第二步:
由频繁项集产生强关联规则。由第一步可知,未超过预定的最小支持阈值的项集已被剔除,如果剩下的这些项集又满足了预定的最小置信度阈值,那么就挖掘出了强关联规则。
以餐饮行业点餐数据为例,首先先将事务数据整理成关联规则模型所需的数据结构。设最小支持度为0.2,将菜品id编号
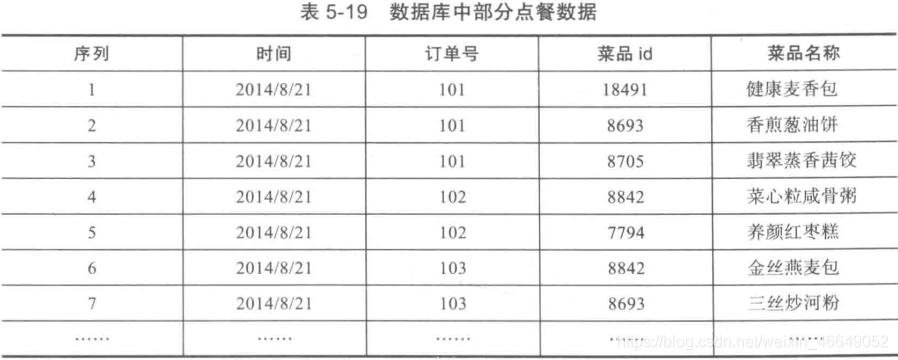
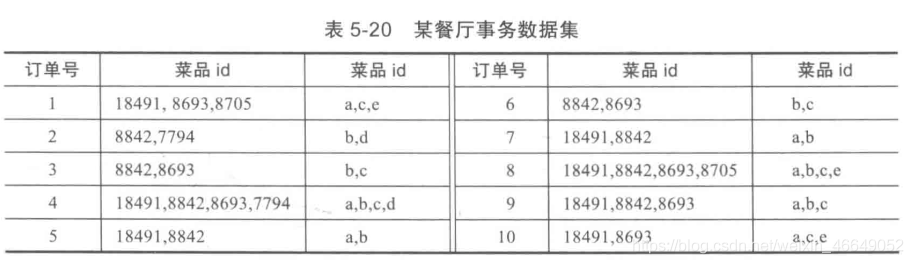
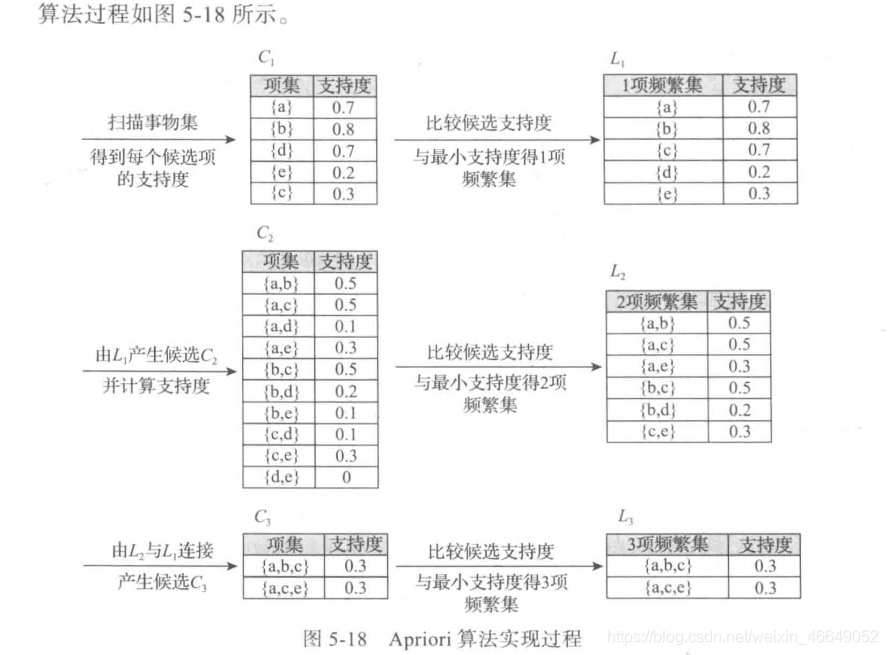



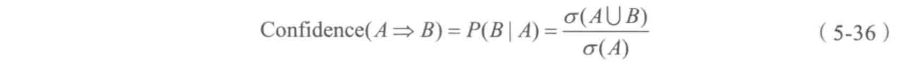


数据集链接
import numpy as np
import pandas as pd
def connect_string(x, ms):
与1项频繁集连接生成新的项集
:param x: 项集
:param ms:
:return: 新的项集
x = list(map(lambda i: sorted(i.split(ms)), x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i, len(x)):
if x[i][:l - 1] == x[j][:l - 1] and x[i][l - 1] != x[j][l - 1]:
r.append(x[i][:l - 1] + sorted([x[j][l - 1], x[i][l - 1]]))
return r
def find_rule(d, support, confidence, ms=u'-'):
寻找关联规则
:param d: 数据集
:param support: 最小支持度
:param confidence: 最小置信度
:param ms: 项集之间连接符号
:return: 强关联规则以及其支持度与置信度
result = pd.DataFrame(index=['support', 'confidence'])
support_series = 1.0 * d.sum(axis=0) / d.shape[0]
column = list(support_series[support_series > support].index)
k = 0
while len(column) > 1:
k =
k + 1
print(u'\n正在进行第%s次搜索...' % k)
column = connect_string(column, ms)
print(u'数目:%s...' % len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only=True)
d_2 = pd.DataFrame(list(map(sf, column)), index=[ms.join(i) for i in column]).T
support_series_2 = 1.0 * d_2[[ms.join(i) for i in column]].sum() / len(d)
column = list(support_series_2[support_series_2 > support].index)
support_series = support_series.append(support_series_2)
column2 = []
for i in column:
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j] + i[j + 1:] + i[j:j + 1])
cofidence_series = pd.Series(index=[ms.join(i) for i in column2])
for i in column2:
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))] / support_series[ms.join(i[:len(i) - 1])]
for i in cofidence_series[cofidence_series > confidence].index:
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
result = result.T.sort_values(['confidence', 'support'], ascending=False)
print(u'\n结果为:')
print(result)
return result
if __name__ == '__main__':
data = pd.read_excel('../data/menu_orders.xls', header=None)
print('转换原数据到0-1矩阵')
ct = lambda x: pd.Series(1, index=x[pd.notnull(x)])
b = map(ct, data.values)
data = pd.DataFrame(list(b)).fillna(0)
del b
support = 0.2
confidence = 0.5
find_rule(data, support, confidence)
转换原数据到0-1矩阵
正在进行第1次搜索...
数目:6...
正在进行第2次搜索...
