


Python基于改进Unet的新冠肺炎等级分割系统(源码&教程)

1.研究背景
新冠肺炎给人类带来极大威胁,自动精确分割新冠肺炎CT图像感染区域可以辅助医生进行诊断治疗,但新冠肺炎的弥漫性感染、感染区域形状多变、与其他肺部组织极易混淆等给CT图像分割带来挑战。为此,提出新冠肺炎肺部CT图像分割新模型XR-MSF-Unet,采用XR卷积模块代替U-Net的两层卷积,XR各分支的不同卷积核使模型能够提取更多有用特征;提出即插即用的融合多尺度特征的注意力模块MSF ,融合不同感受野、全局、局部和空间特征,强化网络的细节分割效果。在COVID-19 CT公开数据集的实验表明:提出的XR模块能够增强模型的特征提取能力,提出的MSF模块结合XR模块,能够有效提高模型对新冠肺炎感染区域的分割效果;提出的XR-MSF-Unet模型取得了很好的分割效果,其Dice,IOU 、F1-Score和Sensitivity指标分别比基模型U-Net的相应指标高出3.21、5.96,1.22和4.83个百分点,且优于同类模型的分割效果,实现了新冠肺炎肺部CT图像的自动有效分割。
2.图片演示

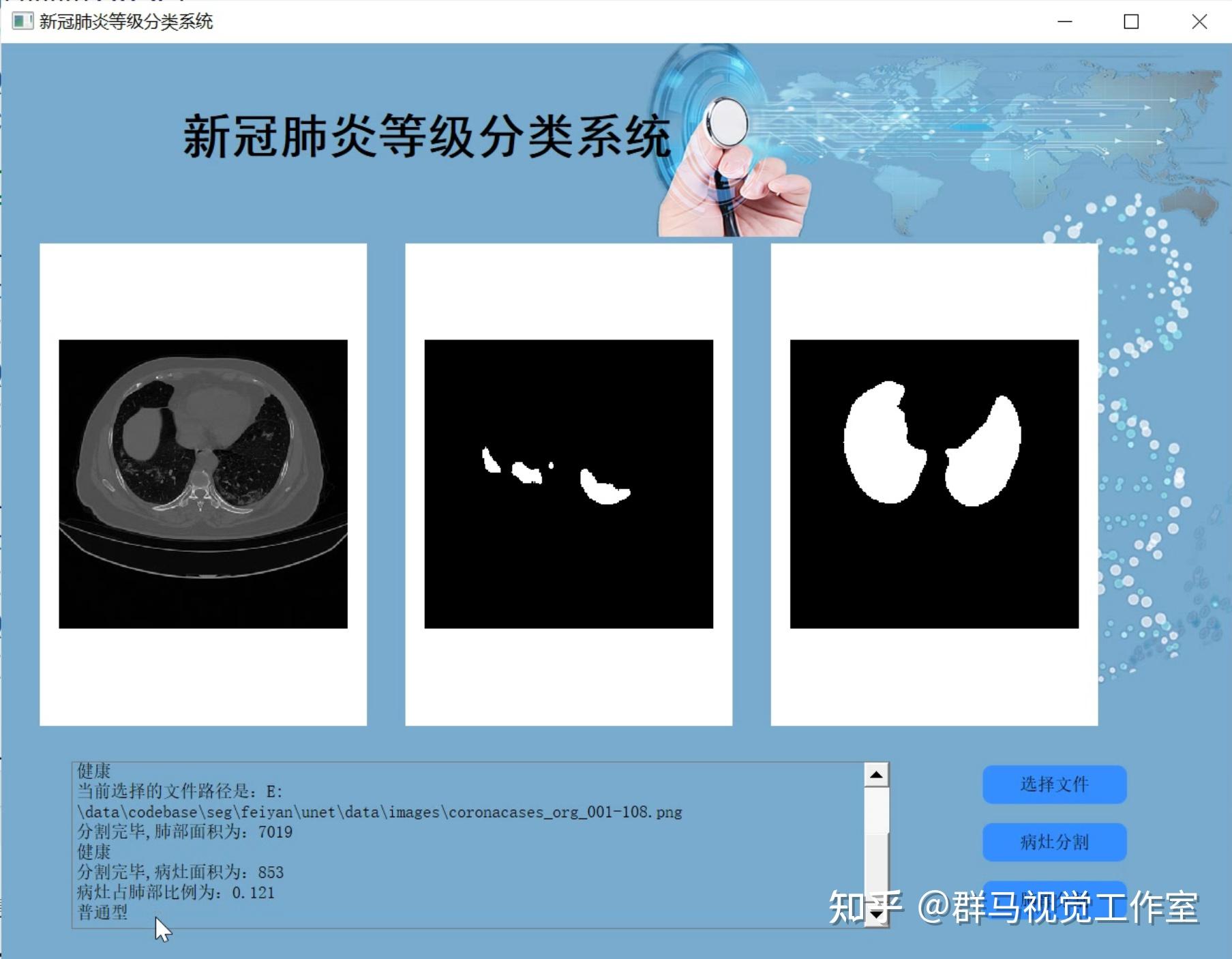

