|
|
|
相关文章推荐

Java离线版语音识别-语音转文字
- 1.项目前言
- 2.Vosk介绍
- 3.项目开发
- 4.效果演示
-
系统:Win10
Java:1.8.0_333
IDEA:2020.3.4
Gitee: https://gitee.com/lijinjiang01/SpeechRecognition1.项目前言
最近在做一个鬼畜视频的时候,需要处理大量语音文件,全部都是 wav 格式的,然后我想把这些语音转成文字,不过这些语音有几千条,这时候我就想能不能用 Java 实现。
不过现在主流的语音识别像百度。讯飞好像都不支持 Java 离线版,在查找一些资料后,我准备使用 Vosk2.Vosk介绍
Vosk 官网: https://alphacephei.com/vosk/
Vosk 是言语识别工具包,Vosk 最大的优点是:- 支持二十+种语言 - 中文,英语,印度英语,德语,法语,西班牙语,葡萄牙语,俄语,土耳其语,越南语,意大利语,荷兰人,加泰罗尼亚语,阿拉伯, 希腊语, 波斯语, 菲律宾语,乌克兰语, 哈萨克语, 瑞典语, 日语, 世界语, 印地语, 捷克语, 波兰语
- 移动设备上脱机工作-Raspberry Pi,Android,iOS
- 使用简单的 pip3 install vosk 安装
- 每种语言的手提式模型只有是 50Mb, 但还有更大的服务器模型可用
- 提供流媒体 API,以提供最佳用户体验(与流行的语音识别 python 包不同)
- 还有用于不同编程语言的包装器-java / csharp / javascript等
- 可以快速重新配置词汇以实现最佳准确性
- 支持说话人识别
至于选择 Vosk 的原因,我想大概因为他们是 Apache-2.0 开源项目吧,而且他们还提供了中文模型,这省了很多事不是么
3.项目开发
3.1 项目准备
这里的项目准备只做一个 wav 语音识别,能够供自己使用就行了
首先,我们需要新建一个 Maven Java 项目,然后导入相关的依赖<!-- 获取音频信息 --> <dependency> <groupId>org</groupId> <artifactId>jaudiotagger</artifactId> <version>2.0.3</version> </dependency> <!-- 语音识别 --> <dependency> <groupId>net.java.dev.jna</groupId> <artifactId>jna</artifactId> <version>5.7.0</version> </dependency> <dependency> <groupId>com.alphacephei</groupId> <artifactId>vosk</artifactId> <version>0.3.32</version> </dependency>这里除了 vosk 相关依赖,我还导入了 jaudiotagger 这个获取音频信息的依赖,因为等会我们需要自动获取音频的采样率(SampleRate),有兴趣的小伙伴可以看一下我另一篇文章:Java获取Wav文件的采样率SampleRate
那么为什么我需要获取音频的采样率呢?这里我们看下 Vosk 官方给的示例代码:
