


普林斯顿Stata教程 - Stata编程

译者:谢作翰 | 连玉君 | ( 知乎 | 简书 | 码云 )
连享会 最新专题

Note: 助教招聘信息请进入「课程主页」查看。
因果推断-内生性 专题 ⌚ 2020.11.12-15 主讲:王存同 (中央财经大学);司继春(上海对外经贸大学) 课程主页 : https:// gitee.com/arlionn/YG | 微信版
http:// qr32.cn/BlTL43 (二维码自动识别)
空间计量 专题 ⌚ 2020.12.10-13 主讲:杨海生 (中山大学);范巧 (兰州大学) 课程主页 : https:// gitee.com/arlionn/SP | 微信版
https:// gitee.com/arlionn/DSGE (二维码自动识别)
原文链接: Princeton Stata 在线课程 (Princeton University - Stata Tutorial )
专题链接
目录
3.1 暂元
- 3.1.1 在暂元中存储文本
- 3.1.2 在暂元中存储结果
- 3.1.3 全局暂元与键盘映射
-
3.1.4 关于暂元的更多信息
3.2 循环 - 3.2.1 遍历数字序列循环
- 3.2.2遍历列表中的元素
- 3.2.3 循环专用列表
- 3.2.4 while循环
- 3.2.5 条件执行
3.3 编写命令
- 3.3.1 无参数程序
- 3.3.2 有参数的程序
- 3.3.3 复合引号
- 3.3.4 位置参数
- 3.3.5 使用Stata语法
- 3.3.6创建新变量
- 3.3.7 Coale-McNeil 拟合
3.4其他主题
这部分是对Stata编程的简单介绍。主要讨论 暂元 和 循环 ,并展示如何编写简单程序。编程是一个很大的主题,我在这里仅进行一些提示,希望能激发你进一步学习的兴趣。本文所涵盖的材料将帮助你更有效地使用Stata。
Stata 9引入了一种新的非常强大的矩阵编程语言
Mata
。这极大扩展了程序员的工具,远远超出了这里所讨论的暂元,但是Mata是一个值得单独讨论的主题,所以本文不会对此进行介绍。然而,您在这里的努力不会白费,因为Mata仅是Stata编程的补充,而不是完全替代。
要了解关于Stata编程的更多信息,我建议您使用Kit Baum的Stata编程简介,现在已发布到第二版。您也可以查阅用户指南第18章,根据需要参考。Nick Cox在Stata Journal的专栏也是学习Stata的绝佳资源。
3.1 暂元
暂元是一个与一些文本相关联的名称,依据范围可分为全局暂元与暂元。
3.1.1 在暂元中存储文本
暂元名称最多为31个字符,并且仅在当前环境(语境)中被识别(console,do file或programe)。
暂元定义语句为
local name [=] text
,输入
`name'
(请注意使用反引号和左引号。)进行调用。
第一种变体不带等号,用于存储任意文本,最多可达64k个字符(在Stata SE中最多可达100万个字符)。文本通常用引号引起来,但不是必须。
示例:回归方程中的控制变量
有时你需要运行一堆回归方程,其中包括一组标准的控制变量,比如
age,agesq,education,和income
。当然,你可以在每个等式中键入这些名称,或者可以剪切和粘贴名称,但这些方法很繁琐且容易出错。聪明的方法是定义一个暂元
local controls age agesq education income然后,输入命令
regress outcome treatment `controls'它与一下命令完全等价
regress outcome treatment age agesq education income如果只运行一次回归,不需要保存信息,但是如果你必须运行多个具有不同结果或处理方式的模型,使用暂元可以提高效率并确保一致性。
这种方法还有一个好处是,如果以后你意识到你应该对某个控制变量取对数,你只需改变暂元的定义即可,比如将
income
改为
logimcome
,对暂元所做的改变会在所有后续模型中应用。
警告:输入不存在的暂元不是错误;,只是会返回一个空字符串。所以要小心拼写正确的暂元名称。如果输入 regress outcome treatment `contrls' ,Stata将读取 regress outcome treatment ,因为暂元 contrls 不存在。如果你输入 control 的话,也会发生同样的情况,因为暂元名称不能按变量名称的方式缩写。
示例:管理虚拟变量
假设你正在参与人口调查工作,受访人按年龄以5年分为一组,从
age15to19
到
age45to49
共分为七组。其中有六组会作为虚拟变量在回归中使用。定义一个暂元
local age "age20to24 age25to29 age30to34 age35to39 age40to44 age45to49"然后在你的回归模型中使用
regress ceb `age' urban
这不仅更短,更具可读性,而且更接近你的意图。这也使得改变对年龄的表示更为容易,如果您以后决定使用线性和二次项表示年龄,则只需定义暂元
local age "age agesq"
