

GPU Memory Problems in PyTorch(显卡爆炸与利用率不足)

**********************************************************************
总结:调整虚拟内存(包括专用和共享GPU内存)的分配大小,能增大batch_size数值的大小,进而提高显存Memory利用率,和GPU利用率
**********************************************************************
深度好文推荐:
为什么显卡的显存都快满了,GPU利用率还显示这么低呢?好浪费呀,但是又无可奈何。当时GPU利用率100%的情况基本是仅存于一块显卡塞4、5个不费显存的小任务的情况。
在比较极端的情况下,甚至GPU的利用率会降到10%以下,就像这样:

而大部分情况下写出来的代码train起来后是这样的:

可以看到,虽然显卡的显存都塞满了,但是显卡功率(最左边那一栏,114W和69W)和利用率(最右边那一栏,35%和38%)却远远没有达到极限。大部分人的想法是,算了算了这不重要,我去做实验了再见【wei笑】
然而!如果你在做大型实验,train一次跑几天呢?这个细节会极大的影响你的实验效率和DDL到来前的实验次数!想一下,完全一样的model和设置,你的代码要train一周,然而隔壁老王只需要train三天╮( ̄▽ ̄””)╭
路人甲:我有256张显卡
小夕:好了这篇文章你可以X掉了
那么,我们有没有可能一直这样呢:
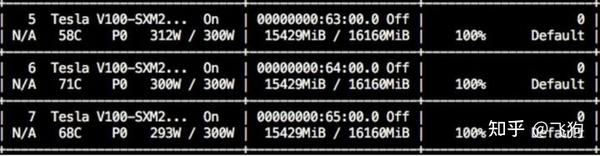
是不是这功率和利用率看起来不可思议!不要怀疑这是PS的图!这只是小夕的日常截图!tricks用的好GPU利用率掉不下来99%,然鹅代码写的足够蠢,也可以上不去5%!
那么问题来了,到底是什么导致的这个差异呢?
不要急,我们来放大一下那些gpu利用率只有30%几的代码在训练时的gpu利用率的变化情况(好像句子有点长
watch -n 0.1 nvidia-smi看!是不是一下子就发现问题啦?可以看到,其实gpu利用率并不是一直在比较低的水平,而是很有规律的周期性的从0涨到接近100再跌到0,再重新涨到100再跌回0。如果同时开着打印日志的窗口,你就会发现这个周期恰好跟每个训练step的时长一致!也就是说,在每个step,其实有一些时间并没有花在GPU里,那当然就是花在cpu里啦。
那在cpu里干什么的呢?当然就是load下一个batch、预处理这个batch以及在gpu上跑出结果后打印日志、后处理、写summary甚至保存模型等,这一系列的花销都要靠cpu去完成。回顾一下我们常写的代码:
create_graph()
create_model_saver()
create_summary_writer()
create_session()
do_init()
for i in range(num_train_steps):
load_batch(...) # cpu
preprocess(...) # cpu
feed_dict = {...} # cpu
fetch_list = [...] # cpu
buf = session.run(fetch_list, feed_dict) # gpu
postprocess(buf) # cpu
print(...) # cpu
if i % x == 0:
summary_writer.write(...) # cpu
if i % xx == 0:
model_saver.save(...) # cpu看,尤其是preprocess(…)任务比较重的话就容易导致代码在cpu里也要跑好一段时间,gpu利用率自然就会上不去而且呈现周期性变化啦。
那么有没有什么办法降低cpu时间,提高gpu时间呢?
一个很自(愚)然(蠢)的想法就是把一切训练代码都用tf的api重写不就好啦,甚至最外层的那个
for i in range(num_train_steps)
其实都可以用tf.while_loop重写呀。嗯,小夕还真的这么尝试过,然后发现
TF api这特喵的都是些什么鬼!各种跟numpy和python内置函数重名却行为不一致是什么鬼!卧槽这个api少了个参数我该怎么办?python里就一行代码就能搞定的事情我为什么写了几十行??