https://github.com/alphacep/vosk-api/blob/master/java/demo/src/main/java/org/vosk/demo/DecoderDemo.javapackage org.vosk.demo; import java.io.FileInputStream; import java.io.BufferedInputStream; import java.io.IOException; import java.io.InputStream; import javax.sound.sampled.AudioSystem; import javax.sound.sampled.UnsupportedAudioFileException; import org.vosk.LogLevel; import org.vosk.Recognizer; import org.vosk.LibVosk; import org.vosk.Model; public class DecoderDemo { public static void main(String[] argv) throws IOException, UnsupportedAudioFileException { LibVosk.setLogLevel(LogLevel.DEBUG); try (Model model = new Model("model"); InputStream ais = AudioSystem.getAudioInputStream(new BufferedInputStream(new FileInputStream("../../python/example/test.wav"))); Recognizer recognizer = new Recognizer(model, 16000)) { int nbytes; byte[] b = new byte[4096]; while ((nbytes = ais.read(b)) >= 0) { if (recognizer.acceptWaveForm(b, nbytes)) { System.out.println(recognizer.getResult()); } else { System.out.println(recognizer.getPartialResult()); System.out.println(recognizer.getFinalResult());这个示例代码里有两个重要点:
- model:也就是 new Model(“model”) 这里,这里需要我们指定模型位置
- sampleRate:也就是 new Recognizer(model, 16000) 这里,他这里的示例代码写死了 sampleRate 为 16000 Hz,不过每个音频的采样率不可能都一样,我需要识别的音频采样率基本都是 44100 Hz,所以这里我们需要将他改为自动识别
3.2 model 准备
我们需要实现离线语音识别,那么就得将模型下载到本地电脑。下载地址为官网的 Models 模块:https://alphacephei.com/vosk/models
我们直接找到 Chinese 分类,这里有 2 个模型,上面较小的 40 多M的是轻量级模型,适用于手机等移动设备;下面 1 个多G的适用于服务器的,很明显模型越大识别语音正确率越高

这里我们两个都下载,等会对比下正确率和速率,下载下来是两个压缩包,直接解压到 D 盘,等会选择路径方便(怎么方便怎么来)。

解压之后如下
3.3 测试音频准备
音频下载地址:https://download.csdn.net/download/qq_35132089/86723883
测试音频已经上传到 CSDN 的资源库,设置下载积分为0,有兴趣的小伙伴可以下载测试玩玩
这里一共准备了 8 段音频,共 62 个字01.wav: 保家卫国 02.wav: 这个世界需要希望 03.wav: 我们的勇气绝对不能动摇 04.wav: 德玛西亚 05.wav: 正义要靠法律要么靠武力 06.wav: 为了那些不能作战的人而战 07.wav: 勇往直前 08.wav: 生命不息战斗不止3.4 代码实现
