[1.7、中国互联网信息中心](#6619-1609601548665)
[2、ICP(Internet Content Provider)备案查询](#1070-1609150295487)
[2.1、国家企业信用信息公示系统](#4328-1608957113762)
[2.2、ICP备案查询网](#2762-1608957274017)
[2.3、ICP备案查询 - 站长工具](#7362-1608957345470)
[2.4、天眼查](#7985-1608957511174)
[2.5、企查查](#5774-1608957266603)
[3、SEO(Search Engine Optimization)查询](#2641-1608957035834)
[3.1、爱站-SEO综合查询](#4489-1608958353806)
[3.2、站长-SEO综合查询](#2085-1608958243261)
[4、历史漏洞](#4377-1608958615406)
[4.1、乌云漏洞库](#4549-1608994973094)
[5、Google Hacking](#6739-1608994952697)
[5.1、intext:后台管理](#1562-1609132494362)
[5.2、intitle:管理登录](#4067-1609132494362)
[5.3、filetype:pdf](#5125-1609132494362)
[5.4、inurl: php?id=](#2626-1609132494362)
[5.5、site:baidu.com](#6099-1609132494362)
[5.6、filetype:pdf site:baidu.com](#2526-1609142599574)
[6、Github](#4070-1609132494362)
[7、维基和百度百科](#6248-1609000172175)
[8、网络空间搜索引擎](#2752-1609143904790)
[8.1、Fofa](#8628-1608994952900)
[8.2、Shodan](#7827-1608995508166)
[8.3、Zoomeye(钟馗之眼)](#1356-1608995559459)
[8.4、Spyse](#4049-1608995592030)
[8.5、Censys](#8054-1609090002560)
[9、REG007](#9669-1611813877072)
[二、APP、小程序、公众号信息收集](#3621-1608994953076)
[1、APP信息搜集](#7068-1608993351034)
[1.1、七麦数据](#7710-1608993411291)
[1.2、AppStore(安卓和IOS)](#2775-1608993545897)
[2、微信公众号和小程序](#3067-1608993411485)
[4、logo](#5930-1609143632016)
[5、favicon.ico](#4627-1608993411642)
[三、子域名收集(挖掘)](#1925-1608957036106)
[1、SSL(HTTPS)证书](#4380-1609090650925)
[1.1、大厂商SSL证书一证多用](#1020-1609128666117)
[1.2、HTTPS证书错误泄露域名](#2835-1609090650925)
[1.3、在线网站证书查询](#5294-1609128697253)
[2、网络深度爬虫](#4998-1609090650925)
[3、域传送漏洞](#7223-1609090925111)
[3.1、常用DNS记录](#1072-1609090925111)
[3.2、DNS区域传送](#9085-1609090925111)
[3.3、域传送漏洞](#3265-1609090925111)
[3.4、检测](#1183-1609090925111)
[4、在线DNS数据](#3644-1609090862170)
[4.1、VirusTotal](#4819-1609091002762)
[4.2、DNSdumpster](#6528-1609091002762)
[4.2、dnsdb](#5960-1609149395775)
[5、自身泄漏](#4068-1609091082152)
[6、Github泄露](#8760-1609091082152)
[7、Google Hacking](#4387-1609090862561)
[8、在线子域名查询](#5190-1609144245688)
[9、子域名枚举爆破](#7195-1609090862754)
[9.1、OneForAll](#2064-1608958948229)
[9.2、subDomainBrute](#8223-1608979107978)
[9.3、Layer](#6550-1608981342591)
[9.4、FuzSub](#3987-1608982931914)
[9.5、Fierce](#2688-1608956009770)
[9.6、御剑](#1849-1609522810625)
[9.7、wydomain](#3722-1609600384813)
[9.8、orangescan](#5955-1609601438779)
[9.9、DNSRecon](#1670-1609601463470)
[9.10、K8](#1149-1609601477005)
[四、IP信息收集](#5028-1608955925899)
[1、CDN概念](#1747-1608955824768)
[2、判断是否真实IP](#8035-1608955824768)
[2.1、nslookup](#1167-1608955824768)
[2.2、多地ping](#1490-1609523033042)
[2.3、IP反查](#2282-1608955824768)
[3、绕CDN找真实IP](#7660-1608955824768)
[3.1、子域名](#3665-1608955824768)
[3.2、历史DNS解析记录](#5845-1608955824768)
[3.3、邮件服务器](#2254-1608955824768)
[3.4、信息泄漏](#3371-1608955824768)
[3.5、网络空间搜索引擎](#4490-1608955824768)
[3.6、利用SSL证书查询](#5540-1609152256957)
[3.7、国外访问](#2123-1609152256957)
[3.8、LTM解码法](#5089-1609152158354)
[五、基本目录、敏感目录及文件](#2181-1608955668851)
[1、dirsearch](#4679-1608992618890)
[2、dirbuster](#3231-1608992732589)
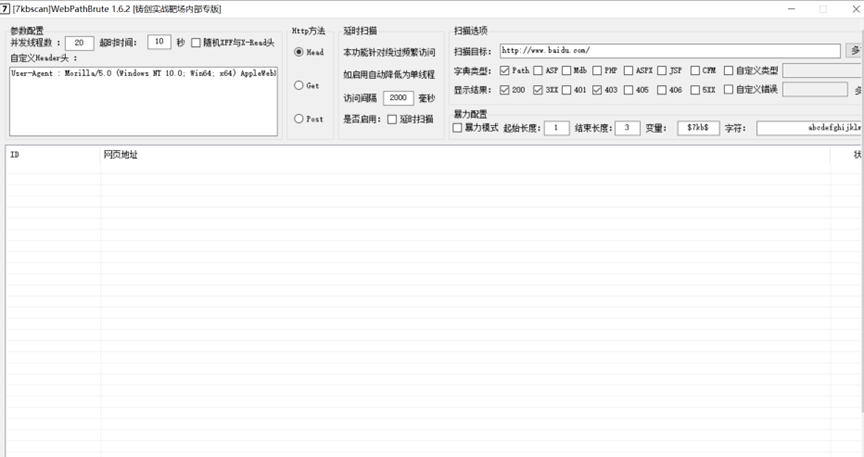
[3、7kbscan](#3622-1608992805474)
[4、Webrobot](#6361-1608920351807)
[5、御剑](#4220-1609573008653)
[6、爬虫-中国菜刀](#6791-1609573020093)
[7、wwwscan](#9124-1609600023020)
[8、cansina](#3046-1609600030284)
[9、dirmap](#8653-1609601106194)
[10、Webdirscan](#6077-1609601148943)
[11、BBscan](#0095-1609601728882)
[12、GSIL](#4978-1609601754493)
[六、端口扫描](#6626-1608993192550)
[1、各服务开启的默认端口以及攻击方向](#6069-1608954466298)
[2、在线查询网站](#6091-1609151143006)
[3、端口扫描工具](#5019-1609133130279)
[3.1、nmap(zmap)](#4561-1609133361937)
[3.2、masscan](#8017-1609133362312)
[3.3、ScanPort](#8422-1609133130279)
[3.4、webrobot](#9722-1609133130279)
[七、旁站C段](#4097-1608920351807)
[1、在线查询](#3070-1608956426469)
[1.1、站点](#9200-1609149932774)
[1.2、Google Hacking、Bing](#6165-1608956426469)
[1.2、网络空间搜索引擎](#2668-1609150042919)
[2、探测工具](#5171-1609149771387)
[2.1、K8Cscan](#2224-1609149800718)
[2.2、nmap、masscan](#8618-1609149771812)
[2.3、goby](#1900-1609149844914)
[2.4、御剑](#6861-1609149994044)
[2.5、北极熊扫描器](#5389-1609150008457)
[2.6、通过手动ping](#1349-1609573401484)
[八、整站分析](#1547-1608920351807)
[1、服务器类型](#5021-1608954477133)
[1.1、 云悉WEB资产梳理](#0096-1609320836918)
[2、网站容器](#7810-1609320832121)
[2.1、火狐渗透测试浏览器](#2839-1609320737099)
[2.2、云悉WEB资产梳理](#2075-1609320737099)
[3、脚本类型](#9370-1608920351807)
[3.1、通过修改首页文件后缀查看页面响应判断](#1029-1608920351807)
[3.2、通过搜索框查找相关文章辨别脚本类型](#9095-1609291086831)
[3.3、通过爬虫工具爬取网站目录判断网站脚本类型](#3279-1609291086831)
[4、CMS类型](#9730-1609291081999)
[4.1、云悉指纹](#8518-1608956783838)
[4.2、ThreatScan](#8393-1608956783838)
[4.3、wappalyzer](#2042-1608956783838)
[4.4、WhatWeb](#2217-1608994323598)
[4.5、BugScaner](#1160-1608956783838)
[4.6、潮汐指纹](#3663-1608994632867)
[5、数据库类型](#6783-1608920351807)
[6、WAF](#5381-1608920351807)
[6.1、在线资产识别](#9127-1609286607208)
[6.2、手动检测是拦截页面或者HTTP可识别字段](#9160-1609286607208)
[九、后台查找](#5054-1608956818746)
工商数据收集
\- 简介
\- 工商数据可以帮助测试人员更好地了解目标公司的信息,以便收敛测试的目标范围。
例如,可以通过工商数据获取公司的控股子公司、经营业务、对外发布的产品等信息
这些信息可以帮助我们更准确地识别出目标公司的网络资产,以便对其进行更有效漏洞挖掘
\- 工商数据
\- 信息来源
\- 爱企查
\- 企百笪
\- 天眼查
\- 启信宝
\- 小蓝本
\- 关注内容
\- 企业股权架构
\- 网站备案
\- 对外公布的产品(小程序、公众号APP、iot设备等)
\- 法人电话号、邮箱
\- 用处
1. 获取控股子公司名称,收集边缘子公司资产
2. 获取备案根域名
3. 获取其他互联网资产
4. 收集用户名等信息
\- 思路
\- 拿到目标公司名之后,先不要着急直接开始收集子域名,先统计好这家公司的股权架构,一般50%控股的可以算作有效目标,子公司资产将为我们提供不少的边缘业务系统
\- 通过股权穿透图收集完子公司名称后,网站备案、对外发布的产品、法人电话和邮箱同样也是比较重要的数据
\- *工具推荐*
\- [https://github.com/wgpsec/ENScan\_GO](https://github.com/wgpsec/ENScan_GO)
### 站长之家
利用查询到网站管理员手机号码、姓名、邮箱通过Whois反查查询出网站管理员所注册过的域名,可以对注册的其他域名进行漏洞挖掘。
**邮箱反查:
**
**注册人反查:**
**电话反查:**
### 爱站
### 微步