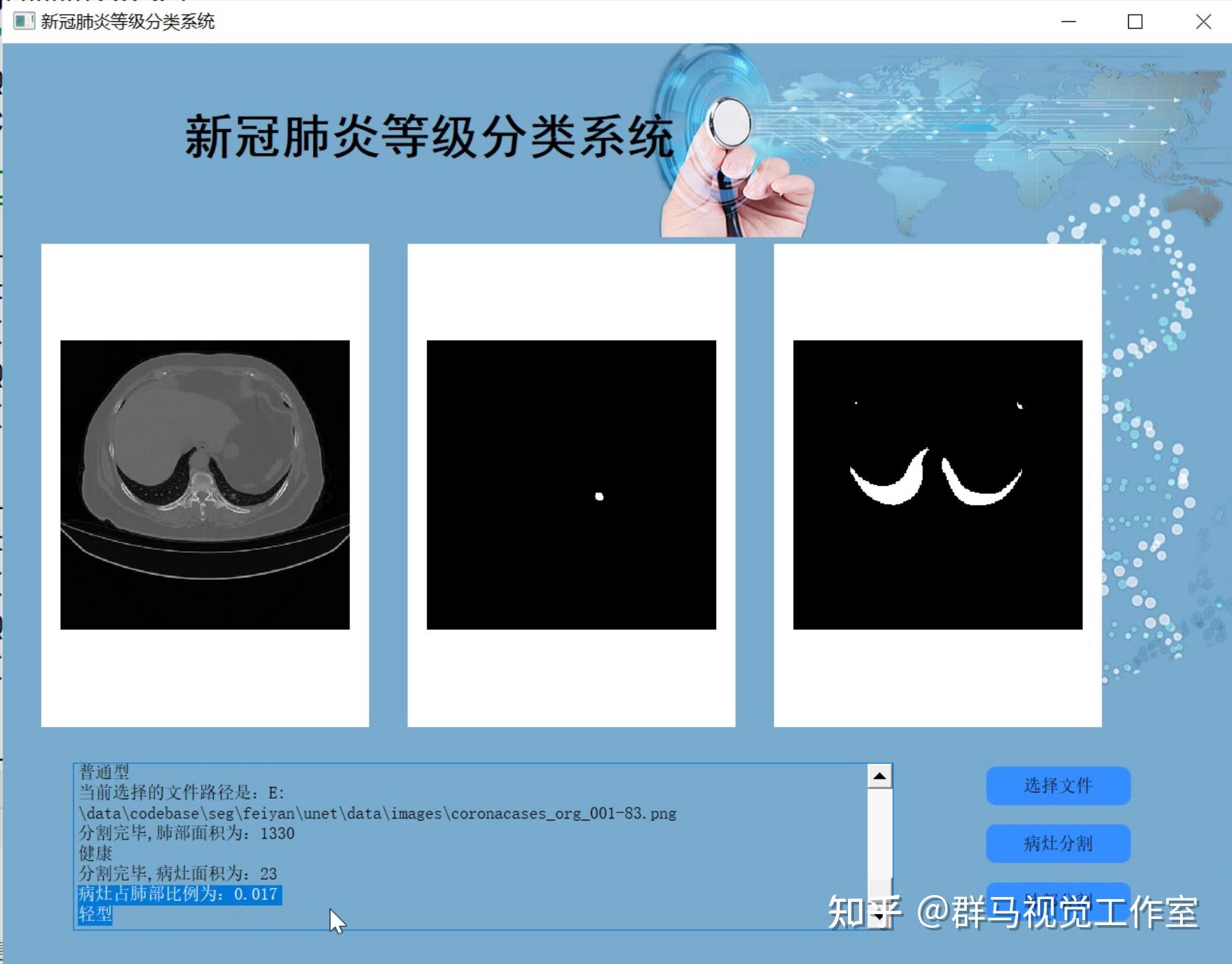

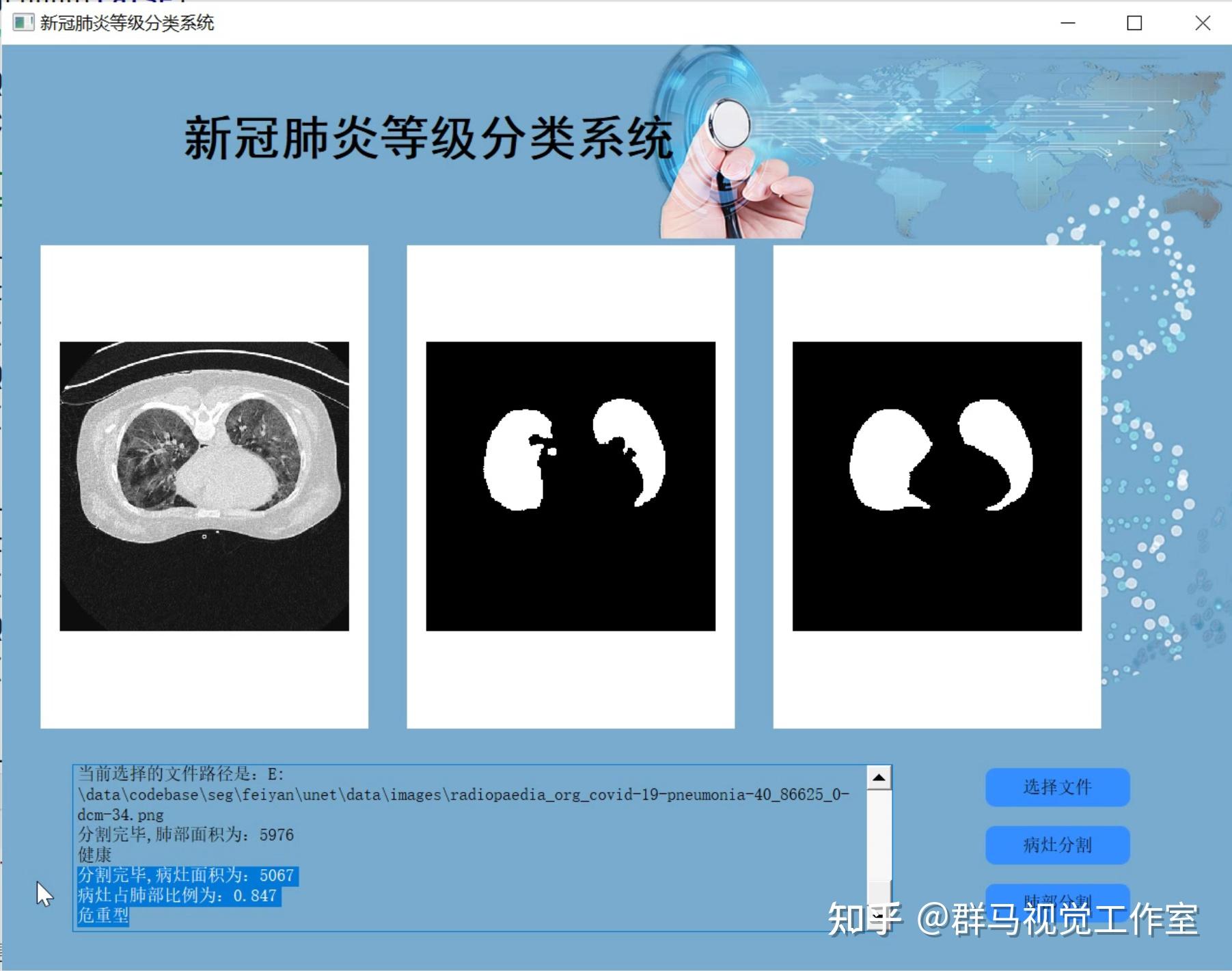
3.视频演示
Python基于改进Unet的新冠肺炎等级分割系统(源码&教程)_哔哩哔哩_bilibili
4.U-Net网络简介
传统语义分割采用基于颜色、形状等低级语义信息P,无法很好分割复杂图像。深度学习技术使用高级语义信息进行分割。2015年,Long等人P3首次使用全卷积神经网络对自然图像进行端到端分割,实现了从传统方法到深度学习方法的突破。2015年Ronneberger等人"在全卷积神经网络基础上提出U-Net结构,在ISBI细胞分割挑战赛中获得第一名。U-Net网络包含编码和解码两部分,编码器进行下采样操作,提取原始图像空间特征,解码器进行上采样操作,根据编码器所提取的空间特征构造出图像。为了防止对应特征丢失,对应编码器和解码器之间有跳跃连接。U-Net的编码器采用两层3x3卷积、ReLU激活函数和2×2最大池化,来提取图像特征,共进行4次下采样,该过程降低特征图尺寸,增加通道数,最终通道数为原来的16倍。