在领域自适应里面也会细分出很多方向。如果源域和目标域距离太大(比如源域是文字,目标域是图像),就可能需要进程多步的迁移,将这个非常大的迁移划分成一步一步的小段迁移,这就是下图中的
多步领域自适应(Multi-step DA)
通过选择合适的中间域来转换成一个个
单步领域自适应(One-step DA)
,这样就只要去研究单步迁移怎么做。
然后单步迁移又可以根据源域和目标域数据情况可以分成
同质
(Homogeneous,即数据空间一样,只是数据分布不一样)和
异质
(Heterogeneous,数据空间都不同)两种。
\begin{aligned} Homogeneous & \Rightarrow \mathcal{X_S = X_T, \ P(X_S) \neq P(X_T)} \\ Heterogeneous & \Rightarrow \mathcal{X_S \neq X_T} \end{aligned}
H
o
m
o
g
e
n
e
o
u
s
H
e
t
e
r
o
g
e
n
e
o
u
s
⇒
X
S
=
X
T
,
P
(
X
S
)
=
P
(
X
T
)
⇒
X
S
=
X
T
接下来,在同质或者异质的DA中又分别可以
根据目标域数据的打标签情况
分为
监督的、半监督的、无监督的DA
。学术界研究最多的是无监督的DA,这个比较困难而且价值比较高。

传统的的ML方法是最小化损失:
m
i
n
n
1
i
=
1
∑
n
L
(
x
i
s
,
y
i
s
,
θ
′
)
如果目标域数据没有标签,就没法用Fine-Tune把目标域数据扔进去训练,这时候无监督的自适应方法就是基于特征的自适应。因为有很多能
衡量源域和目标域数据的距离的数学公式
,那么就能
把距离计算出来嵌入到网络中作为Loss来训练
,这样就能优化让这个距离逐渐变小,最终训练出来的模型就将源域和目标域就被放在一个足够近的特征空间里了。
这些衡量源域和目标域数据距离的数学公式有KL Divergence、MMD、H-divergence和Wasserstein distance等。
例如经典的用于无监督DA的
DDC
方法,它是使用
MMD(Maximum Mean Discrepancy)
,即找一个核函数,将源域和目标域都映射到一个再生核的Hilbert空间上,在这个空间上取这个两个域数据分别作均值之后的差,然后将这个差作为距离。用这个方法训练网络的Loss是:
\mathcal{L} = \mathcal{L}_C(X_s, y) \ + \ \lambda \sum_{l \in L} \mathcal{L}_M(D_s^l, D_t^l)
L
=
L
C
(
X
s
,
y
)
