


深度剖析数据结构背后的数学结构:序,因果,映射
“温故而知新,可以为师矣”
一:从疑问到重构
大量的经典教材和教程都是按功能来讲解数据结构的,学完数据结构你发现你不得不掌握以下名词:


这些经典教程无一例外都缺乏对数据结构进行全局理解的框架,导致我们对数据结构各个类型的理解缺乏连续的逻辑,虽然这不太影响我们的日常编程工作,但是总有一种
知其然不知其所以然
的神秘感觉,每次的学习
全靠记忆
和
经验
来大力出奇迹,缺乏悟道的快感,久而久之,个人经验随着好奇心动力不足而逐渐消逝!
比如:以下疑问经常浮现在我的大脑
1:动态数组和红黑树之间哪些区别是什么,共性是什么?
2:为什么必须构建一个“先进后出”的栈?
3:链表和连续存储数组背后的差别到底是什么?
4:带回路的图为什么不是可用的数据结构?
... ...
总之,数据结构中的“
结构
”,到底是什么东西?
什么是结构
?
数据为什么必须有结构
?
结构是干啥的
?
带着这些疑问,我开始着手”
重构
“数据结构的
理解和定义
,但是鉴于自己的数学功底不足,所做的“
重构
”,只能起到抛砖引玉的作用,个人认为不是很严谨,更多的是借用了一些数学概念来提高
思维的俯视力
,基本的手法是构建一个数学基础来抽象数据结构的核心骨架,同时也希望从另外一个角度来观察
数据结构的整体性质
。
二:如何弄清楚“结构”一词? 数学上有类似概念吗?
于是搜索"
数学 结构
",还真有,超出意外!这是一门我从未听说的数学类型:
近世代数
,
再参考一些数学科普:
从五次方程到伽罗瓦理论
,以及知乎上一些讲解,我抽出2个概念,来解释
数据结构
的
精髓
:
序。
1:
数据结构就是为了
找“序”
,有什么序就决定有什么性质,至此整个数据结构任督二脉全部打通!
2:
任何算法操作只有一种序,即:顺-
序,以及它的逆运算:栈-序,任何算法都可以转换为该序的有限组合,即图灵机序
三:数学3个基础概念,以及先决知识点
A):布尔巴基学派看待数学的一种观点是:
1: 序结构 :集合的两个元素之间的一个序关系,如:比大小,包含关系
2: 代数结构 : 集合上的运算(如+-×÷/等任意操作),构建集合的元素之间的映射:A×A→A,群环域格都是代数结构
3: 拓扑结构 : 集合上定义的开集,构建空间几何
参考资料:
B): 全序和偏序
1: 全序 :集合中任意两个元素可以比较大小,如:全体实数任意2个元素是可以比较大小的,所以是全序
2: 偏序 :集合部分元素部分可比,如:全体复数中实数域是可以比较的,但是实数却无法和虚数i比较大小,所以复数域只具备偏序,俗称: 部分可比较 ,所以叫“ 偏 ”
参考视频教学:
C): 二元关系的性质
自反性VS反自反性
1: 自反性 :任一个A中的元素x,如果都有<x,x>∈R,则称R是自反的。例如:
同姓关系 :任何一个人自身和自身的姓氏相同
小于等于关系 :任何一个数都小于等于自己
包含关系 :任何一个集合都是自己的子集
整除关系 :任何一个整数都是整除自身
2: 反自反性 :任一个A中的元素x,如果都有<x,x>∉R,则称R是反自反的。例如:
父子关系 :任何一个人都不能是自己的父亲或者儿子
小于关系 :任何一个数都可能小于自己
真包含关系 :任何一个集合都不能真包含自己
对称性VS反对称性
1: 对称性 :任一个A中的元素x,y,如果<x,y> ∈R ,那么<y,x> ∈R,则称R是对称的。例如:
同姓关系 :x和y同姓,那么y和x也同姓
朋友关系 :x和y是朋友,那么y和x也是朋友
同余关系 :当且仅当 x≡y (mod)n(x≡y (mod)n表示x,y除以n的余数相同)称此关系为模n的同余关系。举例:5和1除以2都余1 ,300和2除以2都余0,这些都叫同余。
2: 反 对称性 :任一个A中的元素x,y,如果<x,y> ∈R ,且<y,x> ∈R上,那么x=y,则称R是反对称的。例如:
父子关系 :x和y是父子关系,以及y和x也是父子关系不能同时成立,即2个人不能互为父子关系
小于等于关系 :如果x<=y , y<=x,那么只能是x=y的情况,满足反对称定义
包含关系 :如果2个集合相互包含,那么这2个集合必定相等,也满足反对称定义
整除关系 :如果x能整除y,y也能整除x,那么x=y,满足反对称定义
传递性 :任取一个A中的元素x,y,z,如果<x,y>,<y,z> ∈R ,那么 <x,z> ∈R,则称R是传递性。例如:
同姓关系 :如果 x和y 同姓,y和z同姓,那么x和z也同姓
小于关系 :如果 x<y , y<z 同姓,那么 x<z
包含关系 :如果集合Y包含X,集合Z包含Y,那么Z一定包含X
整除关系 :如果y能整除x,z也能整除y,那么z也能整除x
飞机航线可达关系 :如果从x城市能到达y城市,y城市也能到达z城市,那么x城市也能到达z城市
也有一些非传递性关系,例如:
父子关系 :如果y和x是父子关系,z和y是父子关系,那么z和x是爷孙关系
朋友关系 :x和y是朋友,y和z是朋友, x和z不一定是朋友
偏序: 设R是非空集合A上的关系,如果R是自反的,反对称的,和传递的,则称R是A上的偏序关系。
全序:如果R是A上的 偏序关系 ,那么对于任意的A集合上的 x,y,都有 x <= y,或者 y <= x,二者必居其一,那么则称R是A上的全序关系。








参考视频教程:
四:重要结论:
通过以上3个知识点,我们可以得到一个关于数据结构的基本结论:
如果一个数据结构局部能满足
(R,<=)
,且整体又是通过局部
递归来
定义的,那么整体也能保持
(R,<=)。
即我们可以通过构造一个
最小
局部序关系如
(R,<=)
,
在通过
递归定义整体
,
新设计的数据结构
就必然具备:
序。
如果
最小局部是偏序关系
,那么整体也将是偏序关系; (如最大堆最小堆)
如果
最小局部是全序关系
,那么整体也将是全序关系; (如2叉搜索树等)
参考视频教程:
五
:任一全序都
存在
一个最优搜索复杂度,且必定为
lgN
,并和数据结构类型
无关