解码器部分使用2×2反卷积进行上采样,减少通道数,逐渐恢复特征图尺寸。然而,新冠肺炎CT图像十分复杂,U-Net在编码器每一个阶段仅使用普通的两层卷积和池化操作来提取特征,相较于经过设计的卷积组合,这样的特征提取方式容易导致模型无法提取到全部有用的特征信息,甚至还会有一部分特征在这个过程中丢失。此外,U-Net的解码器在逐步恢复图像时也采用简单的两层卷积和反卷积进行,这样又会导致一定的特征信息损失,最终使得网络无法完全恢复图像的复杂特征信息。另外,U-Net没有考虑全局、局部和不同空间位置的特征差异。为了提取新冠肺炎CT图像的复杂特征,提升对该类CT图像感染区域分割的准确性,本文将对U-Net的特征提取结构进行改进。
5.多尺度特征融合注意力模块 MSF
新冠肺炎感染区域大多为弥漫性感染,整幅图像中各个角落都可能存在感染区。卷积感受野大小决定特征关注区域大小,感受野过大或过小可能会使CT图像部分感染区域被分割错误。另外,新冠肺炎感染区域位置不定,形状复杂,极易与其他肺部结构混淆,因此,为使模型能发现感染区域并增加其发现感染区域的能力,提出如图所示的融合多尺度特征的即插即用注意力模块MSF(multi-scale features fusionmodule)。