+
λ
l
∈
L
∑
L
M
(
D
s
l
,
D
t
l
)
其中第一项就是源域之前的模型的Loss(比如分类任务就是分类Loss),然后第二项是在指定层
如
RevGrad(ICML,2015)
的基本思路就是用GAN去让生成器生成特征,然后让判别器判别它是源域的还是目标域的特征,如果判别不出来就说明在这个特征空间里源域和目标域是一致的。
下图中绿色部分是一个特征提取器,源域和目标域数据都扔进去,它就是用来生成(或者叫提取)特征的,然后紫色部分是对源域数据的特征做分类的分类器,红色部分是对源域数据和目标域数据的特征做判别的判别器,这个判别器要不断增强(能很好的判别是源域的还是目标域的特征),同时生成器也要增强,让生成出来的特征能混淆判别器的判别,这样最后生成(提取)出的特征就是源域和目标域空间里一致的了。
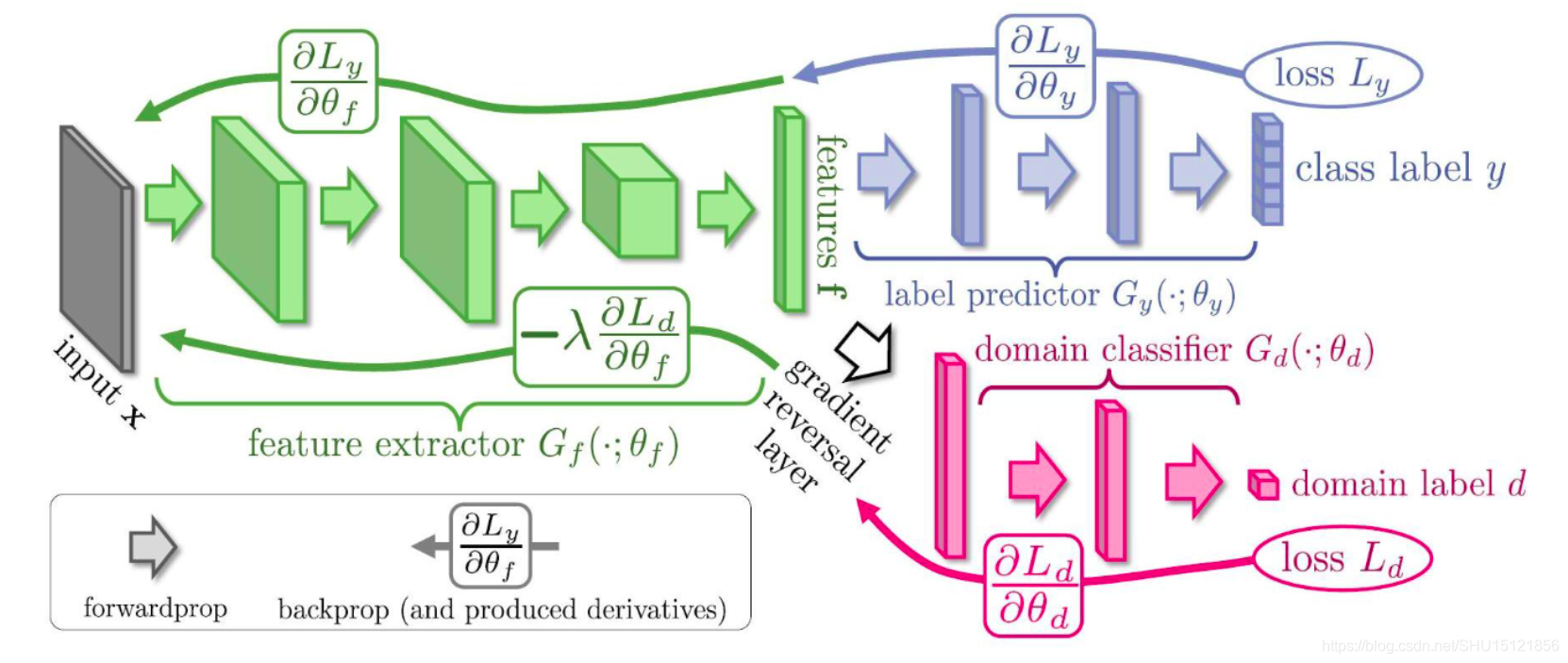
这个可以用GAN的最小化-最大化的思想去训练,也可以用论文中的
梯度反转层(Gradient Reversal Layer)
的方法,就是在上图中白色空心箭头的位置加了个梯度反转层,在前向传播的过程中就是正常的网络,即最小化Loss让红色部分的判别器性能更好,再反向传播的过程中把梯度取负,即优化绿色部分的特征提取器,来尽量让红色部分的判别器分不清特征是源域的还是目标域的。这个方法就是一个训练技巧。
对于它的改进有
CAN(CVPR,2018)
,它把深度网络连续的若干层作为一个block,这样划分成几个block,然后对每个block加一个判别器。它提出
希望在网络高层的block中的特征和域的信息无关
,因为最后要得到的就是不区分源域和目标域数据的网络;而
希望在网络的低层的block中的特征和域的信息有关
,因为底层在提取边缘信息,希望这些边缘信息能更好提取目标域的特征。
还有
MADA(AAAI,2018)
。之前的方法都是源域和目标域的类别都是相同的这些,但是有时候源域和目标域类别不一定相同,比如目标域类别可以是源域类别的子集。这个方法就是提出
不应该是域到域的对齐,而是应该精细到类别到类别的对齐
。这种方式就是只在最后一层用判别器,但是
对于每个类别都单独使用一个判别器
,这种就是
引入语义信息(类别信息)的对齐
,能让特征空间对齐的更好。但是因为在无监督的DA里目标域样本没有标签,所以这里要用源域分类器去对目标域样本输出属于每个类的概率,属于哪个类的概率更大就让那个类的判别器发挥更大的作用。这种方法就是相当于在RevGrad上补充了
5
中基于实例的自适应方法。
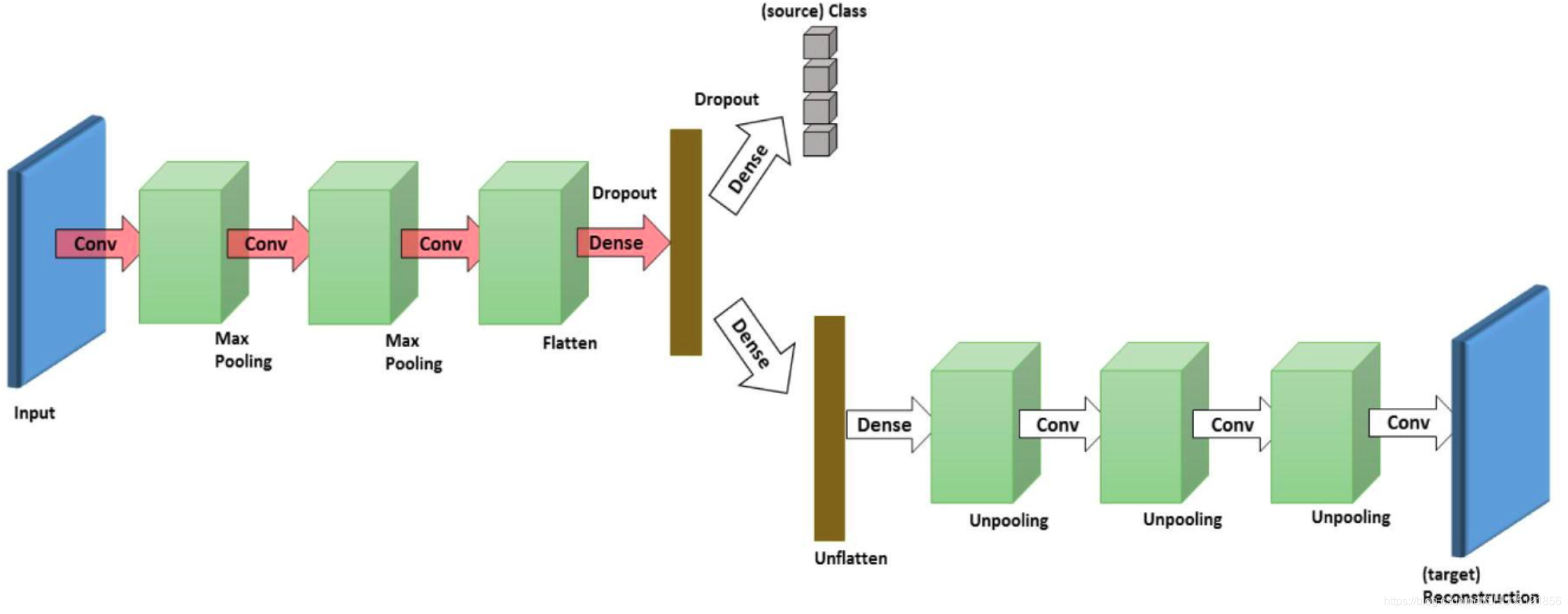
DRCN(2016,ECCV)