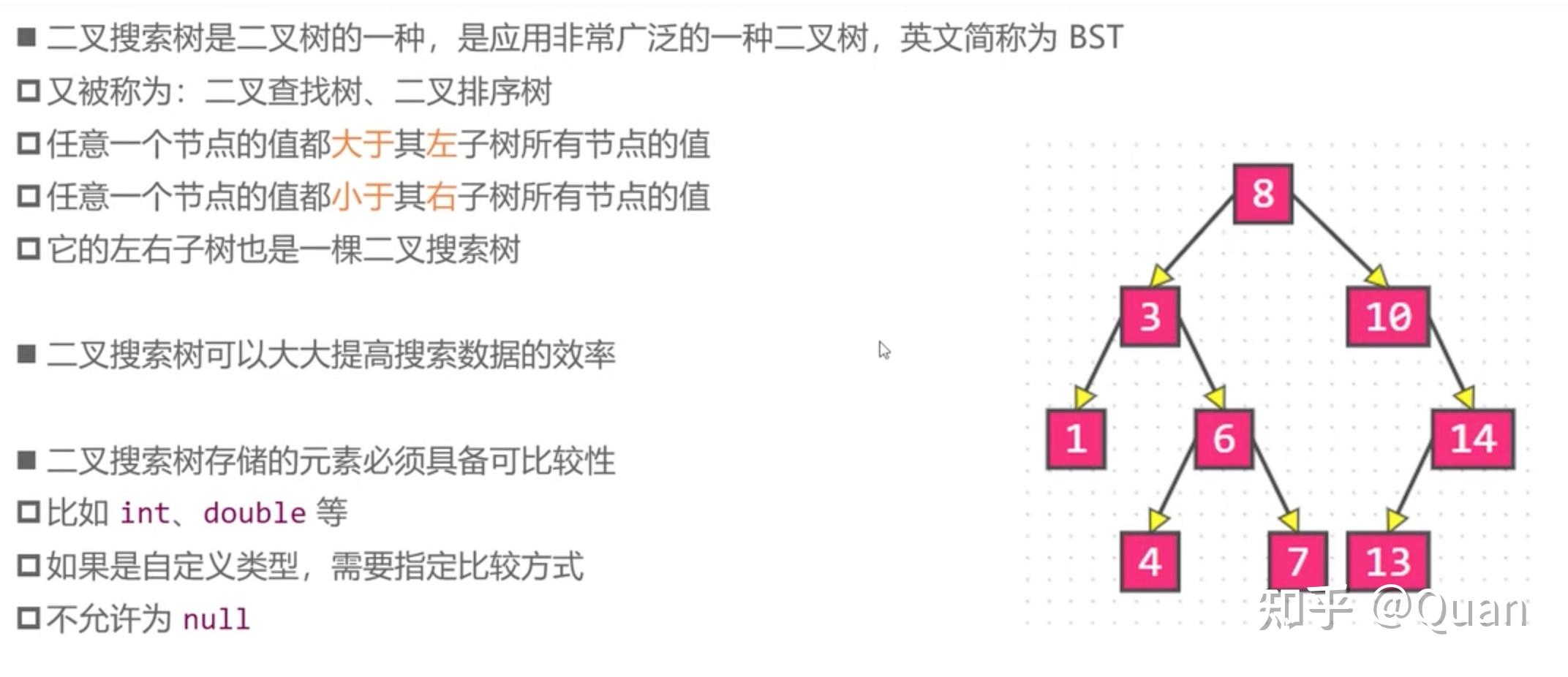

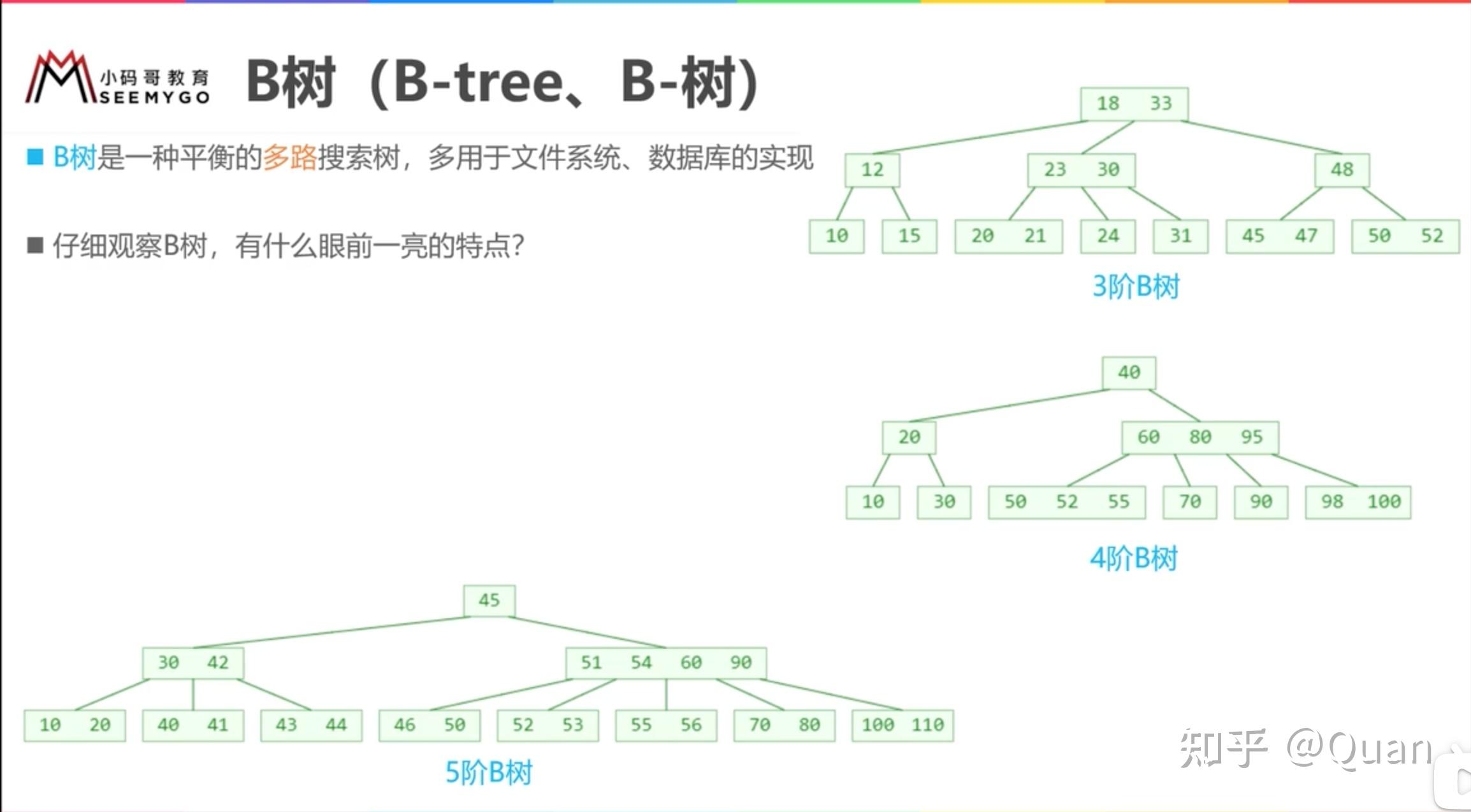

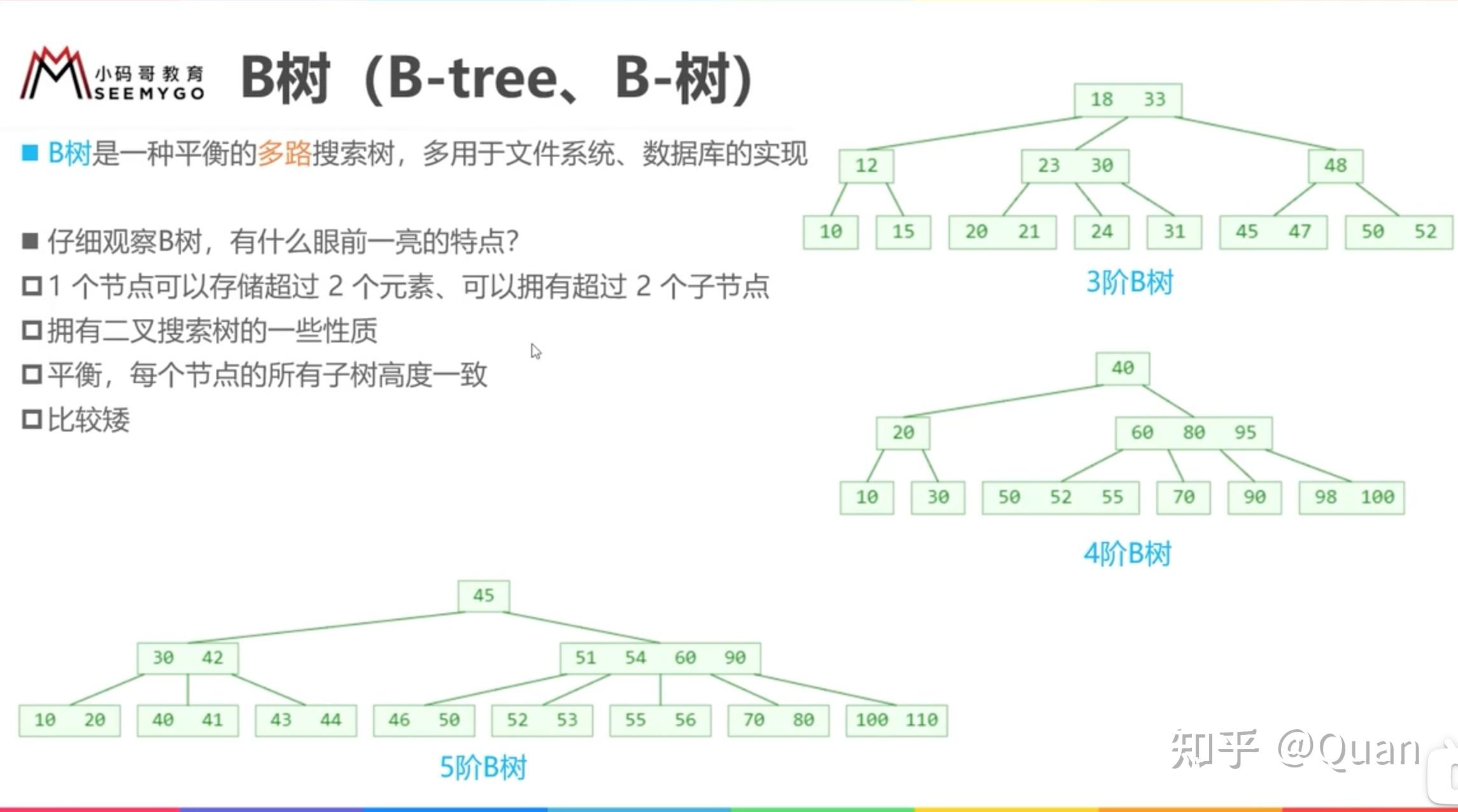

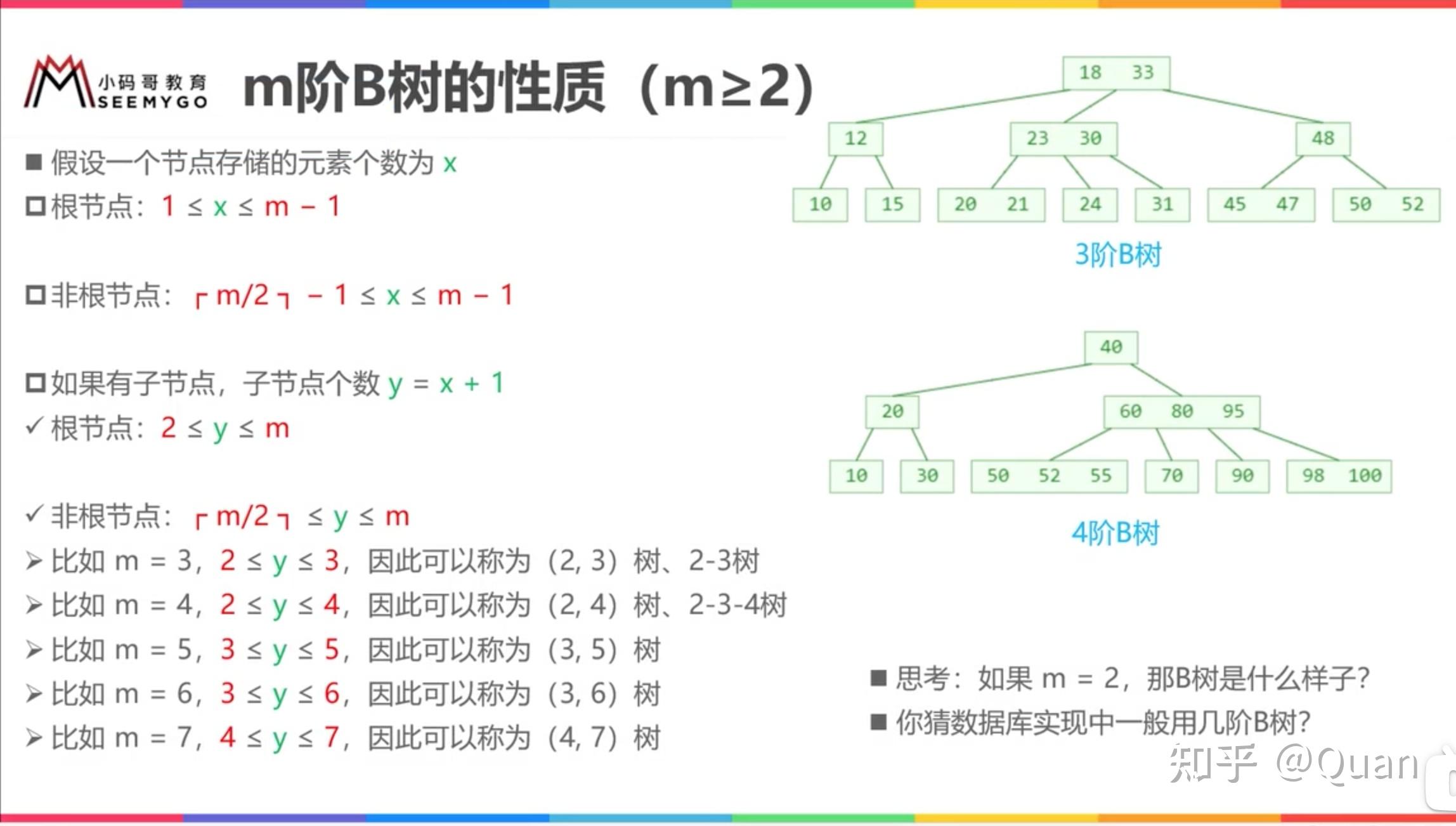
无论B树
父节点是多么长的有序数组
,它和
其子节点依然组成的依然是一个
全序关系
,即不管
B树是多少阶
,其
局部依然是
全序关系
,而每次的比较操作都是O(1)级别的,所以它的搜索复杂度最优值依然为:
lgN!(
注:文件系统一般使用200-300阶的B树
)
所以全序的搜索性能,和数据结构类型无关。仅从树结构来举例:不管有树有多少分支,不管是2叉,3叉,还是4叉,或者是N叉;节点上存储不管是存储1个数,还是2个数,还是3个数,异或是K个数。
它的最优搜索的关键要素是:全序!而只要是全序的,它的
搜索复杂度