### 国外的who.is
### 阿里云域名信息查询
[https://whois.aliyun.com](https://whois.aliyun.com/)
### 腾讯查询
### 中国互联网信息中心
ICP(Internet Content Provider)备案查询
----------------------------------
可以查询该单位备案的其它网站
### 国家企业信用信息公示系统

### ICP备案查询网

### ICP备案查询 - 站长工具

### 天眼查
根据前面获取的企业名称可以获取目标企业的微信公众号、微博、备案站点、APP、软件著作权等信息
### 企查查

SEO(Search Engine Optimization)查询
---------------------------------
### 爱站-SEO综合查询
可以根据域名来收集目标站点的备案信息、名称、注册人等信息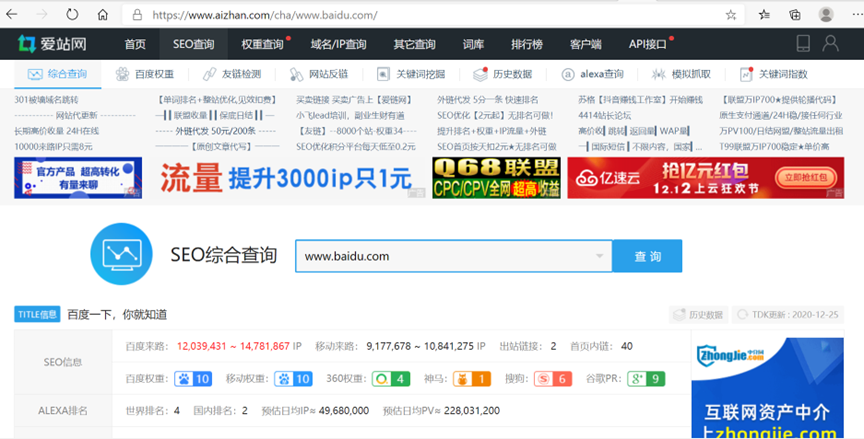
### 站长-SEO综合查询

### Google、bing、baidu
`Google`需要翻墙,一般用来收集一些敏感信息,用老生常谈的方法
这样收集特定的域名
site:xxx.cn
我通常用来收集特定资产的敏感信息
如 `intext:``身份证` `intext:``电话` 再指定后缀 `xlsx` `pdf` `docs`等
另外的时候会收集一些藏的比较深的路由
指定`inurl:xxx`可能会发现额外的资产
不过相比起`Google`我更喜欢用`Bing`,因为不用翻墙
语法的话与`Google`同理,不过`Bing`如果用谷歌语法的话搜集的内容会模糊一些,不是精准搜索
最后就是百度,也是搜集信息的一种方式
Ps:``搜索引擎一般用来收集信息泄露和隐藏较深的路由
这里给大家推荐一个网站 (本人也是看别人的知道的【信息收集之-你不知道的骚思路】[https://www.bilibili.com/video/BV1yP4y117Q2?vd\_source=6ce69e079d1dd642d7810fbf2e9c817e](https://www.bilibili.com/video/BV1yP4y117Q2?vd_source=6ce69e079d1dd642d7810fbf2e9c817e))
二开谷歌语法------ (国内版)
\----------------- (国外版)

Github
------
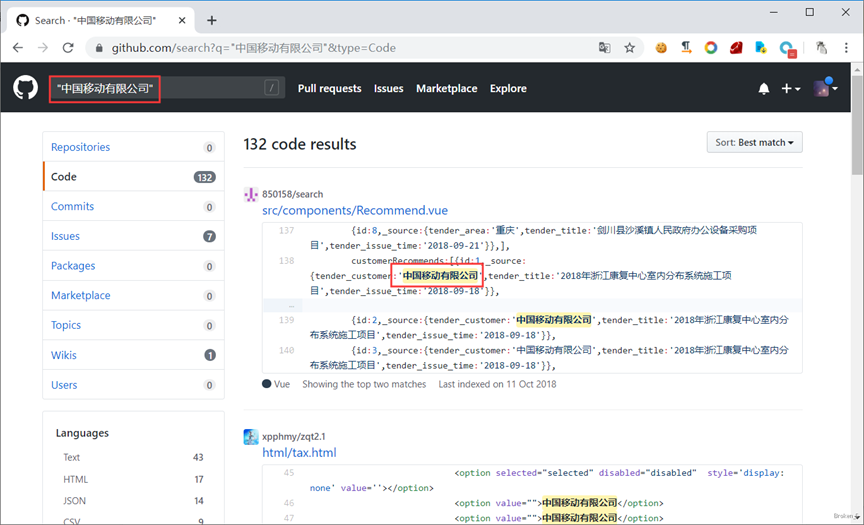
GitHub源码泄露肯定都听说过,但是真正找的源码的案例可能很少,可能是你用的方法有问题,网站域名、网站JS路径、网站备案、网站下的技术支持这些都可以放进去GitHub搜
精确搜索:被双引号引起来的部分代表精确匹配
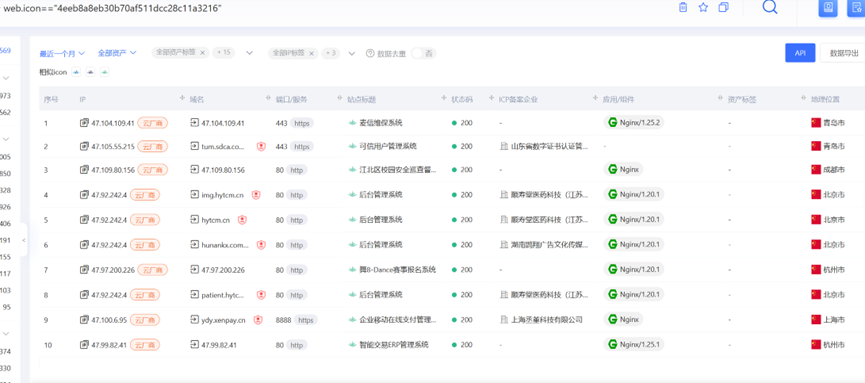
**Fofa 360** **鹰图 钟馗之眼**
鹰图提炼图标很好用
web.icon=="4eeb8a8eb30b70af511dcc28c11a3216"
\\=模糊
\\==精准
icon\_hash="174665376"
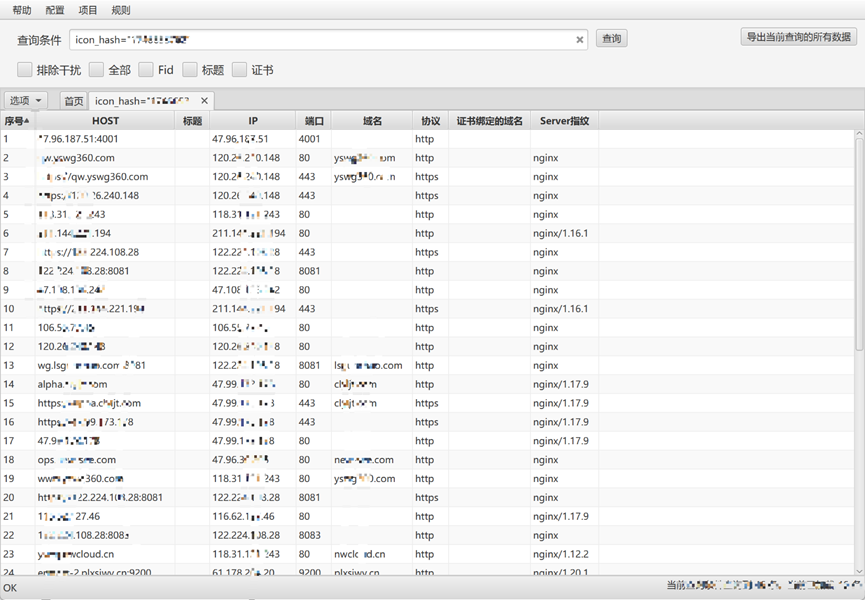
其实,这时候可以发现很多图标,两者是相辅相成的,通过收集图标提炼共性标题,通过收集标题找到共性图标
最好多加个几个精准条件
web.icon=="4eeb8a8eb30b70af511dcc28c11a3216"&&title="ruoyi"