捋清楚思路,接下来实现就比较简单了,我这里写一个 Swing 的项目,准备到时候选择 wav 文件直接语音识别,或者选择一个文件夹,解析该目录下所有的 wav 音频文件
关键代码:import com.lijinjiang.beautyeye.ch3_button.BEButtonUI; import org.jaudiotagger.audio.AudioFile; import org.jaudiotagger.audio.wav.WavFileReader; import org.vosk.Model; import org.vosk.Recognizer; import javax.sound.sampled.AudioSystem; import javax.swing.*; import javax.swing.filechooser.FileNameExtensionFilter; import javax.swing.filechooser.FileSystemView; import java.awt.*; import java.io.*; public class MainFrame { private JFrame mainFrame; // 主界面 private final JPanel contentPanel = new JPanel(null); // 内容面板 private String modelPath; // 模型位置 private File chooseFile; // 选择的文件夹或文件 private JTextField pathField; // 模型位置文本框 private JTextField fileField; // 文件路径文本框 private JTextArea displayArea; // 展示区域 private JLabel timeLabel; // 显示耗时标签 public MainFrame() { modelPath = System.getProperty("user.dir") + "/src/main/resources/vosk-model-small-cn-0.22"; // 初始化模型 System.out.println(modelPath); createFrame(); * 创建主窗口 private void createFrame() { mainFrame = new JFrame(); mainFrame.setTitle("语音识别"); createOperatePanel(); createDisplayPane(); createTimeLabel(); mainFrame.add(contentPanel); mainFrame.setSize(new Dimension(800, 600)); mainFrame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); mainFrame.setLocationRelativeTo(null); mainFrame.setVisible(true); * 创建操作面板 private void createOperatePanel() { JButton pathBtn = new JButton("选择模型"); pathBtn.setLocation(10, 10); pathBtn.setSize(new Dimension(80, 36)); pathBtn.setFocusable(false); // 