转载自:机器之心 | 编辑:泽南
视觉模型有很大的提升空间,研究者们在以往的 LLM 中学到经验教训,认为扩展是一个很有前途的方法。来自谷歌的研究者将 ViT 扩展到 22B 参数量,这是迄今为止报道的最大的视觉主干。
与自然语言处理类似,对预训练视觉主干的迁移提高了模型在各种视觉任务上的性能。更大的数据集、可扩展的架构和新的训练方法都推动了模型性能的提升。
然而,视觉模型仍然远远落后于语言模型。具体来说,迄今为止最大的视觉模型 ViT 只有 4B 参数,而入门级语言模型通常超过 10B 参数,更别说具有 540B 参数的大型语言模型。
为了探索 AI 模型的性能极限,Google Research 最近在 CV 领域的一项研究,率先将 Vision Transformer 参数量扩展到了 22B,提出 ViT-22B,与之前类似的模型参数量 4B 相比,可以说这是迄今为止最大的稠密型 ViT 模型。
Scaling Vision Transformers to 22 Billion Parameters
论文:https://arxiv.org/abs/2302.05442
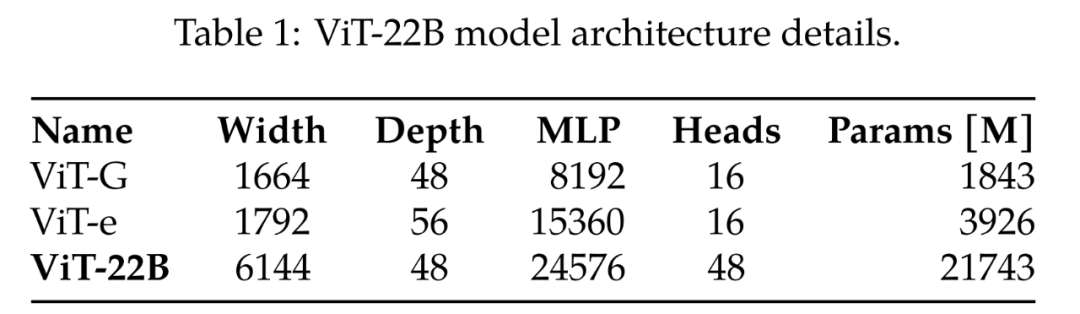
对比之前最大的 ViT- G 和 ViT-e,表 1 给出了比较结果,由下表可得,ViT-22B 主要是扩展了模型的宽度,使得参数量更大,深度和 ViT-G 一样。
 当前的 ViT 大模型
当前的 ViT 大模型
正如这位知乎网友所说,难道是谷歌在 ChatGPT 上输了一局,势必要在 CV 领域争口气?
如何做到的?原来研究早期,他们发现在扩展 ViT 的过程中,出现了训练不稳定性,并且可能会带来架构变化。然后研究人员仔细设计模型,并且以前所未有的效率来实现模型并行训练。ViT-22B 的质量是通过一套全面的任务来评估的,从(少样本)分类到密集输出任务,在这些任务中,它达到或超过了当前 SOTA 水平。例如,即使用作冻结的视觉特征提取器,ViT-22B 在 ImageNet 上的准确率也达到了 89.5%。通过训练 text tower 来匹配这些视觉特征,它在 ImageNet 上实现了 85.9% 的零样本设置准确率。此外,该模型可以看作是一个教师,用作蒸馏目标,研究人员训练了一个 ViT-B 学生模型,在 ImageNet 上的准确率为 88.6%,达到了此类规模模型上 SOTA 水平。
ViT-22B 是一种基于 Transformer 的编码器模型,类似于原始 Vision Transformer 架构,但包含以下三个主要修改,以提高效率和大规模训练的稳定性:并行层、查询 / 键(QK)归一化和 omitted biases。
并行层。正如 Wang 和 Komatsuzaki 研究所述,该研究设计了一个 Attention 和 MLP 并行结构:
这可以通过组合 MLP 和注意力块的线性投影来实现额外的并行化。值得注意的是,用于查询 / 键 / 值投影的矩阵乘法和 MLP 的第一线性层被融合到一个单独的操作中,对于 MLP 的注意力外投影和第二层线性层也是如此。
QK 归一化。训练大模型的一个困难是模型的稳定性,在将 ViT 扩展的过程中,研究人员发现在几千轮的 step 后训练损失呈发散性。特别是在 8B 参数的模型中这种现象尤为突出。为了稳定模型训练,研究人员采用 Gilmer 等人的方法,在点积注意力计算之前对查询和键应用 LayerNorm 归一化操作,以提升训练的稳定性。具体来说,注意力权重计算为:
omitted biases。在 PaLM 之后,偏置项从 QKV 投影中移除,并且所有的 Layernorm 都在没有偏置的情况下应用,从而提高了加速器的利用率 (3%),且质量没有下降。然而,与 PaLM 不同的是,研究人员对 MLP 密集层使用了偏置项,即便如此,这种方式在兼顾质量的同时,速度没有下降。
图 2 展示了一个 ViT-22B 编码器块。嵌入层在原有 ViT 的基础上进行了 patch 提取、线性投影和添加位置嵌入等操作。研究人员使用多头注意力池化来聚合头中的每个 token 表示。