最优值必然
为:
lgN
递归定义请参考:上下文无关文法
六:链表必然是无序的,即它的搜索复杂度最小值为:O(N)


因为即使链表整体“
有序
”的,折半查找对链表搜索也不能达到O(logN)的效率。只有
按照一定映射规则访问集合特定节点
的代价是
常量O(1)时
,折半查找才能达到O(logN),而链表访问其中元素的平均时间是O(N)即线性时间。全序数组才能使用折半查找。即如果想要搜索,最坏的情况必然要枚举每一个元素。
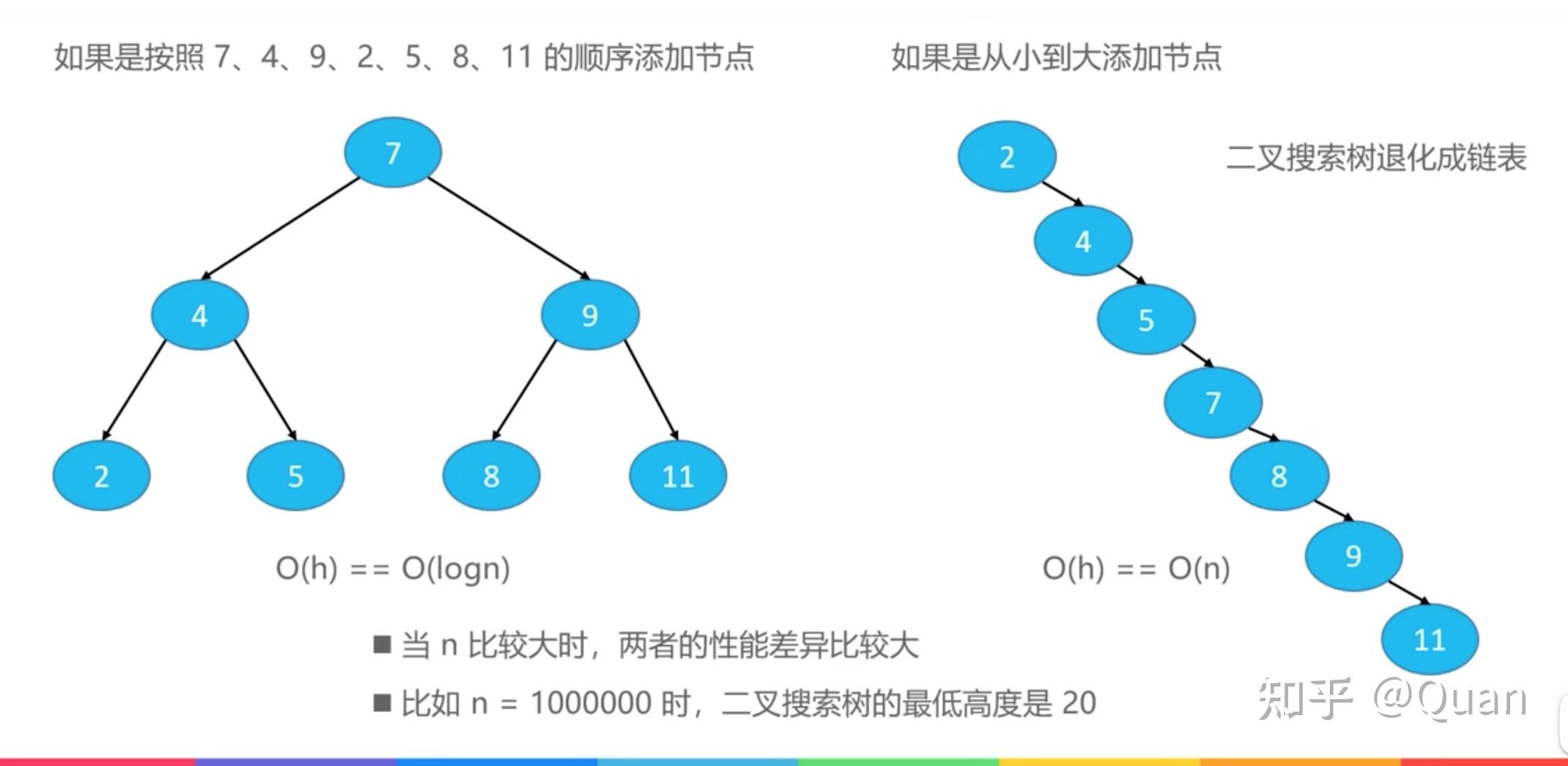
二叉搜索树也是一种有序链表,为什么它可以做到O(logN)?
那是因为二叉搜索树需要做类似“二分查找”的时候,它的
映射规则竟然就在它的左右2个子节点上,保证下一次比较的复杂度为
O(1),这就是
递归定义
的奥妙,
保证局部和整体的自相似性
。
当然如果,二叉搜索树退化成链表,尽管它还是二叉搜索树,那么的搜索性能也要退化到O(N),此时它是失序的!