数目:3...
正在进行第3次搜索...
数目:0...
support confidence
e-a 0.3 1.000000
e-c 0.3 1.000000
c-e-a 0.3 1.000000
a-e-c 0.3 1.000000
c-a 0.5 0.714286
a-c 0.5 0.714286
a-b 0.5 0.714286
c-b 0.5 0.714286
b-a 0.5 0.625000
b-c 0.5 0.625000
a-c-e 0.3 0.600000
b-c-a 0.3 0.600000
a-c-b 0.3 0.600000
a-b-c 0.3 0.600000
其中,'e—a’表示e发生能够推出a发生,置信度为100%,支持度30%。搜索出的关联规则并不一定有实际意义,需要根据问题背景筛选适当的有意义的规则,并赋予合理的解释。
案例数据百度网盘链接-提取码:1234
import numpy as np
import pandas as pd
def loadDataSet():
return [['a', 'c', 'e'], ['b', 'd'], ['b', 'c'], ['a', 'b', 'c', 'd'], ['a', 'b'], ['b', 'c'], ['a', 'b'],
[
'a', 'b', 'c', 'e'], ['a', 'b', 'c'], ['a', 'c', 'e']]
def loaddata():
order_data = pd.read_csv('data/GoodsOrder.csv', header=0, encoding='gbk')
order_data['Goods'] = order_data['Goods'].apply(lambda x: "," + x)
order_data = order_data.groupby('id').sum().reset_index()
order_data['Goods'] = order_data['Goods'].apply(lambda x: [x[1:]])
order_data_list = list(order_data['Goods'])
data_translation = []
for i in order_data_list:
p = i[0].split(",")
data_translation.append(p)
return data_translation
def creatC1(data):
找到1项候选集C1
:param data: 数据集
:return: 1项候选集C1
C1 = []
for row in dataSet:
for item in row:
if [item] not in C1:
C1.append([item])
C1.sort()
return list(map(frozenset, C1))
def calSupport(D, C, minSupport):
计算1项候选集的支持度,剔除小于最小支持度的项集,
:param D: 数据集
:param C1: 候选集
:param minSupport: 最小支持度
:return: 返回1项频繁集及其支持度
dict_sup = {}
for i in D:
for j in C:
if j.issubset(i):
if j not in dict_sup:
dict_sup[j] = 1
else:
dict_sup[j] += 1
sumCount = float(len(D))
supportData = {}
relist = []
for i in dict_sup:
temp_sup = dict_sup[i] / sumCount
if temp_sup > minSupport:
relist.append(i)
supportData[i] = temp_sup
return relist, supportData
def aprioriGen(Lk, k):
改良了剪枝步,原来的Ck是由L1与L(k-1)来连接产生的,这里采用了新的连接方式
使用剪枝算法,减少了候选集空间,找到k项候选集
:param Lk: k-1项频繁集
:param k: 第k项
:return: 第k项候选集
reList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i + 1, lenLk):
L1 = list(Lk[i])[:k - 2]
L2 = list(Lk[j])[:k - 2]
L1.sort()
L2.sort()
if L1 == L2:
a = Lk[i] | Lk[j]
a1 = list(a)
b = []
for q in range(len(a1)):
t = [a1[q]]
tt = frozenset(set(a1) - set(t))
b.append(tt)
t = 0
for w in b:
if w in Lk:
t += 1
if len(b) == t:
reList.append(b[0] | b[1])
return reList
def scanD(D, Ck, minSupport):
计算候选k项集的支持度,剔除小于最小支持度的候选集,得到频繁k项集及其支持度
:param D: 数据集
:param Ck: 候选k项集
:param minSupport: 最小支持度
