

Pytorch深度学习:使用SRGAN进行图像降噪

前言
本人目前双非应用统计学本科大四,即将于23年6月毕业。这个课题完成于22年12月份,是向国外人工智能方向的教授套磁时教授给的,一个月时间里一大堆题目里面选几个做。后来23年1月份面了个试也就录取了,因为都是自己想出来的就打算写个文章记录一下,希望能作为深度学习新人们的一种拓展。
观前提示:本人代码水平低下,Python、Pytorch和深度学习相关知识都为自学,不喜勿喷。
摘要
在这篇文章里,我们使用COCO2014数据集训练了一个去除上采样层的SRGAN用以图像降噪。SRGAN是一个图像超分辨率模型 [1] 。最终,我们在CIFAR-10测试集上得到的原始图像与降噪后的高斯噪声图像之间的平均峰值信噪比(PSNR)和平均结构相似度(SSIM)分别为21.2315和0.9239。
1. 介绍
1.1 图像降噪
图像降噪是指减少数字图像中的噪声的过程。图像中的噪声的来源是相对复杂的,了解图像噪声的产生原因对进行图像降噪很有帮助。这是因为对于满足某些数学统计规律的噪声,如果我们知道噪声的统计特征,那么逆向去除它们就相对方便。此外,许多深度学习技术也被应用于图像去噪领域,深度学习模型通常依赖于数据,了解噪声的分布特征有利于制作数据集。
目前有很多不同的降噪方法,如基于滤波器的中值滤波器 [2] ,基于数学方法的马尔科夫随机场模型,以及基于深度学习的模型,如DnCNN [3] 、FFDnet [4] ,和CBDnet [5] 等。
1.2 SRGAN
卷积神经网络(CNN)在传统的单帧超分辨率图像重建上取得了非常好的效果,可以达到很高的峰值信噪比(PSNR)。其中大部分使用MSE作为损失函数,可以达到很高的PSNR,但是当图像被高倍率上采样时,重建的图像会过于平滑而失去细节。在SRGAN的论文中,作者提出了一种利用生成对抗网络(GAN)进行超分辨率图像重建的方法,这是第一个可以4倍上采样图像的框架。作者提出的损失函数有两个部分: 对抗损失(Adversarial Loss)和内容损失(Content Loss)。
对抗损失使用一个被训练以区分超分辨率图像和原始现实图像的判别器网络将网络的结果推导至自然图像流形,由此降低数据维度。SRGAN使用了一种以感知相似性驱动的内容损失,而不是像素的相似性 [1] ,作者认为这种“感知”更接近人的主观感受。
2. 网络结构
SRGAN可以被分为两个子网络,一个是所谓的生成器,另一个是判别器。生成器由残差网络组成,并与批量归一化(Batch Normalization)层相结合,其作用是生成尽可能逼真的图像。由生成器生成的图像将被放入判别器,它将判别该图像是生成的假高分辨率图像还是真正的高分辨率图像,两个子网络的结构见图1 [1] 。
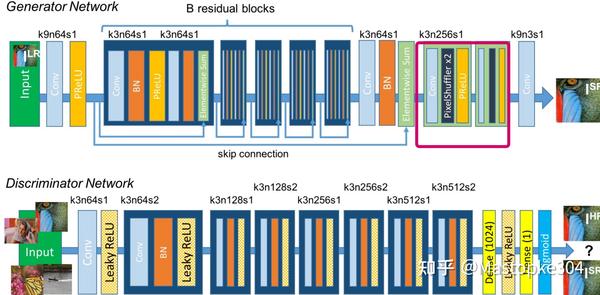