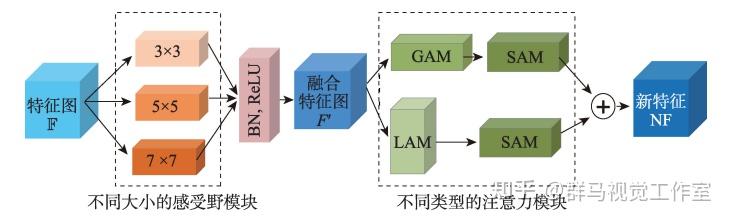
为了避免感受野不同给模型特征提取带来的问题,MSF模块使用3×3、5×5和7×7三种不同大小感受野的卷积核以并行的方式提取特征,这三种不同大小的卷积核分别具有小、中、大三种不同大小的感受野,提取的特征分别经过批归一化BN和ReLU激活后进行特征融合,这样并行的特征提取策略可以最大程度地减少串行卷积带来的特征损失,可以保证融合后的特征图中尽可能多地包含图像的各种特征信息。之后,融合的特征分别经过全局注意力模块(global attention module, GAM)和空间注意力模块(spatial attention module, SAM)构成的一个分支以及局部注意力模块(local attention module ,LAM)和空间注意力模块SAM构成的另一个分支,最后将两支注意力模块特征加和,实现不同大小感受野、全局、局部和不同空间特征的融合,使最终输出的特征图包含不同尺度和位置的信息,从各种维度最大限度保证模型提取到图像更多的特征信息。 假设输入通道数、高、宽分别为C、H和W的特征图F=RC×H*W,图3融合不同大小感受野的特征F'可表达为式(1)。其中,Conv"差XI”表示大小为m×m 、步长为stride的卷积。特征F′分别经过全局注意力模块GAM和局部注意力模块LAM,得到式(2)和式(3)的特征F。和F,。特征F。和F,分别经过空间注意力模块SAM融合位置信息,然后对应分量加和得到式(4)融合不同感受野、关注全局、局部细节信息以及空间位置的新特征图NF.


