最近开始学习图数据库了,图数据库JanusGraph(janus读音类:J+nes, jay 而不是je-nes),
JanusGraph
是一个分布式图数据库引擎,具有以下特性:
-
支持百亿级别的顶点&边的存储及查询
-
本身不负责存储,而是借助其他存储和索引组件配合达到图形数据的查询
-
支持事务,可并发执行复杂图操作

JanusGraph是一个可扩展的图数据库,可以把包含数千亿个顶点和边的图存储在多机集群上。它支持事务,支持数千用户实时、并发访问存储在其中的图。
(JanusGraph is a scalable graph database optimized for storing and querying graphs containing hundreds of billions of vertices and edges distributed across a multi-machine cluster. JanusGraph is a transactional database that can support thousands of concurrent users executing complex graph traversals in real time.)
💬图数据库就是用来存储图结构的数据库。图数据库也是属于NoSQL一种。
-NoSQL数据库大致可以分为以下几类:
-
键值对(key-value)数据库(遵循“键——值”模型,是最简单的数据库管理系统):如Memcache、Redis、Berkeley DB、SQLite…
-
列簇式数据库(按照列(由“键——值”对组成的列表)在数据文件中记录数据,以获得更好的请求及遍历效率。一行中的列数允许动态变化,且列的数目可达数百万,每条记录的关键码不同,支持多值列。):如HBase、hive、sybase IQ/SAPIQ、GreenPlum…
-
文档型数据库(无固定结构,不同的记录允许有不同的列数和列类型。列允许包含多值,记录允许嵌套):如Mongodb、Couchbase、Amazon DynamoDB、CouchDB、MarkLogic…
-
图数据库(以“点——边”组成的网络(图结构)来存储数据)
:如Neo4j、
JanusGraph
、OrientDB、Titan、Virtuoso、ArangoDB …
-
搜索引擎(存储的目的是为了搜索,主要功能是搜索):如Elasticsearch、Solr、Splunk、MarkLogic、Sphinx…
-
对象数据库(受面向对象编程语言的启发,把数据定义为对象并存储在数据库中,包括对象之问的关系,如继承):如Caché、db4o、Versant Object Database、ObjcctStore、Matisse …
-
时序数据库(存储时间序列数据,每条记录都带有时间戳。如存储从感应器采集到的数据):如InfluxDB、RRDtool、Graphite、OpcnTSDB、Kdb+ …
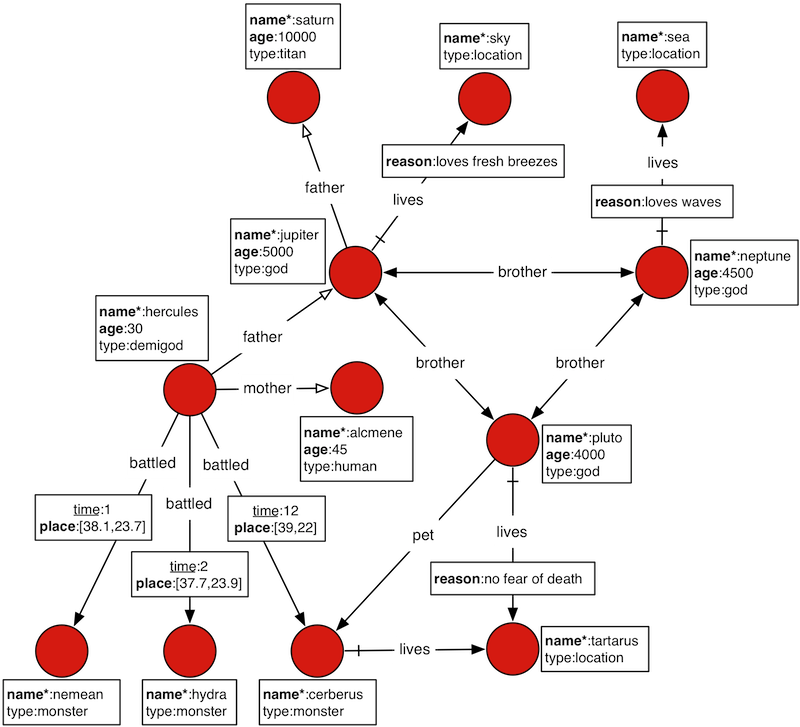
💬图数据库主要处理的是拓扑关系的图,善于处理大量、复杂、互联、多变的网状海量数据,其效率远远高于传统的关系型数据库。就比如下面的图:
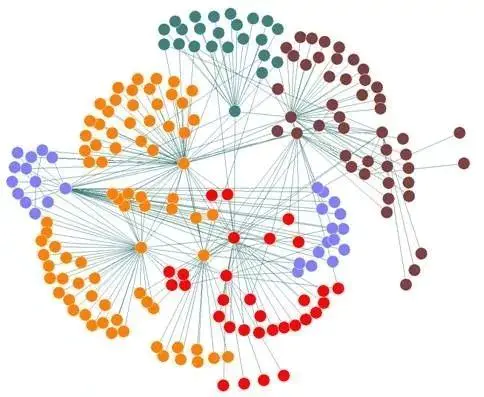
💬图数据库所提供的关联分析能力是
金融反欺诈、威胁情报、黑产打击和案件溯源
等业务所需要的核心能力。图数据库的需求非常多,例如金融安全业务希望使用图数据库进行金融反欺诈关联分析、威胁情报业务希望通过图数据库进行黑产研究和情报分析、还有社交关系分析、知识图谱等需求场景。
💬JanusGraph是一个图形数据库引擎。