:return: 返回频繁k项集及其支持度
sscnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid):
if can not in sscnt:
sscnt[can] = 1
else:
sscnt[can] += 1
numItem = len(
D)
reList = []
supportData = {}
for key in sscnt:
support = sscnt[key] / numItem
if support > minSupport:
reList.insert(0, key)
supportData[key] = support
return reList, supportData
def apriori(dataSet, minSupport=0.2):
apriori关联规则算法
:param data: 数据集
:param minSupport: 最小支持度
:return: 返回频繁集及对应的支持度
C1 = creatC1(dataSet)
D = list(map(set, dataSet))
L1, supportData = calSupport(D, C1, minSupport)
L = [L1]
k = 2
while len(L[k - 2]) > 0:
Ck = aprioriGen(L[k - 2], k)
Lk, supK = scanD(D, Ck, minSupport)
supportData.update(supK)
L.append(Lk)
k += 1
del L[-1]
return L, supportData
def getSubset(fromList, totalList):
生成集合的所有子集
:param fromList:
:param totalList:
for i in range(len(fromList)):
t = [fromList[i]]
tt = frozenset(set(fromList) - set(t))
if tt not in totalList:
totalList.append(tt)
tt = list(tt)
if len(tt) > 1:
getSubset(tt, totalList)
def calcConf(freqSet, H, supportData, ruleList, minConf):
计算置信度,并剔除小于最小置信度的数据,这里利用了提升度概念
:param freqSet: k项频繁集
:param H: k项频繁集对应的所有子集
:param supportData: 支持度
:param RuleList: 强关联规则
:param minConf: 最小置信度
for conseq in H:
conf = supportData[freqSet] / supportData[freqSet - conseq]
lift = supportData[freqSet] / (supportData[conseq] * supportData[freqSet - conseq])
if conf >= minConf and lift > 1:
print(freqSet - conseq, '-->', conseq, '支持度', round(supportData[freqSet], 6), '置信度:', round(conf, 6),
'lift值为:', round(lift, 6))
ruleList.append((freqSet - conseq, conseq, conf))
def get_rule(L, supportData, minConf=0.7):
生成强关联规则:频繁项集中满足最小置信度阈值,就会生成强关联规则
:param L: 频繁集
:param supportData: 支持度
:param minConf: 最小置信度
:return: 返回强关联规则
bigRuleList = []
for i in range(1, len(L)):
for freqSet in L[i]:
H1 = list(freqSet)
all_subset = []
getSubset(H1, all_subset)
calcConf(freqSet, all_subset, supportData, bigRuleList, minConf)
return bigRuleList
if __name__ == '__main__':
dataSet = loaddata()
L, supportData = apriori(dataSet, minSupport=0.02)
rule = get_rule(L, supportData, minConf=0.35)
生成的强关联规则如下:
frozenset({'水果/蔬菜汁'}) --> frozenset({'全脂牛奶'}) 支持度 0.02664 置信度: 0.368495 lift值为: 1.44216
frozenset({'人造黄油'}) --> frozenset({'全脂牛奶'}) 支持度 0.024199 置信度: 0.413194 lift值为: 1.617098
frozenset({'仁果类水果'}) --> frozenset({'全脂牛奶'}) 支持度 0.030097 置信度: 0.397849 lift值为: 1.557043