ViT-22B 使用 14 × 14 的 patch,图像分辨率为 224 × 224。ViT-22B 采用了一种学习到的一维位置嵌入。在对高分辨率图像进行微调期间,研究人员根据预训练的位置嵌入在原始图像中的位置执行二维插值。
训练基础设施与效率
ViT-22B 使用 FLAX 库,实现方式是 JAX,并在 Scenic 中构建。它同时利用了模型和数据并行性。值得一提的是,研究人员使用了 jax. xmap API,它提供了对所有中间体的分片(例如权重和激活)以及芯片间通信的显式控制。研究人员将芯片组织成大小为 t × k 的 2D 逻辑网格,其中 t 是数据平行轴的大小,k 是模型轴的大小。然后,对于 t 组中的每个组,k 个设备获得相同批次的图像,每个设备只保留 1/k 的激活,并负责计算所有线性层输出的 1/k(详细内容如下)。
图 3:异步并行线性操作(y = Ax):跨设备的重叠通信和计算的模型并行矩阵乘法。
异步并行线性操作。为了最大限度地提高吞吐量,必须考虑计算和通信。也就是说,如果希望这些操作在分析上等效于未分片的情况,就必须尽可能少地进行通信,理想情况下让它们重叠,这样就可以保持矩阵乘法单元(FLOP 的大部分容量所在)始终处于繁忙状态。
参数分片。该模型在第一个轴上是数据并行的。每个参数可以在这个轴上完全复制,也可以让每个设备保存它的一个块。研究人员选择从模型参数中分割一些大张量,以便能够拟合更大的模型和批量大小。
使用这些技术,ViT-22B 在 TPUv4 上训练期间,每个核每秒处理 1.15k token。ViT-22B 的模型 flops 利用率(MFU)为 54.9%,表明硬件的使用非常有效。请注意,PaLM 报告的 MFU 为 46.2%,而研究人员在相同硬件上为 ViT-e(仅数据并行)测量的 MFU 为 44.0%。
实验探究了 ViT-22B 用于图像分类的评估结果。
表 2 结果显示,ViT-22B 在各种指标上仍有显著的改善。此外,研究表明,像 ViT-22B 这样的大型模型的 Linear probing 可以接近或超过具有高分辨率的小型模型的 full fine-tuning 性能,通常成本更小、更容易做到。
研究进一步在细粒度分类数据集 iNaturalist 2017 上测试线性可分离性,将 ViT-22B 与其他 ViT 变体进行比较。研究测试了 224px 和 384px 的输入分辨率。结果如图 4。研究观察到 ViT-22B 明显优于其他 ViT 变体,特别是在标准的 224px 输入分辨率下。这表明 ViT-22B 中大量的参数对于从图像中提取详细信息是有用的。
表 3 显示了 ViT-22B 对 CLIP、ALIGN、BASIC、CoCa、LiT 模型的零样本迁移结果。表 3 底部比较了三个 ViT 模型性能。
在所有的 ImageNet 测试集中,ViT-22B 取得了相当或更好的结果。值得注意的是,ObjectNet 测试集上的零样本结果与 ViT 模型大小高度相关。最大的 ViT-22B 将新的 SOTA 设置在具有挑战性的 ObjectNet 测试集中。
Out-of-distribution (OOD)。研究构建了一个从 JFT 到 ImageNet 的标签映射,以及从 ImageNet 到不同分布外数据集的标签映射,即 ObjectNet、ImageNet-v2、ImageNet- R 和 ImageNet- A。
目前可以确认的结果是,与 ImageNet 上的改进一致,扩展模型增加了分布外性能。这适用于只看过 JFT 图像的模型,以及在 ImageNet 上进行微调的模型。在这两种情况下,ViT-22B 在更大的模型上都延续了 OOD 性能更好的趋势(图 5,表 11)。
此外,研究人员还研究了 ViT-22B 模型在语义分割和单目深度估计任务中捕获的几何和空间信息质量。
语义分割。研究人员在三个基准上评估 ViT-22B 作为语义分割主干:ADE20K、Pascal Context 和 Pascal VOC。从表 4 可以看出,当只看到少量分割掩码时,ViT-22B 主干迁移效果更好。
单目深度估计。表 5 总结了研究的主要发现。从最上面的行(DPT 解码器)中可以观察到,与不同的主干相比,使用 ViT-22B 特性产生了最好的性能(在所有指标上)。通过将 ViT-22B 主干与 ViT-e(一个较小的模型,但在与 ViT-22B 相同的数据上进行训练)进行比较,研究发现扩展架构可以提高性能。