那么
多层有序链表
,搜索可以做到O(logN)吗?答案是
否定的
,比如:
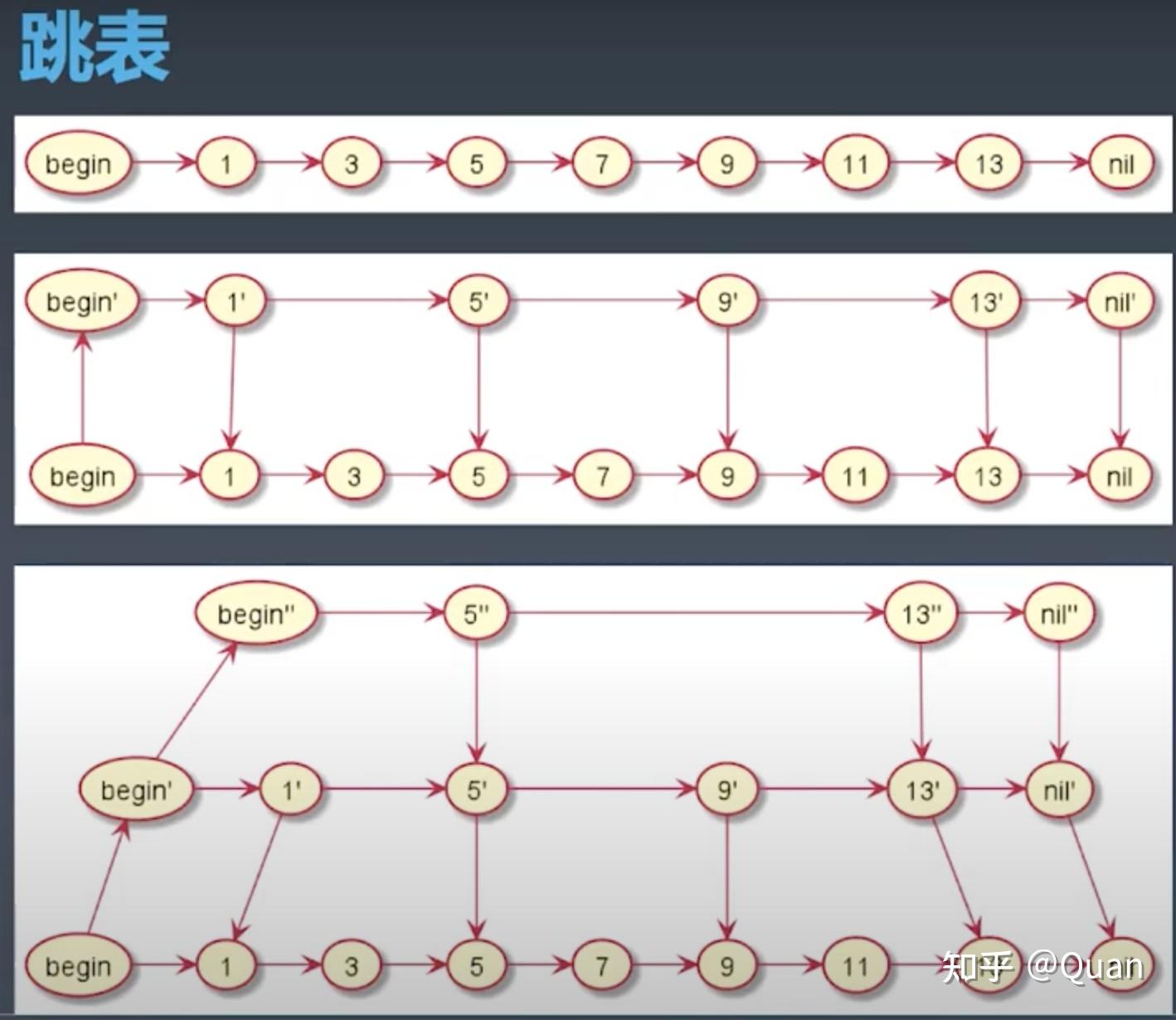
跳表

网上有大量的文章和所谓的证明都认为跳表的搜索性可以做到
O(logN),然而这些文章和观点都是
错误的!他们没有抓住最核心的序关系,以及设计巧妙的O(1)操作。错误的文章如:

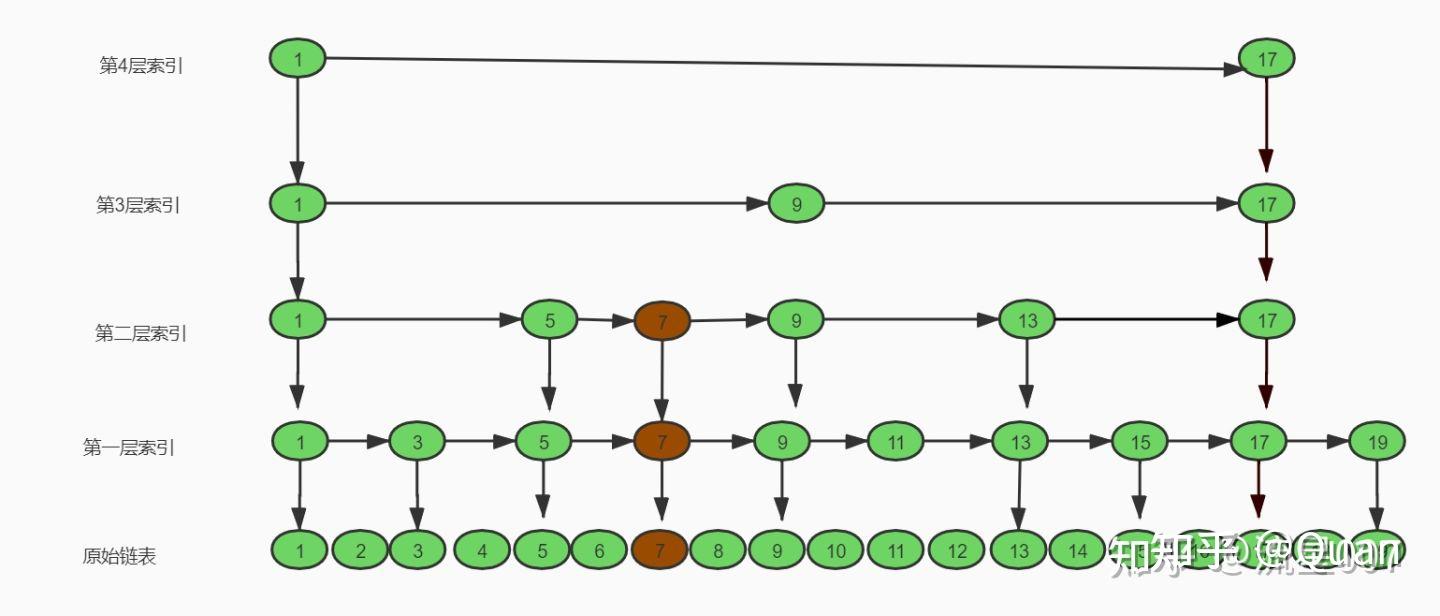
跳表每一层链表都是有序的,且底层的链表局部集合都小于等于上一层链表局部结合,尽管构成全序关系,但在每一层的比较操作必然是O(N)的而不是O(1),所以全序关系的特性并没有挖掘彻底。观察下上图:
从第4层索引开始从2个元素中找到最大值17的复杂度为:O(1)
接着第三层索引从3个找到9,17也可以做到O(1),但需要空间复杂度配合
第二层索引从6个元素中找到7,复杂度突然上升到O(K)
第一层索引从10个元素中
访问
映射规则的元素
又回归到O(1),经过一些算法和内存配合是可以实现的
底层元素从17个元素寻找,局部元素个数等于3的复杂度为O(1),大于3局部的一定是O(K)级别的。
所以跳表结论是:跳表即使表达了全序关系,但它的
映射规则并不能保证下一次比较的复杂度为
O(1),部分比较还包括O(K)级别的操作,所以它的搜索复杂度必然小于O(logN),但是可以做到足够接近O(logN)
虽然链表是无序的,典型的链表是不支持比大小的,导致它在实数域中无法构建一个<=或者>=的
序关系
。但这不代表链表是不支持R关系的。链表的关系可以支持前驱和后驱的。假设链表R的关系为:后驱关系,这非常类似于父子关系(前驱也一样),而父子关系显然
不满足自反性
,但是
满足反自反性
,
满足反对称性
, 也
满足传递性,所以该R不满足偏序的定义,如果满足不了偏序,就满足不了全序。
显然我们可以把链表定义成:描述前驱或者后驱结构的R二元关系,这样就能在O(1)的操作下获得前驱或者后驱,这也是一个优秀数据结构定义的3个必备条件:
1:局部序或者关系
2:局部O(1)的操作
3:满足传递性
其实
数组
也是前后驱关系,从二元关系上看,它的定义和链表一样,
本质也是失序的
,但全序数组却可以获得O(logN)的性能的是来源于
逻辑全序
而
不是关系性质
,其背后基于一个O(1)操作的内存双映射。
总之:如果要使用
前后关系
来
管理你的数据
,你只需要定义一个
局部前后关系性质的结构
即可。它可以是:
数组,链表,双链表,循环链表,图(新增了出度和入度而已),并查集等。
前后关系,可以理解成因果关系,也可以想象成递推关系,条件关系或逻辑关系,它是另外一个描述思维的重要工具
。
至此我们拥有了
2
个重要的
数据思维
工具:
1:序关系
2:因果关系(传递性)
补充资料:离散数学 →的箭头意义
如果则:p→q <=> ┐p∨q
当且仅当:p←→q <=> (p→q)∧(q→p)
七:偏序, 堆,冠军
二元关系下的偏序,有一个非常出名的应用是:足球淘汰赛,那也是一个寻找冠军的游戏!
假设某年世界杯上:
小组A(中国队,日本队,韩国队,越南队)
小组B(巴西队,阿根廷队,德国队,法国队)
比赛大致的流程:
第一轮:
小组A:(中国队,日本队,韩国队,越南队) --->第一轮淘汰2名,剩下(韩国队,中国队)进入半决赛
小组B:(巴西队,阿根廷队,德国队,法国队) --->第一轮淘汰2名,剩下(巴西队,法国队)进入半决赛
第二轮:
(巴西队,法国队,韩国队,中国队)--->第二轮淘汰2名,剩下(巴西队,法国队)
第三轮:
(巴西队,法国队)--->争夺冠亚军,(法国冠军,巴西亚军)
(韩国队,中国队)--->争夺季军,(韩国OUT,中国队季军)
颁奖:
法国冠军,巴西亚军,中国队季军
该比赛规则就是偏序,相对全序,
不用每个队都和另外一个球队比赛一次才一决雌雄(假设全球100支球队,两两比较,值为:
{ 100 \choose 2 }
=
100*99=9900次,这种赛事安排在现实中几乎无法付诸实施)
,只要求部分
区域具备大小关系
,就可以找到
冠军
。这个规则最大的好处,能确保以
最高效率的方式选拔冠军。
但该比赛规则是不是最公平的最有序的规则?答案是否定的!
因为中国队获得了季军,你觉得公平吗
?
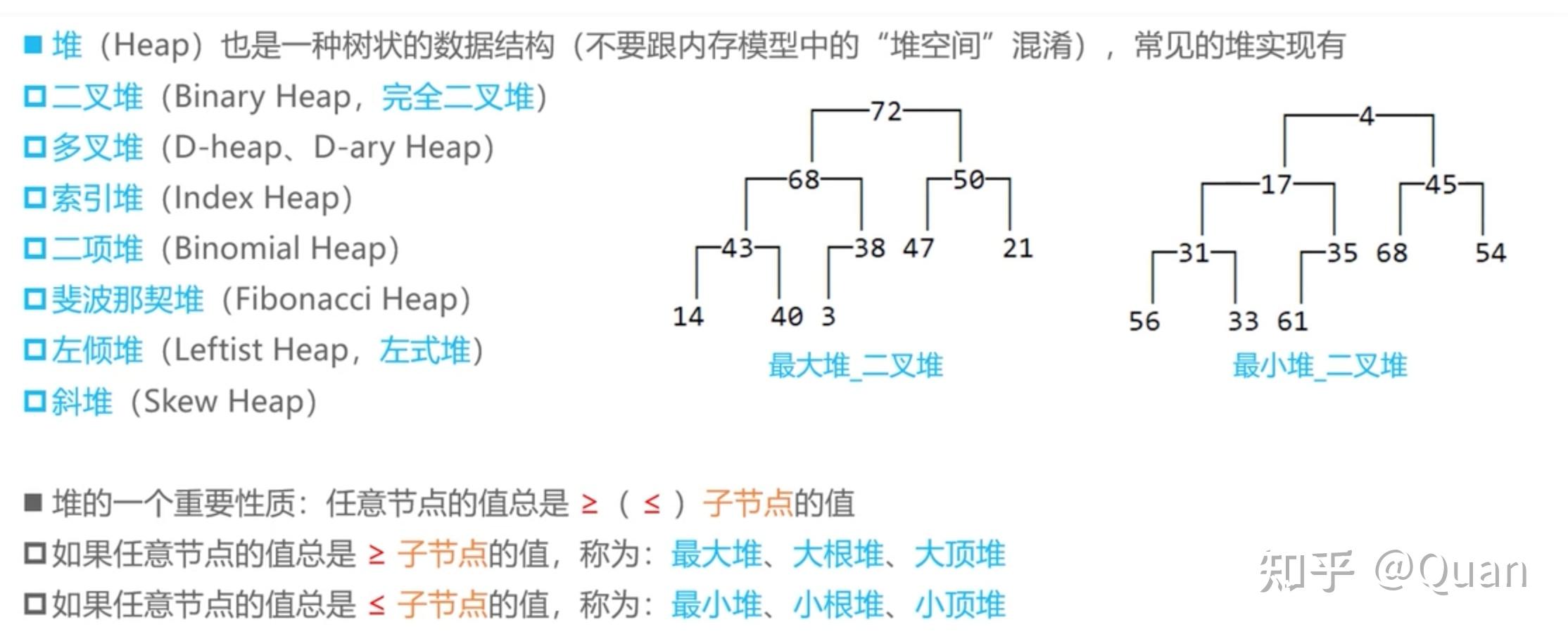
堆也是一个寻找冠军游戏。



