

![[免费配音软件]语音合成,阿里云小姐姐为你配音](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
[免费配音软件]语音合成,阿里云小姐姐为你配音

@ NH4L
轻松实现语音合成,让阿里云小姐姐为你的视频配音 本次调用的是阿里云的语音合成SDK,调用接口进行语音合成。 下面来看看具体实现步骤以及两种利用python进行语音的代码。
直接查看软件更新并下载请点击下方链接
一、注册登录阿里云获取appkey
1.登入阿里云: https://www. aliyun.com/ 2.需要 实名认证 才行哟 3.点击控制台

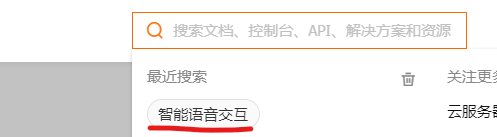
4.在搜索界面搜索 智能语音交互 ,进入智能语音交互控制台
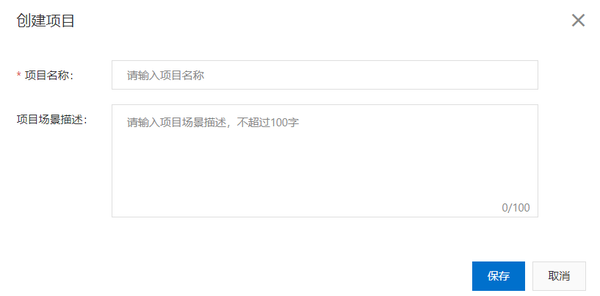
5.点击进入后点击我的项目--创建项目

6.随便输入项目名词和描述即可
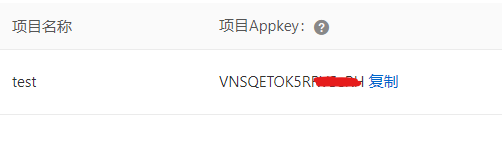
7.即可得到项目appkey
8.点击总览,点击获取AccessToken