并重新运行模型。请注意,第一个
age
是暂元的名称,第二个是变量的名称。在此我用引号使代码更清晰。
请注意嵌套的暂元。如果一个暂元中包含了另一个暂元(在此不妨称为子暂元),新暂元的内容是在创建那一刻就确定的(解析),而不是在被评估时被解析。例如,如果你定义暂元 local controls `age' income education 。在定义新暂元 control 时Stata认为其中包含子暂元 age 并对子暂元内容展开解读,就算在未来你改变了子暂元 age 的内容,新暂元中保留的依然是创建时点子暂元的内容与形式。
但是,有一种方法可以实现新暂元随子暂元同步更新的效果。诀窍是在定义暂元时输入斜杠号避开暂元评估字符 local controls `age' income education 。现在Stata不评估暂元,所以 controls 内容变成了 `age' income education 。当暂元 controls 被评估时,Stata才会发现它包含暂元 age 并对其展开解读。
3.1.2 在暂元中存储结果
第二种类型的暂元定义
local name = text
(含等于号)用于存储结果。它指示Stata将右侧的文本视为表达式,对其进行评估,并在指定名称中存储结果的文本表达。
假设你只是运行一个回归,并想存储R平方结果,以便与后面的回归进行比较。你知道
regress
命令将残差平方和存储在
e(r2)
中,所以你认为如下命令将会奏效:
local rsq e(r2)
但事实并非如此。您的暂元所存储是公式
e(r2)
,如过你输入
display "`rsq'"
你看到的是一条公式,而不是我们所要的数值。解决方法是使用
等号
连接
local rsq = e(r2)
,这会t提示Stata计算表达式并存储结果。
要看到差异,请尝试一下代码
. sysuse auto, clear
(1978 Automobile Data)
. quietly regress mpg weight
. local rsqf e(r2)
. local rsqv = e(r2)
. di `rsqf' // this has the current R-squared
.65153125
. di `rsqv' // as does this
.65153125
. quietly regress mpg weight foreign
. di `rsqf' // the formula has the new R-squared
.66270291
. di `rsqv' // this guy has the old one
.65153125
当你仅仅是想存储文本信息是也可以使用等号,但我并不推荐,尤其当你使用的是旧版Stata时,会带来不必要的麻烦。以
local controls = "age agesq education income"
为例,使用等号不影响正常工作,但会使右引号左边内容被Stata计算,并被标记为字符串格式——最多输入244个字符,而正常暂元文本可输入更多内容。
3.1.3 全局暂元与键盘映射
全局暂元名称最多可包含32个字符,正如名称所示,它具有全局范围。
你可以定义一个全局暂元,
global name [=] text
并使用
$name
进行计算。(你可能需要用
${name}
限定名称的结尾)
我建议你避免使用全局暂元,因为存在名称冲突的可能性。一个有用的应用是使用键盘上的功能键映射。如果你在一个名字很长的共享网络文件夹上工作,请尝试
global F5 \\server\shared\research\project\subproject\
当你打F5时,Stata会替换全名。而你的do files可以使用命令
do${F5}dofile
(我们需要大括号来表明暂元名称是F5,而不是
F5dofile
)
显然你不想在每次使用Stata时输入这个暂元,你可以将其输入到你的
profile.do
文件——每次运行Stata时执行的一组命令。通常情况下,你的个人配置文件最好存储在Stata的启动目录
C:\data
中。
help profilew
了解更多信息。
3.1.4 关于暂元的更多信息
暂元也可用于使用扩展暂元函数获取和存储关于系统或数据集中变量的信息。例如,你可以检索变量和值标签。还有一些命令可以管理你的暂元集合,包括
macro list
和
macro drop
,
help macro
了解更多信息。
3.2 循环
循环用于完成重复性任务。Stata的命令允许循环遍历数字序列和包括变量列表在内的各种类型列表。在我们开始之前,不要忘记Stata自己做了很多循环。如果你想计算收入的对数,你可以在Stata中用一行代码来实现:
gen logincome = log(income)这行代码隐晦地在所有观测值上循环,计算每个收入的对数,又称为 矢量化操作 。你可以自己编写循环,但是没有必要。第一,你不需要;第二,你的代码会比Stata内置循环慢很多
3.2.1 遍历数字序列循环
基本的循环命令采用这种形式
forvalues number = sequence {
... body of loop using `number' ...