此外,将 ViT-e 主干与 ViT-L(与 ViT-e 类似的架构,但训练的数据更少)进行比较,研究发现这些改进也来自于扩展训练前的数据。这些发现表明,更大的模型和更大的数据集都有助于提高性能。
该研究还在视频数据集上进行了探索。表 6 展示了在 Kinetics 400 和 Moments in Time 数据集上的视频分类结果,表明可以使用冻结的主干实现具有竞争力的结果。研究首先与 ViT-e 进行比较,ViT-e 拥有最大的先验视觉主干模型,由 40 亿个参数组成,并且也在 JFT 数据集上进行训练。我们观察到更大的 ViT-22B 模型在 Kinetics 400 上提高了 1.5 分,在 Moments in Time 上提高了 1.3 分。
最后研究注意到,通过完整的端到端微调,还有进一步改进的空间。
更多技术细节请参阅原论文。
参考链接:https://www.zhihu.com/question/583748997
点击进入—>
CV微信技术交流群
CVPR/ECCV 2022论文和代码下载
后台回复:
CVPR2022,
即可下载CVPR 2022论文和代码开源的论文合集
后台回复:ECCV2022,即可下载ECCV 2022论文和代码开源的论文合集
后台回复:
Transformer综述,
即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
原文链接:
https://mp.weixin.qq.com/s?__biz=MzUxNjcxMjQxNg==&mid=2247569384&idx=2&sn=21685f844719f6942b84e1527885c614&chksm=f9a0bd67ced73471e5f8fda713f610a0cd985bf821e217bd276fe22075618fda8e2002803279&scene=126&sessionid=0
from
vit
_grad_rollout import
VIT
AttentionGradRollout
model = torch . hub . load ( 'facebookresearch/deit:main' ,
'deit_tiny_patch16_224' , pretrained = True )
grad_rollout =
VIT
AttentionGradRollout ( model , discard_ratio = 0
端到端存储网络[NIPS 2015] [] []
注意就是您所需要的[NIPS 2017] [] []
乙idirectionalËncod
er
ř对产权在T ransform
er
s:B
ER
T [] [] []
改革者:高效变压器[ICLR2020] [] []
Linform
er
:具有线性复杂度的自我注意[AAAI2020] [] []
图像价值16x16字:用于图像识别的变压器[
VIT
] [ICLR 2021] [] []
DeiT:数据高效的图像变压器[arxiv2021] [] []
DETR:使用变压器进行端到端对象检测[ECCV2020] [] []
可变形DETR:用于端到端对象检测的可变形变压器[ICLR2021] [] []
SETR:使用变压器从序列到序
(arXiv 2021.03)使用堆叠式变压器的多模式运动预测。 ,
(arXiv 2021.03)具有语言和
视觉
的跨模态任务的变压器体系结构的观点和前景。
(arXiv 2020.9)高效变压器:调查。
(arXiv 2020.1)
视觉
中的变形金刚:调查。
最近的论文
(CVPR'20)Speech2Action:动作识别的跨模式监督,
(arXiv 2021.01)Trear:基于变压器的RGB-D自我中心动作识别,
(arXiv 2021.02)用于直接行动提案生成的宽松的变压器解
视觉
变压器的Pytorch实现。 提供了预先训练的pytorch权重,这些权重是从原始jax /亚麻权重转换而来的。 这是和的项目。
Pytorch实施的论文 。 我们提供从预训练的jax /亚麻模型转换而来的预训练的pytorch权重。 我们还提供微调和评估脚本。 获得了与类似的结果。