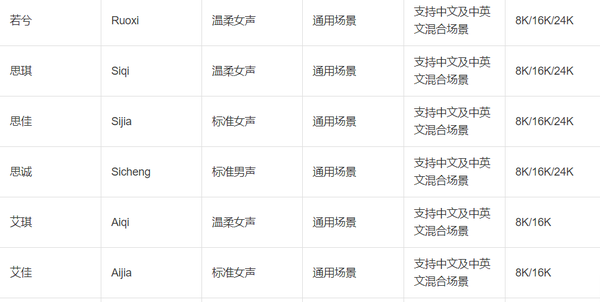
在其中还有很多音频可以试听,可以选择自己喜欢的声音。 这是语音合成的接口说明,不同的声音又不用的voice参数值。 https:// help.aliyun.com/documen t_detail/84435.html?spm=a2c4g.11186623.6.591.73831e0duk4FNT
二、普通方式获得语音合成
通过将网址放入浏览器获取语音,修改自己的appkey和accessToken和需要语音合成的语句即可。
https://nls-gateway.cn-shanghai.aliyuncs.com/stream/v1/tts?appkey=你的appkey&token=你的accesstoken&format=mp3&voice=Aixia&speech_rate=0&volume=100&text=你好呀,小姐姐下面是各个参数说明
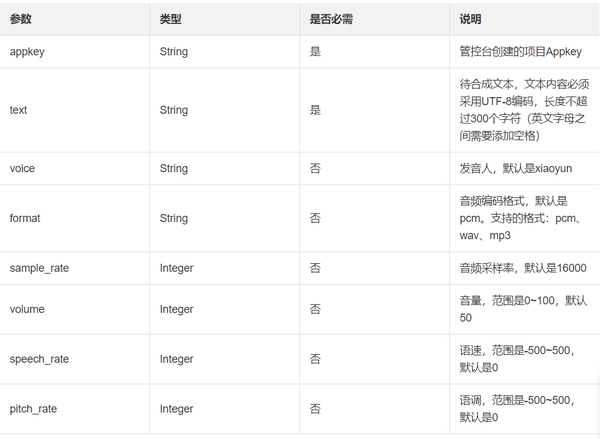
将你的语句修改即可,这种方式最多300个字符,如果需要更多的话,就需要利用python来解决了。
三、配音软件开发成功
下载地址
更新文章 https://zhuanlan.zhihu.com/p/195459302
四、利用python调用SDK进行语音合成
有两种方式
1.官方SDK
第一种是调用阿里云SDK,大家可以到 https:// help.aliyun.com/documen t_detail/120699.html?spm=a2c4g.11186623.6.594.3e86259esNOsnh 中了解详情及配制相关包。 下面铺上代码:
# -*- coding: utf-8 -*-
import threading
import ali_speech
from ali_speech.callbacks import SpeechSynthesizerCallback
from ali_speech.constant import TTSFormat
from ali_speech.constant import TTSSampleRate
class MyCallback(SpeechSynthesizerCallback):
# 参数name用于指定保存音频的文件
def __init__(self, name):
self._name = name
self._fout = open(name, 'wb')
def on_binary_data_received(self, raw):
print('MyCallback.on_binary_data_received: %s'
% len(raw))
self._fout.write(raw)
def on_completed(self, message):
print('MyCallback.OnRecognitionCompleted: %s' % message)
self._fout.close()
def on_task_failed(self, message):
print('MyCallback.OnRecognitionTaskFailed-task_id:%s, status_text:%s' % (
message['header']['task_id'], message['header']['status_text']))
self._fout.close()
def on_channel_closed(self):
print('MyCallback.OnRecognitionChannelClosed')
def process(client, appkey, token, text, audio_name, voice):
callback = MyCallback(audio_name)
synthesizer = client.create_synthesizer(callback)
synthesizer.set_appkey(appkey)
synthesizer.set_token(token)
synthesizer.set_voice(voice)
synthesizer.set_text(text)
synthesizer.set_format(TTSFormat.WAV)
synthesizer.set_sample_rate(TTSSampleRate.SAMPLE_RATE_16K)
synthesizer.set_volume(50)
synthesizer.set_speech_rate(0)
synthesizer.set_pitch_rate(0)
try:
ret = synthesizer.start()
if ret < 0:
return ret
synthesizer.wait_completed()
except Exception as e:
print(e)
finally:
synthesizer.close()
def process_multithread(client, appkey, token, number):
thread_list = []
for i in range(0, number):
text = "这是线程" + str(i) + "的合成。"
audio_name = "sy_audio_" + str(i) + ".wav"
thread = threading.Thread(target=process, args=(client, appkey, token, text, audio_name))
thread_list.append(thread)
thread.start()
for thread in thread_list:
thread.join()
if __name__ == "__main__":
client = ali_speech.NlsClient()
client.set_log_level('INFO')
voice = 'Aixia'
appkey = '你的appkey'
token = '你的token'
text = "哼!都怪你,也不哄哄人家,人家超想哭的,捶你胸口,大坏蛋!捶你胸口你好讨厌!要抱抱嘤嘤嘤哼,人家拿小拳拳捶你胸口!大坏蛋,打死你..."
audio_name = 'audio.mp3'
process(client, appkey, token, text, audio_name, voice)
# 多线程示例
# process_multithread(client, appkey, token, 2)2.访问url获取
这种方式唯一的好处就是不用安装SDK,pip中有requests即可。 这里我自己做了一个根据句号的中文字符串切割算法,限制结束符为 句号"。" ,同时一段文字只能小于300字符(免费的情况下),进行循环获取每段语音的音频文件(voice1.mp3, voice2.mp3,·····)。 代码如下:
# encoding:utf-8
import requests
from requests.exceptions import RequestException
import urllib.parse
import urllib.request
import re
import os
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"}
def request_url(url, name):
response = requests.get(url, headers=headers)
print('状态码: ' ,response.status_code)
try:
if response.status_code == 200:
download_voice(url, name)
return None
except RequestException:
return None
def download_voice(url, name):
if not os.path.exists('./audioFiles'):
os.makedirs('./audioFiles')
file_path = r'./audioFiles/{}.mp3'.format(name)
print('正在下载:', name, '.mp3\n')
urllib.request.urlretrieve(url, file_path)
logging.info(name, '.mp3下载完成!!!!!!!!!')
def not_empty(s):
return s and s.strip()
def cut_text(text, length):
text = re.sub('[\r\n\t]', '', text)
text_array = list(filter(not_empty, text.split('。')))
text_i = [0]
text_len = 0
list_1 = []
for i in range(len(text_array)):
list_1.append(i)
text_len = text_len + len(text_array[i])
# print(text_len)
if text_len > length:
text_len = 0
text_len = text_len + len(text_array[i])
# print(text_len)
text_i.append(i-1)
list_1.clear()
if text_i[-1] < (len(text_array) -1):
text_i.append(len(text_array) -1)
# print(text_i)
new_text_i = []
for i in range(len(text_i) - 1):
list1 = []
for a in range(text_i[i] + 1, text_i[i+1] + 1):
list1.append(a)
new_text_i.append(list1)
new_text_i[0].insert(0, 0)
# print(new_text_i)
new_text_array = []
for t in new_text_i:
x = ''
for t1 in range(len(t)):
x += text_array[t[t1]] + '。'
new_text_array.append(x)
return new_text_array
def get_voice(appkey, token, voice, speech_rate, format, volume, file_name, text, id):
url = 'https://nls-gateway.cn-shanghai.aliyuncs.com/stream/v1/tts?appkey=' + appkey \
+ '&token=' + token + '&format=' + format + '&voice=' + voice + '&speech_rate=' + \
str(speech_rate) + '&volume=' + str(volume) + '&text=' + text
request_url(url, file_name + str(id))
def get_network():
response = requests.get('https://www.baidu.com')
return response.status_code
def get_token_expire(appkey, token):
url = 'https://nls-gateway.cn-shanghai.aliyuncs.com/stream/v1/tts?appkey=' + appkey \
+ '&token=' + token + '&text=你好'
response = requests.get(url, headers=headers)
return response.status_code
def compose(appkey, token, voice, speech_rate, format, volume, file_name, text):
if get_network() == 200:
res = get_token_expire(appkey, token)
if res != 400:
if len(text) < 300:
get_voice(appkey, token, voice, speech_rate, format, volume, file_name, urllib.parse.quote(text), 0)
else:
text_array = cut_text(text, 300)
# print(text_array)
for id in range(len(text_array)):
get_voice(appkey, token, voice, speech_rate, format, volume, file_name, urllib.parse.quote(text_array[id]), id)
return 'success'
else:
return 'token expired'
else:
return 'network fail'
if __name__ == '__main__':
voice = 'Aixia'
appkey = 'VNSQETOK5RRVSeRH'
token = '0f3947bec58446c581dc46544bb3224e'
speech_rate = -200
format = 'mp3'