用外部构造函数?
内部构造函数往往是为了在生成这个实例前做一些预处理(例如判断输入变量是否符合要求等)更详细的例子请参见文档
多重派发和Julia的面向对象
Julia语言是没有
class
的,但这并不意味着 Julia 无法面向对象,Julia对象的方法(method)通过
多重派发
和
类型树
进行分配,而不依赖于
class
这种结构。下面这一部分不会影响你使用Julia的多重派发特性,因为它非常的直觉化,但是如果你可以通过下面Python和C++的例子了解到到底什么是多重派发和单重派发,那么也将是非常有益的。
---------------------------------------------
想了解什么是多重派发,我们要先从
单重派发(single dispatch)
说起,我再用
Python
举个例子,Python 3.4有一个的提案(
PEP 443
)里有一个对单重派发通用函数的提案:
from functools import singledispatch
@singledispatch
def fun(arg, verbose=Falase):
print(arg)
@fun.register(int)
def _(arg, verbose=False):
print(arg)所谓单重派发就是只能按照函数参数的一个类型进行派发方法,从而实现多态。
顾名思义,多重派发就是根据所有参数的类型进行派发方法。C++的函数重载其实就是一种静态的多重派发(static multiple dispatch)。但是到了动态类型就不行了,比如下面这个来自StackOverflow的例子
#include <iostream>
struct A {};
struct B : public A {};
class Foo {
public:
virtual void wooo(A *a, A *b) { std::cout << "A/A" << std::endl; };
virtual void wooo(A *a, B *b) { std::cout << "A/B" << std::endl; };
void CallMyFn(Foo *p, A *arg1, A *arg2) {
p->wooo(arg1, arg2);
int main(int argc, char const *argv[]) {
Foo *f = new Foo();
A *a = new A(); B *b = new B();
CallMyFn(f, a, b);
return 0;
}
运行上面的
C++
代码将会得到
A/A而我们预期的是
A/B
这是因为
C++
只支持 Single Dispatch (多重派发在提案中:
Report on language support for Multi-Methods and Open-Methods for C++
),对于动态类型,编译器只能通过
class
名称决定调用的方法,当需要根据参数等信息决定方法的时候就无能为力了。注意,多重派发是一个动态类型的特性,这里
A
,
B
都是做成了动态类型,于函数重载不同,一些类似于多重派发在
C++
中实际上是函数重载,出现歧义(ambiguous)是由于
C++
的隐式类型转换。
---------------------------------------------
顾名思义,就是会根据所有的参数来进行派发。例如让我们在Julia里重新实现
C++
里的例子,注意由于 Julia 没有继承,我们在这里用抽象类型代替。Julia会匹配参数类型最符合的方法,然后调用。在Julia里,由于Julia本身是动态语言,函数的重载(overload)与多重派发是一个意思,但是实际上Julia的派发会发生在运行时和编译时,而这在很少的情况下有可能影响性能。
abstract type TypeA end
struct TypeB <: TypeA end
struct TypeC <: TypeA end
wooo(a1::TypeA, a2::TypeA) = println("A/A")
wooo(a::TypeA, b::TypeB) = println("A/B")
callme(a1::TypeA, a2::TypeA) = wooo(a1, a2)
b = TypeB(); c = TypeC();
callme(c, b)在Julia里,上面的 wooo称为一个通用函数(generic function)而对某些类型的具体实现,例如
wooo(a1::TypeA, a2::TypeA) = println("A/A")称为 method。
下面来说说Julia的类型系统
类型系统
Julia的类型主要分为抽象类型(Abstract Type)和实体类型(Concrete Type),实体类型主要分为可变类型(Mutable Type)和不可变类型(Immutable Type)
abstract type AbstractType end
struct ImmutableType <: AbstractType
mutable struct MutableType <: AbstractType
