

Flask Web 小项目——SQL 建表语句生成器


一、有些长的前言
作为数据分析工程师,在日常工作中,需要新建大量的表来完成大大小小的需求。在完成了数据源确认,SQL 逻辑验数等工作后,想到还要为这个 SQL 建 Hive 表、建 MySQL 表、建 Clickhouse 表、建调度任务等一系列繁琐但又必须完成的工序,就会发现「革命远未成功」。
在进行一番自我审查后,发现主要是构建建表语句时让人感觉繁琐,主要由以下几方面导致:
- 虽然都是 SQL,但在不同的存储介质中的建表语法是不一样;
- 一般团队里有自己的语法规范,而这种规范会体现在每个细节中,操作多起来,犯错的机会也会增加;
- 建表时定义的字段和注释,还是得逐个核对修改,这一点是最耗时间的;
为了提升工作效率,有必要将建表语句的构建流程给自动化,而针对上述问题,需要逐个击破。具体思路如下:
- 团队里一般会有自己的建表语句范例,以此作为基础框架,然后传参进行填充;
- 根据写好的 SQL 语句,给建表语句填充 column 名称;
- 构建字段与注释的字典,保证同一个字段,同一个业务含义和注释;
二、数据工作流
输入 SQL 及建表信息 → 解析出新建表要定义的字段 → 字段自动化注释 → 构建建表语句 → 封装建表语句构建 API → 前端调用输出结果
自己画的草图:
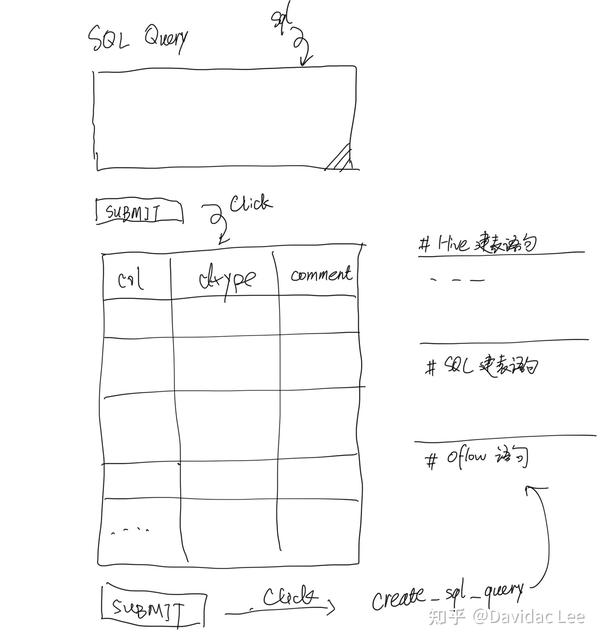