}
这
forvalues
是一个关键字,
number
是一个暂元的名称,它将被设置为序列中的每个数字,
sequence
是一个如下形式的数值范围
-
min/max:从min到max以1为步长的数字序列,例如1/3产生1,2和 3 -
first(step)last:从first到last以step为步长依次排列的数字序列例如15(5)50为15,20,25,30,35,40,45和50。
(指定第二种序列的方法有两种,这里列出的是最清晰的,替代方案请参阅
help forvalues
)
开头的左大括号必须是第一行的最后一项(注释除外),并且循环必须以独立成行的右大括号结束。循环会对序列中的每个值执行一次并将结果保存在暂元
number
(本例中暂元名为
number
)中。
创建虚拟变量
这是我最喜欢的创建年龄组虚拟变量的方式。虽然Stata 11引入了因子变量,Stata 13改进了估算表格的标签,大大减少了“滚动自己的”虚拟变量的需求,但代码仍然具有启发性。
forvalues bot = 20(5)45 {
local top = `bot' + 4
gen age`bot'to`top' = age >= `bot' & age <= `top'
}
这将创建一组虚拟变量
age20to24
到
age45to49
。循环时,暂元
bot
将以5为步长在20和45范围内取值表示年龄组的
下限
(即20,25,30,35,40和45)。
在循环内部,我们创建一个暂元
top
来表示年龄段的
上限
,它等于下限加4。第一次循环中
bot
是20,所以
top
是24.我们使用
等号
来存储
bot
加4的
结果
。
下一行是一个简单的生成语句。第一次循环时语句会显示
gen age20to24 = age >= 20 & age <= 24
(你可以建立自己的暂元来查看),这将创建第一个虚拟变量,然后Stata将返回顶部创建下一个。
3.2.2遍历列表中的元素
第二个循环命令是
foreach
,它有六种风格,以处理不同类型的列表。我将从通用列表开始:
foreach item in a-list-of-things {
... body of loop using `item' ...
}
foreach
是一个关键字,
item
是自己选择的暂元名称,
in
是另一个关键字,紧跟着是空格分隔的单词。试试这个例子
foreach animal in cats and dogs {
display "`animal'"
}
由于暂元
animal
被设置为列表中的每个单词,因此该循环将输出
“猫”
,
“和”
和**“狗” **。Stata不知道“和”不是一种动物,但即使这样做,它也不会在意,因为这个列表是通用的。
如果你想循环一个不规则的数字序列 - 例如你需要用Coale-Demeny区域模型生命表对第2,6和12级做一些事情 - 你可以编写
foreach level in 2 6 12 {
... do something with `level' ...
}
这可能是你需要了解循环的全部内容。
3.2.3 循环专用列表
foreach
还有其他五种变体,它们在特定类型的列表上循环,我现在简要介绍它们。
变量列表
也许是最有用的变体
foreach varname of varlist list-of-variables {
... body of loop using `varname' ...