实际上,这篇文章的一大创新点在于提出了一种包括了上述了的对抗损失和内容损失的新型损失函数,其中内容损失的计算公式为:
\\l^{SR}_{X}=l^{SR}_{VGG/i,j}=\frac{1}{W_{i,j}H_{i,j}}\sum\limits^{W_{i,j}}\limits_{x=1}\sum\limits^{H_{i,j}}\limits_{y=1}(\phi_{i,j}(I^{HR})_{x,y}-\phi_{i,j}(G_{\theta_G}(I^{LR}))_{x,y})^2 \tag{1} \\ 其中 \phi_{i,j} 表示由VGG19内的第 i 个最大池化层之前的第 j 个卷积经过激活后得到的特征图,这是给定的。而内容损失则是重建图像 G_{\theta_G}(I^{LR}) 和参考图像 I^{HR} 的特征表示之间的欧式距离 [1] 。而 W_{i,j} 和 H_{i,j} 分别表示重建图像与参考图像在VGG网络内的特征图。
对抗损失的计算公式为:
\\ l^{SR}_{Gen}=\sum\limits^{N}\limits_{n=1}-\log{D_{\theta_D}(G_{\theta_G}(I^{LR}))} \tag{2} \\ 其中 D_{\theta_D}(G_{\theta_G}(I^{LR})) 为重建图像 G_{\theta_G}(I^{LR}) 是真实高分辨率图像的概率。作者为了更好的梯度表现,选择最小化 -\log{D_{\theta_D}(G_{\theta_G}(I^{LR}))} 而非 \log{[1-D_{\theta_D}(G_{\theta_G}(I^{LR}))]} [6] 。
将上述两种损失结合起来,就是感知损失函数(Perceptual loss function):
\\ l^{SR}=\underbrace{\underbrace{l^{SR}_X}_{\rm content \space loss}+\underbrace{10^{-3}l^{SR}_{Gen}}_{\rm adversarial \space loss}}_{\rm perceptual \space loss \space (for \space VGG \space based \space content \space losses)} \tag{3} \\
最后,需要说明的是,本文的网络结构是上述SRGAN网络去除了生成器中最后两个上采样层(即图1的红色方框内)所得到的结构。
3. 实验
3.1 数据集与评估指标
我们使用了COCO2014数据集中共80000张图片用于训练,使用CIFAR-10数据集中10000张图片用于测试。我们首先将图片随即裁剪成 96\times96 的大小,并将像素值归一化至 [0,1] ,随后人工地将 \mu=0, \sigma^2=0.01384 的高斯噪声添加到图片上,我们使用PSNR和SSIM来衡量模型的性能。
3.2 训练
我们使用一张NVIDIA RTX3080Ti GPU训练我们的网络。生成器中残差块的个数为5,并且正如第2节提到的,我们去除了所有的上采样层,使得输入与输出的大小能够保持一致。损失函数为第2节中定义的感知损失函数。生成器的学习率为 10^{-4} ,而判别器的学习率为 10^{-3} 。此外,我们应用了早停法(Early stopping)来防止过拟合。
4. 结果
最终,我们在30次训练迭代后在COCO2014得到了测试集上平均PSNR为21.2315且SSIM为0.9239的模型。原始图片、噪声图片,以及降噪后的图片的示例见图2,测试结果如图3。




5. 结论
我们简单地修改了SRGAN的网络结构,并且使用COCO2014中80000张图片进行训练,使用CIFAR-10中10000张图片用于测试。最终得到了一个测试集平均PSNR为21.2315,平均SSIM为0.9239的模型。目前模型的不足之处在于,降噪后的图片会损失一部分颜色。
结语&后续更新
2023/3/30 本人是深度学习新手,这篇文章也只是为了完成任务而作,所以其学术性和实用性等都不在考虑范围内。并且由于任务时间限制,并没有对模型进行细致优化和后续更新,因此目前模型也存在许多可以改进的地方,例如可以增加生成器中残差块的数量,或者对判别器与生成器的超参数进行微调,相信能够得到更好的性能。本文代码已开源至Github: https:// github.com/Mastopke304/ SRGAN4ImageDenoising ,非重大BUG一般不会更新。
2023/4/11 预告一下本文的代码详解版,一周内更新。
2023/4/14 代码详解已更新: Pytorch深度学习:使用SRGAN进行图像降噪——代码详解 - 知乎 (zhihu.com) ;Github仓库的earlystopping.py文件更新,修复了一个BUG。
2023/4/25 修改文章勘误。
参考
- ^ a b c d C. Ledig et al., "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network," 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 105-114, doi: 10.1109/CVPR.2017.19.
- ^ Chen Tao, Kai-Kuang Ma, and Li-Hui Chen. Tri-state median filter for image denoising. IEEE Transactions on Image Processing, 8(12):1834–1838, Dec. 1999. 1
- ^ K. Zhang, W. Zuo, Y. Chen, D. Meng and L. Zhang, "Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising," in IEEE Transactions on Image Processing, vol. 26, no. 7, pp. 3142-3155, July 2017, doi: 10.1109/TIP.2017.2662206.
- ^ K. Zhang, W. Zuo and L. Zhang, "FFDNet: Toward a Fast and Flexible Solution for CNN-Based Image Denoising," in IEEE Transactions on Image Processing, vol. 27, no. 9, pp. 4608-4622, Sept. 2018, doi: 10.1109/TIP.2018.2839891.
- ^ S. Guo, Z. Yan, K. Zhang, W. Zuo and L. Zhang, "Toward Convolutional Blind Denoising of Real Photographs," 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 1712-1722, doi: 10.1109/CVPR.2019.00181.
- ^ I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In Advances in Neural Information Processing Systems (NIPS), pages 2672–2680, 2014.