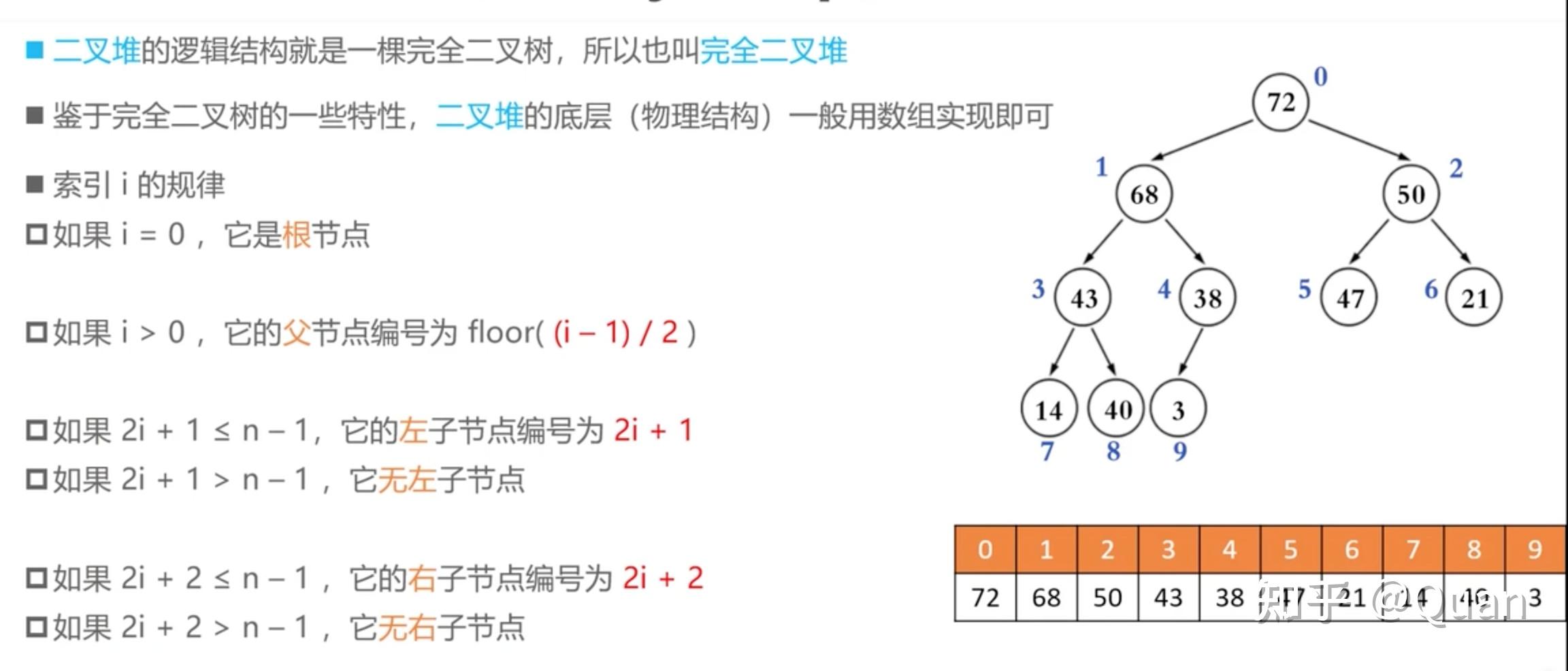

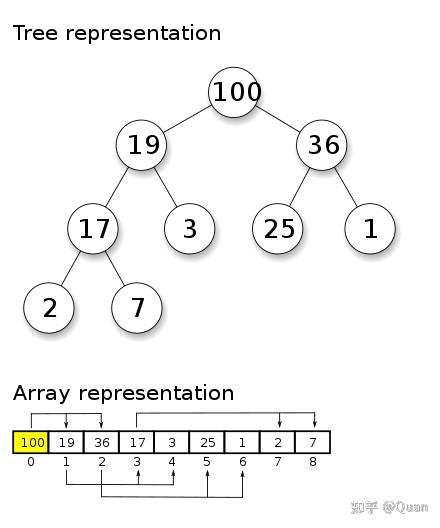

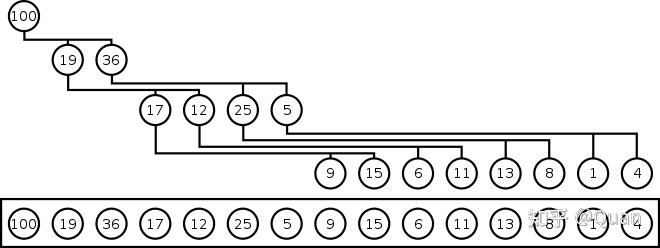
wiki资料:
堆的定义:
1:先定义局部偏序
针对二叉堆:
父节点P>=左节点L,父节点P>=右节点R,即: P>=R , P>=L, 构成偏序关系,又因为L和R无法比较大小,所以堆不是全序,全序要求任意元素均可比且均有大小关系 。
扩展定义:
父节点P>=任意子节点S,即: P>=S1,P>=S2,... P>=Sn,构成偏序关系,因为(S1,S2,...Sn)不要求比较大小,故子节点集合S是无序的,所以集合(P,S1,S2,...Sn)不满足全序关系。
2:递归定义
整体是由偏序的递归定义而生成(如:树结构,或者数组表示法的逻辑递归)
于是下面经验也成立:
如果 最小局部是偏序关系 ,那么整体也将是 偏序关系 ;
注:该命题我暂时还不知道怎么去证明,但感觉上是靠谱的,我的逻辑是:
一个递归定义的命题,整体上要 至少 能够“ 保持 ” 最小局部 的 全部性质 ,否则, 递归式本身就是错误的 !
堆,只看偏序就足够了!
堆的偏序描述了一个现象:
如果局部定义是
1
个数大于另外
K
个数,那么堆本身也必然描述,
1
个数大于另外
N
个数。这不就是
最大堆
的核心目标吗?(最小堆反过来即可)
如果考虑递归所带来的传递性性质(假设为二叉堆),发现:
1:第1层(从根节点开始)必然有一个最大值,该层元素个数为1,所以根节点就是
最大值
2:抛去上一层元素,第2层必然有一个最大值,该层元素个数为2,所以该层2个元素必然有一个是
次大
的数
3:抛去前2层元素,第3层必然有一个最大值,该层元素个数为4,所以该层4个元素必然有一个是
次次大
的数
... ...
这看起像一个
金字塔结构
,而金字塔
每层结构
,都
必然包含一个最大值
,但只需保证一个就可以了,并不是说,该层级其它元素都比它下一层每一个元素要”
高
“ (因为偏序特意规定他们之间是不可比的)


