写在前面:
最近自学了一下python爬虫,用来简单爬取论坛的数据,只学到了一些皮毛,毕竟还是要以实用为主嘛…学会了下面的代码,就可以爬取一些网站的数据了,这里我使用xpath库进行爬取,问我为什么不用正则?因为我还不是很会用,哈哈。
1.pycharm开发工具
2.python3.8
3.xpath helper
4.有手就行
http://hongdou.gxnews.com.cn/viewforum-21.html
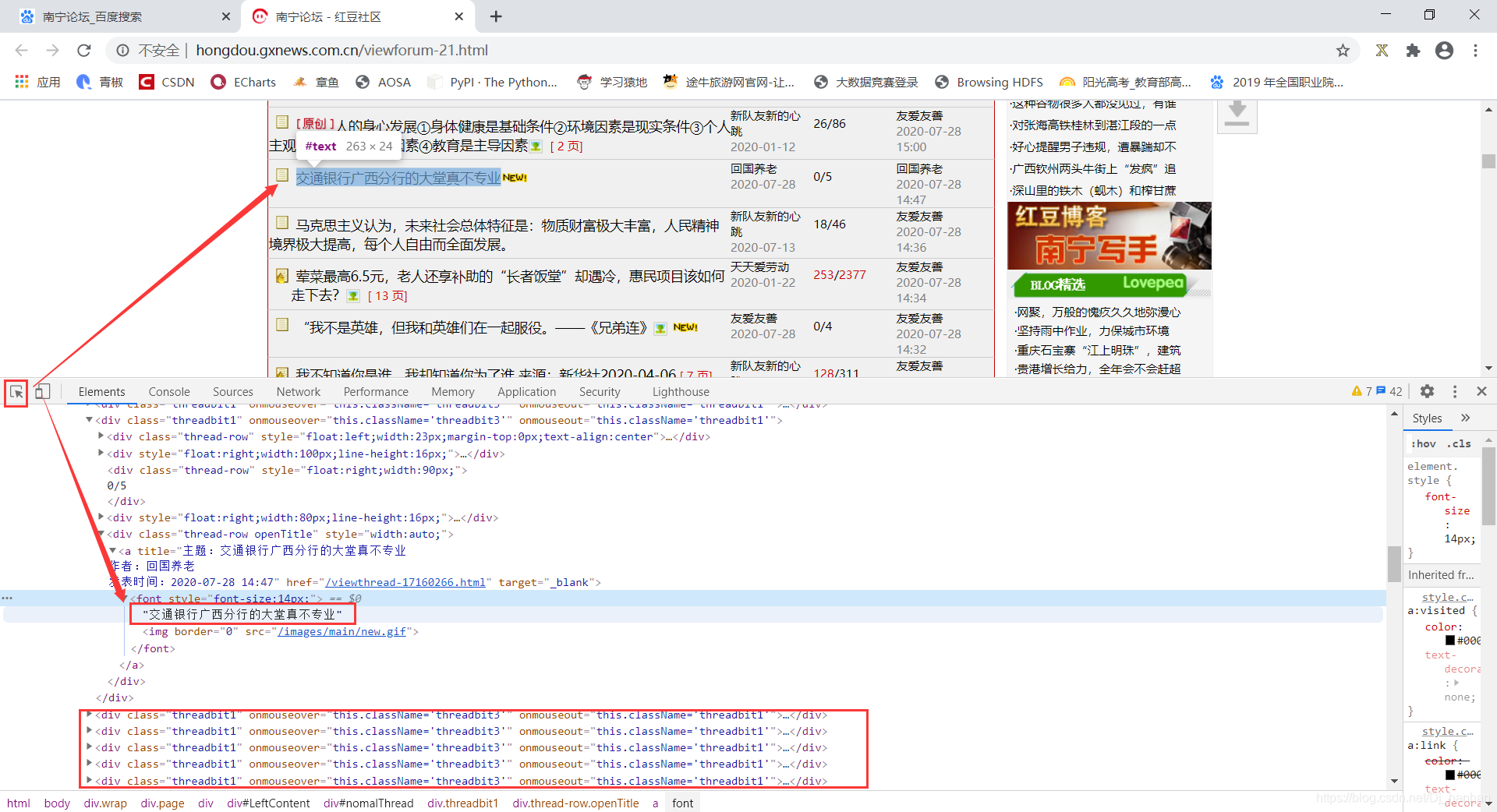
通过观察可以发现,我们想要数据都在【div class=“threadbit1”】里面

第一页是【http://hongdou.gxnews.com.cn/viewforum-21-1.html】
第二页是【http://hongdou.gxnews.com.cn/viewforum-21-2.html】
最后一页是【http://hongdou.gxnews.com.cn/viewforum-21-73.html】
从中我们可以找到翻页的规律,就是+1
import requests
import time
from lxml import etree
url='http://hongdou.gxnews.com.cn/viewforum-21-%d.html'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
if __name__ == '__main__':
fp = open('./hongdou.csv','w',encoding='utf-8')
for i in range(74):
s_url=url%(i+1)
res = requests.get(s_url,headers=headers)
res.encoding='gbk'
text = res.text
html = etree.HTML(text)
items = html.xpath('//div[@class="threadbit1"]')
for item in items:
title=item.xpath('.//div[@class="thread-row openTitle"]/a/font/text()'),
yeshu=item.xpath('.//span[@class="threadpages"]/text()'),
author=item.xpath('.//div[@style="float:right;width:80px;line-height:16px;"]/a[1]/text()'),