`Web``的内容```
body=ruoyi
大家记得多看前端源码
### 提炼特殊路由
不同的站点路由其实是不一样的,在这里的话若依站点最特殊的路由是`prod-api`
因此我们从路由的角度来体验
一种是找超链接的提炼方式
body=prod-api/

可以找到站点中带有若依的超链接路由

打开之后我们就可以发现确实超链接指向的是若依的系统
如果收集的若依系统够多,可以发现存在二开的系统有其他的路由,比如`admin-api` `dev-api` 等等
另一种方式可能就需要用到搜索引擎去相辅相成的寻找特殊路由
### GIT提炼
很多开源的若依二开可以在`github`找到相关的项目,往往修改较多的就是默认的`prod-api`为主,可以按照上面的内容去提炼,这样可以直接收集各个二开若依系统
### 傻蛋
网址:[https://www.shodan.io](https://www.shodan.io/)
活动:**Shodan\***\*黑五1美元一个,淘宝、咸鱼可以看看\*\*
普通:69美元 每月最多 100 万个结果 每月扫描多达 5,120 个 IP 5,120 个 IP 的网络监控
高级:359美元 每月最多 2000 万个结果 每月扫描多达 65,536 个 IP 65,536 个 IP 的网络监控
超级:1099元 每月无限 每月扫描多达 327,680 个 IP 327,680 个 IP 的网络监控
普通与高级功能差别:漏洞搜索过滤器
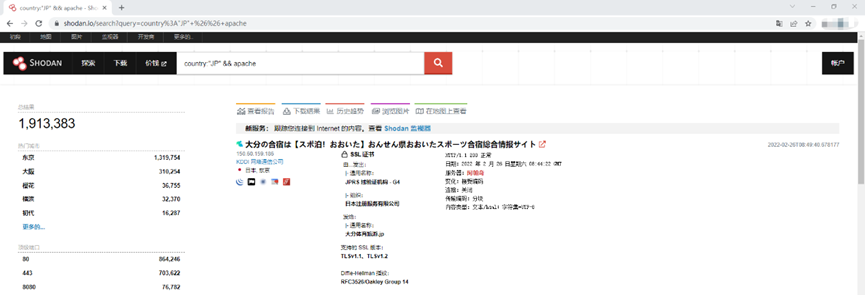
#### 语法
- city:搜索指定城市 例如:**city:“tokyo ”**
- country:搜索指定国家 例如:**country:“JP”**
- http.title:搜索指定网站标题 列如:**http.title:“hacked by”**
- http.html:搜索指定网页类容 例如:**http.html:“hello world”**
- http.status:搜索指定返回响应码 例如:**http.status:“200”**
- http.server:搜索指定返回中的server类型 例如:**http.server:“PHP”**
- net:搜索指定网络范围或 IP段,例如:**net:“8.8.0.0/16”**
- org:搜索指定的组织或机构,例如:**org:“google”**
- port:搜索指定的端口或服务,例如:**port:“22”**
- product:搜索指定的操作系统/软件/中间件,列如:**product:“Samsung”**
- screenshot.label:搜索指定描述图像内容的标签 列如:**screenshot.label:“ics”**
- os:搜索指定限定系统OS版本, 例如:**os:“Windows Server 2008 R2”**
- hostname:搜索指定的主机或域名,例如:**hostname:“google”**
- vuln:搜索指定CVE漏洞编号,例如:**vuln:“CVE-2014-0723”**
- isp:搜索指定的ISP供应商,例如:**isp:“China Telecom”**
- version:搜索指定的软件版本,例如:**version:“1.2.3”**
- geo:搜索指定的地理位置,参数为经纬度,例如:**geo:“44.55,66.77”**
#### 搜索案例
搜索日本国家,中间件是Apache服务器并且状态码是200的机器
country:"JP" && apache && http.status:"200"
搜索日本国家,摄像头是海康威视
country:"JP" && Hikvision-Webs
搜索日本国家,操作系统是Windows Server 2008 R2并且开放3389端口的机器
country:jp && os:Windows Server 2008 R2 && port:3389
搜索日本国家,操作系统是Windows Server并且存在永恒之蓝漏洞的机器(更高级会员才能使用vuln)
country:jp && os:Windows Server \* && vuln:CVE-2017-0146
#### [shodan](https://so.csdn.net/so/search?q=shodan&spm=1001.2101.3001.7020)语法参考资料
[Filter Reference](https://www.shodan.io/search/filters)
[Shodan使用指南 - zha0gongz1 - 博客园](https://www.cnblogs.com/H4ck3R-XiX/p/12950736.html)
[暗黑引擎 -- Shodan常用搜索语法*web安全工具库的博客-CSDN博客*shodan搜索语法](https://blog.csdn.net/weixin_41489908/article/details/110404340)[https://blog.csdn.net/weixin\_41489908/article/details/110404340](https://blog.csdn.net/weixin_41489908/article/details/110404340)
### 钟馗之眼--知道创宇
[ZoomEye - Cyberspace Search Engine](https://www.zoomeye.org/)
免费: 查询结果展示量:4百条 查询API额度:每月1w
高级:4800/年 查询结果展示量:1千条 查询API额度:每月3w
VIP:9600/年 查询结果展示量:2千条 查询API额度:每月4w
高级与VIP功能差别:蜜罐识别

#### 语法
- country:搜索指定国家 例如:**country:“JP”**
- city:搜索指定城市 例如:**city:“San Diego”**
- [subdivisions](https://www.zoomeye.org/searchResult?q=subdivisions:):搜索相关指定行政区的资产 例如:**subdivisions:“\***\*东京”\*\*
- [ssl.cert.availability](https://www.zoomeye.org/searchResult?q=ssl.cert.availability:1):搜索证书是否在有效期内 例如:**ssl:“1”or“0”**
- ip:搜索指定的IP(ipv4/6) 列如:[ip:](https://www.zoomeye.org/searchResult?q=ip:)**“8.8.8.8”**
- cidr:搜索指定的IP段 列如:[cidr:](https://www.zoomeye.org/searchResult?q=cidr:52.2.254.36/24)**“52.2.254.36/24”**
- org:搜索指定的组织或机构,例如:**org:“google”**
- isp:搜索相关网络服务提供商的资产 例如:[isp:](https://www.zoomeye.org/searchResult?q=isp:)**“China Mobile”**
- port:搜索指定的端口或服务,例如:**port:“22”**
- hostname:搜索相关IP"主机名"的资产 例如:[hostname:](https://www.zoomeye.org/searchResult?q=hostname:google.com)**“google.com”**
- site:搜索域名相关的资产 例如:[site:](https://www.zoomeye.org/searchResult?q=site:baidu.com)**“baidu.com”**
- device:搜索路由器相关的设备类型 例如:[device:](https://www.zoomeye.org/searchResult?q=device:)**“router”**
- os:搜索指定限定系统OS版本, 例如:**os:“Windows Server 2008 R2”**
- title:搜索指定网页类容 例如:[title:](https://www.zoomeye.org/searchResult?q=title:)**“hello world”**
- app:搜索指定的组件 列如:**app:“apache ”**
- ver:搜索指定的版本 l例如:**ver“1.2.3”**
- service:指定服务类型 例如:**service:“ftp”**
#### 钟馗之眼语法参考资料
[Zoomeye-钟馗之眼语法参考*Pika\_mia的博客-CSDN博客*zoomeye语法](https://blog.csdn.net/qq_42716969/article/details/105994291)
[zoomeye用户使用手册*ncafei的博客-CSDN博客*zoomeye](https://blog.csdn.net/ncafei/article/details/63683377)
[ZoomEye(钟馗之眼)搜索技巧记录: - \_H0f - 博客园](https://www.cnblogs.com/someone9/p/8688636.html)
[信息收集利器:ZoomEye - FreeBuf网络安全行业门户](https://www.freebuf.com/sectool/163782.html)
### 360 QUAKE--360
[360网络空间测绘 — 因为看见,所以安全](https://quake.360.cn/quake/#/index)
免费 数据广度开放性:5百条 Quake积分:3千/月
高级:299/年 数据广度开放性:5千条 Quake积分 :3W/月
终身:999 数据广度开放性:1W条 Quake积分 :5W/月
功能差别:相似图标、深度识别、专用语法、圈内交流
**邀请码: Cm2TX9**

