
数据集+插件,一把子解决遮挡下目标检测难题

前言 在三维世界当中,物体之间的相互遮挡非常常见。然而,如此常见的遮挡,却仍然是机器视觉系统在场景理解时的主要障碍。本文基于VGG组最新论文 A Tri-Layer Plugin to Improve Occluded Detection,为大家带来目标检测与实例分割任务当中遮挡物问题的最新进展。
目前 MMDetection 已支持本文提出的 Occluded Detection Benchmark ,欢迎大家来试用和 PK,检验算法在遮挡情况下的鲁棒性。
本文转载自OpenMMLab
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
引言
在三维世界当中,物体之间的相互遮挡导致图像无法记录物体的全貌,是机器视觉系统在场景理解时的 主要障碍 。当前的深度学习感知算法已经取得了显著的进度,但是他们仍然无法较好地解决物体遮挡的问题。同时,当前仍缺乏 大规模的 、 涉及多种常见物体种类 的 真实遮挡数据集 ,使得我们难以评估算法在真实遮挡情况下的鲁棒性。
因此,本文提出了一套 可扩大规模(scalable) 的方法来 自动 生成这样的数据集, 定义了两大类不同的遮挡 ( 被部分遮挡 v.s. 被割裂 , partially occluded v.s. separated ),并形成了 衡量模型检测被遮挡物体性能的新的benchmark 。
使用上述生成的数据集,本文还尝试使用 三层式的分层表征 (layered representation)去 刻画物体之间的遮挡关系 ,从而让模型能够对遮挡有更好的理解,以提升其检测被遮挡物体的性能和在目标检测、实例分割任务中的总体表现。
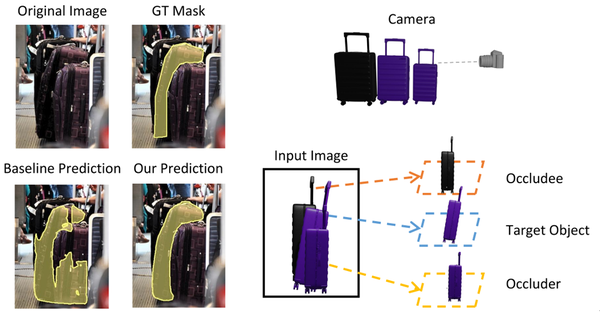
2. 数据集生成
本文一共生成了四个数据集,包括用于 测试 的 Separated COCO 和 Occluded COCO ,以及用于 训练 的 Occluder Mask 和 Occludee Mask 。四个数据集已经全部公开,Separated COCO 和 Occluded COCO 已经在 mmdet 中支持,可以在项目主页上下载这些数据集,并使用 mmdet 在 Separated COCO 和 Occluded COCO 上进行测试 。
测试数据集


Separated COCO 和 Occluded COCO 是自动生成的 COCO val 数据集的子集,收集了各种不同种类的 被割裂 和 被部分遮挡的物体 。通过这种方式,本文将 遮挡定义为两大类:被割裂的和被部分遮挡的 。
