|
|
|


我想写一个歌声合成引擎,求教需要学习哪些音频、声学方面和编程方面的内容?
关注者
311
被浏览
41,260
10 个回答

代码现已开源: https:// github.com/yxlllc/Mathe matica-Voice-Kernel-Codes
目前只有核心算法的部分,注释写得极其详细,基本上能看懂这篇回答以及大致掌握Mathematica就能看懂全部(约300行左右)。
最近很长的一段时间一直在搞GUI的部分,bug非常多,这部分就不开源了,所以真想拿它“调教”的同学可能会有些失望。不过我认为最重要的还是这些算法层面的东西。现在我提供了我自己的思路,大家可以作为参考,自己搞个GUI出来,或者嫌慢的话用其它语言比如C++改写一遍,也欢迎大家指出我的代码中可以改进的地方。
————————————————————————————————————
开发一个性能接近Vocaloid这样的软件是很具有挑战性的,但是,开发一个能听的歌声合成引擎并没有楼上各位所说的那么困难。
首先先上结果,这是我用约为400行Mathematica代码开发的合成系统制作的一首翻唱: https://www. bilibili.com/video/av12 144081
如果你觉得还算“能听”的话,不妨可以参考一下我的学习与实现方法,因为我 从几乎没有专业基础的“小白”到整个系统的开发完成,总用时不到一个月,所用成本几乎为0 。当然,不得不承认它的合成效果和题主提到这些引擎有很大的差距,本人目前是物理系大三学生,并没有系统上过软件设计和数字信号处理(DSP)之类的课程,知识储备很有限,如有专业人士能指出我回答中不专业的部分,甚至能给出改进我合成系统的方法,在下不胜感激!
下面正式进入问题的回答部分。
首先,你至少需要熟练掌握一门基础编程语言(比如C语言),最好能够再熟练使用像Matlab, Mathematica这种计算软件。后者能够帮助你节省大量开发时间,举题主标”1“的问题为例,在Mathematica中,将wav文件中的波形信息转换成可供处理的数据只需要一行简单代码:
data=AudioData@Import[“音频文件地址.wav”];运行后变量data就成为了存储波形数据的数组,可用于之后的一系列数学运算。
有了这些编程语言的基础,我们现在就可以开始编写一个歌声合成系统了。
首先,我认为设计任何一个这样的合成系统,第一阶段音源的设计是非常重要的。我认为,你无论采用什么方法,它至少要能达到: 能够覆盖人类歌曲中所能出现的一切正常歌词发音 (像B-Box、阿卡贝拉这样”非正常”的可以不考虑,不过要是真包含进去那就相当厉害了),或至少是覆盖某种语言,比如普通话。以“袅袅虚拟歌手”这款软件为例,根据它的官方教程( http:// yuyinniaoniao.com/docs/ src/1rec )最基础的音源数据库构建,需要录制412个中文拼音的一声发音。如果你选择采用拼接为主的算法,那么至少也需要一个齐全的音素数据库,并按照元音辅音分类,这样才有可能拼接出各种可能出现的歌词发音。如果是采用Cevio这样的思路,那些用做HMM模型的训练样本的也是要经过设计的,不过这目前大大超出了我的水平。这个坑确实很深,深入研究的话需要很多语言学的知识。
不过不着急,我们可以 耍赖地使用TTS系统 (即Text To Speech,文字转语音的合成系统)直接完成第一阶段的开发。现在各大IT公司几乎都有自己的TTS产品,比如国外有苹果的siri,,微软的cortana,谷歌最新开发的wavenet,国内有百度语音和讯飞语音等,且有许多公司开放了SDK接口,可以免费安装下载这些TTS引擎。
甚至,你根本不用下载任何东西。Windows 10系统自带了Microsoft Speech Platform,它内置了一个被称作Microsoft
Huihui Desktop (微软慧慧桌面版)的中文TTS引擎。只要你打开cmd输入几句PowerShell脚本命令运行就能立刻让微软慧慧发声:
Powershell “Add-Type -AssemblyName System.Speech;$synth=New-Object System.Speech.Synthesis.SpeechSynthesizer;&synth.Speak(‘说话内容’);”其中“说话内容”可以是中文也可以是英文,可以是单字也可以是词组或句子。另外在脚本中增加其它命令可调整语速和音量等参数,并且可以设置是否输出wav文件,具体可以参考以下链接: https:// msdn.microsoft.com/zhtw /library/system.speech.synthesis.speechsynthesizer.aspx
这样一来,题主标“2”“3”“4”就直接解决了,因为我们根本不需要人类录制音源,不需要了解背后的语言学知识和相关算法。这些问题那些大科技公司已经帮你解决了。
在音源系统设计好之后,我们接下来可以正式进入第二阶段核心算法流程的开发了。正如前面的回答所提到的,许多相对成熟的算法都有开源代码的实现,并且DSP领域有很多适合小白入门的书籍。不过事实上,很多相对基础的概念在维基百科上都有很好的阐述,在翻开厚厚的教科书之前,不妨先上网查一查。 下面我将分享一下我的400行Mathematica代码中,核心部分的大致工作流程,在大方向上属于 基于变速和变调的合成 (比较有代表性的软件是UTAU),希望能对有这方面开发打算的刚入门同学有所帮助(大量干货预警)。
第1步:根据前面所说,首先用PowerShell脚本调用微软慧慧TTS,将歌词字符串生成的wav文件音源导入Mathemaica
第2步:指定帧长和帧偏移量,将音频按顺序切分成一系列重叠帧
比如音频总长1s,帧长设置为0.1s,帧偏移量设置为0.05s,那么第一帧就是0s~0.1s,第二帧是0.05s~0.15s,第三帧是0.1s~0.2s......最后一帧是0.9s~1s。
第3步:对每一帧应用加窗的高精度傅里叶变换
具体操作是先将每一帧加窗(测试发现Hamming窗的效果较好),之后补上帧长数倍数量的0(比如数据是“1234”,加帧长一倍数量的0就是“12340000”),然后对其做快速傅里叶变换(FFT)得到高精度的频谱数据。
第4步:对于每帧,在一定频率范围内,直接读出第一个频谱峰值(取复数模)的横坐标位置,计算得到该帧的基频 f_{base} ,并计算出目标基频 f_{goal} 与 f_{base} 之比k
这里说一下,如果没有颤音即频率波动的话,那么一般目标基频与midi note的换算公式可以由如下公式表述:
f_{goal}=440*2^{\frac{note(goal)-note(A4)}{12}}Hz
现在通用的国际标准音叉的频率是440Hz,对应音符A4, midi note为69,以上公式适用于所有基于十二平均律设计的乐器。
这是唯一需要 乐理和midi相关知识 的一步。因为我们最终是要制作音乐,所以单单只了解DSP相关知识是不行的,不过不需要了解太深。
第5步:对于每帧,选取合适的df(跟第3步选取的窗函数密切相关),计算 (i f_{base}-df , i f_{base}+df) 内的频谱数据的复数模方和(即在该范围内的频谱能量)再开方(i=1,2,3…),得到不同倍频处的近似振幅,即泛音数据
泛音 以及 共振峰 (泛音中振幅较大值所处的位置)是非常重要的概念,它对于 音色和音素的辨认 是至关重要的,这方面的知识最好要深入了解一些。
第6步:用多项式插值的方法拟合第5步得到的泛音列数据,得到关于频率的共振曲线F(f)
第5和第6步合起来的整个目的是得到下图上方的这条曲线,拟合次数不要太高(实际上线性拟合的效果就已经很高了)。
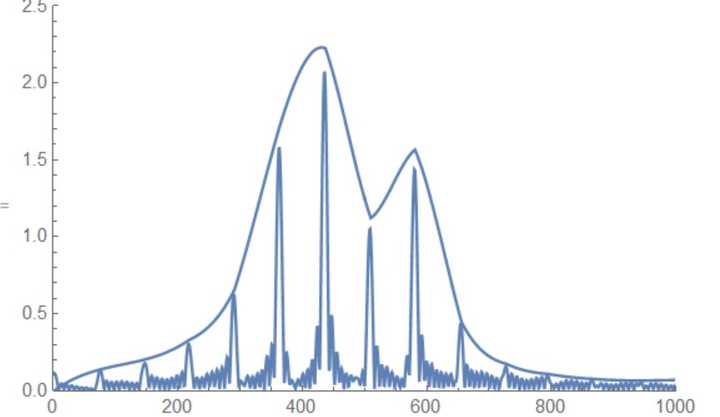
这个是微软慧慧元音ʌ频谱图,可以看出在频率1150Hz左右有一个共振峰(横坐标并不是频率,大概差了2.7倍)。维基百科”Formant”词条( https:// en.wikipedia.org/wiki/F ormant )总结了不同元音的平均共振峰位置。
第7步:对于每帧,计算共振峰修正曲线 \frac{F(kf)}{F(f)} ,以其为 滤波器 进行滤波,将频谱数据还原为波形数据(做快速傅里叶逆变换IFFT,去掉之前在尾部补充的那若干个0,再做除法去掉原来的窗函数)