#### 语法
- country:搜索指定国家(中文添加\_cn) 例如:**country:“JP”**
- city:搜索指定城市 例如:**city:“tokyo ”**
- owner:搜索IP归属单位 例如:**owner:“tencent.com”**
- isp:搜索IP归属运营商 例如:**isp:“amazon.com”**
- ip:查询IP地址或网段 列如:**ip:"1.1.1.1/22"**
- is\_ipv6:查询IPV6格式的IP 列如:**sis\_ipv6:"true"**
- port:搜索指定的端口或服务 例如:**port:“\[50 TO 60\]”**
- transport:查询udp数据 例如:**transport:“udp”**
- domain:查询资产域名 例如:**domain:“google.com”**
- hostname:查询主机名包含指定资产的数据 例如: **hostname:“google.com”**
- app:搜索指定的组件 列如:**app:“apache ”**
- response:查询端口原生返回数据中包含指定参数的资产 列如:**response:“google.com”**
### 相应网站
[Censys Search](https://search.censys.io/)
[GreyNoise](https://www.greynoise.io/)
[各个国家代码是什么?\_百度知道](https://zhidao.baidu.com/question/750335434727022652.html)
[https://github.com/0x727/Space\_view](https://github.com/0x727/Space_view)
### 聚合测绘空间搜索工具
项目名称:聚合测绘空间搜索(**HW\***\*蓝队情报收集\*\*) 项目地址:
支持搜索的引擎:**Fofa\***\*、Zoomeye、Quake、Shodan、Censys、BinaryEdge、threatbook\*\*
1\. git clone
2\. cd Search-Tools && pip3 install -r requirements.txt
3\. python3 search\_main.py
APP、小程序、公众号信息收集
===============
1、APP信息搜集
---------
### 1.1、七麦数据
通过当前APP查询所属公司的所有APP

通过当前APP查询同开发者应用

### 1.2、AppStore(安卓和IOS)
查询同开发者应用

2、微信公众号和小程序
-----------
通过微信搜索公众号并去关注,然后进去点击文章之类的,下拉可以看到它的网页来源,大部分是微信提供的,所以需要去阅读原文,但是原文也可能是第三方提供的,所以还需要自己自行去判断,找到它的url后又可以去爆一波子域名了,

随便点击文章通过下拉查看域名,例如:

4、logo
------
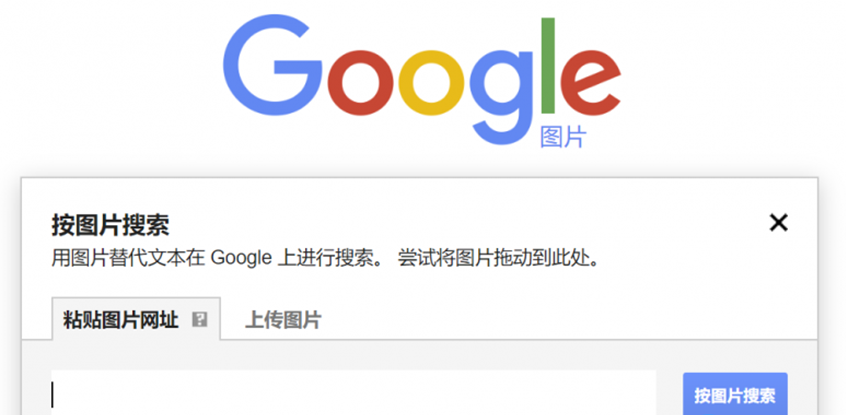
当你不确定目标产品是什么时,比如你不知道他是谁家的WAF或者路由器,可以利用查看网站logo地址,然后复制logo地址,点击按图片搜索,到谷歌里面查询;也可以把目标logo下载下来,利用上传图片来查询,通过搜索出来的结果可以判断目标产品和厂商。


5、favicon.ico
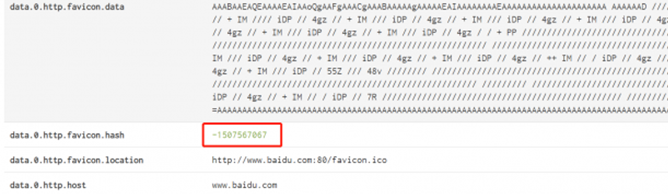
-------------
首先先来介绍一下什么favicon.ico文件,所谓favicon,便是其可以让浏览器的收藏夹中除显示相应的标题外,还以图标的方式区别不同的网站。favicon.ico也被称为 website icon(网页图标)、page icon(页面图标)或url icon(URL图标),具体细节请问度娘。下面这个小东西就是 Favicon.ico,我们可以通过在shodan里寻找它的哈希并去查找相关资产,打开shodan页面,或者用shodan插件都行。



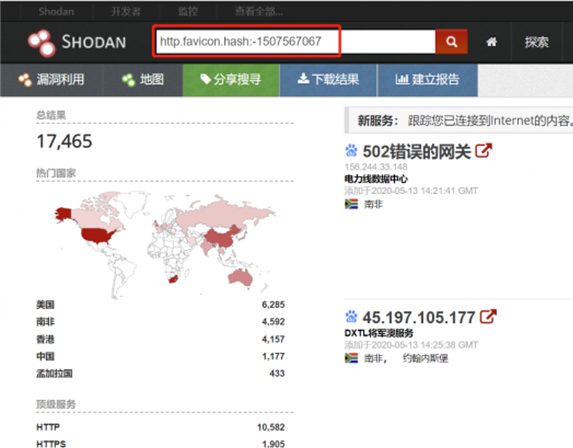
三、子域名收集(挖掘)
===========
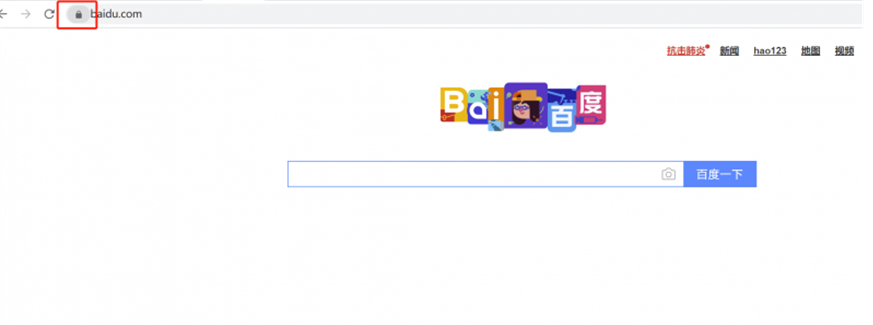
1、SSL(HTTPS)证书
--------------
点击浏览器网站旁边的小锁,然后点击证书就可以查看到该网站的SSL证书了

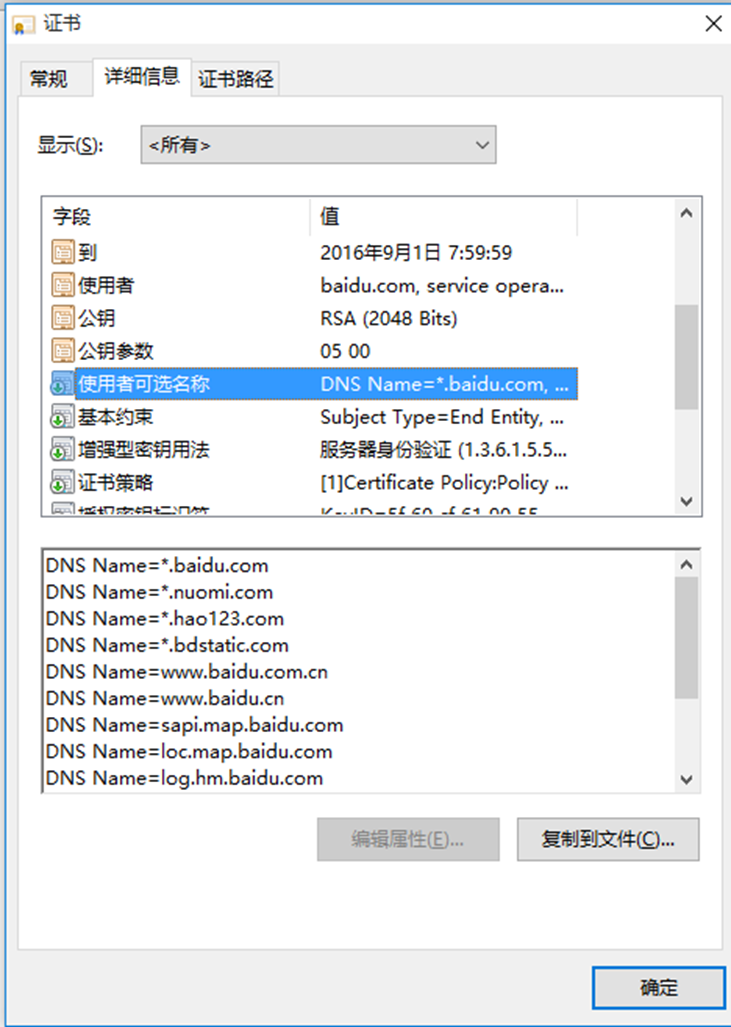
### 1.1、大厂商SSL证书一证多用
大厂商的SSL证书一般都是**一证多用**,根据证书透明日志这个特性,可以得知一些子域名。
如百度:[https://www.baidu.com](https://www.baidu.com/)
如搜狐:[https://vpn.sohu-inc.com](https://vpn.sohu-inc.com/)
### 1.2、HTTPS证书错误泄露域名
有时候https证书报错会泄露域名