不绘制焦点 pathBtn.addActionListener(e -> showChoosePathDialog()); pathField = new JTextField(); pathField.setEditable(false); pathField.setLocation(100, 10); pathField.setSize(new Dimension(250, 36)); JButton fileBtn = new JButton("选择文件"); fileBtn.setFocusable(false); // 不绘制焦点 fileBtn.addActionListener(e -> showChooseFileDialog()); fileBtn.setLocation(360, 10); fileBtn.setSize(new Dimension(80, 36)); fileField = new JTextField(); fileField.setEditable(false); fileField.setLocation(450, 10); fileField.setSize(new Dimension(250, 36)); // 开始执行按钮 JButton startBtn = new JButton("执行"); startBtn.addActionListener(e -> execute()); startBtn.setUI(new BEButtonUI().setNormalColor(BEButtonUI.NormalColor.green)); startBtn.setFocusable(false); // 不绘制焦点 startBtn.setLocation(710, 10); startBtn.setSize(new Dimension(70, 36) ); contentPanel.add(pathBtn); contentPanel.add(pathField); contentPanel.add(fileBtn); contentPanel.add(fileField); contentPanel.add(startBtn); * 创建展示面板 private void createDisplayPane() { JScrollPane scrollPane = new JScrollPane(); displayArea = new JTextArea(); scrollPane.setViewportView(displayArea); displayArea.setEditable(false); displayArea.setBorder(null); scrollPane.setSize(new Dimension(775, 480)); scrollPane.setLocation(8, 56); contentPanel.add(scrollPane); private void createTimeLabel() { timeLabel = new JLabel(); timeLabel.setHorizontalAlignment(SwingConstants.RIGHT); // 文本靠右对齐 timeLabel.setSize(new Dimension(100, 36)); timeLabel.setLocation(680, 530); contentPanel.add(timeLabel); * 选择模型位置 private void showChoosePathDialog() { JFileChooser fileChooser = new JFileChooser(); // 初始化一个文件选择器 String pathValue = pathField.getText().trim(); if (pathValue.length() == 0) { FileSystemView fsv = fileChooser.getFileSystemView(); // 获取文件系统网关 fileChooser.setCurrentDirectory(fsv.getHomeDirectory()); // 设置桌面为当前文件路径 } else { // 设置上一次选择路径为当前文件路径 File file = new File(pathValue); File parentFile = file.getParentFile(); if (parentFile == null) { fileChooser.setCurrentDirectory(file); } else { fileChooser.setCurrentDirectory(parentFile); fileChooser.setFileSelectionMode(JFileChooser.DIRECTORIES_ONLY); // 可选文件夹和文件 fileChooser.setMultiSelectionEnabled(false); // 设置可多选 int result = fileChooser.showOpenDialog(mainFrame); if (result == JFileChooser.APPROVE_OPTION) { File file = fileChooser.getSelectedFile(); modelPath = file.getAbsolutePath(); pathField.setText(modelPath); // 将选择的文件路径写入到文本框 * 选择需要转换成文字的文件夹或者文件 * 文件夹:表示该目录下一层所有 wav 都需要转成文字 * 文件:表示只需要将该文件转换成文字即可 private void showChooseFileDialog() { JFileChooser fileChooser = new JFileChooser(); // 初始化一个文件选择器 String fileValue = fileField.getText().trim(); if (fileValue.length() == 0) { FileSystemView fsv = fileChooser.getFileSystemView(); fileChooser.setCurrentDirectory(fsv.getHomeDirectory()); // 设置桌面为当前文件路径 } else { // 设置上一次选择路径为当前文件路径 File file = new File(fileValue); File parentFile = file.getParentFile(); if (parentFile == null) { fileChooser.setCurrentDirectory(file); } else { fileChooser.setCurrentDirectory(parentFile); fileChooser.setFileSelectionMode(JFileChooser.FILES_AND_DIRECTORIES); // 可选文件夹和文件 fileChooser.setMultiSelectionEnabled(false); // 设置可多选 