三、字段解析及自动化注释
(1)输入信息
对建表语句范例进行分析,总结出每次建表时,对范例语句进行修改的部分,包括:
- 表名
- 表注释
- 字段
- 字段类型
- 字段注释
(2)解析字段
一个常见的 SQL 查询语句,会包括
select
,
from
,
where
等关键字,而我们要定义的字段介于
select
和
from
之间,而字段之间可通过逗号进行分割区分。
select col1, col2, ... from tmp_db.tmp_tbl where dt = xxxxx;
不过在实际的 SQL 中,我们还会通过内置函数对数据进行处理,并且在这些函数的使用中,也会出现逗号(如
regexp_replace(source_string, pattern, replace_string)
函数),这种情况会影响字段分割,需要专门处理。考虑这种逗号都会出现在函数括号之内,我们可以根据这个规律区分这个逗号是用于分割字段,还是用于调用函数中。
p = re.compile('\.*?[(](.*?)[)]', re.S)
经过以上的处理,我们可以通过逗号来分割出我们想要定义的字段,如果字段是通过别名来定义,那可以再以空格分割一下,取倒数第一位,也能提取出要定义的字段了。
(3)字段自动化注释
为了对要定义的字段进行自动化注释,这里以业务中已有的表作为参考,把每个表的字段及注释提取出来,并来构建成字典。
以 Hive 为例,批量查看表字段及注释的方法,最简单的就是:直接查询 Hive 元数据,在元数据库中可以通过 SQL 语句查询表结构、权限信息等各种表属性。
不过在大部分的情况下,我们都没有元数据相关的查询权限。但我们平时通过
desc tbl_name
或
show create table tbl_name
语句查询到表里字段名和备注信息,因此我们可以借助 shell 脚本,把上述语句的查询结果存放(重定向)到临时文件,接下来就是文本处理的工作了,然后就能得到我们想要的信息了。
具体方法如下:
function ExecHive()
beeline --showHeader=false --verbose=false --showWarnings=false --outputformat=tsv -n ${username} -p ${password} -u 'jdbc:hive2://server1,server2,server3/;serviceDiscoveryMode=zooKeeper;' -e $1
databases=('db1' 'db2')
for database in ${databases[@]}
ExecHive "use $database ; show tables ;" | sed s/\'//g > /home/result/$database
rm /home/result/desc_tbl/$database
for table in `cat /home/result/$database`
# 获得分区信息的行号
line=`ExecHive "desc $database.$table ;" | awk '/# Partition Information/{print NR}'`
# 通过管道将 desc 的查询结果传递到 awk,并通过 awk -v 设置变量,规整结果输出
ExecHive "desc $database.$table ;" | awk -v line=${line} -v database=$database -v table=$table '{if(NR<line){print database"."table"\t"$0}}' | sed s/\'//g >> /home/result/desc_tbl/$database
done得到的数据再经过统计,就可以知道每个字段在所有表里的注释分布以及数据类型分布,默认大家大部份时间都按照规范来建表的话,取量高的注释或数据类型为定义标准即可。
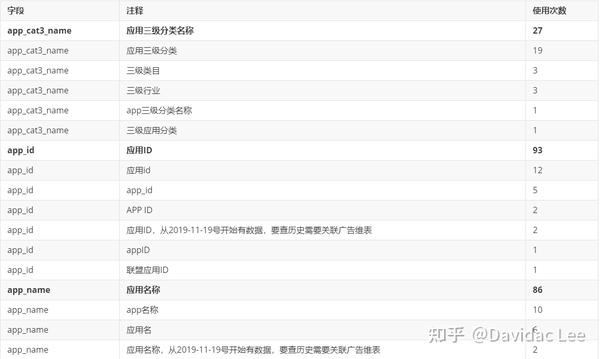

为方便在 Python 上查询到注释,这里把字段的注释和数据类型的定义标准导入进 Python 程序,并以 dict 的形式呈现出来,如:
sql_col_dict = {
"dt": {"col": "dt", "comment": "日期", "dtype": "string"},
"imei": {"col": "imei", "comment": "imei", "dtype": "string"},
"busi_type": {"col": "busi_type", "comment": "业务类型", "dtype": "string"},
"prod_id": {"col": "prod_id", "comment": "商品ID", "dtype": "string"},
"click_nums": {"col": "down_nums", "comment": "点击量", "dtype": "bigint"},
"pay_nums": {"col": "pay_nums", "comment": "购买量", "dtype": "bigint"},
"amount": {"col": "amount", "comment": "金额", "dtype": "bigint"},
"expose_nums":{"col": "expose_nums", "comment": "曝光量", "dtype": "bigint"},
"cvr":{"col": "cvr", "comment": "转化率", "dtype": "double"},
"ctr":{"col": "ctr", "comment": "点击率", "dtype": "double"}
不过在实际工作中,每个人的开发与命名习惯都有所不同,根据实际需求定义新字段并不少见,虽然我们可以设置每天运行脚本来更新字典,字典覆盖范围也会越来越壮大,但还是未能完全解决新定义字段的自动注释问题,所以最后还是需要自己手动修改个性化的注释或者约束这些过于个性化的操作,所以这里试图探索另一种解决方案,引入外部的翻译 API 对字段进行翻译,如百度翻译 API,参照官方文档的说明,我们只要构建这样的 URL 并进行请求,就能得到翻译结果了。