其本身专注于紧凑图序列化、丰富图数据建模、高效的查询执行
。另外,JanusGraph利用Hadoop进行图分析和批处理图处理。JanusGraph为数据持久性、数据索引、客户端访问实现了强大的模块化接口。JanusGraph的模块化体系结构使其可以与多种存储、索引、客户端技术进行互操作。它还简化了扩展JanusGraph以支持新的过程。
JanusGraph可以适配多种数据库和索引
。JanusGraph默认支持以下的适配,但是JanusGraph的模块化架构使得也支持第三方的适配器。
数据库
:
-
Apache Cassandra
-
Apache HBase
-
Oracle Berkeley DB Java版
-
Elasticsearch
-
Apache Solr
-
Apache Lucene
💬JanusGraph是2016年12月27日从Titan fork出来的一个分支,之后TiTan的开发团队在2017年陆续发了0.1.0rc1、0.1.0rc2、0.1.1、0.2.0等四个版本,最新的版本是2017年10月12日。 titan是从2012年开始开发,到2016年停止维护的一个分布式图数据库。最初在2012年启动titan项目的公司是Aurelius,2015年此公司被 DataStax(DataStax是开发apache Cassandra 的公司)收购,DataStax公司吸收了TiTan的图存储能力,形成了自己的商业产品DataStax Enterprise Graph。
TiTan开发者们希望把TitTan放到Apache Software Foundation下,不过,DataStax不愿意这样做(可能考虑到要保护自己的商业产品DataStax Enterprise Graph的技术优势吧,其实这点优势是从Titan来的),而且自从2015年9月DataStax收购了Titan的母公司后,TiTan一直处于停滞状态(应该是DataStax收购之后,忙于推出自己的商业产品DataStax Enterprise Graph,忙于整合Titan进自己的商业产品吧,可是Titan本身没有得到发展)。鉴于此,2016年6月,TiTan的开发者们fork了一个TiTan的分支(因为Titan已经属于DataStax了,所以他们必须另外弄一个商标),重命名为JanusGraph,并将其置于Linux Software Foundation下。
2017年4月6日发布了第一个版本0.1.0-rc1,目前最新版本是2017年10月12日发布的0.2.0版。
JanusGraph项目启动的初衷是“通过为其增加新功能、改善性能和扩展性、增加后端存储系统来增强分布式图系统的功能,从而振兴分布式图系统的开发”,JanusGraph从Apahce TinkerPop中吸收了对属性图模型(Property Graph Model)的支持和对属性图模型进行遍历的Gremlin遍历语言。(“reinvigorate development of the distributed graph system to add new functionality, improve performance and scalability, and maintain a variety of storage backends,JanusGraph incorporates support for the property graph model with the open source graph computing framework Apache TinkerPop and its Gremlin graph traversal language”.)