fileChooser.removeChoosableFileFilter(fileChooser.getAcceptAllFileFilter()); // 不显示所有文件的下拉选 fileChooser.addChoosableFileFilter(new FileNameExtensionFilter("wav", "wav")); int result = fileChooser.showOpenDialog(mainFrame); if (result == JFileChooser.APPROVE_OPTION) { chooseFile = fileChooser.getSelectedFile(); fileField.setText(chooseFile.getAbsolutePath()); // 将选择的文件路径写入到文本框 * 开始执行操作 private void execute() { displayArea.setText(""); // 执行后清空显示面板 if (modelPath == null || 0 == modelPath.length()) { JOptionPane.showMessageDialog(mainFrame, "模型位置不能为空", "错误", JOptionPane.ERROR_MESSAGE); return; if (chooseFile == null) { JOptionPane.showMessageDialog(mainFrame, "未选择文件夹或者音频文件", "错误", JOptionPane.ERROR_MESSAGE); return; long startTime = System.currentTimeMillis(); // 用于测试进度条的线程 Thread thread = new Thread() { public void run() { if (chooseFile.isDirectory()) { // 如果是文件夹,则遍历里面每个文件 File[] files = chooseFile.listFiles(pathname -> pathname.getName().endsWith(".wav")); if (files != null) { for (File childFile : files) processFile(childFile); } else { processFile(chooseFile); //显示进度条测试对话框 ProgressBar.show((Frame) null, thread, "语音正在识别中,请稍后...", "执行结束", "取消"); // 否则直接处理该文件 long endTime = System.currentTimeMillis(); String msg = "耗时:" + (endTime - startTime) + "ms"; timeLabel.setText(msg); * 处理文件:语音转文字 private void processFile(File file) { try (Model model = new Model(modelPath);//该段是模型地址 InputStream ais = AudioSystem.getAudioInputStream(new BufferedInputStream(new FileInputStream(file))); //该段是要转的语言文件,仅支持wav Recognizer recognizer = new Recognizer(model, getSampleRate(file))) { //该段中12000是语言频率(Hz),需要大于8000,可以自行调整 int