所以除了函数式编程的大牛,小夕极力的不建议重蹈覆辙!尤其是我们这些遇到汇编会哭,看到Lisp会崩溃的90后小仙女!
所以没办法把整个train loop都描述进计算图了?
别怕别怕,好在后来其实tensorflow已经封装了一个特别好(多)用(坑)的上层API来把整个train loop都能轻松的封装在计算图中,从而实现超级高的GPU利用率和训练效率!
Estimator
不用管它为啥叫Estimator,只需要知道,它把我们刚才想做的事情基本都给封装好了就行。把刚才的那个经典的写法搬过来
1. create_model()
2. create_model_saver()
3. create_summary_writer()
4. create_session()
5. do_init()
6. for i in range(num_train_steps):
7. load_batch(...) # cpu
8. preprocess(...) # cpu
9. feed_dict = {...} # cpu
10. fetch_list = [...] # cpu
11. buf = session.run(fetch_list, feed_dict) # gpu
12. postprocess(buf) # cpu
13. print(...) # cpu
14. if i % x == 0:
15. summary_writer.write(...) # cpu
16. if i % xx == 0:
17. model_saver.save(...) # cpu1-5行在estimator中都封装好啦,你只需要把相关配置塞进estimator的RunConfig就可以啦~
7-9行也封装好啦,你只需要把数据集载入和预处理的相关代码的函数塞给estimator.train的input_fn~
第10行也封装好啦,你只需要把要fetch的loss、train_op丢进estimator的EstimatorSpec~
第11行也封装好啦,你只需要把描述模型计算图的函数塞给estimator的model_fn~
第12-13行不用操心细节了,global_step和loss自动完成了,剩下的丢给tf.Print和LoggingTensorHook吧~
第14-17行不用你写了,自动完成了
╮(╯▽╰)╭
经过这么一顿折腾,我们发现GPU利用率大大提高啦~直逼80%甚至90%。那么还有没有可以压榨的空间呢?
其实这时仔细一分析就会发现虽然estimator把大部分的代码写进计算图里了,但是从数据的载入和预处理依然是在cpu里 串行 进行呀,而且比如一个batch有128个样本,那么estimaor内部在run每个step的时候还是要等着这128个样本串行的处理完才行。这显然就是最后的瓶颈啦!有没有办法消除掉呢?·当然有,那就是
tf.data
TF的dataset API可以说让人又爱又恨了,它确实看似提供了一种把整个预处理都搬进计算图进行并行化处理的途径,但是!如果你真的完全用tensorflow API来做复杂的预处理的话,真的会让人疯掉的QAQ因此,这里在用tf.data之前,小夕极力的建议先把数据集尽可能的transform成预处理后的样子,包括 做分词、做截断、做word2id等,不过padding和input_mask可以留在TF里面做 ,毕竟都只需要一行。
那做完这些预处理后,数据该怎么存储会更方便后续的读取和处理呢?最最最建议的方式还是使用
tf.records
来存储,磁盘、内存的存储和IO效率都会相比传统方式更快一些,x和y也不用分开了。当然这样的唯一的坏处就是不能直接打开看数据集╮( ̄▽ ̄””)╭毕竟数据集被做成了二进制文件。
但是实在比较懒不想用tf.record的话,那么小夕 极力建议把x和y分开存储 ,并且尽量让tf.data在读取数据的时候做完上面的那些必要的预处理,以避开难用的字符串基础操作API并且减轻训练时的cpu和内存压力。
tf.data还有一个很大的好处就是可以很天然的支持以streaming的方式读取数据 ,这样在面对大数据集时就不会发生数据load完后发现显卡被占的尴尬事件了╮( ̄▽ ̄””)╭
好像讲了这么久,还是没讲怎么用tf.data加速QAQ,来来来进入正题啦。
想想哈,没用tf.data的时候,我们写出来的代码实际跑起来就是这个样子的:
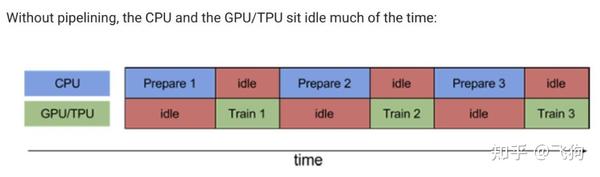
这也是文章开头小夕解释的为什么gpu利用率上不去并且周期性变化的重要原因。那么我们可以不可以消除idle,像下面这样让prepare和train的过程并行进行呢?