第8步:对于每帧,应用 重采样 算法将共振峰修正过的波形数据重采样为原来长度的1/k
第7和第8步合起来完成了变调同时“保持音色”的工作。如果没有第7步(那么第5、6步也不需要)而只有第8步,则共振峰的特性将被破坏,这是因为傅里叶变换有一个非常重要的性质,那就是重采样运算在时域和频域上是互逆的,即对于时域上的重采样:
y(t)=x(kt)
在频域上其相应的傅里叶变换满足:
Y(f)=X(f/k)
这将导致共振峰的整体偏移,举个例子来说,如果我将微软慧慧元音ʌ重采样为原来长度的80%,k取0.8,那么基频将上升至原来的1.25倍,但同时共振峰从原来的约1150Hz也上升至1450Hz,此时音色将发生明显的改变。第7步的滤波操作就是为了补偿重采样所带来的共振峰整体移动。
第9步:根据目标音长,将所有经过共振峰修正后的重采样帧用 SOLA算法 连接起来
SOLA是常见的也是性能较好的音频连接与算法,在此就不介绍算法的具体细节了。
以上就是整个工作流程的大致介绍,其中有很多的诸如算法参数选取等具体细节,还有一些计算复杂度的问题(调用声卡或显卡做并行计算的设计)。另外还有一些关于合成性能的细节(即题主标6的一系列问题),我可以试图做一些回答:
(1)BRI声音洪亮程度:不懂…
(2)BRE声音沙哑程度:不懂…
(3)OPE开口大小:可以在第9步实现,即对音源的不同部分应用不同的变速速率。
(4)GEN性别因子:可以改动第7步。“性别”在声音上的体现也是音色的一种,跟共振峰的位置是密切相关的。对于同样的音素,一般男声的共振峰频率要低于女声,差距大概在4个半度这样的量级。因此我们可以改动共振峰修正曲线,将 \frac{F(kf)}{F(f)} 改为 \frac{F(gkf)}{F(f)} ,增加一个参数g,g>1音色往“男”性方向偏移,g=1音色保持不变,g<1音色往“女”性方向偏移。之所以加引号是因为这个模型过于简单,与真实的人类发声的物理机制有所差距。
(5)PIT频率曲线:调整第4步中各帧的 f_{goal} 即可
(6)情感因素:不懂…
如果你已经完成了前两个阶段的开发了,那么可以认为你的合成引擎已经成形,接下来就是第三阶段图形用户界面(GUI)的开发了。当然,如果你开发这个引擎只是给自己玩的或以偏学术研究目的为主,那么其实这一步几乎不那么重要。就像我一样,我的代码几乎全部是最核心的算法部分,然后就用了不到100行Mathematica代码写了个极其简单的GUI界面,大概长这个样子……
最后选择性的回答题主关心的一些其它问题。
首先是关于量化的歌声合成质量的问题,我认为需要从两个维度来考虑这个问题。一个维度是“接近人类”的程度,我认为这是可以量化的,以大量人类歌声为训练样本然后搞个神经网络来打分?另一个维度是“是否好听”的维度,我认为这基本上没法量化,因为音乐或者艺术这种东西本来就是很主观的,并不一定越“接近真实”越是好的艺术,甚至有时候相反。比如机器人学中的 恐怖谷理论 :当机器人与人类相像超过一定程度的时候,人们的反应便会突然变得极之反感,哪怕机器人与人类有一点点的差别,都会显得非常显眼刺目,直到相像程度进一步提高到某个数量级后。所以,歌声合成这方面会不会出现类似的“恐怖谷”呢?以目前的技术水平来看暂时还无法回答。
然后是关于“逆向工程”的问题。怎么说呢,如果你是像我一样只是为了自娱自乐的话,且不和任何人分享,搞破解当然可以(反正没人知道),商业化的话当然是不行的……
最最后,我想说一些题外话。如果你真的下定决心想要搞这么一个东西,最好是因为自己真的有兴趣去钻研这些东西,而不是仅仅是跟风觉得这个东西很酷。另外,不要太看中结果,毕竟专门靠这一行吃饭的人也是少数。也许你辛辛苦苦开发出来的东西得不到别人的认可,但是你 在开发过程中收获到的关于数学、编程、DSP、乐理甚至是语言学的知识,永远是一笔宝贵的财富 。总之,我希望如果遇到困难不要轻易放弃,因为, 比想象力更难的,是按照自己价值观行动的勇气 。

首先谢题主邀。其实我看到这个邀请是诚惶诚恐的,因为自己在这里没有什么干货可讲,还请各位见谅。