bytes; byte[] b = new byte[4096]; while ((bytes = ais.read(b)) >= 0) { recognizer.acceptWaveForm(b, bytes); displayArea.append(file.getName() + " "); displayArea.append(recognizer.getFinalResult() + System.lineSeparator()); } catch (Exception e) { JOptionPane.showMessageDialog(mainFrame, e.getMessage(), "错误", JOptionPane.ERROR_MESSAGE); e.printStackTrace(); * 获取音频文件的采样率 private Float getSampleRate(File file) throws Exception { WavFileReader fileReader = new WavFileReader(); AudioFile audioFile = fileReader.read(file); String sampleRate = audioFile.getAudioHeader().getSampleRate(); return Float.parseFloat(sampleRate);4.效果演示
4.1 界面效果
界面效果就是如下图所示
- 点击选择模型,就可以指定模型文件夹路径
- 点击选择文件,就可以指定需要识别的语音或文件夹
- 最后点击执行即可开始语音识别
- 识别成功,会将对应音频文件名和识别的文字写在下面的文本域中
- 最后还会将使用时间显示在界面右下角
4.2 单个文件语音识别
4.2.1 轻量模型
这里选择模型选择轻量模型,文件只识别第一个文件
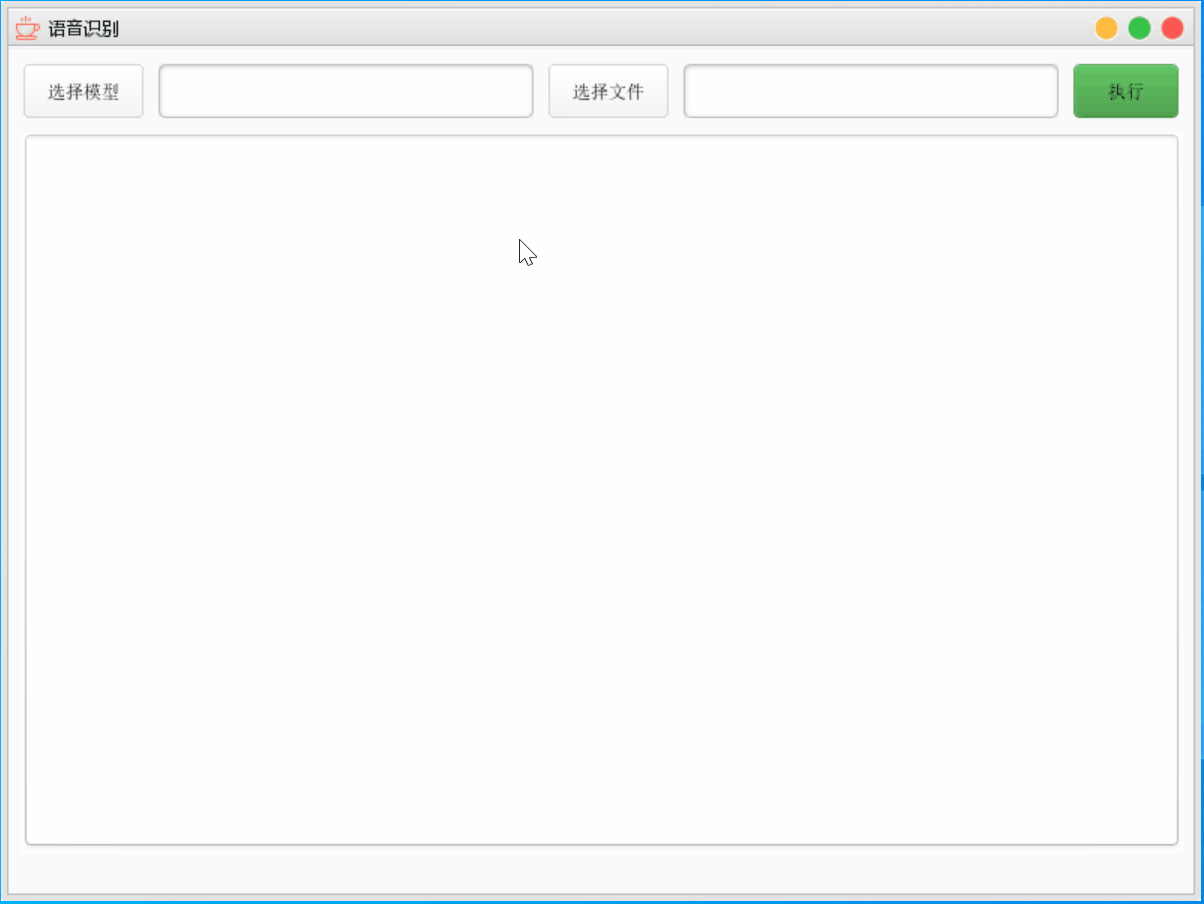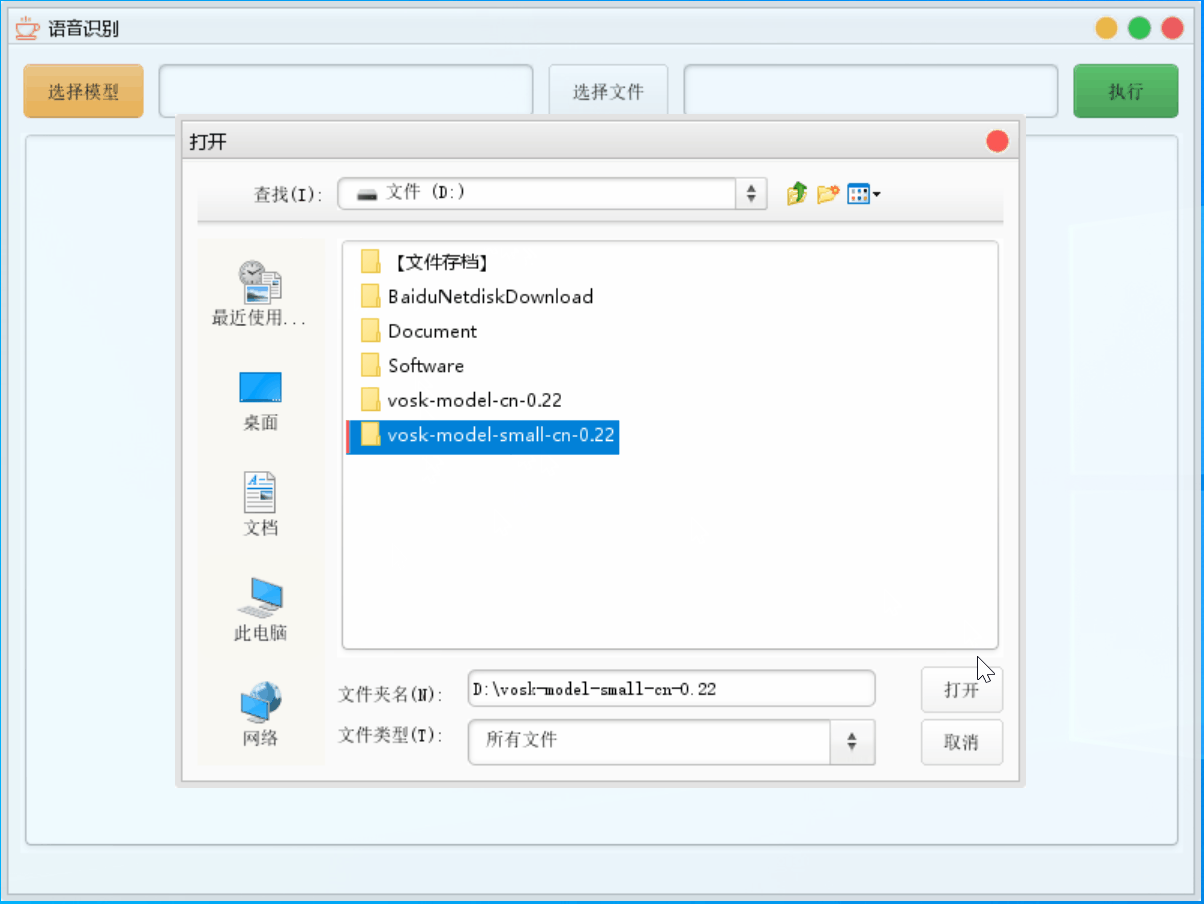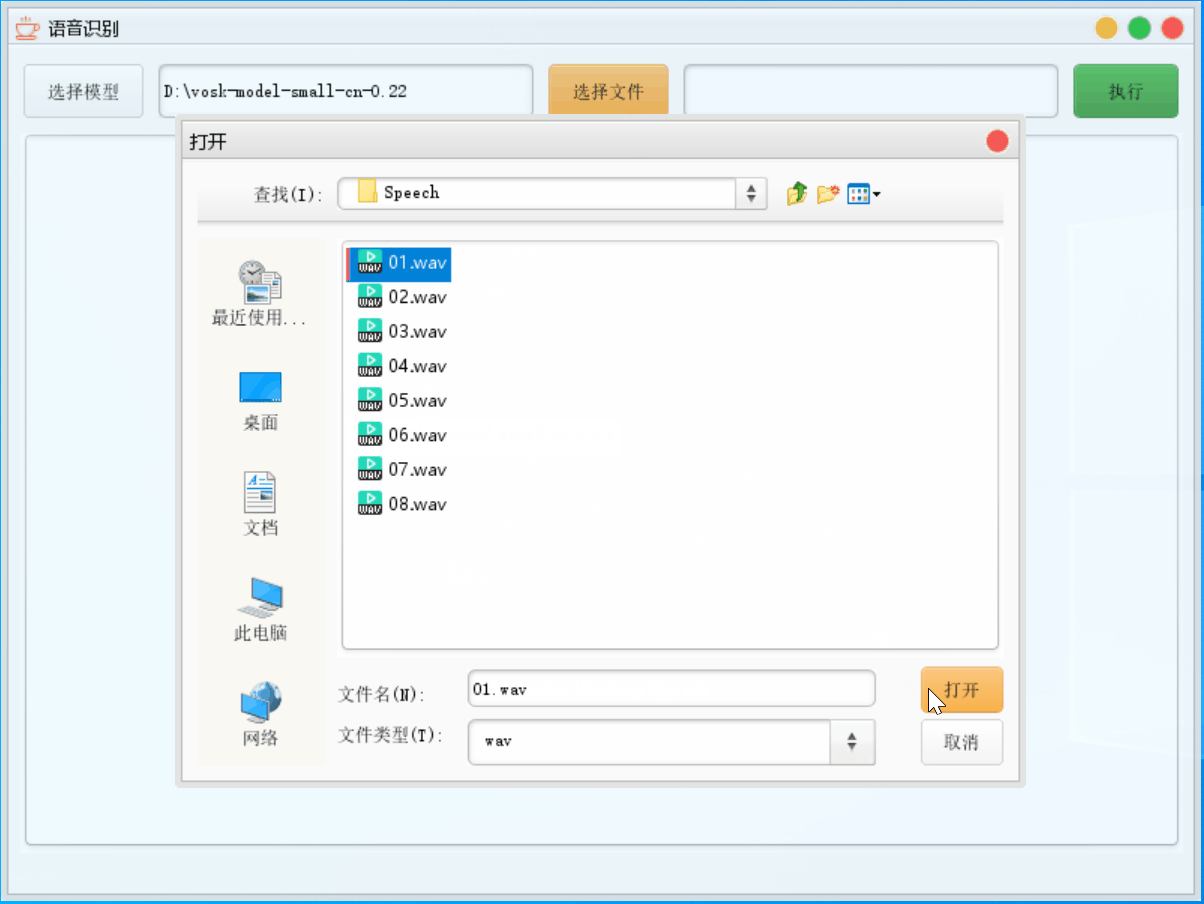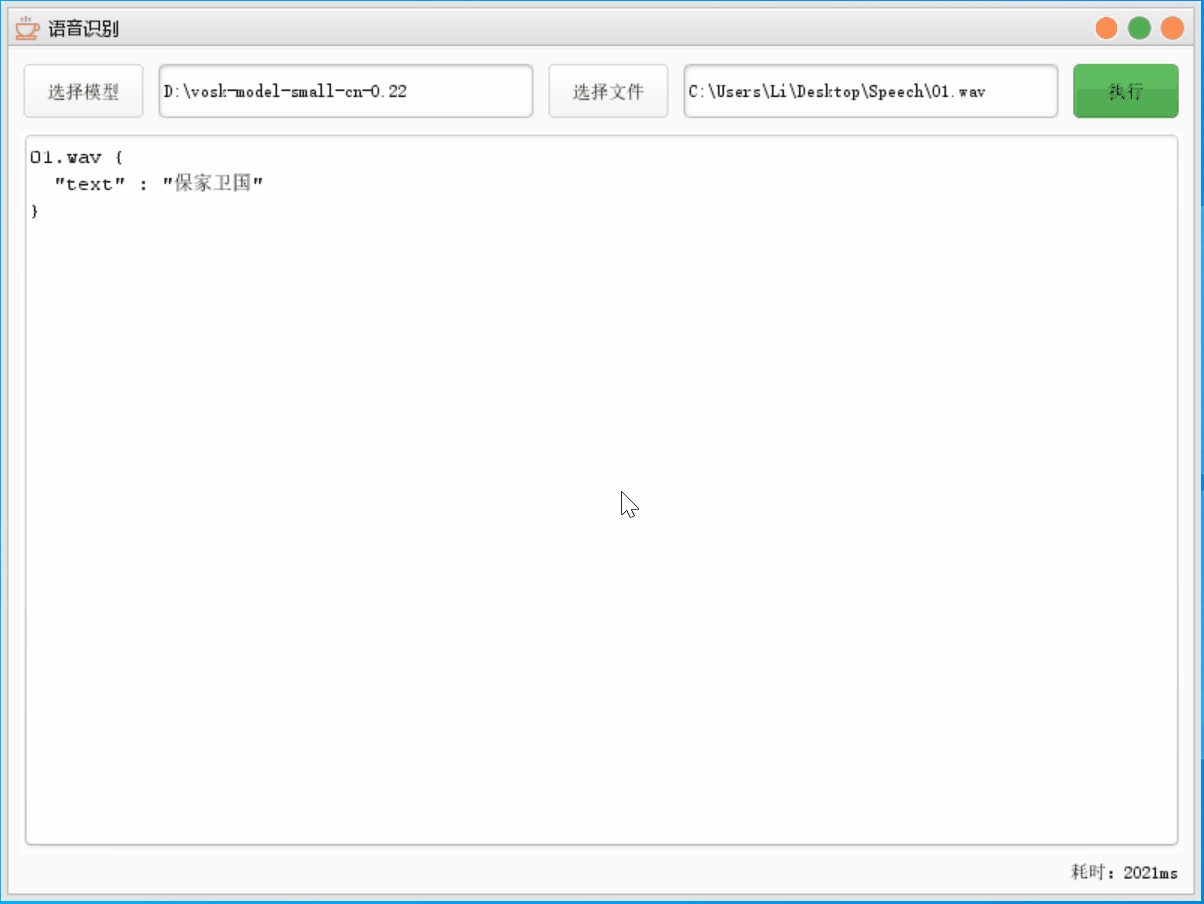
4.2.2 通用模型
这里模型替换为了通用模型,语音文件不变,然后执行
4.2.3 两者对比
这里我们可以发现同一个文件,轻量模型只用了 1/10 的时间就识别完成,且成功率均为 100%,不过这也存在这段语言比较简单的原因单个文件语音识别 轻量模型 通用模型 正确率 100% 100% 消耗时间 2021 ms 21093 ms 4.3 多个语音文件识别
4.3.1 轻量模型
这里的模型还是选择轻量模型,语音文件选择整个语音文件夹
4.3.2 通用模型
这里模型替换为了通用模型,语音文件不变,然后执行;因为这里耗费时间太长了,GIF 做了抽帧处理
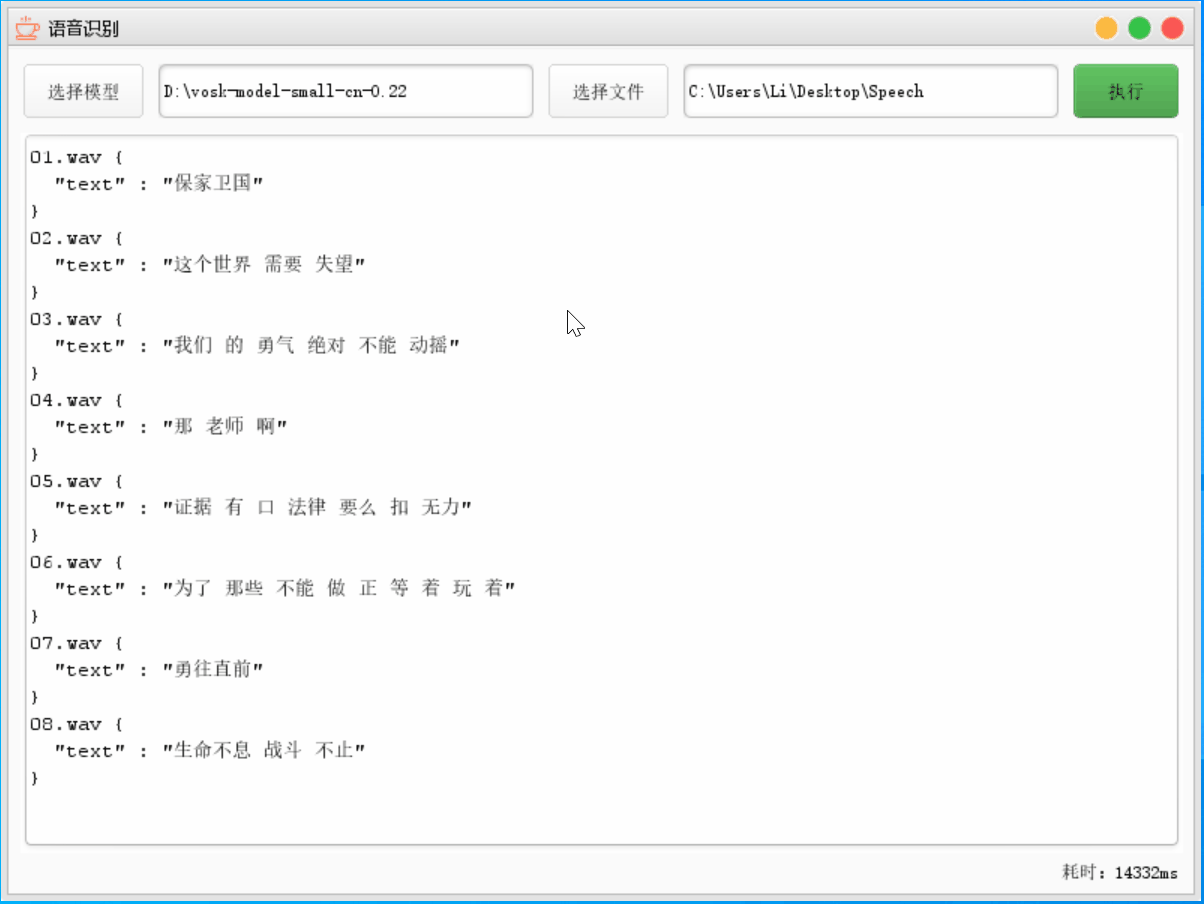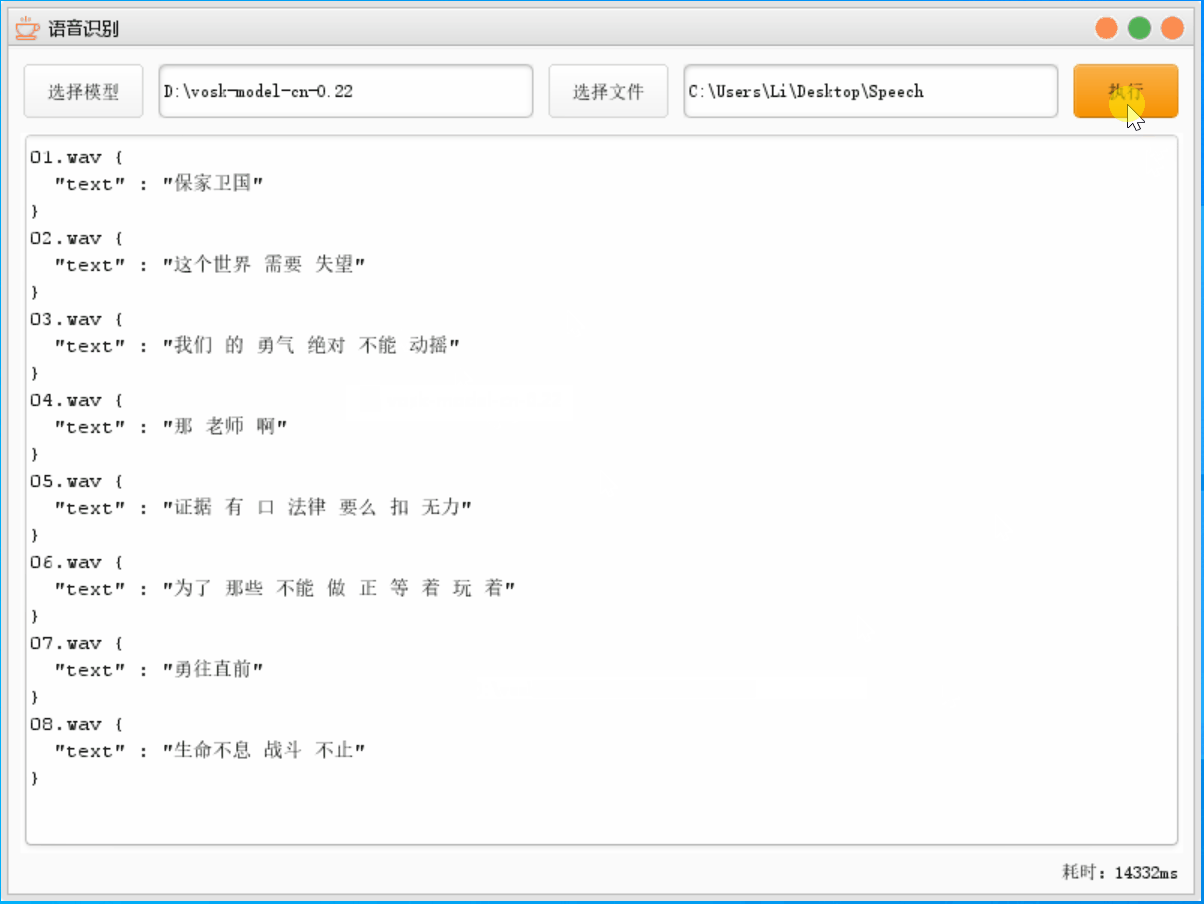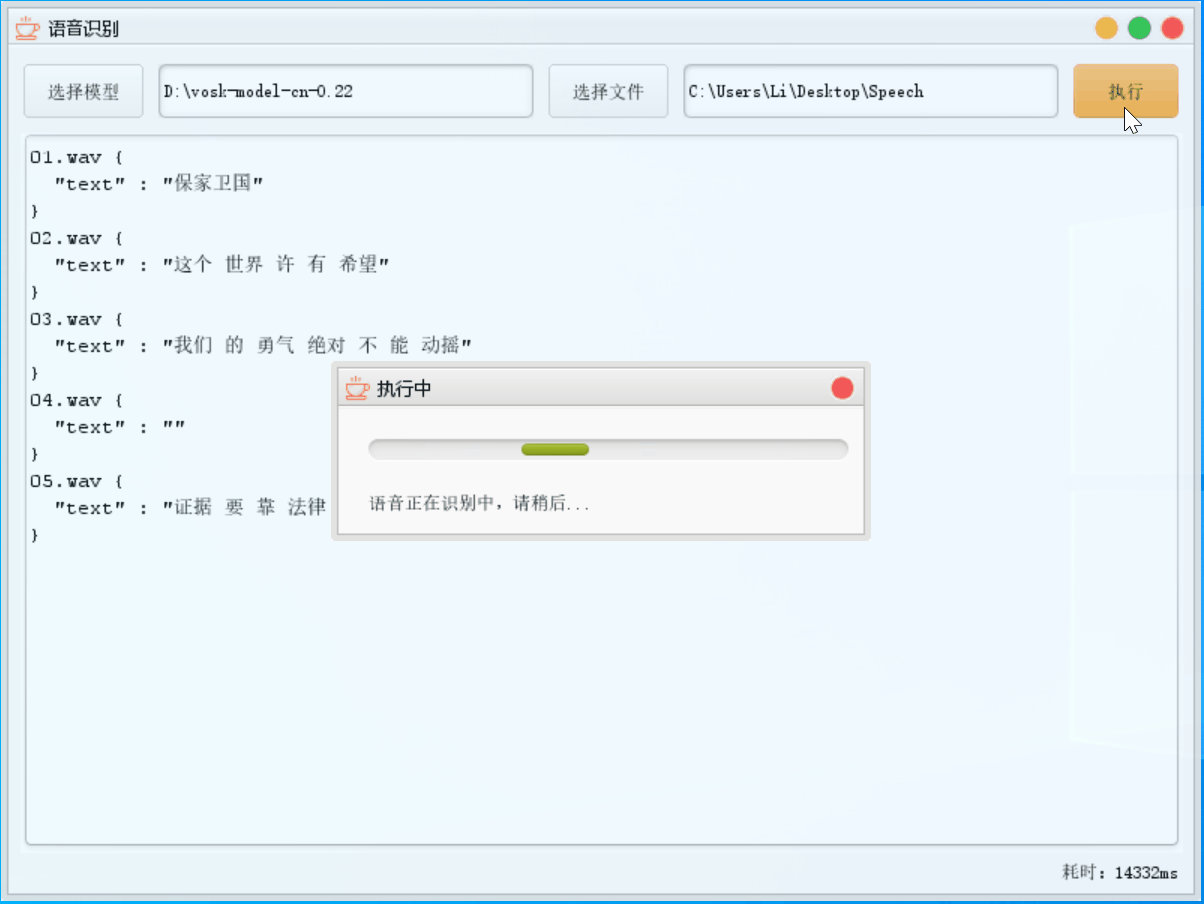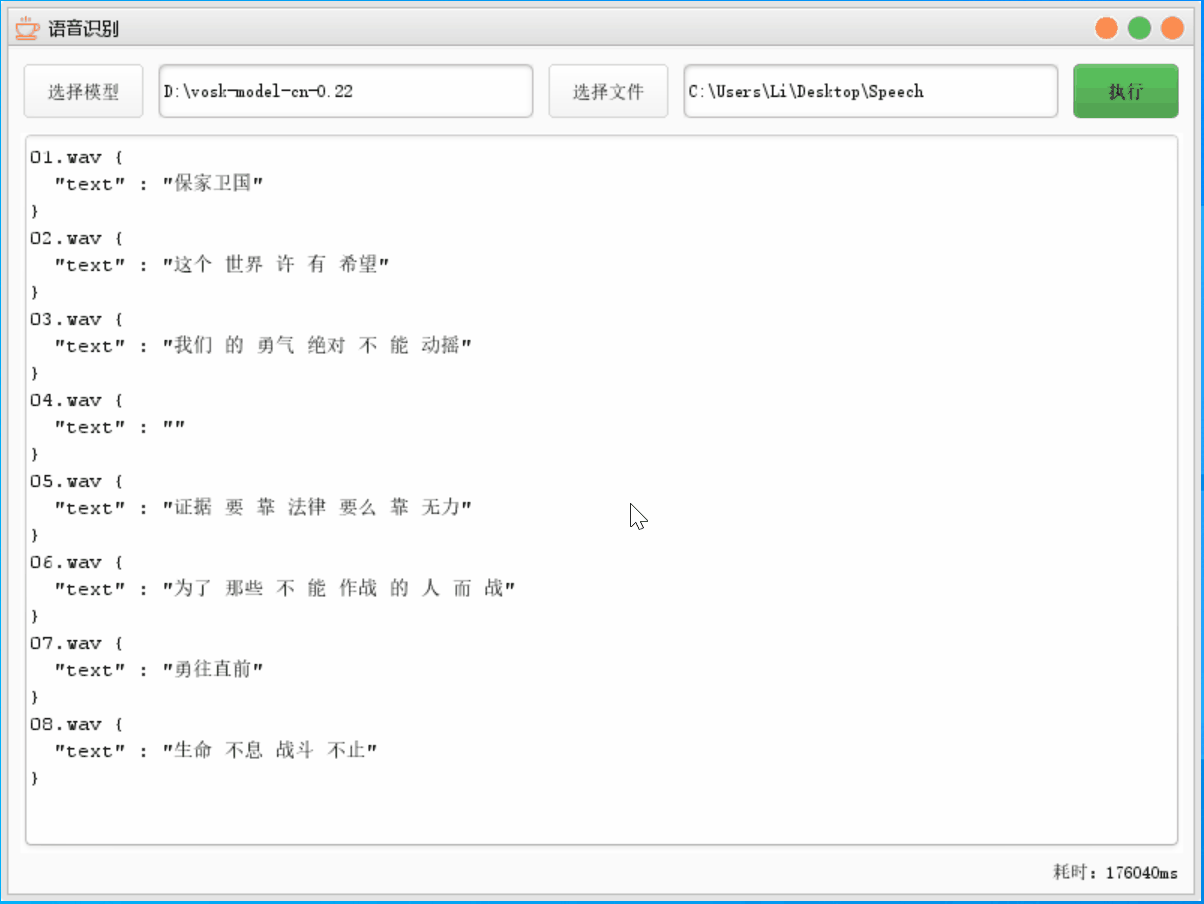
4.3.3 两者对比
这里我们可以发现同一个文件,轻量模型只用了 8% 的时间就识别完成,不过这里的正确率只有 71% 左右,通用模型的正确率却有 84% 左右,当然因为其中存在一些专有名词如德玛西亚,两次都没有识别出来多个文件语音识别 轻量模型 通用模型 正确率 71.43% 84.12% 消耗时间 14332 ms 176040 ms 5.项目总结