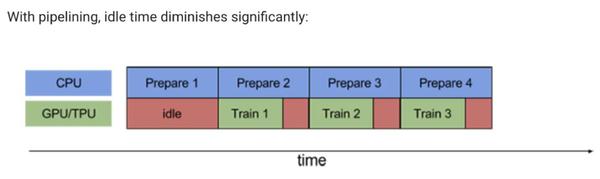
当然可以!那就是
prefetch
从prefetch的意思就可以理解,那就是预先获取下一个step要load的batch。使用tf.data里面的叫做prefetch的神奇api就可以轻松完成啦,这个api里的参数buffer_size就是讲的是额外的fetch多少份,比如buffer_size=1,然后我们要prefetch的是batch的话,那么模型每次prepare完一个batch后,就会自动再额外的prepare一个batch,这样下一个train step到来的时候就可以直接从内存中取走这个事先prepare好的batch啦。(详情见后面)
等下,看上图的话,有木有发现,如果prepare一个batch耗时很短的话确实两全齐美,但是如果耗时比较久,尤其一下子prefetch好几个batch的话,一旦prepare的用时超过了train一个step的用时,那么每个train step的性能就会受限于prepare的效率啦。放大一下这个问题的话如下图所示
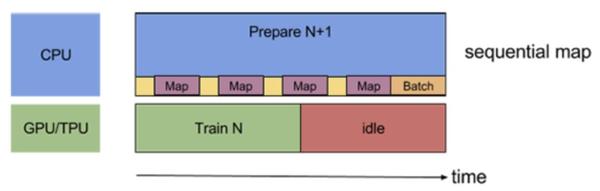
看,prepare用时太久反而会导致train完一个step后gpu空闲了(虽然其实下个step的batch可能已经prepare好了)
那么能不能确保prepare阶段的用时小于train阶段的用时呢?
parallel mapping
一个很简单的想法当然就是让样本并行处理啦~如果batch size是128,prefetch size=1,那么准备一个batch要
串行的
跑128*2=256次的预处理,但是如果我们开4个线程去跑,是不是就看起来快多啦。幸运的是我们也不用自己手撸多线程了,tf.data.Dataset在map(预处理)函数里有一个参数
num_parallel_calls
,给这个参数赋值就可以并行parse啦。如图,
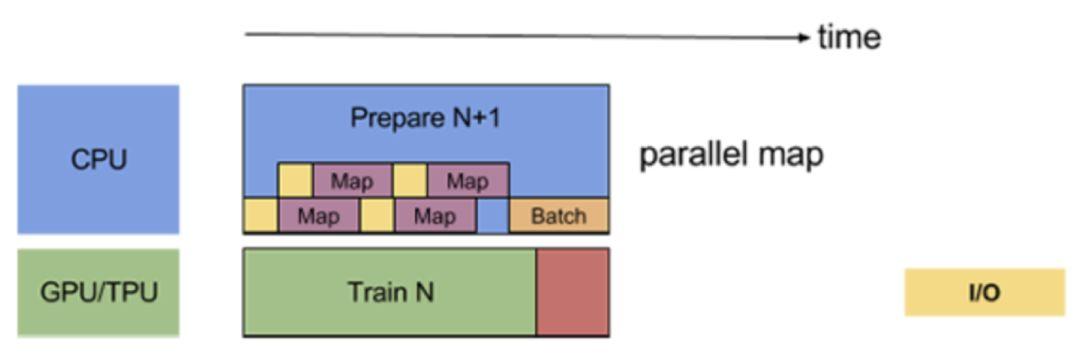
这样的话只要 prefetch的buffer_size和map的num_parrellel_calls取得合适 ,基本就可以实现不间断的train啦,也就是几乎达到100%的GPU利用率!