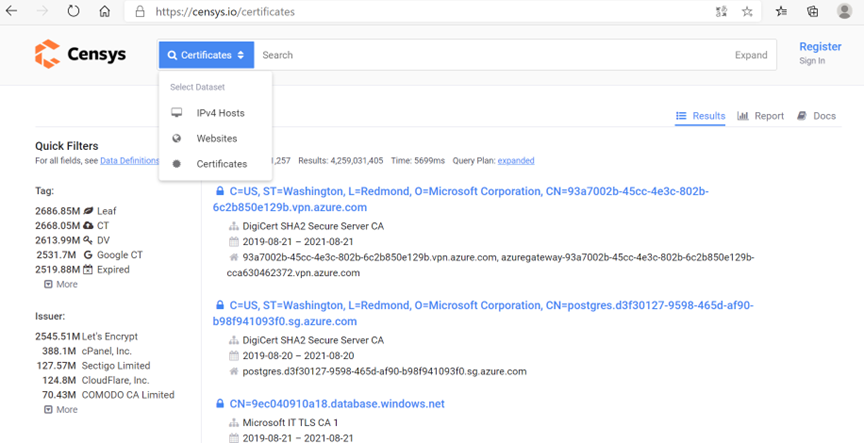
### 1.3、在线网站证书查询
2、网络深度爬虫
--------
以[www.sina.com.cn](www.sina.com.cn)为例,我们使用正则表达式抓取页面以sina.com.cn结尾的所有的URL(一级深度)。
!/usr/bin/env python
====================
coding=utf-8
============
author=
==============================
create=20160701
===============
import re
import requests
from pprint import pprint
def crawl\_page(url, domain):
print('\[\*\] Crawl URL: {0}'.format(url))
found\_url = set()
req = requests.get(url, timeout=15)
content = req.text
link\_list = re.findall(r"(?<=href=").+?(?=")|(?<=href=').+?(?=')", content)
for url in link\_list:
result = re.findall('http\[s\]?://(.\*?).sina.com.cn', url)
if len(result) > 0:
found\_url.add('{0}.{1}'.format(result\[0\], domain))
pprint(found\_url)
if **name** == '**main**':
page\_url = ''
main\_domain = 'sina.com.cn'
crawl\_page(page\_url, main\_domain)
一级深度爬出来的结果,就有146个子域名,这个小脚本权当抛砖引玉,可以再深度定制。
\[\*\] Crawl URL:
{'2016.sina.com.cn',
'ah.sina.com.cn',
'ai.lottery.sina.com.cn',
'aipai.sina.com.cn',
'app.sina.com.cn',
'astro.sina.com.cn',
'auto.sina.com.cn',
'career.sina.com.cn',
'golf.sina.com.cn',
'zx.jiaju.sina.com.cn'}
\[\*\] Found Links Num: 146
3、域传送漏洞
-------
快速判断出某个特定区域的所有主机,获取域信息,如网络拓扑结构、服务器ip地址,为攻击者的入侵提供大量敏感信息。
### 3.1、常用DNS记录
主机记录(A记录): A记录是用于名称解析的重要记录,它将特定的主机名映射到对应主机的IP地址上。
IPv6主机记录(AAAA记录): 与A记录对应,用于将特定的主机名映射到一个主机的IPv6地址。
别名(CNAME记录): CNAME记录用于将某个别名指向到某个A记录上,这样就不需要再为某个新名字另外创建一条新的A记录。
电子邮件交换记录(MX记录): 记录一个邮件域名对应的IP地址
域名服务器记录 (NS记录): 记录该域名由哪台域名服务器解析
反向记录(PTR记录): 也即从IP地址到域名的一条记录
TXT记录:记录域名的相关文本信息
### 3.2、DNS区域传送
DNS服务器分为主服务器、备份服务器和缓存服务器。而域传送指的是一台备用服务器使用来自主服务器的数据更新自己的域(zone)数据库。这为运行中的DNS服务提供了一定的冗余度,其目的是为了防止主的域名服务器因意外故障变得不可用时影响到整个域名的解析。
### 3.3、域传送漏洞
DNS区域传送(DNS transfer)指后备DNS服务器从主服务器获取数据,以更新自己的zone数据库,这可以防止因主DNS服务器故障造成的业务中断,为DNS服务提供了冗余备份,但是许多DNS服务器却被错误配置成只要收到AXFR请求,就向对方进行域传送。
当存在这种错误配置时,攻击者就可以获取整个域的所有记录,造成整个网络架构泄露。正确的配置包括
allow-transfer {ipaddress;}; 通过ip限制可进行域传送的服务器
allow-transfer { key transfer; }; 通过key限制可进行域传送的服务器
### 3.4、检测
nmap脚本扫描
nmap –script dns-zone-transfer –script-args dns-zone-transfer.domain=targetdomain -p 53 -Pn dns.xxx
dig命令
dig @114.114.114.114 twosmi1e.com axfr @指定DNS服务器, 后面指定域名,axfr为域传送请求
nslookup
输入nslookup命令进入交互式shell界面;
server 命令参数设定查询将要使用的DNS服务器;针对某个域名可先输入域名获取dns信息。
ls命令列出某个域中的所有域名;如果太长不适合查看可定向保存至文件夹中。
exit命令退出

4、在线DNS数据
---------
有许多第三方服务聚合了大量的DNS数据集,并通过它们来检索给定域名的子域名。
### 4.1、VirusTotal
### 4.2、DNSdumpster
### 4.2、dnsdb
5、自身泄漏
------
robots.txt
crossdomain.xml(跨域策略文件cdx)
从流量中分析提取
6、Github泄露
----------
7、Google Hacking
----------------
搜索引擎查询都会做一些反制爬虫的手段,目前使用google去采集的方法是调用google的官方API,或者调用bing的API去辅助采集。
8、在线子域名查询
---------
9、子域名枚举爆破
---------
向DNS服务器(如8.8.8.8和8.8.4.4)请求字典里面的子域名,看返回的数据里面是否有记录,如果有则说明这是一个存在的子域名。比如说,向114.114.114.114定向请求[www.qq.com](www.qq.com)的记录,返回了一条A记录指向182.254.34.74,就说明存在这个域名;相应的请求wooyun.qq.com并没有相应的记录返回,这就说明没有这个域名存在。
\***注:一般只使用同一套主、副DNS,即8.8.8.8和8.8.4.4,DNS服务器不宜混搭,否则容易出现大量误报\***
发包可以用第三方库,比如说lijiejie的subDomainBrute使用了dnspython这个包。使用第三方包的确好,但是免不了一层封装和不能很好地理解DNS报文协议,也可能会降低一定的效率,和**没有解决泛解析的好办法**。
***泛解析这个问题的解决方法很简单,向DNS请求\*记录,然后把枚举子域名回来的记录和\*的记录比对,如果相同则直接排除\\***。但是实际上,如果使用第三方包,不自己造轮子的话,是无法实现这个的。因为有些域名的\*记录是CNAME,而第三方包只能解析出IP却不会返回出CNAME给你。举个例子,以[www.baidu.com](www.baidu.com),大家ping一下都知道会跳转到[www.a.shifen.com](www.a.shifen.com),这就是一个CNAME记录,但是我们用第三方包只能获得最后解析出来的ip。
也就是说,**如果一个域名他的泛解析是一个CNAME记录而且这又是一个CDN域名**(恰巧这个又不少),那么不是自己定制的dns查询函数,一般都会出现大量泛解析误报。这就有点像是灯下黑,知道了怎么做就可以了,却一直没有解决的办法。
如果要自己定制的话需要研究一下DNS报文协议,这里引用两张图片做简要分析
这是向DNS请求部分的:
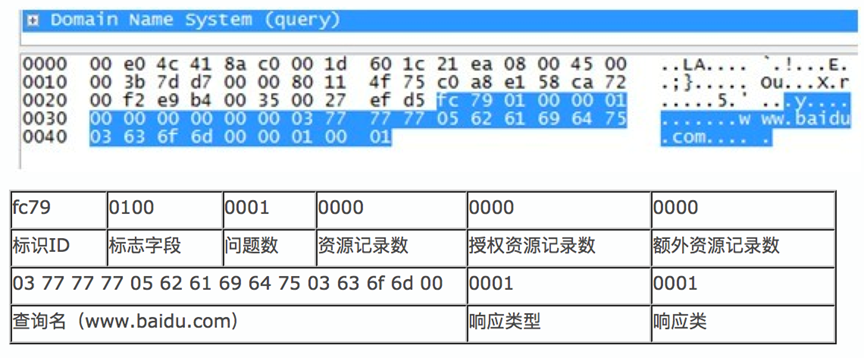
这是DNS服务器回传的报文:
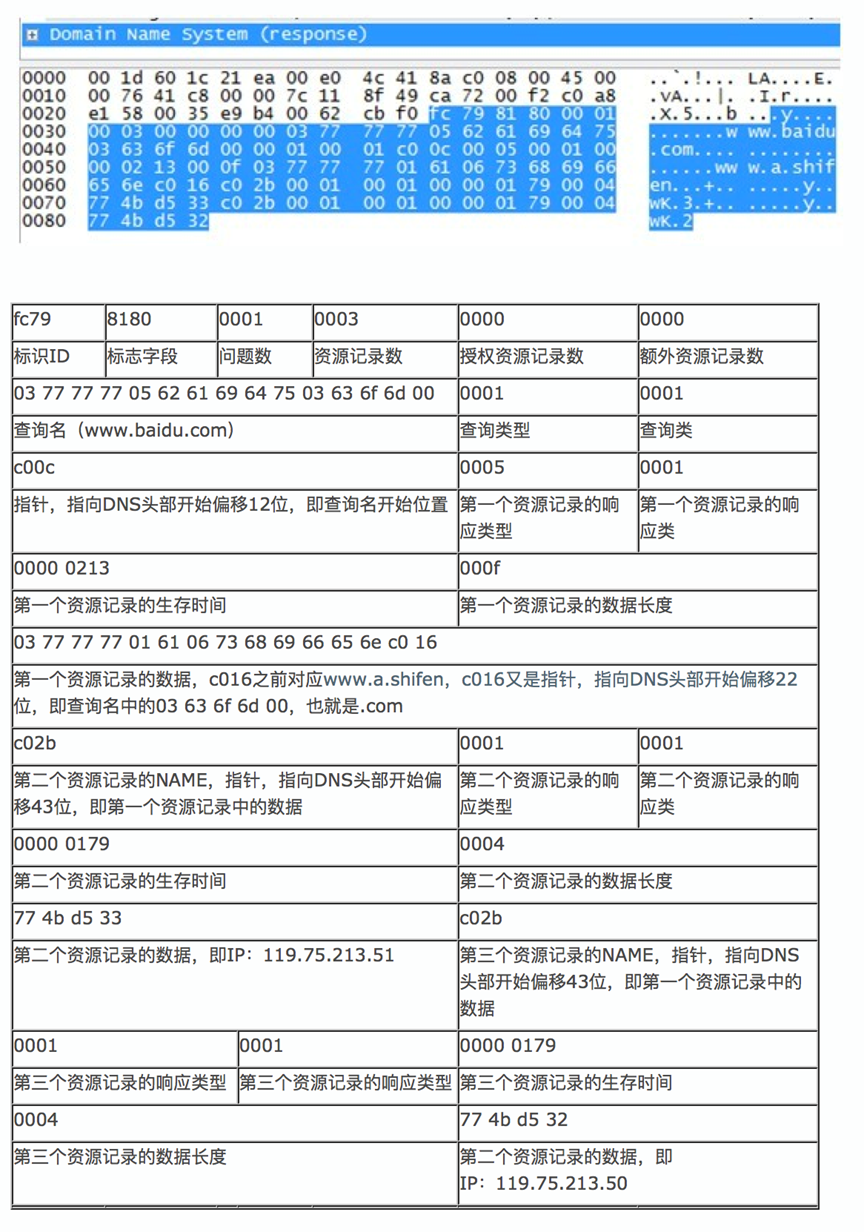
只需要按照这个协议的格式做正则提取即可获得我们想要的信息,A记录的是固定的正则,CNAME记录需要嵌套一层正则才能获取。
这里提供几个测试域名,都有CNAME记录作为泛解析的。
alitrip.com
taobao.com
tmall.com
52pk.com
focus.cn
### 9.1、OneForAll
下载地址:
目前支持一键收集:子域、子域常用端口、子域Title、子域状态、子域服务器等
020*信息收集*子域名OneForAll