frozenset({'牛肉'}) --> frozenset({'全脂牛奶'}) 支持度 0.021251 置信度: 0.405039 lift值为: 1.58518
frozenset({'冷冻蔬菜'}) --> frozenset({'全脂牛奶'}) 支持度 0.020437 置信度: 0.424947
lift值为: 1.663094
frozenset({'本地蛋类'}) --> frozenset({'其他蔬菜'}) 支持度 0.022267 置信度: 0.350962 lift值为: 1.813824
frozenset({'黄油'}) --> frozenset({'其他蔬菜'}) 支持度 0.020031 置信度: 0.361468 lift值为: 1.868122
frozenset({'本地蛋类'}) --> frozenset({'全脂牛奶'}) 支持度 0.029995 置信度: 0.472756 lift值为: 1.850203
frozenset({'黑面包'}) --> frozenset({'全脂牛奶'}) 支持度 0.025216 置信度: 0.388715 lift值为: 1.521293
frozenset({'糕点'}) --> frozenset({'全脂牛奶'}) 支持度 0.033249 置信度: 0.373714 lift值为: 1.462587
frozenset({'酸奶油'}) --> frozenset({'其他蔬菜'}) 支持度 0.028876 置信度: 0.402837 lift值为: 2.081924
frozenset({'猪肉'}) --> frozenset({'其他蔬菜'}) 支持度 0.021657 置信度: 0.375661 lift值为: 1.941476
frozenset({'酸奶油'}) --> frozenset({'全脂牛奶'}) 支持度 0.032232 置信度: 0.449645 lift值为: 1.759754
frozenset({'猪肉'}) --> frozenset({'全脂牛奶'}) 支持度 0.022166 置信度: 0.38448 lift值为: 1.504719
frozenset({'根茎类蔬菜'}) --> frozenset({'全脂牛奶'}) 支持度 0.048907 置信度: 0.448694 lift值为: 1.756031
frozenset({'根茎类蔬菜'}) --> frozenset({'其他蔬菜'}) 支持度 0.047382 置信度: 0.434701 lift值为: 2.246605
frozenset({'凝乳'}) --> frozenset({'全脂牛奶'}) 支持度 0.026131 置信度: 0.490458 lift值为: 1.919481
frozenset({'热带水果'}) --> frozenset({'全脂牛奶'}) 支持度 0.042298 置信度: 0.403101 lift值为: 1.577595
frozenset({'柑橘类水果'}) --> frozenset({'全脂牛奶'}) 支持度 0.030503 置信度: 0.36855 lift值为: 1.442377
frozenset({'黄油'}) --> frozenset({'全脂牛奶'}) 支持度 0.027555 置信度: 0.497248 lift值为: 1.946053
frozenset({'酸奶'}) --> frozenset({'全脂牛奶'}) 支持度 0.056024 置信度: 0.401603 lift值为: 1.571735
frozenset({'其他蔬菜'}) --> frozenset({'全脂牛奶'}) 支持度 0.074835 置信度: 0.386758 lift值为: 1.513634
frozenset({'全脂牛奶', '酸奶'}) --> frozenset({'其他蔬菜'}) 支持度 0.022267 置信度: 0.397459 lift值为: 2.054131
frozenset({'酸奶', '其他蔬菜'}) --> frozenset({'全脂牛奶'}) 支持度 0.022267 置信度: 0.512881 lift值为: 2.007235
frozenset({'全脂牛奶', '根茎类蔬菜'}) --> frozenset({'其他蔬菜'}) 支持度 0.023183 置信度: 0.474012 lift值为: 2.44977
frozenset({'根茎类蔬菜', '其他蔬菜'}) --> frozenset({'全脂牛奶'}) 支持度 0.023183 置信度: 0.48927 lift值为: 1.914833
import numpy as np
import pandas as pd
import xlrd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
import warnings
warnings.filterwarnings("ignore")
def loaddata():
order_data = pd.read_csv('data/GoodsOrder.csv', header=0, encoding='gbk')
order_data['Goods'] = order_data['Goods'].