end抽象类型使用 abstract type 关键字 匹配 end声明。默认的合成类型都是不可变类型,使用 struct 搭配 end 声明。而可变类型在 struct 前面增加 mutable 关键字即可。某个实体类型(concrete type)是另外一个抽象类型(abstract type)或者抽象类型是另外一个抽象类型的 子类 ,这样的关系使用 <: 来声明。
一个抽象类型的所有子类型会构成一颗树,其中实体类型一定在树的叶子结点
下面这个
view_tree
函数会对一颗类型树进行深度优先遍历(DFS)
using InteractiveUtils # 0.7 之后需要调用这个标准库
function view_tree(T, depth=0)
println(" "^depth, T)
for each in subtypes(T)
view_tree(each, depth+1)
view_tree(AbstractType)运行会得到AbstractType作为父节点的类型树
AbstractType
ImmutableType
MutableType再看一个复杂一些的例子(自己运行一下试试):
abstract type AbstractAnimal end
abstract type AbstractBird <: AbstractAnimal end
abstract type AbstractDog <: AbstractAnimal end
abstract type AbstractCat <: AbstractAnimal end
struct Sparrow <: AbstractBird end
struct Kitty <: AbstractCat end
struct Snoope <: AbstractDog end
view_tree(AbstractAnimal)
而Julia在分发一个函数的方法的时候,会尽可能匹配最具体的类型,也就是尽可能匹配这颗树的叶子结点。思考一下下面这段代码的运行结果
combine(a::AbstractAnimal, b::AbstractAnimal, c::AbstractAnimal) = "three animals get together!" # method 1
combine(a::Sparrow, b::AbstractCat, c::AbstractAnimal) = "a sparrow, a cat and some animal" # method 2
combine(Sparrow(), Kitty(), Sparrow()) # 这个会匹配方法2
类型在 Julia 里是非常廉价的,利用多重派发和廉价的类型,我们可以针对数学对象实现更详细的优化,例如对于满足不同性质的矩阵,我们有对它们之间互相乘积的优化方法,我们可以将部分操作作为懒惰求值(Lazy Evaluation)加入运算中,然后再为满足不同性质的矩阵派发精细的优化方法:
- 对满足 ATA=I 的矩阵,如果遇到了自己的转置可以什么都不算
- 对满足上三角的矩阵(或者下三角矩阵),在一些矩阵分解等操作的时候可以调用更快的数值方法
- 而对于单位矩阵,我们总可以什么都不算
实际上Julia在标准库里已经这么做了 (虽然实际上依然还有更多的特殊矩阵,你也许可以在 JuliaArrays 里找到你需要的矩阵类型),不同类型的矩阵会被派发到不同类型的方法上去。
试试对Julia自带的抽象类型 AbstractMatrix 运行这个代码
view_tree(AbstractMatrix)总结一下
Julia有这样的特点: 廉价的类型 和 多重派发 + 类型树 的结构,我们可以 继承类型的行为(behavior) 而不能 继承类型的成员 ,而多重派发让所有Julia类型很自然地变成了鸭子类型(Duck Type),我们只要定义好不同的 接口 / interface 就足以定义类型的行为。
实际上由于严格保持了树的结构,Julia也不允许多重继承,也不存在混入(mixin)这样的设计模式,这避免了 钻石继承的问题 。
需要说明的是,以上仅仅是Julia的特点,它带来了一些好处,也同时带来了一些缺点。限于篇幅暂且不表。
问题:想想这几种
rand
的接口,例如
rand(1:10)
,
rand(Bool)
,
rand(Bool, 2, 2)
等是怎么实现的?
在Julia里调用Python
在当下,如果有人说放弃 Python 那一定是一个很愚蠢的决定,正如开头所说,Python 和 Julia 各自有其优缺点,而我们在迁移到 Julia 之后依然可以调用我们的一些历史依赖,并且也依然可以将新写的更快更简单的代码作为 Python 的包提供给 Python 社区。所以你可以选择
- 用Julia给Python加速
- 整体迁移到Julia上来,但是调用自己的历史代码。
这主要需要依赖于两个包:
PyCall.jl
和
pyjulia
。这一部分我们主要讲
PyCall.jl
目前PyCall还没有更新到1.0但是在0.6和0.7都是没有问题的。如果你没有安装
PyCall
模块,请使用Julia的包管理器安装
PyCall
,如果你的环境里没有安装
python
或者不在标准路径中,那么Julia将会下载一个 miniconda 来安装 python 环境。如果你想使用你已经安装的
python
,请在Julia的环境变量
ENV
中设置
python
路径:
julia> ENV["PYTHON"] = "... python 路径 ..."