其中被割裂指的是,目标物体掩码被遮挡物分成不同的区域;而被部分遮挡指的是目标物体被部分遮挡但掩码仍保持连接。
这两种不同的遮挡,具有 不同的难度等级 。 这两个可扩大规模的真实图像数据集对模型检测 80 个常见类别的被遮挡物体的能力设置了新的 benchmark ,已经在 Paper With Code 上发布。
训练数据集


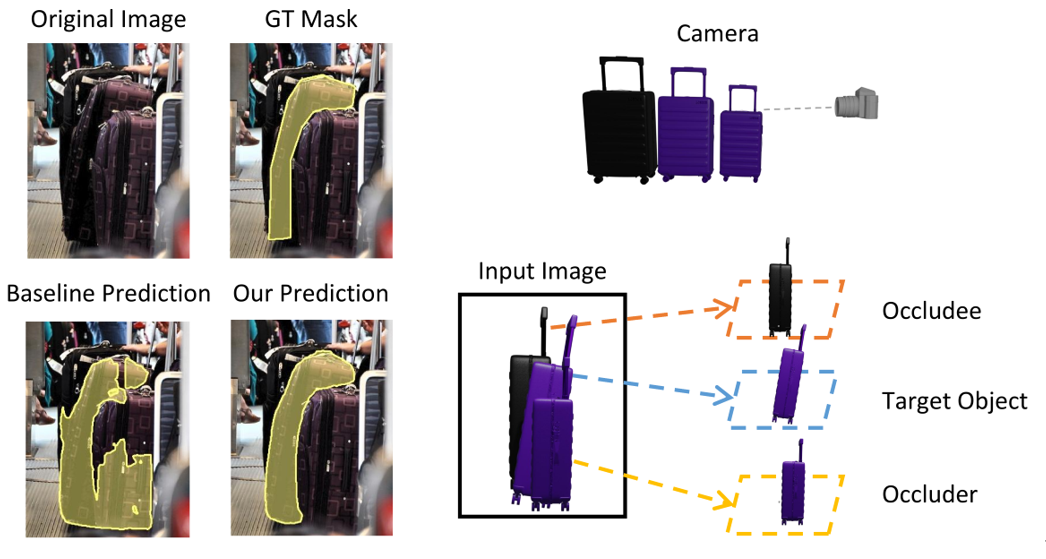
Occluder Mask 和 Occludee Mask 是用于
训练“三层”插件
的自动生成的训练数据集,对于每一个 COCO train 里面的物体,收集了其
遮挡物
(目标物体前面挡住它的物体)和
被遮挡者
(目标物体后面被它挡住的物体)。
生成方法
自动生成数据集的方法是 不完整掩码补全(amodal completion) ,加以深度估计(depth estimation)来验证不完整掩码补全的推断结果。一般认为,如果物体 A 被物体 B 遮挡,那么 A 不完整掩码补全的结果,应当与B的掩码重合,并且,通常被遮挡者(occludee)会比遮挡者(occluder)有更深的深度。
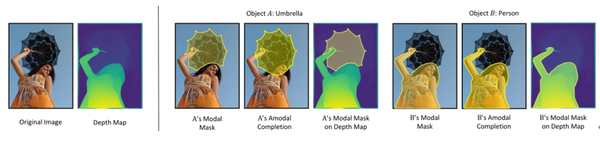
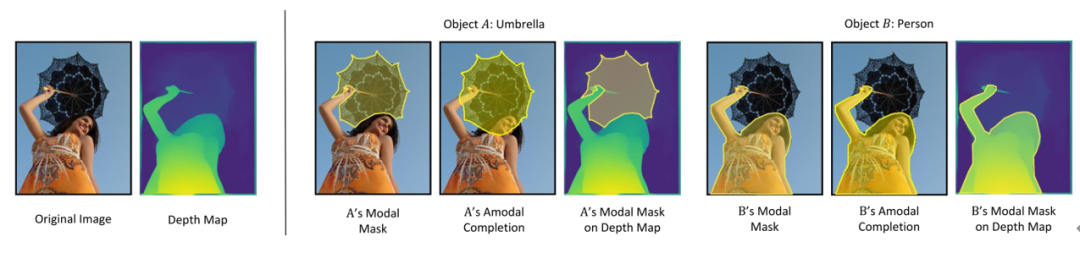
如上图所示,左边是原始图像及其深度估计图,而右边则展示了两个物体(伞和女孩)的不完整掩码补全图,以及深度估计图。
在这种情况下,可以 得出结论 ,女孩遮挡了伞,因为:(i)伞的补全掩码与女孩原来的掩码重叠,但反之则没有重叠;(ii) 平均深度图表明伞的平均深度大于女孩的平均深度。所以,可以预测“伞被女孩所遮挡”。一旦得到了遮挡关系,就很容易为测试数据集收集被遮挡的物体(Occluded COCO & Separated COCO),并为训练中的每个物体收集遮挡物(Occluder Mask)与被遮挡者(Occludee Mask)。
3. 插件架构
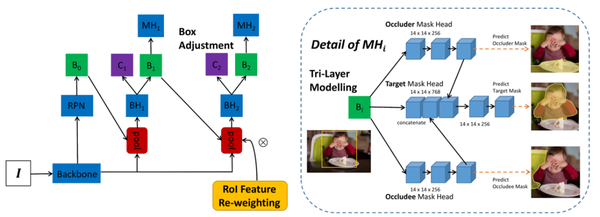
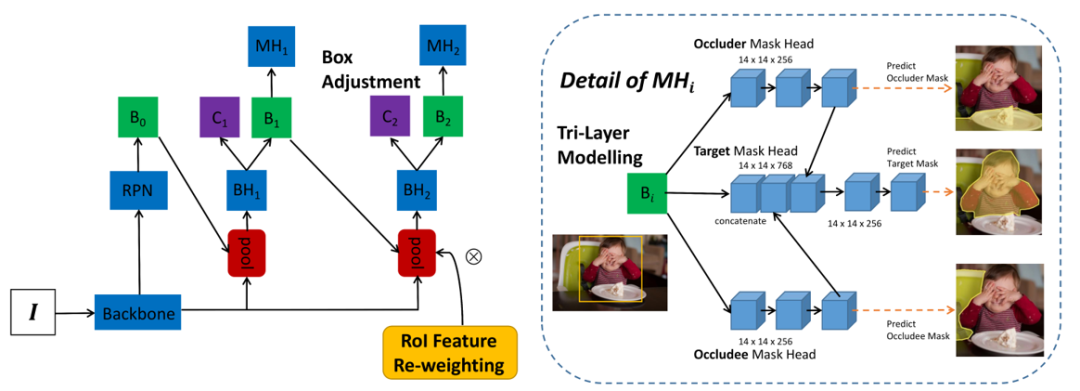