💬它的整体架构,大致分为三部分:
-
图计算框架(TinkerPop)
-
数据存储(Cassandra,HBase,BerkeleyDB)
-
索引存储(Elasticsearch,Solr,Lucene)
JanusGraph从其框架上来说,是起到一个桥梁的作用。将各种开源的软件连接到一起,形成一个大型图数据库
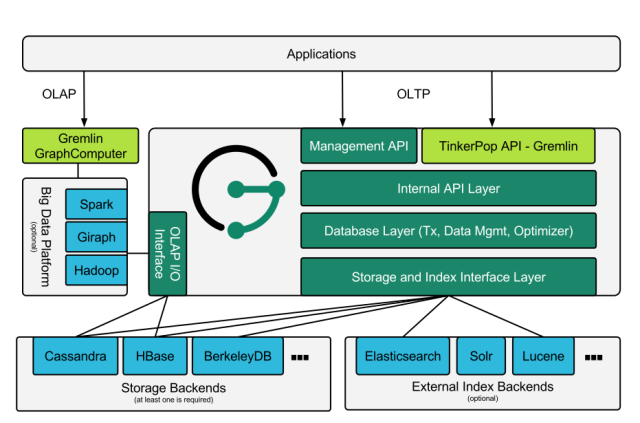
💬来源
General JanusGraph Benefits
-
Support for very large graphs. JanusGraph graphs scale with the
number of machines in the cluster.
-
Support for very many concurrent transactions and operational graph
processing. JanusGraph’s transactional capacity scales with the
number of machines in the cluster and answers complex traversal
queries on huge graphs in milliseconds.
-
Support for global graph analytics and batch graph processing through
the Hadoop framework.
-
Support for geo, numeric range, and full text search for vertices and
edges on very large graphs.
-
Native support for the popular property graph data model exposed by
Apache TinkerPop.
-
Native support for the graph traversal language Gremlin.
-
Numerous graph-level configurations provide knobs for tuning
performance.
-
Vertex-centric indices provide vertex-level querying to alleviate
issues with the infamous super node problem.
-
Provides an optimized disk representation to allow for efficient use
of storage and speed of access.
-
Open source under the liberal Apache 2 license.
百度翻译版:
-
支持非常大的图形。JanusGraph图随集群中的机器数量而扩展。
-
支持很多并发事务和操作图处理。JanusGraph的事务处理能力随着集群中机器的数量而扩展,并在毫秒内回答大型图上的复杂遍历查询。
-
通过Hadoop框架支持全局图分析和批处理图处理。
-
支持对超大图形上的顶点和边进行地理、数字范围和全文搜索。
-
对Apache TinkerPop公开的流行属性图数据模型的本机支持。
-
对图遍历语言Gremlin 的本机支持。
-
许多图形级配置提供了用于调整性能的旋钮。
-
以顶点为中心的索引提供顶点级查询,以缓解臭名昭著的超级节点问题。
-
提供优化的磁盘表示形式,以便高效使用存储和加快访问速度。
-
开放源代码,使用Apache2许可证。
-
后端数据存储可以由多种选择:Hbase、Cassandra、Google Bigtable等
-
满足实时的复杂图遍历、满足
ACID
一致性的
OLTP
-
可以利用外部如ElasticSearch、Solr、Lucene软件,实现全量文档的搜索功能
-
基于spark+hadoop的
OLAP
-
使用Gremlin语言查询;与Apache TinkerPop 项目高度兼容
OLTP
:
-
OLTP (Online Transactional Processing,
联机事务处理
)是专注于面向事务的任务的一类数据处理,通常涉及在数据库中插入,更新或删除少量数据,主要是处理大量用户下的大量事务。
-
OLTP事务实例: 在线银行、网上买一本书、预订一张机票、发送一个文本消息、电话推销员输入电话调查结果、呼叫中心员工查看和更新客户的详细信息
ACID
:
-
ACID,指数据库
事务正确执行的四个基本要素
的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),一个支持事务的数据库必须要支持这几个特性,否则无法保证数据的正确性。
-
联机实时分析
(OnlineAnalytical Processing, OLAP技术是快速响应多维分(Multidimensionalanalysis, MDA)的一种解决方案。它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。
💬JanusGraph有如下核心概念:
-
Vertex
:图中的点
-
Edge
:图中的边
-
Vertex Label
:节点类型,每个节点只能有一个Label(不同于Neo4j)
-
Edge Label
:边类型
-
Property Key
:属性名称(属性名称和边类型不能重复)
-
Property
:属性,key-value形式,janusgraph中属性有Cardinality的概念,包括SINGLE、LIST、SET三种,即对于一个属性key可以有单个值、列表值、集合值
(1)
第一种方式
:可以把JanusGraph嵌入到应用程序中去,JanusGraph和应用程序处在同一个JVM中。应用程序中的客户代码(相对JanusGraph来说是客户)直接调用Gremlin去查询JanusGraph中存储的图,这种情况下外部存储系统可以是本地的,也可以处在远程。
(2)
第二种方式
:应用程序和JanusGraph处在两个不同JVM中,应用通过给JanusGraph提交Gremlin查询给GremlinServer,来使用JanusGraph,因为JanusGraph原生是支持Gremlin Server的。(Gremlin Server是Apache Tinkerpop中的一个组件)。
常用数据库有哪些(附带数据库排名)?