我注意到题主打上了“逆向工程”的标签,首先希望题主不要去做任何侵犯知识产权的事(虽然逆向工程不一定是侵权的,比如符合“合理使用”的),尤其是试图对 VOCALOID 进行拆解研究。因为 VOCALOID 产品的许可协议书[1]明文指出:
用户不得以任何方式对EDITOR及LIBRARY进行反编译、拆卸、逆向工程或者其他途径获取源代码,并不得全部或部分复制、修改、改变、租赁、出租或者经销EDITOR及LIBRARY,或者制作衍生产品。
此外,VOCALOID 在包括日本、美国在内的多个国家受专利保护,在中国也是如此(CN100337104C、CN100524456C)。侵犯知识产权不仅是非法的,而且是令人所不齿的。
Rocaloid 在前期开发过程中一直是侵权的(试图在破解其格式的基础上分解 VOCALOID 的数据库,并重新组合),后期不但有了自己的引擎、UI,好像还有了自己的数据库格式,而且也开发出了能让 UTAU 使用该引擎的接口,我没有持续关注这个项目,所以对现在他们的进展不是很了解。但是作者一开始是打着实现让 Miku 能演唱中文的梦想的旗号开发的,作者的爱、决心和毅力,以及强大的学习能力固然是令人敬佩的,但选择了一个错误的方向实在可惜。
我想说的第二点是希望题主多参考和学习前人的成果,而不是在这里猜测、脑补和当伸手党。(我曾因此被人骂得狗血喷头。)题主提到的一些参数在 iVocaloid 论坛和 Vocaloid Wiki 等处都有很多对于原理的猜测,UTAU 也对其中一些进行了模仿实现,这些都是很好的学习材料。关于语音合成、信号处理等,有很多专著、专利、论文(据说 VOCALOID 也有论文,但是没有被找出来)可读,也有如 HTS(基于 HMM 的语音合成系统,CeVIO 便是基于此,另一个由此项目衍生的“产品”是Sinsy)等发展多年的开源项目。 这些很多都是合法而且能免费取得的,题主没有必要去冒侵犯版权的风险。
其实题主与其去发明一套新的合成系统,不如去了解已有的系统,再对其改进或移植。比如著名的开源语音学软件 Praat 中有一个质量比较好的 OLA 合成引擎,我利用它的脚本功能和命令行界面,使用 C++(现在改为 Python 了)把它封装成了一个适合 UTAU 使用的引擎,在对一些录制效果比较好的采样进行合成时有锦上添花的效果,还是相当令我满意的。
鉴于达成这一目标需要攀登许多学科的高峰(除容易想到的语音学、信号处理和一些程序设计知识外,题主提到的话题应该还包括软件工程、统计学等),而且其中一些甚至是科班研究人员研究多年都难以解决的问题。我作为一个精力有限的渣渣,已经知难而退了。最后祝楼主好运。先写这么多了,如有疏漏,还请不吝指教。
[1] 来自零售版洛天依的安装程序,内容与其他 VOCALOID 产品的授权许可基本一致,应该是自日文原文翻译而来。
-----
更新一下,想再说几句。乐器声音的合成和人声合成还是有很多差别的,希望题主不要把其中的差距想得过于简单。在如今存储空间飞速增长的时代,乐器音源几乎已经走上了堆叠采样的不归路,这样也确实能有非常好的效果。但人声的多变性(语音学上的、发声方法上的等等)和“采样对象是人”决定了穷举所有可能的组合(比如像钢琴音源把 88 个键分不同力度级都录一遍)是不现实且不可能的,所以如何在简化录音过程和获得好的效果之间取舍是一个非常重要的一点。(而语音合成[speech synthesis]由于要面对很多嵌入式设备还必须压缩到一个非常小的体积。)合成人声时还必须考虑如何在伸缩和变调后还能维持语音特性(比如共振峰,因为例如在升高音调之后共振峰也会整体上移,出现如 VOCALOID 中 GEN 升高一般的效果)。题主可以参考 UTAU 作者的演讲稿做一个初步的了解,翻译版:
utau演讲_中文R1.pdf。还有如何去管理采样,虽然没有 text-to-speech 那样需要考虑多音字之类的问题,但是也要考虑如何把音素连接成音节,如何把音节连接成词,如何连词成句,还要考虑语音(可能比音素更小)由于前后文的影响发生的变化等等,这些恐怕要建立在一定量的统计分析之上。至于语音合成质量,是有评分方法的,叫做 MOS(Mean Opinion Score)。