这里
foreach
,
of
和
varlist
是关键字,它们必须准确输入。
list-of-variables
是一个存储变量名字的列表。你可以进行适当缩写,比如使用类型变量的名称
var*
来指代以
“var”
开头的所有变量,或
var1-var3
对变量
var1
到
var3
进行引用。
这种循环的有点是
foreach varname in list-of-variables
命令中Stata会检查列表中的每个名称是否确实是现有的变量,并且可以缩写或使用扩展名称。
如果你需要对新生成变量进行循环,使用命令
foreach varname of newlist list-of-new-variables
。关键字
newlist
替换原有的
varlist
,告诉Stata检查列表中此前不存在的变量名称。
遍历暂元中词汇
其他两个变体循环遍历本地或全局暂元中的单词,格式是分别使用关键字
global
或
local
,后跟暂元名称(代替列表名)。例如,这里有一种方法可以
从暂元中列出控制变量名称
:
foreach control of local controls {
display "`control'"
}
在数据集中我们可以使用
foreach
和
varlist
来实现相同目的。
数字列表
Stata中有一个
foreach
变体专门用于处理
forvalues
无法处理的数字列表。
假设一项调查在1980年开始进行,并在1985年和1995跟进。(在1990年虽然他们同样希望跟进,但并未得到资助),要对间隔不规则数字列表进行循环,你可以使用
foreach year of numlist 1980 1985 1995 {
display "`year'"
}
你可以做一些比打印年份名更有趣的事情,比如将
numlist
指定为1 2 3或1/5((意思是1 2 3 4 5)),或是1(2)7(从1到7以2为步长计数以得到1 3 5 7); 更多信息
help numlist
。
这个命令优于优点通用命令的地方是Stata会检查数字列表中的每个元素是否为一个数字。
3.2.4 while循环
与许多编程语言一样,Stata也有一个while循环,它具有以下结构
while condition {
... do something ...
}条件是表达式。 只要条件为真(非零),循环就会执行。 通常情况下,内部循环时会有条件不满足,否则代码将永远运行。
while
循环一种典型用途是迭代估计,当连续估计的差值大于预设的容差循环继续进行。迭代计数通常用于检测对象是否缺乏收敛性。
continue [,break]
命令将会中断包括
while
,
forvalues
,
foreach
在内的所有循环。该命令将停止当前迭代并继续下一个迭代,除非已经指定了
break
,否则将退出循环。
3.2.5 条件执行
Stata的也有一个
if
编程命令,为了不与限定子集的限定符
if
混淆(如
summarize mpg if foreign
),该
if
命令具有以下结构
if expression {
... commands to be executed if expression is true ...
else {
... optional block to be executed if expression is false ...
}
这里
if
和可选的
else
是关键字,
help exp
了解表达式信息。
{
必须是一行中最后一项(注释除外),
}
必须单独成行。
如果
if
或
else
部分由单个命令组成,便不需要大括号并且可以单独成行,如
if expression command
。但不可以使用括号情况下同行成列如
if expression { command }
。你可以将代码分成三行来使用大括号,这通常会提高代码的可读性。
在这里我们设置一个简单的循环,在十次迭代的五次之后停止,
forvalues iter=1/10 {
display "`iter'"
if `iter' >= 5 continue, break
}3.3 编写命令
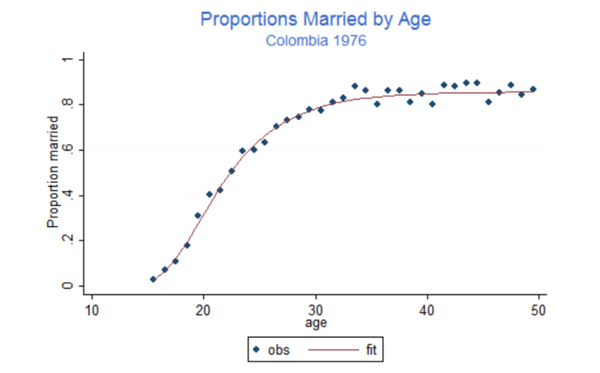
我们接下来的任务是编写自己的Stata命令,跟随我们开发几个简单的程序,一个用于标注你的输出( sign your output),另一个来评估Coale-McNeil模型的婚礼安排,我们可以创建如下所示图表:
3.3.1 无参数程序
让我们开发一个命令,以你的名字标注你的输出。开发一个命令最简单的方法是从一个do文件开始。启动Stata的do-file编辑器(Ctrl+9)并输入:
capture program drop sign
program define sign
version 9.1
display as text "Germán Rodríguez "
display "{txt}{hline 62}"
end
如果你现在输入
sign
,Stata将使用文本样式显示签名

签名
的
program drop
在需要改变
do file
内容或重新运行该文件时使用,类似于数据集中的
clear
命令。因为你不能定义一个已经存在的程序。在一次使用时需要
capture
,此时没有什么程序需要删除。
version 9.1
表明该命令是为Stata版本9.1开发的,可以帮助未来版本的Stata正确运行它,即使语法在此期间发生了变化。