如下图结构,左侧是一个Encoder,也是将源域和目标域样本都扔进去生成特征用的,然后对于源域特征用一个分类器去分类,这样使得Encoder生成的特征能够很好的区分源域的样本(即是一个比较好的特征),对于目标域特征用一个Decoder去解码,使得能尽量还原目标域的样本。这样下来生成的特征所在的特征空间在源域和目标域样本上比较近。
DSN(NIPS,2016)
将源域和目标域的样本分别拆分成两部分,一部分是两个域私有的Encoder,即尝试编码各自域中特定的信息,另一部分是两个域共有的Encoder,显然想到得到的就是这种共有特征。在分类时尽量
让私有的特征和共有的特征正交
,这样体现出它们更不相关,两个域各有一个损失
1 迁移学习的直观理解人类容易在类似的任务上利用先前的经验,比如学过自行车就很容易学会摩托车,学会打羽毛球也能帮助学习打网球,学过小提琴也会对学习二胡有帮助。也就是把一个领域上学习的知识迁移到另一个领域上,目的也是让计算机有举一反三的能力(大概是实现AGI的一个重要的坎),或者是去尝试充分利用已经训练过的某个领域的知识来解决当前的任务(这样可以解决数据少的问题)。在迁移学习中要强调源域(Source Domain)、源任务(Source Task)、目标域(Target Domain)和目标任务(Tar
Profile
最近因为个人需要看了一些 D
ADA
DA 和 DRDRDR 的文章。
这篇文章比较有意思的是:将聚类设计成目标函数,从而一方面实现经网络抽取特征在分布上的自然聚类,一方面因为特征分布的聚类自然提高了分类效果,一方面加快了聚类的速度,同时最主要的就是实现了不同源域之间的结构的细粒度对齐,从而促进 UDAUDAUDA 算法的性能。
Introduct
ion
D
ADA
DA 有一个基本的解决思路就是:认为源域 SSS 与目标域 TTT 的边缘分布在高层语义空间是可以等价的,因此,致力于在高层隐空间拉近两个域的分布,设计为一个类似 minθ
在点云上进行域自适应的自我监督
学习
自我监督
学习
(SSL)可以从未标记的数据中
学习
有用的表示形式,并已有效地应用于图像的域自适应(DA)。 尚不知道是否以及如何利用它来进行3D感知领域的适应。 在这里,我们描述了对点云上的DA的SSL的首次研究。 我们引入了一个新的借口任务系列,即“变形重构”,该变形任务是由模拟到真实转换中遇到的变形所激发的。 关键思想是使输入形状的区域变形并使用神经网络对其进行重构。 我们设计了三种类型的形状变形
方法
:(1)基于体积:基于输入空间中的接近度的形状变形; (2)基于特征的:使形状上形状相似的区域变形; (3)基于采样:基于三个简单采样方案的形状变形。 作为单独的贡献,我们还针对点云开发了一种基于混合训练过程的新