fa_time = item.xpath('.//div[@style="float:right;width:80px;line-height:16px;"]/a[2]/text()'),
lend_author=item.xpath('.//div[@style="float:right;width:100px;line-height:16px;"]/a[1]/text()'),
lend_time = item.xpath('.//div[@style="float:right;width:100px;line-height:16px;"]/a[2]/text()');
fp.write('%s\t%s\t%s\t%s\t%s\t%s\n'%(title,yeshu,author,fa_time,lend_author,lend_time))
print('第%d页爬取成功'%(i+1))
time.sleep(1)
fp.close()
- 在获取的url地址中使用%d占位符,为后面爬取多页数据做准备。
- print(res.status_code) 前期可以打印一下状态码,看请求成不成功。
time.sleep(1),一秒钟爬取一次,保守起见,不要给别人服务器造成太大压力,如果一直频繁请求你可能会被拉入黑名单。- 我发现这个网页的编码格式是
GBK,但是大部分的网站编码格式都是utf-8 fp = open('./hongdou.csv','w',encoding='utf-8') 想要保存成txt格式都可以咯,为什么这里编码是utf-8,这是反复测试的结果,不然保存会乱码,就是那么奇怪。s_url=url%(i+1)如果像是翻一页+20,括号里也可以写成(i*20),但是range里面就需要相应的改变了,比如 2X20=40,3X20=60…
使用xpath helper帮助我们更加精准的获取到想要的数据。当然,代码不是唯一的,你怎么开心怎么来,写着写着发现变黄了就说明你找到了,运行一下代码看找到想要的数据就得了呗。
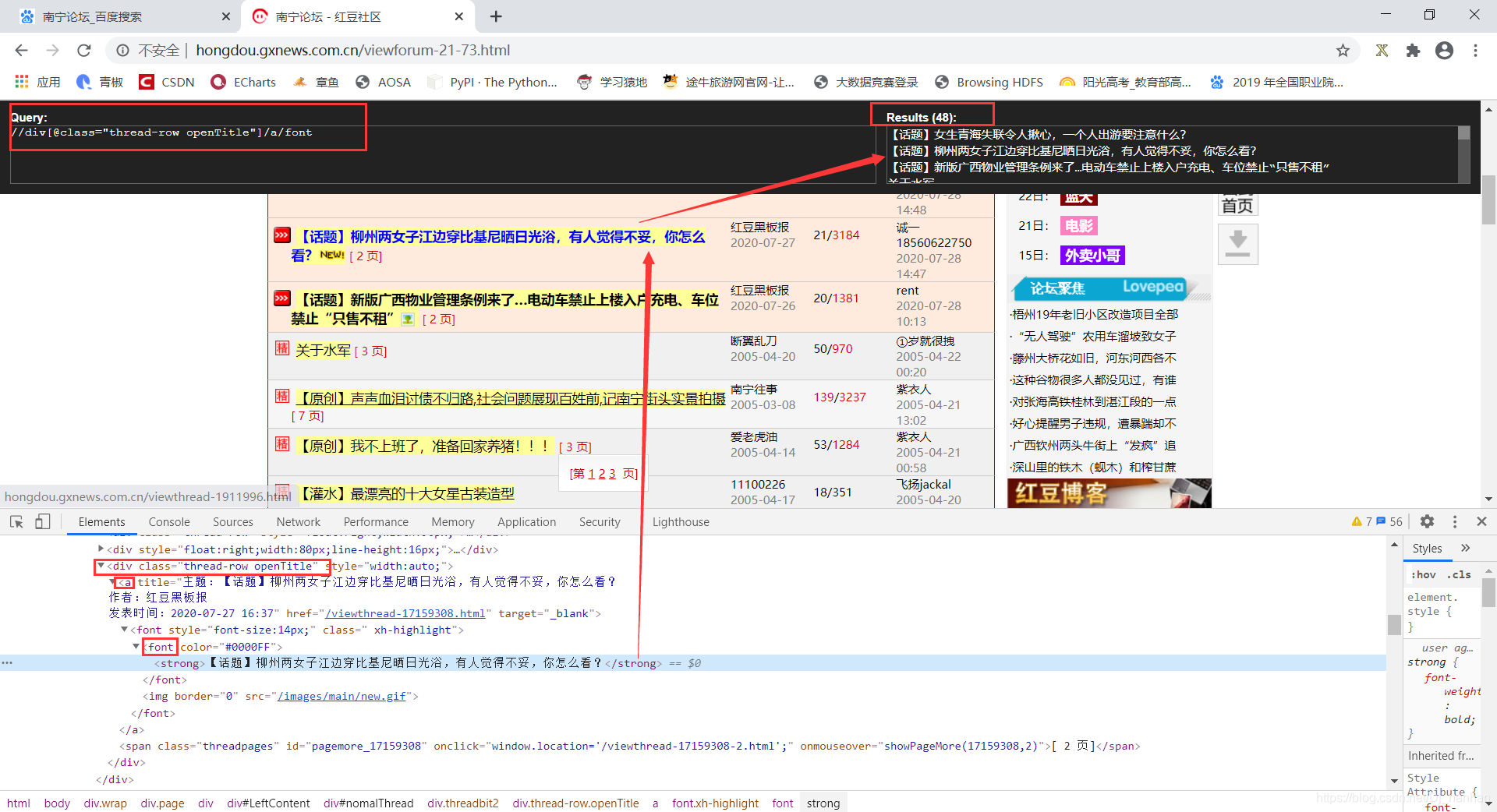
以获取标题为例:
title=item.xpath('.//div[@class="thread-row openTitle"]/a/font/text()'),
前面加个点代表当前路径下,后面加个/text(),不加就获取不到。如果增加下面的.strip()去除两边空格的方法,我有时候会报错,所以我干脆就不用了
title=item.xpath('.//div[@class="thread-row openTitle"]/a/font/text()')[0].strip(),
获取完了可以打印一下看对不对:
print(title);
要在谷歌浏览器里用,别的浏览器我没用过。
安装包在这:https://pan.baidu.com/s/1vAz-wIdsJ5EaX1hp37St4g提取码【8a2h】
解压安装包——浏览器中打开右上角三个点——选择更多工具——扩展程序——加载已解压的扩展程序
重启一下浏览器,发现右上角多了个X标就得了;在网页中按快捷键Ctrl+Shift+X就可以打开使用了
写在前面:最近自学了一下python爬虫,用来简单爬取论坛的数据,只学到了一些皮毛,毕竟还是要以实用为主嘛…学会了下面的代码,就可以爬取一些网站的数据了,这里我使用xpath库进行爬取,问我为什么不用正则?因为我还不是很会用,哈哈。1.环境准备1.pycharm开发工具2.python3.83.xpath helper4.有手就行2.分析需要爬取的网站http://hongdou.gxnews.com.cn/viewforum-21.html通过观察可以发现,我们想要数据都在【di.
爬虫之天涯论坛需求获取天涯论坛上某个关键字搜索出来的所有页面里面的每个帖子的楼主ID和回帖者的ID解决方法Python+正则表达式re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。str.find(str, beg=0, end=len(string))
如果包含子字符串返回开始的索引值,否则返回-1import requ
for car in car_list:
title = car.xpath(".//a[@class='carinfo_title']/text()")[0]
price = car.xpath(".//p[@class='carinfo_price']/text()")[0]
km = car.xpath(".//p[@class='carinfo_km']/text()")[0]
year = car.xpath(".//p[@class='carinfo_year']/text()")[0]
print(title, price, km, year)
这段代码会先发送一个 GET 请求获取汽车之家二手车页面的 HTML 内容,然后使用 lxml 解析器解析 HTML,并通过 XPath 表达式获取到每辆二手车的标题、价格、公里数和年份信息。最后,将这些信息打印出来。
需要注意的是,如果要获取更多的二手车信息,可以通过修改 URL 中的参数来实现。例如,将 URL 修改为 `https://www.che168.com/china/used/o1s2i7`,可以获取到所有价格在 2 万元以下、公里数在 7 万公里以下的二手车信息。