### 9.2、subDomainBrute
工具地址:
高并发的DNS暴力枚举工具
020*信息收集*子域名subDomainsBrute

### 9.3、Layer
Layer子域名挖掘机是一款域名查询工具,可提供网站子域名查询服务;拥有简洁的界面、简单的操作模式,支持服务接口、暴力搜索、同服挖掘三种模式,支持打开网站、复制域名、复制IP、复制CDN、导出域名、导出IP、导出域名+IP、导出域名+IP+WEB服务器以及导出存活网站!
通过查看WEB服务器信息,筛选版本比较低的服务器(win2003+iis6.0),查看每个子域名是否开启常见的端口(3389、3306、21端口等),利用爆破工具进行枚举,会达到事半功倍的效果。

### 9.4、FuzSub
### 9.5、Fierce
### 9.6、御剑
### 9.7、wydomain
### 9.8、orangescan
### 9.9、DNSRecon
### 9.10、K8
四、IP信息收集
========
首先,我们要判断该域名是否存在CDN的情况,我们可以去在线CDN查询网站:**** 。如果查询出的ip数量大于一个的话,则说明该ip地址不是真实的服务器地址。以我的经验来看,**如果是2个或者3个,并且这几个地址是同一地区的不同运营商的话,则很有可能这几个地址是服务器的出口地址,该服务器在内网中,通过不同运营商NAT映射供互联网访问,同时采用几个不同的运营商可以负载均衡和热备份。如果是多个ip地址,并且这些ip地址分布在不同地区的话,则基本上可以断定就是采用了CDN了**。
1、CDN概念
-------
内容分发网络(content delivery network或content distribution network,缩写作CDN)指一种通过互联网互相连接的电脑网络系统,利用最靠近每位用户的服务器,更快、更可靠地将音乐、图片、视频、应用程序及其他文件发送给用户,来提供高性能、可扩展性及低成本的网络内容传递给用户,**主要就是通过多个不同节点加快网站的访问速度。**
2、判断是否真实IP
----------
### 2.1、nslookup
**命令端**
意义:用了CDN的会返回多个IP地址
**在线工具**
### 2.2、多地ping
看IP是否一致,在线工具:
、
、
### 2.3、IP反查
反查IP有多个域名,那IP多半不是真实IP
3、绕CDN找真实IP
-----------
### 3.1、子域名
CDN不便宜,所以很多站都是主站做了CDN,而很多小站没做CDN,所以可以通过上面收集到的子域名查询到真实的IP地址,进而知道网站真实IP的C段了。
### 3.2、历史DNS解析记录
查询未使用CDN前的DNS服务器解析记录,查看IP与域名绑定的历史记录,可能会存在使用CDN前的记录
DNS查询
微步在线
[http://toolbar.netcraft.com/site\_report?url=](http://toolbar.netcraft.com/site_report?url=) 在线域名信息查询
DNS、IP等查询
CDN查询IP
### 3.3、邮件服务器
大部分网站会有注册,订阅,找回密码的功能会发送邮件,因为邮件系统一般都在内部,所以就可以通过邮箱获得真实的IP,邮件头信息中会有真实IP
### 3.4、信息泄漏
有些网站会有phpinfo页面,一些debug模式不关等信息泄漏问题,上面会有真实IP
### 3.5、网络空间搜索引擎
通过shadan、fofa等搜索引擎,通过对目标
网站的特征进行搜索,很多时候可以获取网站的真实IP
### 3.6、利用SSL证书查询
### 3.7、国外访问
一般的站点在国内可能会有CDN,但是在国外的用户覆盖率比较低,所以通过国外的节点进行请求往往能获取真实IP
### 3.8、LTM解码法
当服务器使用F5 LTM做负载均衡时,通过对set-cookie关键字的解码真实ip也可被获取,例如:Set-Cookie:
BIGipServerpool\_8.29\_8030=487098378.24095.0000,先把第一小节的十进制数即487098378取出来,然后将其转为十六进制数1d08880a,接着从后至前,以此取四位数出来,也就是0a.88.08.1d,最后依次把他们转为十进制数10.136.8.29,也就是最后的真实ip。
五、基本目录、敏感目录及文件
==============
由于发布网站时,服务器配置问题,导致目录浏览功能打开,从而引起信息泄露,造成安全隐患。在信息收集过程中,需要收集的敏感目录/文件信息包括:
1.robots.txt
2.crossdomin.xml
3.sitemap.xml
4.后台目录
5.网站安装包
6.网站上传目录
7.mysql管理页面
8.phpinfo
9.网站文本编辑器
10.测试文件
11.网站备份文件(.rar、zip、.7z、.tar.gz、.bak)
12.DS\_Store 文件
13.vim编辑器备份文件(.swp)
14.WEB—INF/web.xml文件
目录扫描对应信息收集来说特为重要,比如robots文件当中就可能泄露网站的后台或者CMS信息等,安装包中便泄露了网站的源码,phpinfo泄露了服务器的一些配置信息,编辑器、上传页面便可以进行利用相关的漏洞进行渗透,mysql、后台管理页面可以进行枚举爆破来尝试登陆进行下一步的安全测试。
扫描网站目录结构,看看是否可以遍历目录,或者敏感文件泄漏
后台目录:弱口令,万能密码,爆破
安装包:获取数据库信息,甚至是网站源码
上传目录:截断、上传图片马等
mysql管理接口:弱口令、爆破,万能密码,然后脱裤,甚至是拿到shell
安装页面 :可以二次安装进而绕过
phpinfo:会把你配置的各种信息暴露出来
编辑器:fck、ke、等
iis短文件利用:条件比较苛刻 windows、apache等
robots.txt 文件是专门针对搜索引擎机器人robot 编写的一个纯文本文件。我们可以在这个文件中指定网站中不想被robot访问的目录。这样,我们网站的部分或全部内容就可以不被搜索引擎收录了,或者让搜索引擎只收录指定的内容。因此我们可
以利用robots.txt让Google的机器人访问不了我们网站上的重要文件,GoogleHack的威胁也就不存在了。
假如编写的robots.txt文件内容如下:
User-agent: \*
Disallow: /data/
Disallow: /db/
Disallow: /admin/
Disallow: /manager/
Allow:/images/
其中“Disallow”参数后面的是禁止robot收录部分的路径,例如我们要让robot禁止收录网站目录下的“data”文件夹,只需要在Disallow参数后面加上 /data/ 即可。如果想增加其他目录,只需按此格式继续添加。文件编写完成后将其上传到网站的根目录,就可以让网站远离Google Hack了。
虽然robots文件目的是让搜索蜘蛛不爬取想要保护的页面,但是如果我们知道了robots文件的内容的话,我们就可以知道目标网站哪些文件夹不让访问,从侧面说明这些文件夹是很重要的了。
1、dirsearch
-----------
工具地址:
002*目录信息*dirsearch

