知识图谱,又称为科学知识图谱,在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
图谱共现矩阵是把数据进行整合筛选等操作后,将所要的某一列数据进行处理。这一列中出现的数据,通过矩阵的方式表示它们之间的联系。矩阵中的数字代表相关联的次数。
程序中出现的数据都是本书所给实例。
下载数据的网站[\《Python数据分析》暨南大学 王斌会](http://blog.leanote.com/DaPy)
import networkx as nx
import matplotlib.pyplot as plt
nG=nx.Graph();
一定要加前两行,要不然后面画图会显示不了中文
import pandas as pd
def list_split(content,separator):
new_list=[]
for i in range(len(content)):
new_list.append(list(filter(None,content[i].split(separator))))
return new_list
def list_replace(content,old,new):
return[content[i].replace(old,new) for i in range(len(content))]
WXdata=pd.read_excel('PyDm_data.xlsx','WXdata');
设置一个分解信息函数list_split(content,separator)和清除空格的函数list_replace(content,old,new),由于原始文本数据中含标点符号,对数据进行预处理,去掉这些干扰的东西。
def find_words(content,pattern):
return[content[i] for i in range(len(content)) if (pattern in content[i])==True]
def search_university(content,pattern):
return len([find_words(content[i],pattern) for i in range(len(content))
if find_words(content[i],pattern)!=[]])
university=pd.read_excel('PyDm_data.xlsx','university');
organ=list_split(WXdata['Organ'],';')
data1=pd.DataFrame([[i,search_university(organ,i)] for i in university['学校名称']])
keyword=list_split(WXdata['Keyword'].dropna(axis=0,how='all').tolist(),';;')
keyword1=sum(keyword,[])
author=list_replace(WXdata['Author'].dropna(axis=0,how='all').tolist(),',',';')
author1=list_split(author,';')
author2=sum(author1,[])
data1;
查找函数find_words(content,pattern)用于查找每一列中所要元素
由于后面要画三个图,分别是作者,大学和关键词,这里先提取出数据
data_author=pd.DataFrame(author2)[0].value_counts()[:30].index.tolist()
data_keyword=pd.DataFrame(keyword1)[0].value_counts()[:30].index.tolist()
data_university=data1.sort_values(by = 1,ascending=False,axis=0)[0:30][0].tolist()
data_university;
由于数据较多,这里设置一个提取高频数据的函数,只选取每一列中出现次数最多的三十个来进行研究。
```python
def occurence(data,document):
empty1=[];empty2=[];empty3=[]
for a in data:
for b in data:
count = 0
for x in document:
if [a in i for i in x].count(True)>0 and [b in i for i in x].count(True)>0:
count=count+1
empty1.append(a);empty2.append(b);empty3.append(count)
df=pd.DataFrame({'from':empty1,'to':empty2,'weight':empty3})
G=nx.from_pandas_edgelist(df,'from','to','weight')