进一步,我们可以得出:
偏序是集合
(层级)
序,而全序是元素序!
至于:左倾堆,斐波那契堆,配对堆,D堆,二项式堆等,他们的偏序定义和二叉堆一样,所以它们的核心性质是一致的。唯一的区别是,
左倾堆,斐波那契堆,配对堆,D堆,二项式堆,二叉堆等
他们仅仅是在
删除,添加,合并等操作上,做平衡取舍而已
。比如让
树左外歪一点,
不追求那么平衡,两个优先级堆合并就容易一些,
这就是
左倾堆;
又比如,既然偏序是集合序,那不如把这些
集合序分拆成
森林
,那
添加方便一点
,如斐波那契堆,二项式堆
这些数据结构的构造,和基于全序的二叉搜索树,B数,红黑树一样,都是先定义好
序结构
,进而打造一个稳定的
核心性质
,然后对
删除,添加,合并等操作做平衡取舍!
还进一步,
堆的偏序结构
是
描述
1个数
大于
另外一些数
的序,我认为叫
1/N-1
分类问题更科学。
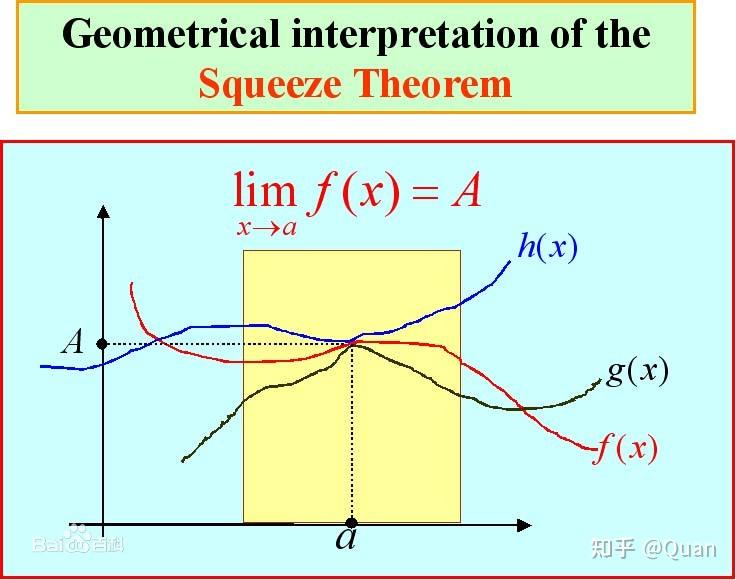
那么可以使用
2个堆
的组合运用,可以找出中位数,或任一百分比的数据。
假设在一批无序实数中(假设不重复),寻找一个
第30%大小
的值,可以将以上问题转换为2个堆问题:
1:假设这个值为x存在
2:那么x一定是
M1集合的
最小值
和
M2集合的
最大值
,那么M1集合的规模一定是30%,M2集合一定是70%
这不就是夹逼定理吗!?

关于堆,还有一个关于面试问题:top K
其大概的思路就是:
1:构建一个最小堆,将前K个值放进去
2: 依次将剩下的数字大于最小堆的最小值,替换最小堆


详情请看全国优秀IT教育工作者MJ小码哥的教程:
top K问题其实也不难,但是大部分人第一反应还是用使用
全序
来做,这肯定能做出来的,但是这里牵扯到一个更核心的问题:我们首先要区分待解决问题是
全序问题
还是
偏序问题
,而
偏序问题
也可以叫
一般选择性问题,
那么就可以
克制
自己使用
全序
一刀切的解决
所有序关系
的习惯!
其实分组,分治也是一种
偏序思维。详情请看屈婉玲教授的一般选择性问题。
但不得不承认,全序就是计算机最优美的结构,用处最为广泛!
八:从单射、双射与满射,到Map,Set
任何满足
映射关系的数据结构
,不管以单机形式存在,还是以网络形式存在,不论是以多维表格形式描述,还以任何其它特种结构来描述(json,xml,结构体等),也不管存储地址是否连续,只要想获得
O(1)的操作,
只需让映射关系的
映射函数
足够简单即可,如
线性映射。
O(1)级别的操作是映射能力的一个最核心指标,可称之为:
原子操作的数据结构
!
Array
和
Struct
就是2个最经典的原子操作级别的数据类型!
(其实Struct也是数据结构,并且是王者般的存在)
虽然所谓的一些高级数据类型诸如,
Map
(
LinkMap,TreeMap,HashMap,LinkedHashMap
),
Set
(
LinkSet,TreeSet
)看起来
应该是映射关系最显而易见的品种
,但很可惜,除
HashXX
外,
它们的构建不是基于
良好的映射函数
,而是基于
其它更基础的数据结构
组合
而已。
(Set:一种逻辑集合,不能包含重复的键;Map:其实就是Set,只不过每个键值都对应一个值,一般简称:Key-Value结构)
映射关系
数学上,单射、满射和双射指根据其定义域和陪域的关联方式所区分的三类函数。
单射:指将不同的变量 映射 到不同的值的函数。
满射:指 陪域 等于 值域 的函数。即:对陪域中任意元素,都存在至少一个定义域中的元素与之对应。
双射(也称一一对应):既是 单射 又是 满射 的函数。直观地说,一个双射函数形成一个对应,并且每一个输入值都有正好一个输出值以及每一个输出值都有正好一个输入值。
满射:对任意b,存在a满足f(a) = b~ 。 即:值域y是满的,每个y都有x对应,不存在某个y没有x对应的情况~

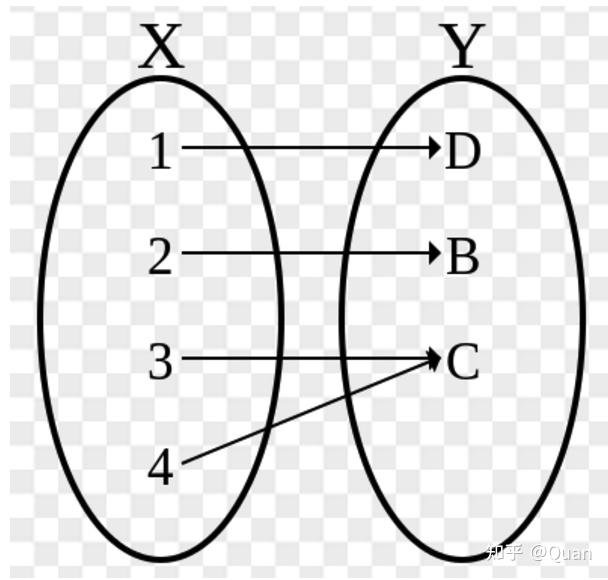
单射:(one-to-one function) 一对一函数,x不同则y不同~。即:没有一个x对应两个y,也没有一个y有对应两个x~