最后一行使用了一些
SMCL
(Stata Markup Control Language),发音为“smickle”,Stata标记控制语言是Stata输出处理器的名称。
SMCL
使用纯文本结合大括号中。例如,
{txt}
将显示模式设置为文本,
{hline 62}
绘制一个宽度为62个字符的水平线。了解更多关于SMCL类型的信息
help smcl
。
3.3.2 有参数的程序
为了制作有用的程序,你经常需要在命令后面输入参数以传递信息给它们。让我们写一个能够回应你所说的话的命令:
capture program drop echo
program define echo
version 9.1
display as text "`0'"
end
尝试输入
echo Programming Stata Tutorial
看看会发生什么。
当你调用
echo
命令时,Stata将参数存储在名为
0
的暂元中,并且用
display
命令将暂元结果以文本呈现,由于是文本,所以带上双引号。(假如你输入
echo Hi
,暂元
0
由空白变为
Hi
,命令会读取
display Hi
,此时stata会报错无法找到
Hi
命令,我们希望命令读取`display “Hi”,因此为暂元添加引号)

echo程序
如果我们没有指定任何内容,则暂元
0
将是一个空字符串,该命令将读取
display ""
并且Stata将打印一个空行。
3.3.3 复合引号
在庆祝之前,我们需要解决新命令的一个小问题。输入
echo The hopefully "final" run
,Stata会报错。为什么呢?因为
"final"
中含有引号在读取命令显示为:
display "The hopefully "final" run"
Stata理解的则是
“The hopefully” final “run”
,两个引号包围的词夹着没有引号的
final
,这在Stata看来是一句无效表达。显然我们需要一些方法来区分内部和外部引用。
顺便提一句,你可以通过
set trace on
命令看到Stata执行的整个过程(如下所示)。完成后别忘了输入
set trace off
。
help trace
以了解更多信息。
echo The hopefully "final" run
---------------------------------------------------------------- begin echo ---
- version 9.1
- display as text "`0'"
= display as text "The hopefully "final" run"
The hopefully final" run" invalid name
------------------------------------------------------------------ end echo ---
r(198);
那么问题该如何解决呢?答案是使用Stata的复合引号:
`"
开始,
" '
结束,例如
`"compound quotes"'
。由于打开和关闭符号不同,这些引号可以嵌套。复合引号可以在任何使用双引号的地方使用。如果引用的文本包含双引号,则必须使用复合引号。
所以我们的最终版本是
display "`0'"
。
program define echo
version 9.1
if `"`0'"' != "" display as text `"`0'"'
你会注意到我删去了
capture drop line
这是因为我们现在准备将程序保存为
ado
文件。输入
sysdir
以找出您的个人
ado
目录位置,然后将文件保存为
echo.ado
。现在你可以在任意时刻调用该命令。
(ps,如果要确认新建命令没有和官方命令重名,输入
which echo.Stata
,得到回复
file echo.Stata not allowable filetype
即可)
3.3.4 位置参数
Stata除了将所有参数一起存储在暂元
0
,还会把参数的文本分别存储在暂元'1','2','3'等等之中(使用参数作为分隔符),并在这些暂元中对解析参数。
通常你会先解析暂元
`1'
然后转向下一个。这时
mac shift
命令会派上用场,因为它将所有的暂元都向下移动一个,所以现在2的内容在1,3的内容在2等等。这样,你只需一直对暂元
1
处理即可,直到列表耗尽时
1
内容为空,你的工作就完成了。
下是显示参数内容的规范程序:
capture program drop echo
program define echo
version 9.1
while "`1'" != "" {
display `"`1'"'
mac shift
不要忘记
mac shift
,否则你的程序可能会永远运行。(或者直到你按下
break
)
尝试
echo one two three testing
和
echo one "two and three" four
。体会如何通过使用引号将多个单词分组为单个参数。
(ps:我们不仅可以将参数传递给命令,还可以将其传递给do files,
help do
以便了解更多信息。)
3.3.5 使用Stata语法
如果你使用标准的stata语句,你可以充分利用stata自己的解析器,它可以方便地将所有元素存储在暂元中供你使用,不过一个标准的stata语句意味你的参数必须是一个变量列表,或是权重,