return (nx.to_pandas_adjacency(G,dtype=int))
自定义用于画图的共现矩阵的函数 occurence(data,document)
Matrix1=occurence(data_author,author1)
Matrix1;
Matrix2=occurence(data_university,organ)
Matrix2;
Matrix3=occurence(data_keyword,keyword)
Matrix3;
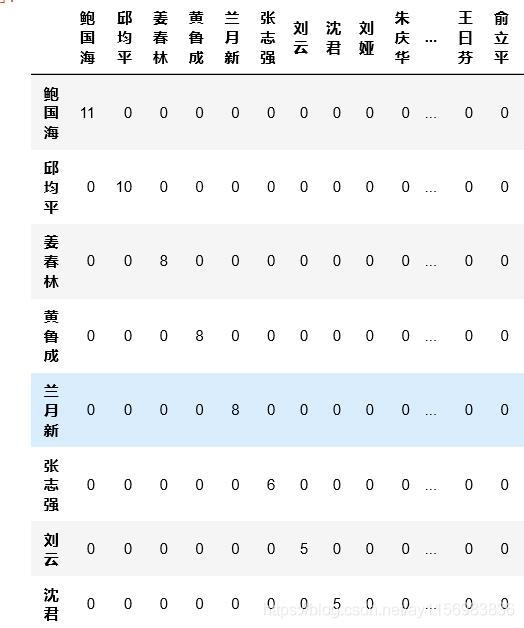
作者矩阵Matrix1的结果
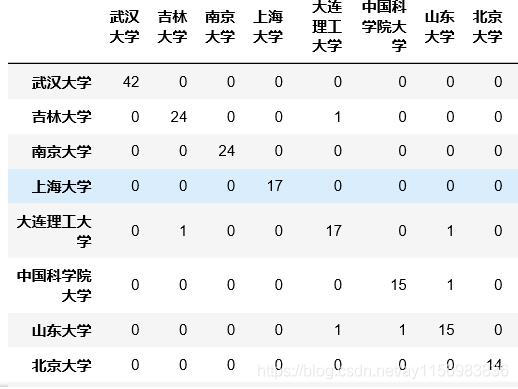
大学矩阵 Matrix2的结果
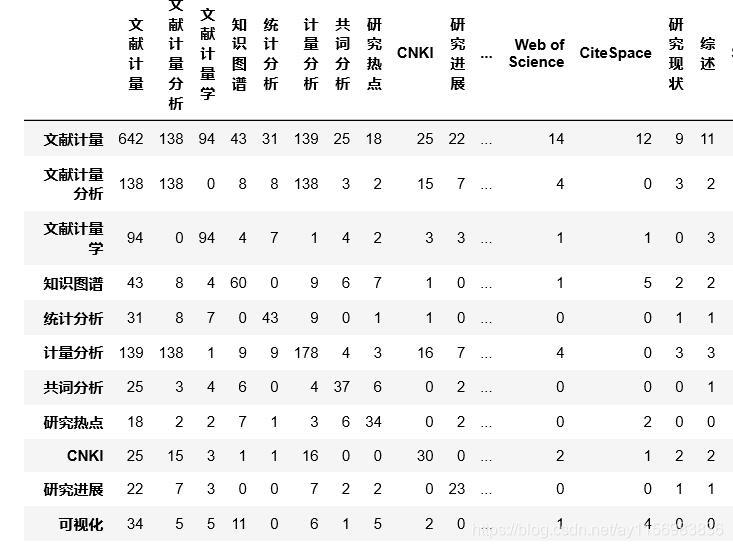
关键词矩阵 Matrix3的结果
import networkx as nx
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
nf1=nx.from_pandas_adjacency(Matrix1)
nx.draw(nf1,with_labels=True,node_color='yellow')
作者列的网络图
高频作者之间合作情况
nf2=nx.from_pandas_adjacency(Matrix2)
nx.draw(nf2,with_labels=True,node_color='yellow')

高校之间合作图谱
graph3=nx.from_pandas_adjacency(Matrix3)
nx.draw(graph3,with_labels=True,node_color='yellow')
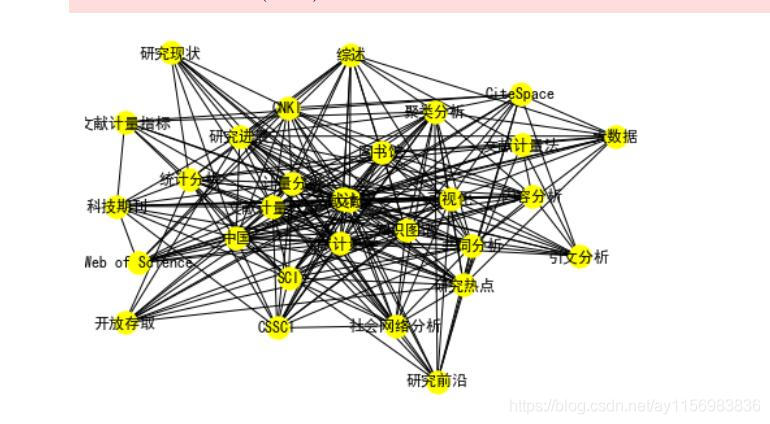
关键词知识图谱
最后,附上一些程序实现过程中参考的网站
1.入门|始于Jupyter Notebooks:一份全面的初学者实用指南http://baijiahao.baidu.com/s?id=1601883438842526311&wfr=spider&for=pc
2.Networkx参考手册 - qingqingpiaoguo的专栏 - CSDN博客
https://blog.csdn.net/qingqingpiaoguo/article/details/60570894
3.python复杂网络库networkx:绘图draw - 皮皮blog - CSDN博客
https://blog.csdn.net/pipisorry/article/details/54291831
4.Drawing — NetworkX 1.10 documentation
https://networkx.github.io/documentation/networkx-1.10/reference/drawing.html
5.《数据挖掘方法》
http://blog.leanote.com/cate/dapy/%E7%9B%AE%E5%BD%95
舆情分析;计算机;python;django;mysql;
本系统使用Python语言和MySQL数据库开发,为社会的网络管理部门提供了言论分析、言论管理、用户管理等多种功能,让用户不需要再繁琐的查看每个人的微博帐号就可以进行以自己城市或地区为关键词的言论分析和管理,在保障了网民们的隐私权和言论自由权的同时,可以最大效率地查看和本地有关的舆情或负面评论。
功能需求分析
(1)用户注册登录:用户们(这里的用户主要是社会上负责网络安全的工作人员)需要按照相关的法律法规进行注册,注册后才可以使用本系统。
(2)首页模块:网站的前台页面主要对所有菜单进行显示,除此之外还能显示最新的社会舆情信息、舆情统计图等。
(3)文本分析模块:系统具有数据分析功能,可以根据用户输入在文本框中的内容进行数据分析,还可以对负面信息进行预警。
(4)文本管理模块:可以查看所有文本的数据并进行管理。
社交网络分析和社区发现是当前很热门的话题,Python作为一种简洁、易学、功能强大的脚本语言,已成为社交网络分析和社区发现的首选工具。这个软件包提供了大量的机器学习算法和数据挖掘算法,其中包括用于社区发现的算法。Python社区发现工具可以从社交网络中提取社区结构,并帮助我们了解社交网络中的互动模式、组织结构和信息传播等方面的特征。Python社交网络分析工具的主要作用是可视化社交网络数据、分析社交网络中的关系、节点和社区的结构、探索社交网络中的重要性和连通性,并检测网络中的异常关系和异常节点。
文|邓旭东HIT今天给大家带来我一个脚本,用来分析社会网络关系。这个图我没有用到gephi或者其他的工具,是我用python纯脚本运行出来的。简单的实现了封装,大家有兴趣可以下载下脚本,运行下。原理知识我就简单说下原理吧,先刻画一个简单的图Aimport networkx as nximport matplotlib.pyplot as plt#有向图DG = nx.DiGraph()#添加一个节...