好啦,思想明白了,代码就容易理解啦。不使用tf.record,直接从预处理好的纯文本格式的数据集load数据时的典型过程如下
def build_input(..):
x = tf.data.XXDataset(..)
x = x.map(..., num_parallel_calls=N) # parellel
y = tf.data.XXDataset(..)
y = y.map(..., num_parallel_calls=N)
dataset = tf.data.Dataset.zip((x, y))
dataset = dataset.repeat(num_epochs)
if is_train:
dataset = dataset.shuffle(..)
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(buffer_size=1) # prefetch
iterator = dataset.make_xx_iterator()
return iterator.get_next()
当然,如果用上
tf.record
后,就不用分别从x和y俩文件中读数据啦,感兴趣的童鞋可自行去了解一下。
补充福利
当然,刚从传统的代码迁移到tf.data+estimator的时候可能会不太适应,最主要的还是debug的方式,不能像之前一样直接session.run(debug_tensor)了,那怎么办呢?
一般来说我们打印tensor有两种情况,一种是计算图出错时需要打印一次或几次来定位问题,一种是像global_step,loss等需要周期性check。对于这两种情况,之前是习惯session.run的时候把要打印的tensor也run出来,而现在这两种情况可以区分对待啦。
对于第一种,小夕感觉最高效的还是直接在计算图里插tf.Print(..),使用非常方便,debug能力很强大!如果打印还需要配合global step,加一条tf.cond就搞定啦。对于第二种,其实global step和loss的话estimator默认就会打印出来,如果是其他需要周期性打印的tensor,那么就用tf.train.LoggingTensorHook包装一下然后丢进estimator.train里吧~习惯之后竟然还感觉挺方便的m(_ _ )m
最后,愿天下没有空闲的显卡
在深度学习中会用到各种各样的数值类型,数值类型命名规范一般为
TypeNum
,比如Int64、Float32、Double64。
- Type:有Int,Float,Double等
- Num: 一般是 8,16,32,64,128,表示该类型所占据的比特数目
常用的数值类型如下图所示( int64 准确的说应该是对应c中的long long类型, long类型在32位机器上等效于int32 ):
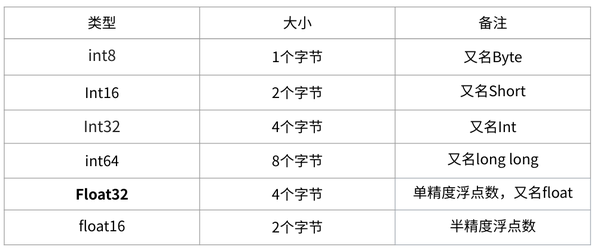
其中Float32 是在深度学习中最常用的数值类型,称为单精度浮点数,每一个单精度浮点数占用4Byte的显存。
举例来说:有一个1000x1000的 矩阵,float32,那么占用的显存差不多就是
1000x1000x4 Byte = 4MB
32x3x256x256的四维数组(BxCxHxW)占用显存为:24M
显卡爆炸
显卡爆炸和内存的使用紧密相连,特别是在代码中对某些变量的不当使用,很有可能内存泄露,从而慢慢得导致显卡OOM(out of memory)。一般来说,计算模型时显存主要是模型参数 + 计算产生的中间变量,细分可以占用分四个部分:
- 模型参数
- 模型计算中间结果
- 反向传播中间结果
- 优化器额外参数
举例来说,对于如下图所示的一个全连接网络(不考虑偏置项b)
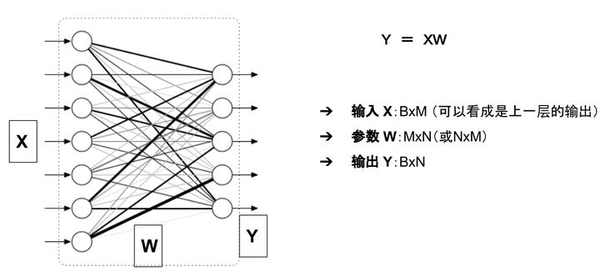
模型的显存占用包括:
- 参数:二维数组 W
- 模型的输出: 二维数组 Y
输入X可以看成是上一层的输出,因此把它的显存占用归于上一层。
参数的显存占用
只有有参数的层,才会有显存占用。这部份的显存占用和 输入无关 ,模型加载完成之后就会占用。
有参数的层主要包括:
- 卷积
- 全连接
- BatchNorm
- Embedding层
- ... ...