2、dirbuster
-----------
工具地址:[https://downloads.sourceforge.net/project/dirbuster/DirBuster%20%28jar%20%2B%20lists%29/1.0-RC1/DirBuster-1.0-RC1.zip?r=https%3A%2F%2Fsourceforge.net%2Fprojects%2Fdirbuster%2Ffiles%2FDirBuster%2520%2528jar%2520%252B%2520lists%2529%2F1.0-RC1%2F&ts=1491212671&use\_mirror=jaist](https://downloads.sourceforge.net/project/dirbuster/DirBuster%20(jar%20%2B%20lists)/1.0-RC1/DirBuster-1.0-RC1.zip?r=https%3A%2F%2Fsourceforge.net%2Fprojects%2Fdirbuster%2Ffiles%2FDirBuster%20%28jar%20%2B%20lists%29%2F1.0-RC1%2F&ts=1491212671&use_mirror=jaist)
当使用扫描工具对站点进行扫描,网站存在WAF后,会给我们的工具进行拦截,这时候我们需要修改User Agent值来绕过WAF的拦截,而DirBuster这款扫描工具便可以修改User Agent值
Mozilla/5.0 (compatible; Baiduspider/2.0; ) 百度蜘蛛抓取欺骗
Mozilla/5.0 (compatible; Googlebot/2.1; ) 谷歌蜘蛛抓取欺骗
Firefox 3.6 Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.2.8;baidu Transcoder) Gecko/20100722 Firefox/3.6.8 ( .NET CLR 3.5.30729) 百度转码浏览欺骗
Chrome Mozilla/5.0 (en-us) AppleWebKit/534.14 (KHTML, like Gecko; Google Wireless Transcoder) Chrome/9.0.597 Safari/534.14 谷歌转码浏览欺骗
3、7kbscan
---------
工具:
4、Webrobot
----------
6、爬虫-中国菜刀
---------
7、wwwscan
---------
8、cansina
---------
9、dirmap
--------
10、Webdirscan
-------------
11、BBscan
---------
12、GSIL
-------
六、端口扫描
======
通过端口扫描可以判断出网站开启的服务,从而通过爆破枚举或者漏洞利用进行突破,进一步提升网站权限,常见的如 135 、137 、138 、139 、445,这几个端口经常爆发漏洞。
扫描到的端口也许是网站的一个旁站,可以尝试对旁站进行漏洞探测,但是有些服务开启的端口可能被管理员修改,通过手工判断分析即可(例如开启了8888端口,通过尝试远程桌面连接确定该端口为3389修改过的端口)。
windows下的命令
===========
显示一个所有的有效连接信息列表,包括已建立的连接(ESTABLISHED ),也包括监听连接请求(LISTENING )的那些连接,
断开连接(CLOSE\_WAIT )或者处于联机等待状态的(TIME\_WAIT )等 :netstat -a
以数字形式显示地址和端口号,显示所有已建立的有效连接:netstat -n
列出所有端口的情况:netstat -ano
查看被占用端口80对应的应用的PID:netstat -ano|findstr "80"
查看80端口被哪个进程或程序占用:tasklist|findstr "80"
结束该进程或程序:taskkill /f /t /im XX.exe
1、各服务开启的默认端口以及攻击方向
------------------

2、在线查询网站
--------
3、端口扫描工具
--------
端口扫描工具常见有nmap和masscan。nmap扫描的准确性较高,但是扫描的比较慢。masscan扫描的比较快,但是准确性较低,如果网站存在WAF可以通过调节扫描线程或者利用FTP连接工具、SSH连接工具、Mysql连接等工具进行手工探测
### 3.1、nmap(zmap)
Nmap扫描中一些常见的服务
msmq? :默认对于的是1801端口,是 MSMQ Microsoft Message Queuing微软消息队列的简称,是windows系统提供的一个功能,开启了该功能,则默认1801端口打开。该服务暂未发现漏洞。

msrpc:Microsoft Remote Procedure Call微软远程过程调用,是 Windows 操作系统使用的一个协议。RPC 提供一种内部进程通讯机制,允许在一台电脑上运行的程序无缝的执行远程系统中的代码。

tcpwrapped:端口状态后经常标记tcpwrapped。tcpwrapped表示服务器运行 tcp\_wrappers服务。tcp\_wrappers是一种应用级防火墙。它可以根据预设,对SSH、Telnet、FTP服务的请求进行拦截,判断是否符合预设要求。如果符合,就会转发给对应的服务进程;否则,会中断连接请求。这说明tcp三次握手已经完成,但是并没有和目标主机建立连接。这表明,虽然目标主机的某项服务是可提供的,但你不在允许访问主机的名单列表中。当大量的端口服务都为tcpwrapped时,这说明可能是有负载均衡或者防火墙阻断了你的连接请求。

Microsoft HTTPAPI httpd 2.0 (SSDP/UPnP):这是SQL Server中的SQL Reporting Service 服务使用的Microsoft HTTPAPI。

### 3.2、masscan
### 3.3、ScanPort
通过ping等方式获取网站IP,然后开始扫描

### 3.4、webrobot

七、旁站C段
======
旁站:是和目标网站在同一台服务器上的其它网站
C端:是和服务器IP处在一个C段的其他服务器
对于防护比较强的主站,通常是很难挖掘到漏洞的,这时需要查看该站点的旁站,通过探测旁站的漏洞进行利用,从而拿下主站的权限。
当网站不存在旁站时,就需要进行C段探测(有些网站买断了相邻的几个IP做为分站,如果拿到分站的管理员敏感信息,如密码之类的,可以尝试对主站进行撞库),通过拿下C段中服务器进行ARP欺骗达到劫持域名的效果
对于红蓝对抗和护网,C段扫描比较有意义。对于单独网站的渗透测试,C段扫描意义不大。C段指的是同一内网段内的其他服务器,每个IP有ABCD四个段,举个例子,192.168.0.1,A段就是192,B段是168,C段是0,D段是1,而C段嗅探的意思就是拿下它同一C段中的其中一台服务器,也就是说是D段1-255中的一台服务器,然后利用工具嗅探拿下该服务器。
1、在线查询
------
### 1.1、站点
[**http://www.5kik.com/c/**](http://www.5kik.com/c/) **?登不上**
### 1.2、Google Hacking、Bing
site:125.125.125.\*
### 1.2、网络空间搜索引擎
fofa、shodan在线工具 语法:ip="106.15.141.18/24"
2、探测工具
------
### 2.1、K8Cscan
### 2.2、nmap、masscan
nmap -p 22,21,443,8080-Pn 172.178.40.0/24
nmap -p 80,8080 --open ip/24
masscan -p 22,21,443,8080-Pn --rate=1000172.178.40.0/24
### 2.3、goby
### 2.4、御剑
### 2.5、北极熊扫描器
### 2.6、通过手动ping
八、整站分析
======
1、服务器类型
-------
服务器信息包括服务器用的操作系统:Linux 还是 Windows 。现在企业网站服务器的操作系统有百分之九十以上用的是Linux操作系统。知道了服务器的操作系统之后,还需要知道操作系统使用的具体版本。因为很多低版本的操作系统都存在已知的漏洞。
判断是Linux还是Windows最简单就是通过ping来探测,Windows的TTL值都是一般是128,Linux则是64。所以大于100的肯定是Windows,而几十的肯定是Linux。但是,通过TTL值来判断服务器类型也不是百分之百准确的,有些windows服务器的TTL值也是几十,而且有的服务器禁止ping。

而判断目标网站服务器的具体的版本的话,可以采用 nmap 进行扫描, -O 和 -A 参数都能扫描出来

检测服务器平台、版本等,获取后可以制定漏洞挖掘方案(如IIS6.0存在解析漏洞等)。
将首页或者其他页面通过修改大小写辨别网站所使用的系统:
区分大小写(页面报错)--Linux
不区分大小写(页面正常)--Windows
### 1.1、 云悉WEB资产梳理
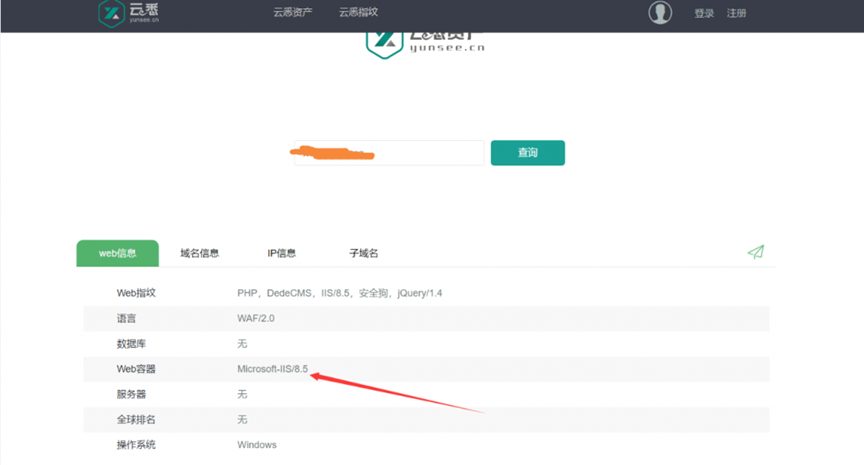
,根据IIS版本判断Windows系统,系统对应版本通过搜索引擎查找。
**注:使用AppScan、WVS等扫描工具也可以判断。**
2、网站容器
------
知道了这些信息之后,我们就需要知道网站用的web服务器是什么类型的:Apache、Nginx、Tomcat 还是 IIS。知道了web服务器是哪种类型后,我们还要探测web服务器具体的版本。比如Ngnix版本<0.83会有解析漏洞 ,IIS6.0会有文件名解析漏洞、IIS7.0会有畸形解析漏洞等。不同的web服务器版本,存在着不同漏洞。
搭建网站的服务组件,例如:iis、Apache、nginx、tomcat等,通过网站容器判断存在的漏洞(如:Apache解析漏洞,nginx解析漏洞)。
### 2.1、火狐渗透测试浏览器