if
/
in
子句,或是一堆选项中的一种或多种。
连享会 最新专题
一个命令原型
让我们编写一个命令,用一个给定的均值,标准差和结婚比例的Coale-McNeil模型计算一定年龄段的结婚概率。我们设计的使用语法是:
pnupt age, generate(married) [ mean(25) stdev(5) pem(1)]
对照语法,我们需要包含确切年龄数据的年龄变量,以及一个必须选项——在给定结婚比例时生成一个新变量。还有一些可选选项指定平均值,标准差和结婚比例,当然这些都预设有默认值。
因此,我们需要一个具有确切年份的年龄的现有变量,以及一个强制选项,指定一个以已婚比例生成的新变量。还有一些选项可以指定时间表中的平均值,标准偏差和结婚比例,所有这些都有默认值。这是命令的第一步
capture program drop pnupt
program define pnupt
version 9.1
syntax varname, Generate(name) ///
[ Mean(real 25) Stdev(real 5) Pem(real 1) ]
// ... we don't do anything yet ...
end
首先要注意的是,该
syntax
命令看起来非常像我们的原型。
变量列表
在我们的语法中的第一个元素是一个变量列表
varlist
。你可以指定最小值和最大值,例如一个需要两个变量的程序
varlist(min=2 max=2)
。当我们只有一个变量时,可以输入
varname
,这是
varlist(min=1 max=1)
的简称。
然后,Stata将确保您的程序调用时使用的是一个现有变量的名称,该变量将被存储在名为
varlist
的暂元中。(t即使你只有一个变量并在你的语法语句中使用
varname
,暂元名依然是
varlis
)尝试
pnupt nonesuch
,Stata会抱错,说“variable nonesuch not found”。
(如果你之前有过编程经验,并且花费大部分时间用于检查输入错误,仅少部分真正用于手头任务,你将会非常喜欢
syntax
,因为它为你执行了很多错误检查)
选项和默认值
可选语法元素包含在方括号[]中。在我们的命令中,
generate
选项是必需的,其他三个是可选的。尝试使用这些命令生成一个范围在15到50的年龄变量小测试数据集
drop _all
set obs 36
gen age = 14 + _n
现在尝试
pnupt age
。这次Stata并未对
age
变量报错,但提示 'option generate() required'。带参数的选项需要指定参数类型(integer,real,string,name)和默认(不强制)值。
generate
需要一个
name
,没有默认值。尝试
pnupt age, gen(2)
。Stata会抱怨说2不是一个变量名。
正常情况下,选项的内容将存储在与选项同名的暂元中。
检查参数
现在我们需要做一些工作来检查名称是否是一个有效的变量名称,我们使用
confirm
:
confirm new variable `generate'
然后Stata检查你是否可以生成这个变量,如果不行,则发出错误110.尝试
pnupt age, gen(age)
,Stata会说 'age already defined'。
现在你应该清楚,stata会检查均值,标准差和结婚比例这三个选项是否有指定数值(缩写为
m()
,
s()
和
p()
),这些值必须是实数,并将被存储在名为
mean
,
stdev
, 和
pem
的暂元中。
你可以对输入做更多的检查。让我们快速检查所有三个参数是负数,其中比例不能大于1。
if (`mean' <= 0 | `stdev' <= 0 | `pem' <= 0 | `pem' > 1) {
di as error "invalid parameters"
exit 110
}你可能希望对每个参数进行单独检查,这正是接下来我们要做的。
临时变量
我们现在准备利用Coale-McNeil模型和伽玛分布之间的关系做一些计算,下面是该程序的工作版本
program define pnupt
*! Coale-McNeil cumulative nuptiality schedule v1 GR 24-Feb-06
version 9.1
syntax varname, Generate(name) [Mean(real 25) Stdev(real 5) Pem(real 1)]
confirm new var `generate'
if `mean' <= 0 | `stdev' <= 0 | `pem' <= 0 | `pem' > 1 {
display as error "invalid parameters"
exit 198
tempname z g
gen `z' = (`varlist' - `mean')/`stdev'
gen `g' = gammap(0.604, exp(-1.896 * (`z' + 0.805)))
gen `generate' = `pem' * (1 - `g')
end
我们可以将概率公式一行写出,但这会牺牲可读性。相反,我们先对年龄变量进行标准化,只是我们该如何称呼这个新变量呢?你或许会叫它
z
,这当然可以。只是如果你命令的用户恰巧有一个变量叫
z
该怎么办呢?当我们计算伽玛函数后,我们又应该如何命令称呼结果呢?