无参数的层 :
- 多数的激活层(Sigmoid/ReLU)
- 池化层
- Dropout
- ... ...
更具体的来说,模型的参数数目(这里均不考虑偏置项b)为:
- Linear(M->N): 参数数目:M×N
- Conv2d(Cin, Cout, K): 参数数目:Cin × Cout × K × K
- BatchNorm(N): 参数数目: 2N
- Embedding(N,W): 参数数目: N × W
参数占用显存 = 参数数目×n
n = 4 :float32
n = 2 : float16
n = 8 : double64
在PyTorch中,当你执行完
model=MyGreatModel().cuda()
之后就会占用相应的显存,占用的显存大小基本与上述分析的显存差不多(
会稍大一些,因为其它开销
)。
梯度与动量的显存占用
举例来说, 优化器如果是SGD:
W_{t+1} = W_{t} - \alpha \nabla F(W_t)
可以看出来,除了保存W之外还要保存对应的梯度 \nabla F(W) ,因此显存占用等于参数占用的显存x2,
如果是带Momentum-SGD
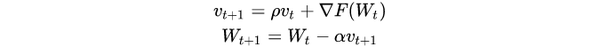
这时候还需要保存动量, 因此显存x3
如果是Adam优化器,动量占用的显存更多,显存x4
总结一下,模型中 与输入无关的显存占用 包括:
- 参数 W
- 梯度 dW (一般与参数一样)
- 优化器的 动量 (普通SGD没有动量,momentum-SGD动量与梯度一样,Adam优化器动量的数量是梯度的两倍)
输入输出的显存占用
这部份的显存主要看输出的feature map 的形状。
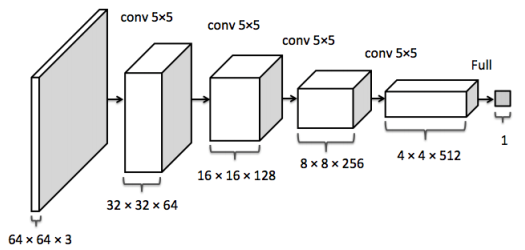
比如卷积的输入输出满足以下关系:
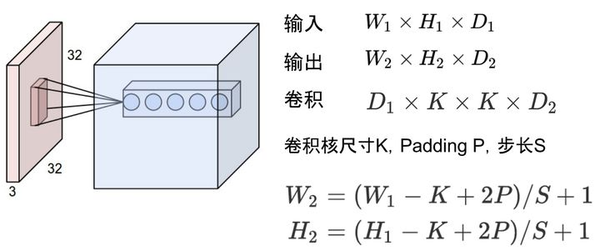
据此可以计算出每一层输出的Tensor的形状,然后就能计算出相应的显存占用。
模型输出的显存占用,总结如下:
- 需要计算每一层的feature map的形状(多维数组的形状)
- 需要保存输出对应的梯度用以反向传播(链式法则)
- 显存占用与 batch size 成正比
- 模型输出不需要存储相应的动量信息。
所有的显存占用计算
显存占用 = 模型自身参数 × n + batch size × 输出参数量 × 2 + 一个batch的输入数据(往往忽略)其中,n是根据优化算法来定的,如果选用SGD, 则 n = 2, 如果选择Adam, 则 n = 4.