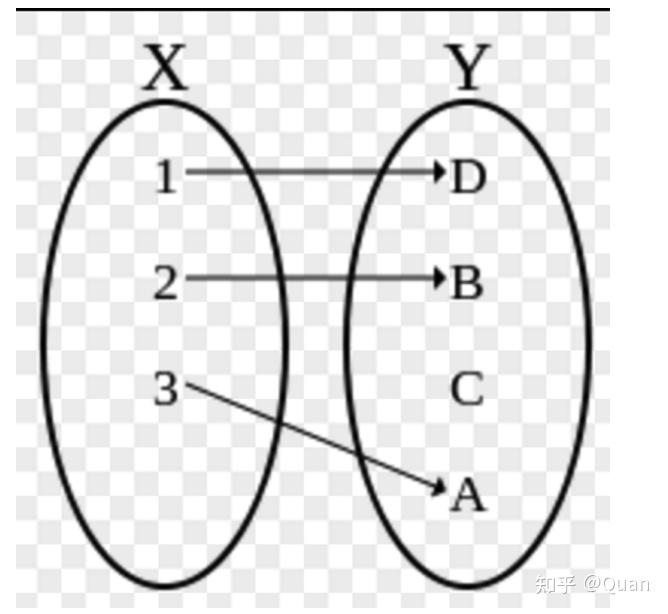
双射:既是满射,也是单射~。即:每个y都有x对应,而且都是一一对应~

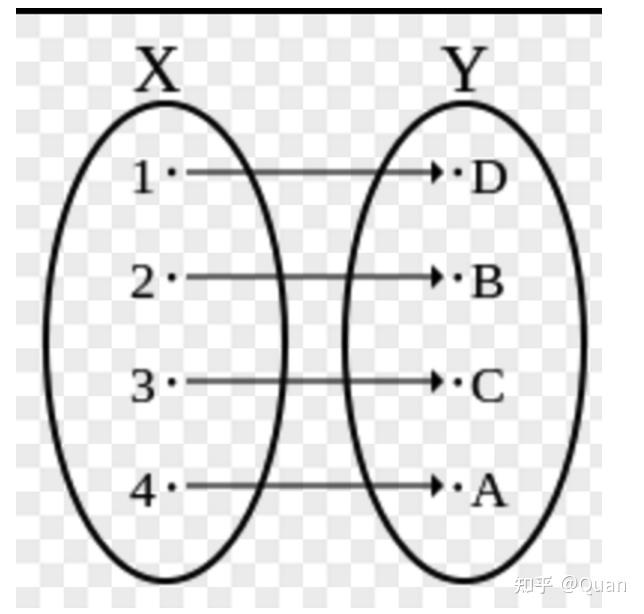
映射关系赋予数据以结构
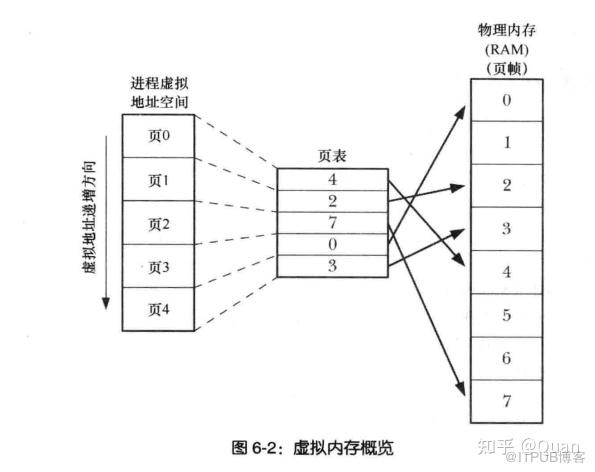
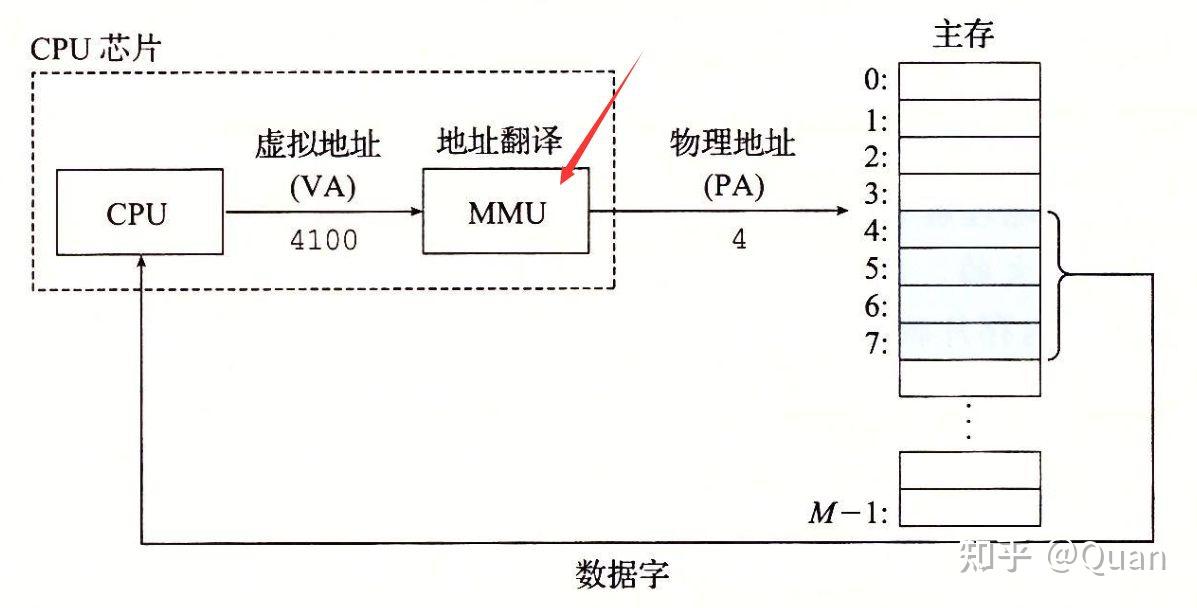
1:双射结构:
一个
连续内存区域
就保证了
双射关系的自然性
,当使用
索引或属性名来访问实际数据时,
双射关系就自动赋予了该操作的
O(1)优势
,
双射关系
也是应用最广泛,性能最高的映射关系。

