


关联规则之Aprior算法与python实现

Aprior算法为经典的关联规则算法,主要思想是通过计算历史数据统计不同规则出现的频率与先后关系,来进行关联规则的识别。
其主要思想为:
- 找出顾客购买记录数据集中的频繁项集,频繁项集满足大于等于最小支持度;
- 根据频繁项集产生强关联规则,关联规则必须满足最小支持度和最小置信度的要求;
以上两条条件缺一不可。
其中所提到的支持度与置信度的计算方式如下:
若存在规则X -> Y,则代表顾客购买X商品以后会购买Y商品,此时的支持度与置信度:
Support(X \rightarrow Y)=\frac{同时包含XY数据数}{数据总数}
Confidence(X\rightarrow Y)=\frac{同时包含XY的数据数}{包含X的数据数}
通过定义支持度与置信度,可以人为规定 最小支持度 与 最小置信度 ,以得到最终的关联规则项集。
此外,还有 “提升度”、“杠杆率”与“确信度” 三种衡量关联规则关系的标准。
lift(X\rightarrow Y)=\frac{support(X\cap Y)}{Support(X)*Support(Y)}=\frac{\frac{同时包含XY的数据数}{数据总数}}{\frac{包含X的数据数}{数据总数}\frac{包含Y的数据数}{数据总数}}
leverage(X\rightarrow Y)=Support(X \rightarrow Y)-Support(X)*Support(Y)=\frac{同时包含XY的总数}{数据总数}-\frac{包含X的总数}{数据总数}*\frac{包含Y的总数}{数据总数}
Conviction(X\rightarrow Y)=\frac{1-Support(Y)}{1-Confidence(X\rightarrow Y)}=\frac{1-\frac{包含Y的数量}{数据总数}}{1-\frac{同时包含XY的数量}{包含X的数量}}
提升度left一般大于1才认为有效,确信度conviction越大,先导项与后继项的关联性越强。
以上三个指标越大,关联强度越大。
下面将使用Python实现Aprior算法。
import numpy as np
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
shopping_list = [['大豆','白菜'],
['白菜','尿布','葡萄酒','甜瓜'],
['大豆','尿布','葡萄酒','橙汁'],
['白菜','大豆','尿布','葡萄酒'],
['白菜','大豆','尿布','橙汁']]
# 转换成数据框
shopping_df = pd.DataFrame(shopping_list)
# 定义将DataFrame恢复为原始ndarray的函数
def deal(data):
return data.dropna().tolist()
df_arr = shopping_df.apply(deal,axis=1,).tolist()
# 购物编码器
te = TransactionEncoder()
df_tf = te.fit_transform(df_arr)
df = pd.DataFrame(df_tf,columns=te.columns_)
df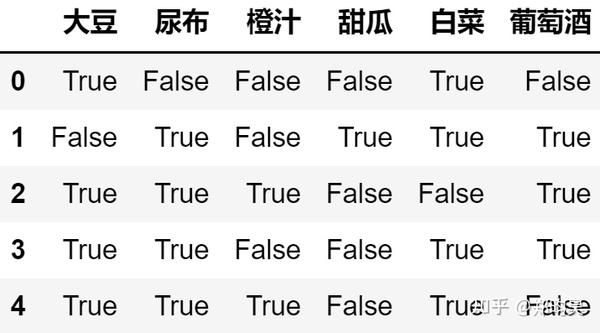

# 求频繁项集
from mlxtend.frequent_patterns import apriori
frequent_itemsets = apriori(df,min_support=0.05,use_colnames=True) # 定义最小支持度为0.05
frequent_itemsets.sort_values(by='support',ascending=False,inplace=True)