深度学习中神经网络的显存占用,我们可以得到如下公式:
显存占用 = 模型显存占用 + batch_size × 每个样本的显存占用可以看出显存不是和batch-size简单的成正比,尤其是模型自身比较复杂的情况下:比如全连接很大,Embedding层很大
另外需要注意:
- 输入(数据,图片)一般不需要计算梯度
-
神经网络的每一层输入输出都需要保存下来,用来反向传播,但是在某些特殊的情况下,我们可以不要保存输入。比如ReLU,在PyTorch中,使用
nn.ReLU(inplace = True)能将激活函数ReLU的输出直接覆盖保存于模型的输入之中,节省不少显存。感兴趣的读者可以思考一下,这时候是如何反向传播的(提示:y=relu(x) -> dx = dy.copy();dx[y<=0]=0 )
优化器参数
优化器参数指的是模型在优化过程即反向传播中所产生的参数, 这部分参数主要指的就是 dw, 即梯度,在SGD中, 其大小与参数一样, 因此在优化期间, 模型的参数所占用的显存会翻倍。
值得注意的是,不同的优化器其所需保存的优化参数不同, 对于 Adam, 由于其还需要保存其余参数, 模型的参数量会在优化区间翻 4 倍。
但是如果模型出现显卡内存不足的错误(torch.FatalError: cuda runtime error (2) : out of memory),很难第一时间确定出问题的所在,不过Pycharm的图形化内存分析工具memory profiler可以看到每一部分的时间和函数引用关系,通过这个工具可以确定出问题的某些行代码。说到工具,也有可以通过htop监控下显卡的:

显存比较常见的一些问题有:
- 全局变量累加导致内存泄漏,如loss变量的处理。这里要注意的是,一定要先和GPU detach了,仅仅使用loss的数值,不然添加的实际上是整个计算图。当然除了loss,其他的变量问题基本上都是出现内存泄露的原因呀。

- 内存垃圾回收。python的变量如果不用了一般不会立即被回收,所以我们可以手动的在每一个epoch里面进行回收。
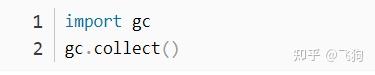
- 多用np.array,而不是list,特别是DataLoader,而且导入时最好先放到cuda中去

- 小心全局变量。
- checkpoint。如果一个模型需要占用的显存实在太大了,那可以使用它分多步进行计算,每次模型都会从上次保存的地方继续训练。
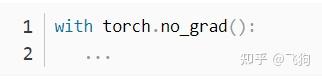
-
爆显存也有可能是忘记设置no_grad(torch.no_grad()是新版本pytorch中volatile的替代),当我们在做 evaluating 的时候(不需要计算导数),我们可以将推断(inference)的代码包裹在
with torch.no_grad():之中,以达到 暂时 不追踪网络参数中的导数的目的,总之是为了减少可能存在的计算和内存消耗。
节省显存的方法
在深度学习中,一般占用显存最多的是卷积等层的输出,模型参数占用的显存相对较少,而且不太好优化。
节省显存一般有如下方法:
- 降低batch-size
- 下采样(NCHW -> (1/4)*NCHW)
- 减少全连接层(一般只留最后一层分类用的全连接层)
- 优化网络结构,或者改用深度可分离卷积代替常规卷积核,较小参数数量
- 选择更小的数据类型
- 一般默认情况下, 整个网络中采用的是32位的浮点数,如果切换到 16位的浮点数,其显存占用量将接近呈倍数递减
- 做梯度累积,将loss划分为n,即loss = loss / n, 当执行完n步再进行梯度更新
降低batch size
这应该很好理解,适当降低batch size, 则模型每层的输入输出就会成线性减少, 效果相当明显。这里需要注意的一点是,
dev batch size
的调整也有助于降低显存, 同时,不要将 dev 或 test 的batch size 设置为样本集长度, 我最近就干了这个傻事,害的我调试了一天才调出来是这个问题。
选择更小的数据类型
一般默认情况下, 整个网络中采用的是32位的浮点数,如果切换到 16位的浮点数,其显存占用量将接近呈倍数递减。
精简模型
在设计模型时,适当的精简模型,如原来两层的LSTM转为一层; 原来使用LSTM, 现在使用GRU; 减少卷积核数量; 尽量少的使用 Linear 等。
数据角度
对于文本数据来说,长序列所带来的参数量是呈线性增加的, 适当的缩小序列长度可以极大的降低参数量。
total_loss
考虑到 loss 本身是一个包含梯度信息的 tensor, 因此,正确的求损失和的方式为:
total_loss += loss.item()释放不需要的张量和变量
采用
del
释放你不再需要的张量和变量,这也要求我们在写模型的时候注意变量的使用,不要随心所欲,漫天飞舞。
Relu 的 inplace 参数
激活函数
Relu()
有一个默认参数
inplace
,默认为Flase, 当设置为True的时候,我们在通过
relu()
计算得到的新值不会占用新的空间而是直接覆盖原来的值,这表示设为True, 可以节省一部分显存。
梯度累积
首先, 要了解一些Pytorch的基本知识:
-
在Pytorch 中,当我们执行
loss.backward()时, 会为每个参数计算梯度,并将其存储在 paramter.grad 中, 注意到,paramter.grad是一个张量, 其会累加每次计算得到的梯度。
-
在 Pytorch 中, 只有调用
optimizer.step()时才会进行梯度下降更新网络参数。
我们知道, batch size 与占用显存息息相关,但有时候我们的batch size 又不能设置的太小,这咋办呢?
答案就是 梯度累加 。
我们先来看看传统训练:
for i,(feature,target) in enumerate(train_loader):
outputs = model(feature) # 前向传播
loss = criterion(outputs,target) # 计算损失
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
optimizer.step() # 反向传播, 更新网络参数而加入梯度累加之后,代码是这样的:
for i,(features,target) in enumerate(train_loader):
outputs = model(images) # 前向传播
loss = criterion(outputs,target) # 计算损失
loss = loss/accumulation_steps # 可选,如果损失要在训练样本上取平均
loss.backward() # 计算梯度
if((i+1)%accumulation_steps)==0:
optimizer.step() # 反向传播,更新网络参数
optimizer.zero_grad() # 清空梯度其实,这块有两种理解方式(受到评论区同学启发), 我谈谈在 bert 里面最常见的那种。
比较来看, 我们发现,梯度累加本质上就是累加
accumulation_steps
个
batchsize/accumulationsteps
的梯度, 再根据累加的梯度来更新网络参数,以达到真实梯度类似
batch_size
的效果。在使用时,需要注意适当的扩大学习率。
更详细来说, 我们假设
batch size = 4
,
accumulation steps = 8
, 梯度积累首先在前向传播的时候以
batch_size=4
来计算梯度,但是不更新参数,将梯度积累下来,直到我们计算了
accumulation steps
个 batch, 我们再更新参数。其实本质上就等价于:
真正的 batch_size = batch_size * accumulation_steps梯度积累能很大程度上缓解GPU显存不足的问题,推荐使用。
以 Pytorch 为例,一个神经网络的训练过程通常如下:
for i, (inputs, labels) in enumerate(trainloader):
optimizer.zero_grad() # 梯度清零
outputs = net(inputs) # 正向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新参数
if (i+1) % evaluation_steps == 0:
evaluate_model()
从代码中可以很清楚地看到神经网络是如何做到训练的:
1.将前一个batch计算之后的网络梯度清零
2.正向传播,将数据传入网络,得到预测结果
3.根据预测结果与label,计算损失值
4.利用损失进行反向传播,计算参数梯度
5.利用计算的参数梯度更新网络参数
下面来看梯度累加是如何做的:
for i, (inputs, labels) in enumerate(trainloader):
outputs = net(inputs) # 正向传播
loss = criterion(outputs, labels) # 计算损失函数
loss = loss / accumulation_steps # 损失标准化