插件一共有三个模块: (a) 三层掩码预测头 (MHi 详细结构见右边)预测检测框Bi内目标物体的掩码(在脸上擦食物的婴儿)、遮挡物(餐桌)和被遮挡者(椅子)的掩码。occluder/occludee 分支的特征嵌入(embedding)作为线索连接到目标掩码嵌入,以帮助更好地预测目标物体掩码;(b) 如左图所示, 迭代预测目标 mask 的过程(索引 i ),使得第二次迭代能够调整初始预测框并更好地检测被部分遮挡/割裂的对象;(c) 第一次迭代后, 根据预测的目标掩码对 RoI 特征进行池化 ,以引导模型更多地关注被部分遮挡/割裂的物体本身。使用的符号是:“I”表示输入图像,“BH”、“MH”、“B”、“C”分别指 bbox head、mask head、bounding box 和 classification。
4. 实验结果
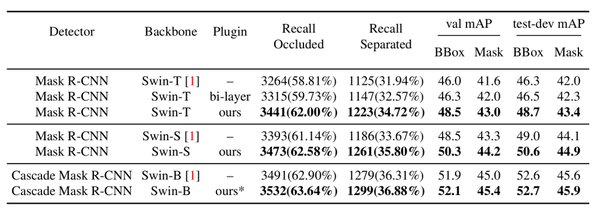
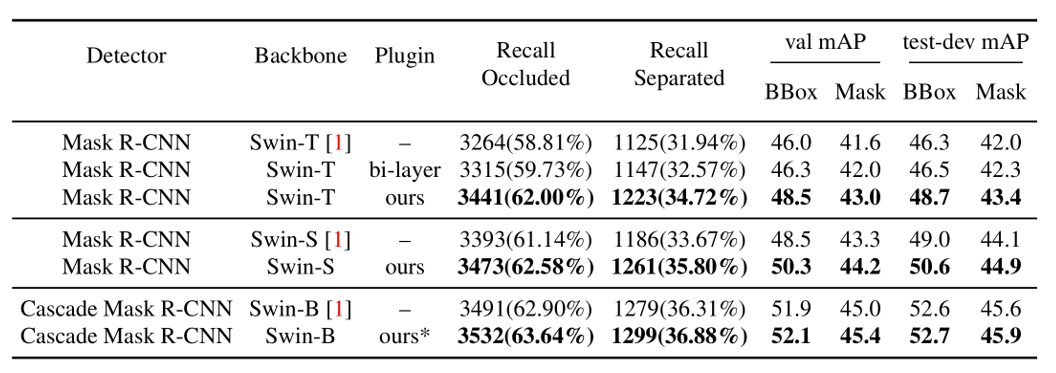
* 仅应用了三层建模,因为 Cascade Mask R-CNN 已经使用了多次迭代。
与不同架构上的 state-of-the-art 进行比较 可见,该插件提高了所有架构的性能,即使是最强的检测器(Swin-B + Cascade Mask R-CNN)。


COCO val 上的定性结果 可以看出,基线模型在具有挑战性的遮挡情况下往往会失败,要么 过度分割(over-segmentation) 被部分遮挡的物体(第 1 行),要么对被割裂的(第 2 行)物体 分割不足(under-segmentation) 。本文提出的插件在很大程度上改进了对被遮挡物体的检测,例如,消除泰迪熊的歧义(第 1 行),并推断出被狗严重遮挡而割裂的椅子(第 2 行)。有关更多示例,请参见论文原文附录。
详细信息可见
项目主页
https://www. robots.ox.ac.uk/~vgg/re search/tpod/
论文链接
https:// arxiv.org/abs/2210.1004 6
代码仓库
https:// github.com/Championches s/Tri-Layer_Plugin_Occluded_Detection
MMDet 中的 Occluded Benchmark
https://
mmdetection.readthedocs.io
/en/dev/useful_tools.html#coco-separated-occluded-mask-metric
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效
消费级显卡的春天,GTX 3090 YOLOv5s单卡完整训练COCO数据集缩短11.35个小时 一层卷积能做啥?
原来Transformer就是一种图神经网络,这个概念你清楚吗?
TensorFlow 真的要被 PyTorch 比下去了吗?