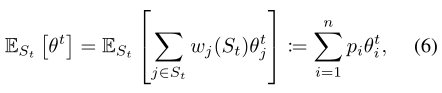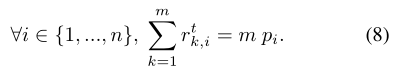对比MD、Algorithm 1、Algorithm 2
数据集:CIFAR10
客户端设计:采用迪利克雷分布(a越小,异构性越强)对CIFAR10进行划分并分配给100个客户,其中10,30,30,20,10个客户分别具备100、250、500、750、1000条训练数据和20、50、100、150、200条测试数据(训练数据的1/5)。

Algorithm 1和Algorithm 2都能实现更小的权重方差,并以此提高了客户的代表性。并通过实验证明两个算法都可以在Non-IID数据集下实现更快更平稳的收敛性质。
《Clustered Sampling: Low-Variance and Improved Representativity for Clients Selection in Federated Learning》针对目前联邦学习中的客户选择策略存在的偏倚问题、server-client通信和训练稳定性问题,这篇文章提出采用聚类抽样的方法进行客户选择,并证明了聚类抽样能提高用户的代表性,并减少不同客户聚合时的权重差异。本文提出了基于样本数量和模型相似性的两种聚合抽样方法,并通过实验证明,采用聚类抽样的方法
1. 论文地址:
[2105.05883v2] Clustered Sampling: Low-Variance and Improved Representativity for Clients Selection in Federated Learning (arxiv.org)
本文所要解决的问题是异构
客户
端资源(数据资源:规模过大/小、计算能力:有快有慢、无线通信条件:模型参数传输时长差异 )——延长服务器的聚合、更新步骤,进而降低模型训练的效率。
为解决上述问题,作者提出了FedCS框架, 相较于传统的模型,其创新点在于增加了 Resource Request步骤,该步骤可以帮助移动边缘计算(MEC)服务器依据工人上传信息评估其“优劣”。 针对上述三种异构情况,若某工人的本地数据集太大/小,计算能力弱、信道状况差则会被工人
选择
算法(贪婪)pass掉,进而保证全局模型训练效率。.
至此
聚类
相关的内容告一段落,前面十篇博客介绍了常见的几种
聚类
算法,也加入了一些代码实现。这篇博客来一个汇总的实例,分别创建圆形数据、月牙形数据、聚团数据以及随机数据,并测试不同数据在各种不同
聚类
算法中的
聚类
效果以及消耗时间。
import time
import warnings
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn import cluster
from sklearn import datasets as ds
from sklearn.neighbo
谱
聚类
是基于谱图理论基础上的一种
聚类
方法,与传统的
聚类
方法相比:具有在任意形状的样本空间上
聚类
并且收敛于全局最优解的优点。(但效率不高,实际工作中用的比较少)
通过对样本数据的拉普拉斯矩阵的特征向量
进行
聚类
,从而达到对样本数据
进行
聚类
的目的;其本质是将
聚类
问题转换为图的最优划分问题,是一种点对
聚类
算法。
谱
聚类
算法将数据集中的每个对象看做图的顶点 V,将顶点间的相似度量化为相应顶点连接边E的权值 w,这样就构成了一个基于相似度的无向加权图 G(V,E),于是
聚类
问题就转换为图的划分问题。基于图的最优划分规则就是子图内的相似度最大,子图间的相似度最小。
谱
聚类
的构建过程主要包含以下
本篇博文为数据挖掘算法系列的第一篇。现在对于Kmeans算法
进行
简单的介绍,Kmeans算法是属于无监督的学习的算法,并且是最基本、最简单的一种基于距离的
聚类
算法。
下面简单说一下Kmeans算法的步骤:
选随机选取K的簇中心(注意这个K是自己
选择
的)
计算每个数据点离这K个簇中心的距离,然后将这个点划分到距离最小的簇中
重新计算簇中心,即将每个簇的所有数据点相加求均值,将这个均值作为对应簇的新簇中心。
重复2、3步,直到满足了你设置的停止算法迭代的条件
注意:停止算法迭代的条件一般有三个:
没有(或最小数目)对象被重新分配给不同的
聚类
。
没有(或最小数目)
聚类
中心再发生变化。
用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别
基于位置信息的商业推送,新闻
聚类
,筛选排序
图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段
1.2 定义
聚类
算法:
一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。
1.3
聚类
算法与分类算法最大的区别
聚类
算法是无监督的学习算法,而分类算法属于监督的学习算法。
1.4
聚类
算法api初步使用
sklearn.cluster.KMean
假设我们有一个在线零售商的顾客数据,其中包含顾客的购买历史、个人信息等。我们可以使用
聚类
算法对这些顾客
进行
细分,以更好地了解他们的购物行为和偏好,从而提高我们的市场营销策略。
首先,我们需要
选择
一个合适的
聚类
算法,例如K-means
聚类
算法。然后,我们需要对数据
进行
预处理,如标准化、缺失值填充等。
接下来,我们可以使用
聚类
算法将顾客划分为不同的群组。每个群组代表一类具有相似购买行为和偏好的顾客。我们可以通过观察每个群组的特征来了解每个群组的典型顾客。例如,如果一个群组中的顾客都购买了相同类型的商品,那么我们可以推断这个群组的典型顾客可能是对这种商品感兴趣的人。
最后,我们可以将每个群组的结果可视化,以便更好地理解每个群组的特点和区别。这样,我们就可以基于
聚类
算法得到
客户
细分的结果,并制定更加针对性的市场营销策略,以提高销售和顾客满意度。