6.新冠肺炎分割数据集(2937张专业标注&文末附下载链接)
使用 该博客分享的包含约60名新冠肺炎患者的共100张轴向CT图像和放射科医生对这100张CT图像感染区域的标注图像 。COVID-19-2数据集由Radio-paedia 的9个不同病例的共829张轴向二维CT切片组成,其中有373张为新冠肺炎切片,由放射科医生进行了感染区域的分割标注,原始数据格式为NIFTI。COVID-19-3数据集由Coronacases Initiative和 Radiopaedia的20个不同病例的共1844张新冠肺炎CT切片组成,感染区域由有经验的放射科医生进行标注。COVID-19-4数据集来源于俄罗斯莫斯科市立医院,包含2937个病例的肺部CT图像,本文使用的为来自其中50个病例的有专家标注图像感染区域的785张确诊新冠肺炎CT图像。




7. MSF模块的特征加和权重测试和训练结果
参考该博客提出的MSF模块 对经过SAM模块的融合全局与空间信息的特征图FC。和融合局部信息与空间信息的特征图Fs的对应元素相加得到融合特征。为了确定Fc和Fs这两个特征图加和时的权重比,分别对这两个特征赋予不同权重进行加和,测试对U-Net模型性能的影响。实验结果如表所示,加粗表示最好结果。

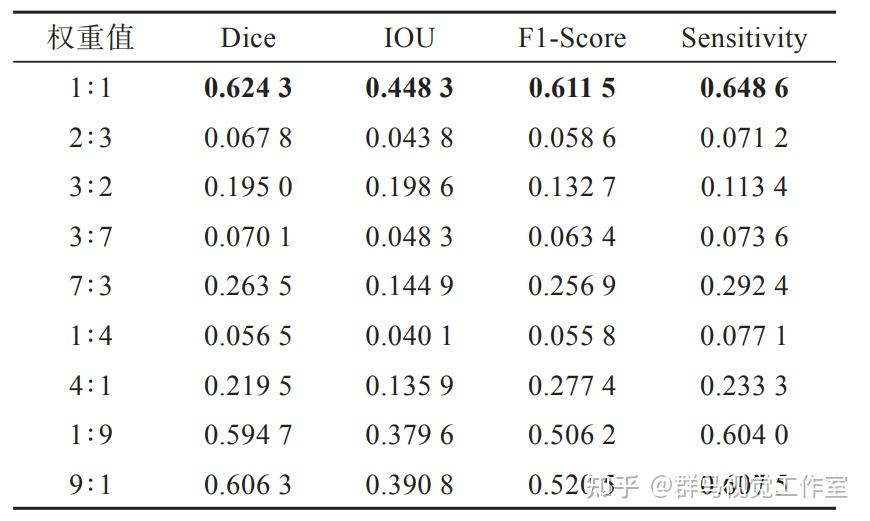
实验结果显示,当两部分特征图加和时的权重比为1∶1时,MSF模块能提取到分割性能最好的特征。当两部分特征图的权重比分别为2:3、3∶7和1∶4时,MSF模块获得的特征的分割性能非常差,各项分割指标基本趋于0,而当权重比为3∶2、4∶1、7:3时,MSF模块提取的特征的分割性能优于相反的权重比,说明Fes特征对MSF模块提取的特征的分割性能影响较大。
8.代码实现
class Decoder(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super(Decoder, self).__init__()
self.up = nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2)
self.conv_relu = nn.Sequential(
nn.Conv2d(middle_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
def forward(self, x1, x2):
x1 = self.up(x1)
x1 = torch.cat((x1, x2), dim=1)
x1 = self.conv_relu(x1)
return x1
class Unet(nn.Module):
def __init__(self, n_class):
super().__init__()
self.base_model = torchvision.models.resnet18(True)
self.base_layers = list(self.base_model.children())
self.layer1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False),
self.base_layers[1],
self.base_layers[2])
self.layer2 = nn.Sequential(*self.base_layers[3:5])
self.layer3 = self.base_layers[5]
self.layer4 = self.base_layers[6]
self.layer5 = self.base_layers[7]
self.decode4 = Decoder(512, 256+256, 256)
self.decode3 = Decoder(256, 256+128, 256)
self.decode2 = Decoder(256, 128+64, 128)
self.decode1 = Decoder(128, 64+64, 64)
self.decode0 = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
nn.Conv2d(64, 32, kernel_size=3, padding=1, bias=False),
nn.Conv2d(32, 64, kernel_size=3, padding=1, bias=False)
self.conv_last = nn.Conv2d(64, n_class, 1)
def forward(self, input):
e1 = self.layer1(input) # 64,128,128
e2 = self.layer2(e1) # 64,64,64
e3 = self.layer3(e2) # 128,32,32
e4 = self.layer4(e3) # 256,16,16
f = self.layer5(e4) # 512,8,8
d4 = self.decode4(f, e4) # 256,16,16