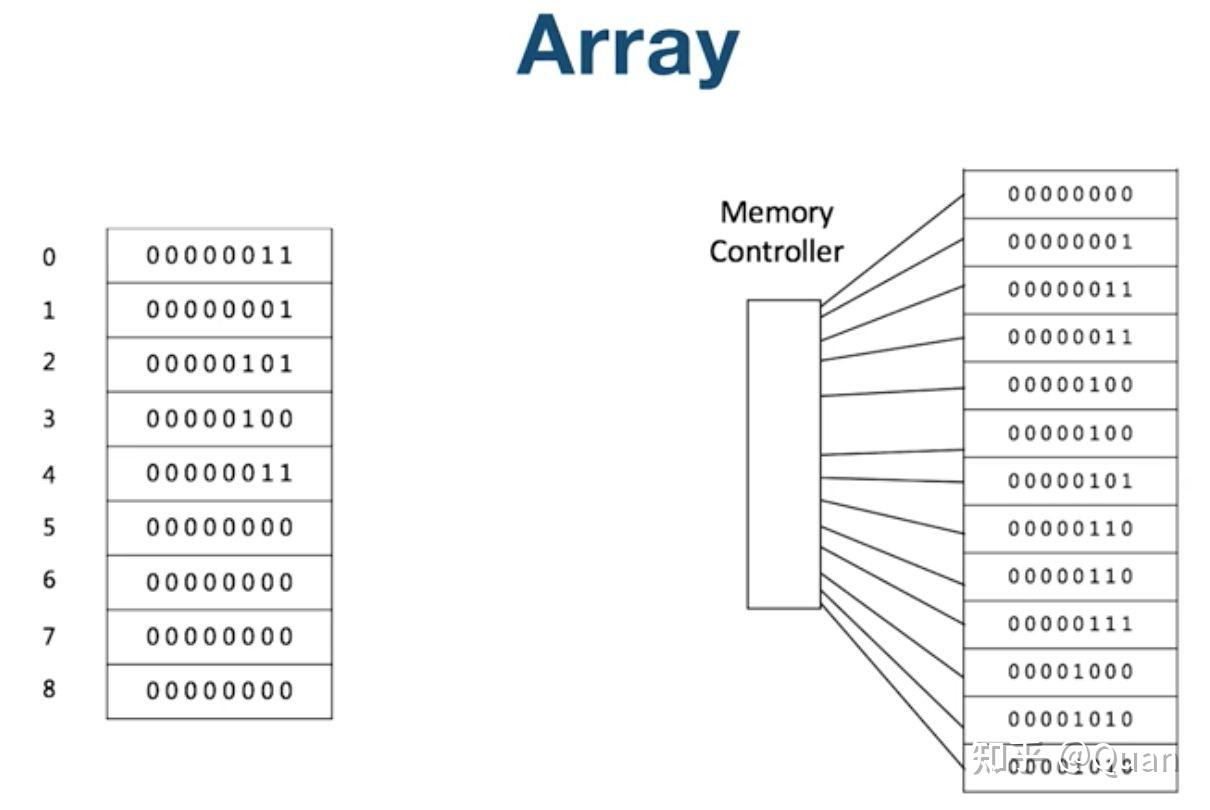

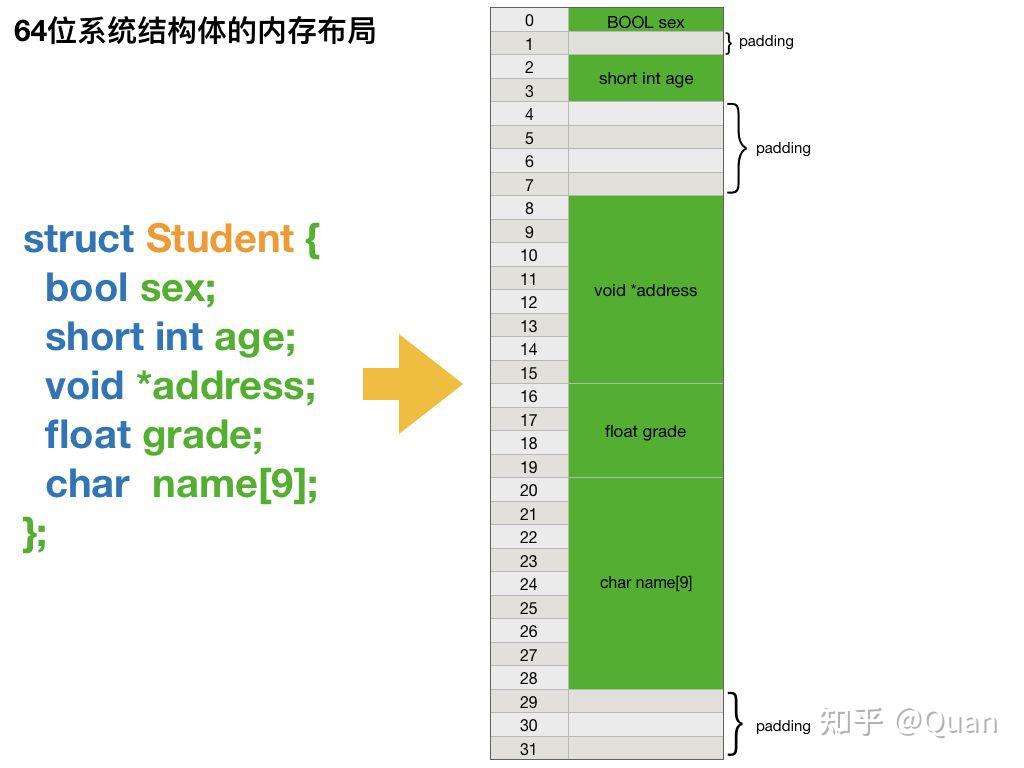
通常一个
映射函数
应该是线性的。



2:单射结构暂时没有找到相应的数据结构或数据类型。没有案例的原因,我猜测是不是:任何数据结构的输出集合Y,都应该有至少一个输入X对应,否则会出现
数据冗余,
换句话说,输出集合Y(数据结构本身)如果存在一个数据永远无法被外界访问(x映射),那么
该数据结构将会存在一个
不必存在
的数据
。
而满足该标准的只有
双射和满射
。
3:满射结构:
从满射的定义角度出发,
HashMap
更像一个描述了1对N的关系映射,即:N个输入,只对应1个输出。虽然情感上我们希望能够避免hash碰撞的出现,并尽可能的期盼hash能像双射一样,满足
一一对应
的性质,可惜,现阶段无法办到!
从应用场景出发,
HashMap
又像一个
将无穷集合映射到有限集合
的
关系映射
,按照这个应用属性,会必然出现多个输入对应1个输出的现象。典型的如散列表算法(Hash function):

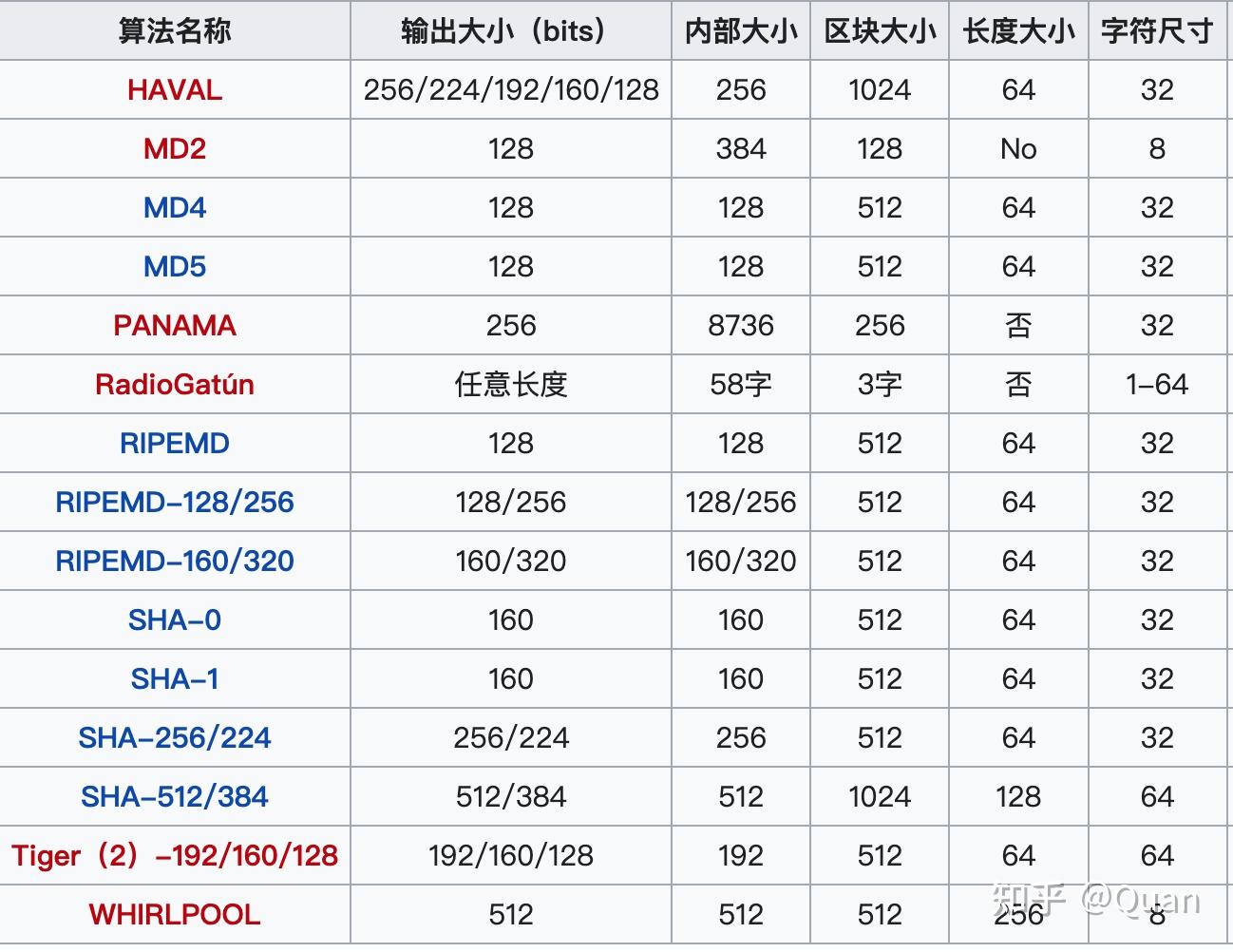
比如128的MD5就是一个满射映射,其碰撞在理论是一定存在,但从概率上看,其碰撞概率和输出容量有关系。我们假设MD5的计算结果足够随机和足够分散,那么一个文件的MD5码,有2的128次方个可能。进而我们知道,随意找出来的两个文件的MD5码相等的可能性,是2e128分之一,所以MD5的碰撞概率很小。
但hashMap的hashCode的容量大小一般是int32位,即2的32次方,此时的碰撞概率就不能忽略了。
详情请看hashCode的几种算法以及优化原则
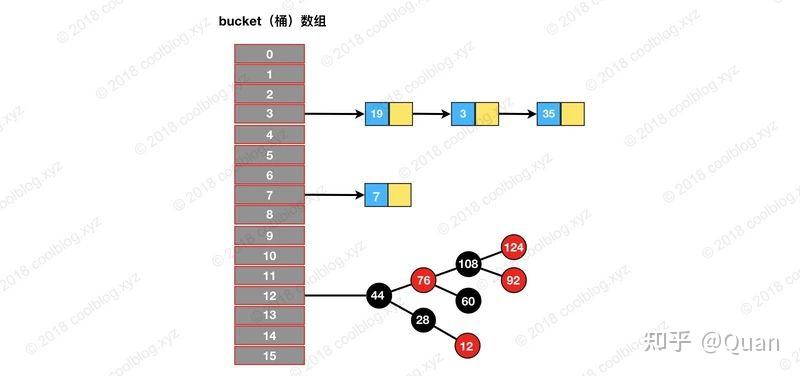
大部分hashMap其实做了2次满射才最终把一个key对应到数组的索引上去的。
第一次把key转换成hashCode,int32类型,O(1)操作
第二次把hashCode mod array_size 映射成数组的索引(取余法) ,O(1)操作
最后找到存储在数组上的基础数据结构(解决hash冲突用的):如:LinkList,红黑树等

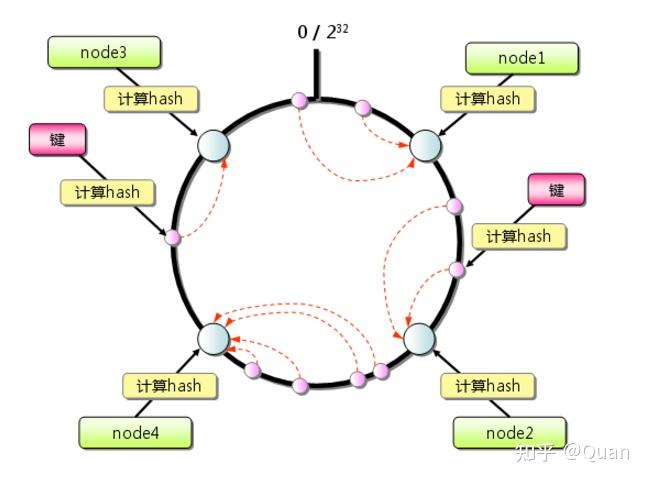
当然还可以使用
区间法
来做Map:
第一次还是把key转换成hashCode
第二次把hashCode按照区间分层若干段,
比如1-10000映射到n1,10001-20000映射到n2......
比如
一致性哈希算法
核心映射关系就运用了
区间法Map

详情请参考:
映射即赋予数据以结构,又赋予数据以简洁!
至此我们拥有了
3
个重要的
数据结构俯视工具
:
1:序关系 2:因果关系 3:映射关系
九:无所不在的序应用
1: 将
无序请求
转成
有序请求
,如Actor模型,CSP模型,协程,其核心原理将乱序请求(消息),强制转换成有序请求(邮箱,队列),获得基于无锁的高并发性
2: 混合使用
线性时序和递归时序
,如epoll模型和Reactor事件机制,其核心原理是交叉使用顺序请求和递归时序响应,获得基于无阻塞的异步性
... ...
结束语:一旦抓住了“序”这个关键字,就抓住了任何数据结构的本质和精髓,这有利于我们去识别和发明,一些更加优秀的数据结构。