创建环境:
conda create --name
vit
--file requirements.txt
conda activate
vit
我们提供,这些是从原始jax / flax wieghts转换而来的。 您可以下载它们并将文件放在“ weights / pytorch”下以使用它们。
否则,您可以下载,并将这些帧放在“ weights / jax”下以使用它们。 我们将在线为您转换权重。
当前支持三个数据集:ImageNet2012,CI
作者丨科技猛兽 编辑丨极市平台导读本文
提出
了迄今为止
最大
的密集
视觉
ViT
模型
ViT
-
22B
,具有
220
亿
参数
。并发现超大
ViT
病态训练的不稳定性,这种不稳定性组织了模型尺度的进一步
扩展
。作者通过仔细设计模型,以较高的效率实现模型并行训练。本文目录52
扩展
到
220
亿
参数
的巨大
视觉
Transform
er
(来自
谷歌
,含
ViT
作者)52
ViT
-
22B
论文解读52.1 背景...
标题:心理理论可能自发地出现在大型语言模型中作者:Michal Kosinski文章链接:https://arxiv.org/abs/2302.02083 心理理论 (ToM),或将不可观察的心理状态归因于他人的能力,是人类社会互动、沟通、同理心、自我意识和道德的核心。我们在没有任何示例或预训练的情况下,对多种语言模型执行广泛用于测试人类 ToM 的经典错误信念任务。我们的结果表明,2022 年之前发布的模型几乎没有能力解决 ToM 任务。然而,2022 年 1 月版本的 GPT-3(davi
本文
提出
了迄今为止
最大
的密集
视觉
ViT
模型
ViT
-
22B
,具有
220
亿
参数
。并发现超大
ViT
病态训练的不稳定性,这种不稳定性组织了模型尺度的进一步
扩展
。作者通过仔细设计模型,以较高的效率实现模型并行训练。
本文改进了
ViT
的架构和训练,减少了内存消耗并提高了模型的准确性!最终成功训练了一个具有20
亿
参数
的
ViT
模型:
ViT
-G,在ImageNet上达到了90.45%的 top-1准确率。
注1:文末附【
视觉
Transform
er
】交流群
想看更多CVPR 2021论文和开源项目可以点击:
CVPR2021-Pap
er
s-with-Code
ViT
-G
Scaling Vision
Transform
er
s
作者单位:
谷歌
大脑(苏黎世),有原
ViT
一作和二作
论文:https://arxiv.org/a
1, TITLE:A Machine Learning Pipeline for Aiding School Identification from Child Trafficking Images
AUTHORS: SUMIT MUKHE...
太长不看版
Vision
Transform
er
将CV和NLP领域知识结合起来,对原始图片进行分块,展平成序列,输入进原始
Transform
er
模型的编码器Encod
er
部分,最后接入一个全连接层对图片进行分类。在大型数据集上表现超过了当前SOTA模型
当前
Transform
er
模型被大量应用在NLP自然语言处理当中,而在计算机
视觉
领域,
Transform
er
的注意力机制attention也被广泛应用,比如Se模块,CBAM模块等等注意力模块,这些注意力模块能够帮助提升网络性能。而我们的工作展示了不需
ViT
(Vision
Transform
er
)论文笔记
(AN IMAGE IS WORTH 16X16 WORDS:
TRANSFORM
ER
S FOR IMAGE RECOGNITION AT SCALE)
Abstact
虽然
Transform
er
架构已经成为自然语言处理任务的事实标准,但它在计算机
视觉
中的应用仍然有限。在
视觉
中,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件(替换CNN模型的一部分),同时保持其整体结构。我们表明,这种对CNN的依赖是不必要的,直接应用于图像块序列的 pu