综合比较下来我们基本可以得出结论:如果对正确率要求没那么高的情况下,轻量模型完全符合我们的要求;而且通用模型的时间消耗确实太大了,可能需要一些方法来减少时间的消耗。
vosk-model-small-cn-0.3 Vosk是一个离线开源语音识别工具。它可以识别16种语言,包括中文。 API接口,让您可以只用几行代码,即可迅速免费调用、体验功能。 目前支持 WAV声音文件格式。 GITHUB 源码: https://github.com/alphacep/vosk-api 模型下载:https://alphacephei.com/vosk/models API调用示例文件: 包含python/nodejs/curl版本(http://www.moneymeeting.club/wp-content/uploads/2020/10/vosk.rar) 我在网页下载了好久,所以分享在这里,应该不会比那里还要慢吧最近变懒了,连做读书笔记都不想打字了,于是找了一下网上看看有木有语音转文字的工具,发现 windows 自家就有啊,但是准确率惊人啊,所以心血来潮就开搞了,这里用到了讯飞的语音转文字服务 1、到讯飞开放平台那边注册开发者账号 2、找到 “语音听写” 3、创建应用 4、填写完表单之后,会得到一个 appid 5、下载 SDK 6、下载的 SDK 一般都有三个 demo 项目,使用其中一个...java 语音转文字的依赖资源包。 使用前操作 1、把dll文件放在%JAVA_HOME%\bin下(注意系统是32位还是64位),也可以放在C:\Windows\System32下,如果是64位应该放在C:\Windows\SysWOW64 下。建议放在jdk的bin目录下 2、如果是在eclipse下开发,需要重新引入jdk(Preference/Java/Installed JREs) 3、开发时将jacab.jar包放在项目lib下并add到liabraries中即可。使用vosk开源项目,基于java实现离线语音转文字 文章目录前言一、VOSK是什么?二、使用步骤1.环境准备2.maven依赖如果导入失败可以下载jar,build path一下;3.语言模型4.运行代码总结 当前主流的语音识别大厂有科大讯飞、百度、谷歌等,但在他们官网中发现,支持java离线版的并不多,科大讯飞离线包仅基于安卓,而百度官方并没有离线版的,所以在资源查找中筛选出VOSK、CMU Sphinx,并且两者都是开源的,但CMU Sphinx官网中并没有中文模型,所以在选用上选择了VO.可以离线识别,但是暂时只有一个小的语音库,识别准确率特别低。如果谁有训练语音库的方法希望可以分享一下。谢谢!springboot框架搭的一个小demo。原文地址还有前端页面html和js,有录音,播放,翻译等小功能,详情见下边原文地址。 原文:java 离线中文语音文字识别 - Rolay - 博客园转载注明出处:https://www.cnblogs.com/rolayblog/p/15237099.html 项目需要,要实现类似小爱同学的语音控制功能,并且要离线,不能花公司一分钱。...当前主流的语音识别大厂有科大讯飞、百度、谷歌等,但在他们官网中发现,支持java离线版的并不多,科大讯飞离线包仅基于安卓,而百度官方并没有离线版的,所以在资源查找中筛选出VOSK、CMU Sphinx,并且两者都是开源的,但CMU Sphinx官网中并没有中文模型,所以在选用上选择了VOSK.Vosk是言语识别工具包。Vosk最好的事情是: 1.支持二十+种语言 - 中文,英语,印度英语,德语,法语,西班牙语,葡萄牙语,俄语,土耳其语,越南语,意大利语,荷兰人,加泰罗尼亚语,阿拉伯, 希腊语, 波斯语, 菲
推荐文章