JanusGraph
JanusGraph(一)–简介
JanusGraph:图数据库系统简介
JanusGraph学习之路:(1)概述
什么是OLTP?
OLAP基础
JanusGraph
入门
实操安装hbase查看hbase web UI安装
janusgraph
启动
janusgraph
服务配置conf/
janusgraph
-hbase-test01.properties修改gremlin-server.yaml配置启动
janusgraph
服务客户端交互gremlin控制台交互idea应用交互
本篇博客主要记录在centos上安装
janusgraph
以及在idea中开发
图
应用的简单示例过程,对于
janusgraph
和gremlin相关的概念和语法不做介绍。具体可自行查阅相关
###1.什么是知识
图
谱
知识
图
谱:是显示知识发展进程与结构关系的一系列各种不同的
图
形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
###2.知识
图
谱应用
知识
图
谱的应用场景非常广泛:
场景一 新闻事件的关联分析
场景二 识别反欺诈潜在风险
场景三 不一致性验证识别
场景四 失联客户管理
JanusGraph
简介
JanusGraph
是一个可扩展的
图
数据库
,可以把包含数千亿个顶点和边的
图
存储在多机集群上。它支持事务,支持数千用户实时、并发访问存储在其中的
图
。
我们可以将
图
数据库
系统的应用领域划分成以下两部分:
用于联机事务
图
的持久化技术(通常直接实时地从应用程序中访问)。这类技术被称为
图
数据库
,它们和“通常的”关系型
数据库
世界中的联机事务处理(Online Transacti...
笔者由于工作中需要用到
图
数据库
,所以花2小时研究了下
Janus
Graph
这个开源项目,下面是一些学习心得,如果后面使用有更多启发再更新,如有错误,欢迎纠正。
学习一门技术最标准的方式是从官网
入门
:https://docs.
janusgraph
.org/
然后搞清楚以下问题即可:
是什么?为什么出现?
再深入理解原理
1.
JanusGraph
是什么
本质问题是
图
数据库
是什么...
(1)什么是
数据库
:
硬盘—管理软件
数据库
(
Data
Base、DB)是一个长期存储在计算机内、有组织的、有共享的、统一管理的数据集合。他简而言之就是一个存储数据的仓库。为了方便数据的存储和管理,他将数据按照特定的规律存储在硬盘上,通过
数据库
管理系统,可以有效的组织和管理存储再
数据库
中的数据。
我们也可以说
数据库
是由一批
数据库
的有序集合,这些数据被存放在结构化的数据表里。数据表之间相互关联、反映了客观事物间的本质联系。
数据库
系统提供对数据的安全控制和完整性控制。
2.
数据库
系统:
数据库
系统由3部分组成:
(1)
数据库
:用于存储数据的地方
(2)
数据库
管理系统:用于管理数据的软件
(3)
数据库
数据库
管理系统(
Data
base Management System)是一种操纵和管理
数据库
的大型软件,用于建立、使用和维护
数据库
,简称DBMS。它对
数据库
进行统一的管理和控制,以保证
数据库
的安全性和完整性。用户通过DBMS访问
数据库
中的数据,
数据库
管理员也通过DBMS进行
数据库
的维护工作。它可以支持多个应用程序和用户用不同的方法在同时或不同时刻去建立,修改和询问
数据库
。大部分DBMS提供数据定义语言DDL(
Data
Definition Language)和数据操作语言DML(
Data
Manipulation Language),供用户定义
数据库
的模式结构与权限约束,实现对数据的追加、删除等操作。
非常感谢您的提问。以下是我对“spark从
入门
到放弃——
初识
spark(一)”的回答:
“spark从
入门
到放弃”是一个非常有趣的话题,而“
初识
spark(一)”则是其中的第一篇文章。在这篇文章中,作者主要介绍了Spark的基本概念和特点,包括Spark的分布式计算模型、RDD(弹性分布式数据集)的概念和特点、Spark的运行模式等等。此外,作者还介绍了如何在本地环境中安装和配置Spark,并给出了一些简单的示例代码,帮助读者更好地理解Spark的基本用法和操作方法。
总的来说,这篇文章对于初学者来说非常有帮助,可以帮助读者快速
入门
Spark,并了解其基本概念和特点。如果您对Spark感兴趣,我建议您可以继续阅读“spark从
入门
到放弃”系列文章,深入了解Spark的更多知识和应用。