至于准确率……可以参考下。


以上,字段的解析与自动注释的思路已经梳理清楚了,接下来可以直接 coding:
sql = """
select
,busi_type
,app_id
,app_name
,sum(expose_nums) expose_nums
,sum(click_nums) click_nums
,sum(pay_nums) pay_nums
,sum(amount) amount
,sum(click_nums)/sum(expose_nums) ctr
from tmp_db.ods_tbl
where dt = 20200923
group by dt
,busi_type
,app_id
,app_name
sql_col_dict = {
"dt": {"col": "dt", "comment": "日期", "dtype": "string"},
"imei": {"col": "imei", "comment": "imei", "dtype": "string"},
"app_id": {"col": "app_id", "comment": "应用ID", "dtype": "string"},
"app_name": {"col": "app_name", "comment": "应用名称", "dtype": "string"},
"busi_type": {"col": "busi_type", "comment": "业务类型", "dtype": "string"},
"prod_id": {"col": "prod_id", "comment": "商品ID", "dtype": "string"},
"click_nums": {"col": "down_nums", "comment": "点击量", "dtype": "bigint"},
"pay_nums": {"col": "pay_nums", "comment": "购买量", "dtype": "bigint"},
"amount": {"col": "amount", "comment": "金额", "dtype": "bigint"},
"expose_nums":{"col": "expose_nums", "comment": "曝光量", "dtype": "bigint"},
"cvr":{"col": "cvr", "comment": "转化率", "dtype": "double"},
"ctr":{"col": "ctr", "comment": "点击率", "dtype": "double"}
sql = sql.lower()
col_list_tmp = sql.replace('\n', '').replace('select', '').replace('from', '?').replace('where', '?')
col_list_tmp = col_list_tmp.split('?')[0]
# 替换调用函数时括号里的逗号
p = re.compile('\.*?[(](.*?)[)]', re.S)
# print(re.findall(p, col_list_tmp))
col_list_tmp = p.sub('', col_list_tmp)
# # logging.debug('特殊字符处理' + col_list_tmp)
col_list_len = len(col_list_tmp.split(','))
sql_col_info = []
for i in range(col_list_len):
tmp_col = col_list_tmp.split(',')[i].strip()
if len(tmp_col.split(' ')) > 0:
col = tmp_col.split(' ')[-1]
else:
col = tmp_col
if col in sql_col_dict.keys():
info = sql_col_dict[col]
info.update(id=i)
else:
# comment = baidu_translate(col)
comment = '未知'
info = {"col": col, "comment": comment, "dtype":"string","id": i}
sql_col_info.append(info)
print('Analysis Result:', sql_col_info)输出结果为:
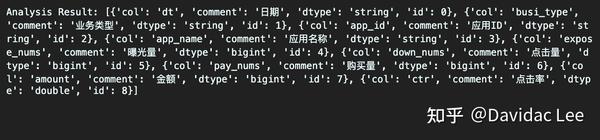

(4)构建建表语句
实现上述步骤以后,接下来就是对建表语句的各个元素进行拼接,需要对输出结果进行大量的微调。
db_name = 'test_db'
tbl_name = 'test_tbl'
tbl_comment = 'test_comment'
hive_text = ''
mysql_text = ''
for i in range(len(sql_col_info)):
col_info = sql_col_info[i]
if col_info['dtype'] == 'string':
mysql_text += '{col} varchar(40) comment "{comment}",\n'.format(**col_info)
else:
mysql_text += '{col} {dtype} comment "{comment}",\n'.format(**col_info)
if i == len(sql_col_info) - 1:
hive_text += '{col} {dtype} comment "{comment}"\n'.format(**col_info)
else:
hive_text += '{col} {dtype} comment "{comment}",\n'.format(**col_info)
hive_head = 'create table ' + db_name + '.'+ tbl_name + '\n('
hive_foot = ')' + ' comment "' + tbl_comment + '"\nPARTITIONED BY (dayno bigint COMMENT "日期")\nSTORED AS ORCFILE;'
mysql_head = "create table " + tbl_name + '\n(\n' + 'id bigint unsigned NOT NULL AUTO_INCREMENT COMMENT "主键ID",\ndt date NOT NULL DEFAULT "0000-00-00" COMMENT "日期,时间格式日期",\n'
mysql_foot = 'PRIMARY KEY (`id`,`dt`),\nKEY `idx_dt` (`dt`)\n) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT="' + tbl_comment + '"\nPARTITION BY RANGE (TO_DAYS(dt))\n(PARTITION pmin VALUES LESS THAN (737850) ENGINE = InnoDB,\nPARTITION pmax VALUES LESS THAN MAXVALUE ENGINE = InnoDB);'
hive_query = hive_head + '\n' + hive_text + hive_foot
mysql_query = mysql_head + mysql_text + mysql_foot
all_query = '<b># Hive 建表语句</b>' + '\n' + hive_query + '\n\n' + '<b># MySQL 建表语句</b>' + '\n' + mysql_query
tbl_query = {
'all_query': all_query
print(tbl_query)输出结果:


四、前后端交互
至此,我们可以在 Python 端完成 SQL 语句的解析和建表语句的搭建。接下来,需要把这个操作搬到前端 web 界面来完成。目前流行的 Python Web 开发框架有 Django、Tornado 和 Flask,无论采用哪种语言,使用框架技术都可以避免重复造轮子,从而快速高效地实现系统开发。而 Flask 框架的特点是轻量级且上手快,从安装(
pip install flask
)第一个网页的上线,输入的指令不到 10 行。
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return "Hello World"
if __name__ == '__main__':
app.run(port = 5000, debug = True)
Flask 框架很重要的一个概念是路由,路由的作用就是为用户请求的 URL 找出其对应的处理函数,在 Flask 中通过装饰器来定义路由,如上面的代码中的
@app.route('/')
,那就代表着但我们在浏览器输入根目录(本机的话就是 localhost 加端口) URL 和
/
时,就会调用
index()
,于是我们在前端页面才会看到 Hello World 的字样。同样地我们也可以对「字段解析及自动化注释」步骤的处理方法封装成函数,并注册一个路由,如
/sql_analysis
,这样我们就可以通过 URL 访问返回我们想要的处理结果了。


Hello World 版的网页上线后,同样地,我们可以通过简单的 HTML 标签实现我们预想中的交互控件。


这样前端页面的基础框架已经完成了。接下来就要考虑前后端交互的问题了,包括两点:
- 后端获取前端页面输入的信息;
- 后端处理完获取到的信息后往前端页面输出。
在常见的网页交互中,只有点击了按钮,信息才会提交,因此,我们需要对按钮控件下功夫。我们可以利用 HTML button 控件的 onclick 属性,用来定义我们点击按钮时触发的事件,具体数据交互流程为:
-
点击 button,触发
submit_entry()函数; -
通过
getElementById()获取页面对应 ID 的元素,并对变量进行赋值; - 将第 2 步获取得到的变量作为参数,构建 fetch 请求;
-
调用
/sql_analysis接口,获取字段处理结果,并写入到输出结果的 div
<!-- 定义展示输出结果的 div-->
<div class="output-frame">
<p class="step">二、输出结果</p>
<p class="output" id='output-result'>{{output}}</p>
</div>
<!-- button 控件注册 onclick 属性 -->
<button class="btn btn-primary" onclick="submit_entry();">分析</button>
<!-- 定义 submit_entry() 函数 -->
<script>
function submit_entry()
var tbl_name = document.getElementById("tbl_name");
var tbl_comment = document.getElementById("tbl_comment");
var sql = document.getElementById("sql");
var entry = {
tbl_name: tbl_name.value,
tbl_comment: tbl_comment.value,
sql: sql.value,
fetch(`${window.origin}/sql_analysis`, {
method: "POST",
credentials: "include",
body: JSON.stringify(entry),
cache: "no-cache",
headers: new Headers({
"content-type": "application/json"
.then(function(response) {
return response.json();
}).then(function(data) {
console.log(data);