上述问题的答案是
tempname
命令,该命令使stata生成唯一的临时变量名,本例中两个变量名会分别被存储在暂元
z
和
g
中。由于这些暂元是本地的,因此不存在名称冲突的问题。临时变量的另一个特点是当程序结束时它们会自动消失,所有工作stata会自动替你做好。
gen `z' = (`varlist' - `mean')/`stdev'
这行代码乍一看会有些奇怪,但请记住我们所有感兴趣的量现在都存储在暂元中,我们调用时必须先对暂元解析:
z'获取我们临时变量的名称,
varlist'获取用户指定的年龄变量的名称,
mean'获取平均值,
stdev'得到标准差的值。在暂元代换之后,这行代码会读取类似的内容
gen _000001 = (age-22.44)/5.28
,这可能会更有意义。
if/in
你可能在考虑允许用户在命令中指定
if
和
in
条件,这需要添加到
syntax
中,它们将被存储在暂元中,然后你可以在计算中使用它们,在这种情况下传递给生成。
有关此主题类型的更详细的讨论
help syntax
3.3.6创建新变量
有时你编写的命令会创建一个新的变量。事实上,这就是我们的小命令所做的。如果我们可以使用
egen
像这样的一种命令输入形式会非常方便:
egen married = pnupt(age), mean(22.48) stdev(5.29) pem(0.858)
答案是肯定的。因为
egen
是用户可扩展的。要实现一个名为
pnupt
的函数,你必须创建一个程序(do files )的_gpnupt,换句话说就是添加前缀
_g
。关于
egen
扩展的文档有点稀少,但一旦你知道了这个基本事实,你只需要查看
egen
命令的源文件并复制即可。
所以这里是我们的Coale-McNeil命令版本的
egen
。
program define _gpnupt
*! Coale-McNeil cumulative nuptiality schedule v1 GR 24-Feb-06
version 9.1
syntax newvarname=/exp [, Mean(real 25) Stdev(real 5) Pem(real 1)]
if `mean' <= 0 | `stdev' <= 0 | `pem' <= 0 | `pem' > 1 {
display as error "invalid parameters"
exit 198
tempname z g
gen `z' = (`exp' - `mean')/`stdev'
gen `g' = gammap(0.604, exp(-1.896 * (`z' + 0.805)))
gen `typlist' `varlist' = `pem' * (1 - `g')
end
这个版本和上一个之间的差异很小,主要体现在
egen
接受表达式输入而不是单单变量输入.输入参数会被解析并存储在一个名为
exp
的临时变量中。输出变量被指定为
varlist
,在本例中为
newvarname
。这就是为什么
z
现在与
exp
和
gen
产生
varlist
。
typlist
的存在是因为
egen
可以让你指定输出变量的类型(默认情况下为float)并传递给我们的函数,函数再将它传递给
gen
。
3.3.7 Coale-McNeil 拟合
我们准备揭示最初的图形是如何制作的。这些数据可以在我网站的人口统计部分的Stata文件中找到,数据包括已婚和单身女性的年龄。我们将计算观察到的已婚比例,根据Rodríguez和Trussell(1980)的估计值计算拟合值,并绘制结果图。这一切只需几行代码即可完成。
use http://data.princeton.edu/eco572/datasets/cohhnupt