Q1:什么是网络分析(Network Analysis)?
网络分析(Network Analysis)是通过计算特征值间的相关系数,寻找变量之间的联系,以网络图或者连接模型(connection model)来展示数据的内部结构,并将显著相关的特征节点用不同粗细的线相连来表示不同变量(物种或基因等)间的相互作用关系。从而简化复杂系统并提取有用信息的一种定量分析方式。在生态学中常利用相关性来构建网络模型,可以使用一个数据集例如物种群落数据进行分析,这时候展现物种之间的共出现模式(co-occurance p
1. 创建一个图import networkx as nxg = nx.Graph()g.clear() #将图上元素清空所有的构建复杂网络图的操作基本都围绕这个g来执行。2. 节点节点的名字可以是任意数据类型的,添加一个节点是g.add_node(1)g.add_node("a")g.add_node("spam")添加一组节点,就是提前构建好了一个节点列...
import networkx as nx # 导入networkx
import matplotlib.pyplot as plt # 导入绘图工具
// 绘制社交网络图
G = nx.Graph() # 声明一个图G
//为图添加节点和边
G.add_nodes_from([1, 2, 3, 4, 5, 6, 7, 8...
中间被很多人转了,我是从机器之心公众号(almosthuman2014)看到的,最初来源应该是 Maël Fabien 大佬的博客,致谢
https://github.com/maelfabien/Machine_Learning_Tutorials
第一部分:图介绍
图是什么?
如何存储图?
图的类型和性质
Python 示例
第二部分:图算法
Pathfinding(寻路)
Community detection(社群检测)
Centrality(中心
import networkx as nx
该库是一个用python语言开发的图论与复杂网络建模工具,内置了常用的图与复杂网络分析算法,可以方便的进行复杂网络数据分析,仿真建模等工作。
在使用networkx库绘制网络图时,常用node表示节点,cycle表示环(通常环是封闭的),edges表示边。
例1:使用networkx库绘制无向网络图
from matplotlib im
在第二章介绍了 R 语言中的基本数据类型,本章会将其组装起来,构成特殊的数据结构,即向量、矩阵与列表。这些数据结构在社交网络分析中极其重要,本质上对图的分析,就是对邻接矩阵的分析,而矩阵又是由若干个向量构成,因此需要熟练掌握这些特殊的数据结构。
向量的创建
向量元素的访问
向量的运算
向量的其他常用操作
矩阵的创建
矩阵元素的访问
矩阵的运算
矩阵的特征值与特征向量
如何将存储在磁盘上的邻接矩阵输入到 R 程序中,是进行社交网络分析的起点。在前面的章节中已经介绍了基本的数据结构以及代码结构,本章将会面对一个实质性问题,学习如何导入一个图以及计算图的一些属性。
图的文件表示
导入一个图
生成人工网络
图的基本分析
图的文件表示
在计算机中,最常见的两种表示图的基本结构是邻接矩阵和邻接表。以最简单的无权无向图为例,邻接矩阵中第 \(i\) 行第 \(j\) ...
该项目是个人毕设项目,答辩评审分达到95分,代码都经过调试测试,确保可以运行!欢迎下载使用,可用于小白学习、进阶。
该资源主要针对计算机、通信、人工智能、自动化等相关专业的学生、老师或从业者下载使用,亦可作为期末课程设计、课程大作业、毕业设计等。
项目整体具有较高的学习借鉴价值!基础能力强的可以在此基础上修改调整,以实现不同的功能。
欢迎下载交流,互相学习,共同进步!