方法
。 对综合和真实家具数据的六个领域适应性进行的评估表明,与以前的工作相比有很大的改进。
克隆仓库并安装
git clone ht
Dom
ain
Ada
pta
t
ion
1. 源域与目标域区别在哪? 2. 不同的域自适应
方法
Reference
含义:在经典的机器
学习
中,当 源域 和 目标域 数据分布不同,但是两者的任务相同时,这种 特殊 的
迁移学习
就是域自适应(
Dom
ain
Ada
pta
t
ion
)
上面含义若看不太懂,简要解释如下:我们一般都是假设
领域自适应
是
迁移学习
中的一类重要问题,主要解决当训练集和测试集的数据分布存在偏差时,如何使得训练出的分类器更好的适应测试集上的数据。早期的基于统计
学习
等浅层模型的做法主要是先设计一套特征提取
方法
,然后对训练集和测试集的特征进行分布匹配,此时再将分类器用到测试集上会取得更好的预测效果。但是这种分步式的操作效果还是比较有限的,不能同时兼顾数据分布和分类器的训练,要想实现端到端的在数据分布差异约束下进行分类训练,就要依靠神经网络。
近几年来使用
深度学习
方法
解决
领域自适应
问题的文章有很多,都取得了比较好的效果
域自适应是一种机器
学习
中的问题,它解决的是训练数据与测试数据存在不同分布的情况。具体而言,域自适应旨在利用在一个或多个源域上训练得到的模型,来对一个未知目标域上的数据进行有效的预测。
域自适应面临的主要挑战之一是域间的分布差异。不同域之间可能存在特征分布的偏移,或者标签分布的偏移,这导致了在目标域上直接使用源域模型时的性能下降。为了解决这个问题,研究者提出了各种
方法
。
一类常见的
方法
是基于特征映射的域自适应
方法
。这些
方法
通过
学习
一个映射函数,将源域和目标域的特征空间映射到一个共享的特征空间中,从而减小域间的分布差异。有些
方法
将源域的标签信息也用于训练这个映射函数,以增强其适应目标域的能力。
另一类
方法
是基于实例重标定的域自适应
方法
。这些
方法
试图通过调整源域的样本权重或标签权重,使得源域上的样本在目标域上的表现更好。有些
方法
借助迁移矩阵来确定样本权重,从而实现重标定。
还有一类
方法
是基于深度神经网络的域自适应
方法
。这些
方法
利用深度神经网络的能力来提取抽象的特征表示,并通过在网络中加入领域分类器或对抗损失函数等方式,来减小域间的分布差异。
总的来说,域自适应是一个重要而具有挑战性的问题,在实际应用中具有广泛的潜力。目前研究者们提出了各种各样的
方法
来解决这个问题,但仍然存在很多挑战和待解决的问题,例如如何减小源域与目标域的分布差异,以及如何更有效地利用标签信息等。