### 2.2、云悉WEB资产梳理\\
2.3、脚本类型
--------
我们需要知道网站用的脚本类型:php 、Jsp 、Asp 、Aspx 。
1)可以根据网站URL来判断
2)site:xxx filetype:php
3)可以根据Firefox的插件来判断

### 3.1、通过修改首页文件后缀查看页面响应判断
通过修改index.xxx后缀内容(为ASP\\ASPX\\PHP\\JSP),查看页面返回情况,页面返回正常便可以判断脚本类型,判断脚本类型是信息收集中最基本的工作之一。
### 3.2、通过搜索框查找相关文章辨别脚本类型
在网站搜索框中输入任意字符,查询后,通过浏览器上的URL判断网站脚本类型。
### 3.3、通过爬虫工具爬取网站目录判断网站脚本类型
Webrobot
4、CMS类型
-------
在渗透测试中,对目标服务器进行指纹识别是相当有必要的,因为只有识别出相应的Web容器或者CMS,才能查找与其相关的漏洞,然后才能进行相应的渗透操作。这是我们想要识别这些网站的指纹,我们就可以利用以下一些指纹识别在线网站。
识别dedecms、phpcms、emlog、帝国cms等,通过网站使用的CMS找取该CMS已经公布的漏洞进行利用,进一步渗透网站。
### 4.1、云悉指纹
### 4.2、ThreatScan

### 4.3、wappalyzer
### 4.4、WhatWeb
[http://whatweb.net/](https://whatweb.net/)
### 4.5、BugScaner
### 4.6、潮汐指纹
5、数据库类型
-------
我们需要知道网站用的是哪种类型的数据库:Mysql、Oracle、SqlServer 还是 Access 。虽然这几种数据库的语法大体上相同,但是还是有区别的。所以我们还是要知道目标网站用的是哪种数据库,并且数据库是哪个版本的
各端口对应数据库类型:
**sql server--1433**
**oracle--1521**
**mysql--3306**
**postgresql--5432**
**access--默认不开放连接端口,数据库存储在FTP服务器上。**
几种数据库的区别:
Access 全名是Microsoft Office Access,是由微软发布的关联式数据库管理系统。小型数据库,当数据库达到100M左右的时候性能就会下降。数据库后缀名: .mdb 一般是asp的网页文件用access数据库
SQL Server是由Microsoft开发和推广的关系数据库管理系统(DBMS),是一个比较大型的数据库。端口号为1433。数据库后缀名 .mdf
MySQL 是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品。MySQL是最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的应用软件之一,MySQL数据库大部分是php的页面。默认端口是3306
Oracle又名Oracle RDBMS,或简称Oracle。是甲骨文公司的一款关系数据库管理系统。常用于比较大的网站。默认端口是1521
首先,成本上的差距,access是不要钱的,mysql也是开源的,sql server 是收费的一般也就几千,Oracle的费用则数万。其次,处理能力,access支持千以内的访问量,sql server支持几千到上万的访问,而Oracle则支持海量的访 问。再次,从数据库的规模来看,access是小型数据库,,mysql 是中小型数据库,sql server是中型数据库,Oracle是大型数据库。
通常情况:access--asp mysql--php oracle--jsp sqlserver--aspx
postgresql--php,常见搭配:
ASP 和 ASPX:ACCESS、SQL Server
PHP:MySQL、PostgreSQL
JSP:Oracle、MySQL
端口扫描判断数据库类型的方法较为准确,但是管理员也可能选择不开放外网数据库端口,开放内网的数据库端口,也有些管理员喜欢使用站库分离的方法或者使用WAF进行拦截端口扫描来防护站点,这样我们通过端口扫描判断数据库类型的方法便有些失效了。
6、WAF
-----
判断安全狗、阿里云云盾、360网站卫士、护卫神等WEB应用程序防火墙,便于采取绕过WAF的办法。
Nmap探测WAF有两种脚本。
一种是http-waf-detect。
命令:nmap -p80,443 --script=http-waf-detect ip
一种是http-waf-fingerprint。
命令:nmap -p80,443 --script=http-waf-fingerprint ip
WAFW00F探测WAF
命令:wafw00f -a 域名
### 6.1、在线资产识别
云悉WEB资产梳理
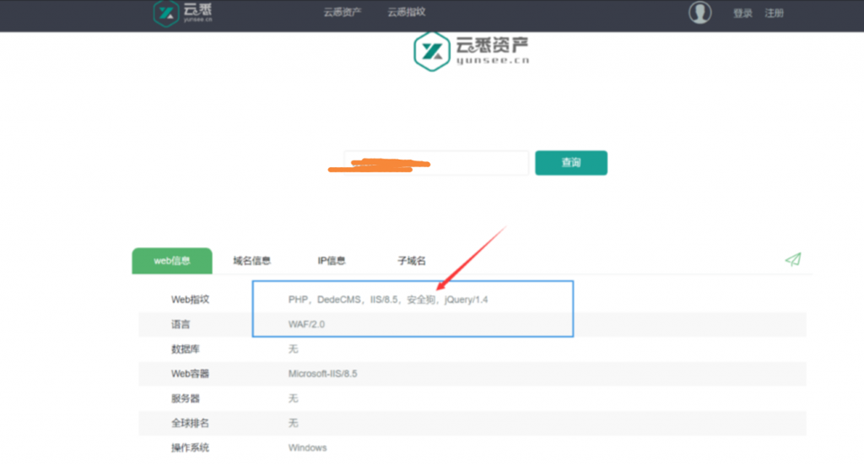
### 6.2、手动检测是拦截页面或者HTTP可识别字段
在搜索框中输入XSS弹窗代码<script>alert('XSS')</script> ,WAF拦截后判断WAF。
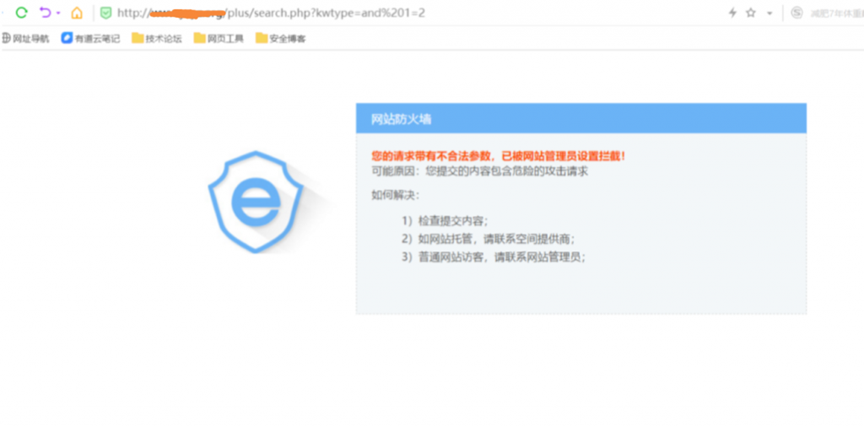
在可能存在的注入页面输入检测注入漏洞代码and 1=2,被WAF拦截后判断WAF。
九、后台查找
======
·1弱口令默认后台:admin,admin/login.asp,manage,login.asp等等常见后台
·2查看网页的链接;一般来说,网站的主页有管理登陆类似的东西,大多数在网站底部版权处或鲁在冒页导肌程等,有些可能被管理员删掉
·3查看网站图片的属性有可能图片是上传大管理后台目录,但是是在前台显示
·4查看网站使用的管理系统,从而确定后台
·5用工具查找:wwwscan,intellitamper,御剑,进行爬虫、字典穷举扫描
·6robots.txt的帮助:robots.txt文件告诉蜘蛛程序在服务器上什么样的文件可以被查看
·7 GoogleHacker通过语法查找后台
·8查看网站使用的编辑器是否有默认后台,FCK、ewb等默认后台
·9短文件利用短文件漏洞进行猜解
·10、子域名有可能管理后台为admin.xxxxx.com、login.xxxxx.com
·11sqlmap-sql-shell load\_file('d:/wwroot/index.php');利用sql注入查看文件源码获取后台
·12社工、XSS利用社会工程系获取后台,利用存储型XSs获取后台