apply(lambda x: "," + x)
order_data = order_data.groupby('id').sum().reset_index()
order_data['Goods'] = order_data['Goods'].apply(lambda x: [x[1:]])
order_data_list = list(order_data['Goods'])
data_translation = []
for i in order_data_list:
p = i[0].split(",")
data_translation.append(p)
return data_translation
if __name__ == '__main__':
dataSet = loaddata()
column_list = []
for var in dataSet:
column_list = set(column_list) | set(var)
print('转换原数据到0-1矩阵')
data = pd.DataFrame(np.zeros((len(dataSet), 169)), columns=column_list)
for i in range(len(dataSet)):
for j in dataSet[i]:
data.loc[i, j] += 1
frequent_itemsets = apriori(data, min_support=0.02, use_colnames=True)
print(pd.DataFrame(frequent_itemsets))
pd.DataFrame(frequent_itemsets).to_csv('frequent_itemsets.csv')
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.35)
print(pd.DataFrame(rules))
pd.DataFrame(rules).to_csv('rules.csv')
support itemsets
0 0.038434 (威化饼)
1 0.026029 (一般饮料)
2 0.025826 (一般肉类)
3 0.033452 (超高温杀菌的牛奶)
4 0.064870 (黑面包)
.. ... ...
117 0.024301 (香肠, 苏打)
118 0.027351 (苏打, 酸奶)
119 0.021047 (苏打, 糕点)
120 0.023183 (根茎类蔬菜, 全脂牛奶, 其他蔬菜)
121 0.022267 (酸奶, 全脂牛奶, 其他蔬菜)
[122 rows x 2 columns]
antecedents consequents ... leverage conviction
0 (黑面包) (全脂牛奶) ... 0.008641 1.217899
1 (猪肉) (全脂牛奶) ... 0.007435 1.209520
2 (猪肉) (其他蔬菜) ... 0.010502 1.291779
3 (牛肉) (全脂牛奶) ... 0.007845 1.251315
4 (根茎类蔬菜) (全脂牛奶) ... 0.021056 1.350401
5 (根茎类蔬菜) (其他蔬菜) ... 0.026291 1.426693
6 (水果/蔬菜汁) (全脂牛奶) ... 0.008168 1.178904
7 (其他蔬菜) (全脂牛奶) ... 0.025394 1.214013
8 (人造黄油) (全脂牛奶) ... 0.009235 1.268706
9 (凝乳) (全脂牛奶) ... 0.012517 1.461085
10 (黄油) (全脂牛奶) ... 0.013395 1.480817
11 (柑橘类水果) (全脂牛奶) ... 0.009355 1.179008
12 (冷冻蔬菜) (全脂牛奶) ... 0.008149 1.294636
13 (热带水果) (全脂牛奶) ... 0.015486 1.247252
14 (酸奶油) (全脂牛奶) ... 0.013916 1.352735
15 (本地蛋类) (全脂牛奶) ... 0.013783 1.412030
16 (酸奶) (全脂牛奶) ... 0.020379 1.244132
17 (糕点) (全脂牛奶) ... 0.010516 1.188729
18 (仁果类水果) (全脂牛奶) ... 0.010767 1.236375
19 (黄油) (其他蔬菜) ... 0.009308 1.263065
20 (酸奶油) (其他蔬菜) ... 0.015006 1.350565
21 (本地蛋类) (其他蔬菜) ... 0.009991 1.242619
22 (根茎类蔬菜, 全脂牛奶) (其他蔬菜) ... 0.013719 1.533320
23 (根茎类蔬菜, 其他蔬菜) (全脂牛奶) ... 0.011076 1.457687
24 (全脂牛奶, 酸奶) (其他蔬菜) ... 0.011427 1.338511
25 (酸奶, 其他蔬菜) (全脂牛奶) ... 0.011174 1.528340
[26 rows x 9 columns]
参考于《python数据分析与挖掘实战》,后面有时间的话,会基于《机器学习实战》学习一下FP-Tree关联规则分析
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论留言!

pip install mlxtend
调用apriori进行关联规则分析,具体代码如下,其中数据集选取本博客 “机器学习算法——关联规则” 中的例子,可进行参考,设置最小支持度(min_support)为0.4,最小置信度(min_threshold)为0.1,
最小提升度(lift)为1.0,对数据集进行关联规则分析,
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxte
Apriori算法的高效纯Python实现。 适用于Python 3.6及更高版本。
先验算法发现分类数据中的隐藏结构。 经典示例是一个数据库,其中包含从超市购买的商品。 每次购买都有许多与之相关的物品。 我们想从数据中发现关联规则,例如{bread, eggs} -> {bacon} 。 这是的目标,而可以说是解决此问题的最著名算法。 该存储库包含apriori算法的有效,经过测试的实现,如Agrawal等人于1994年发表的中所述。
该代码是稳定的并且被广泛使用。 Bonaccorso在《精通机器学习算法》一书中对此进行了引用。
这是一个最小的工作示例。 请注意,在每次有eggs交易中,也有bacon 。 因此,将以100%的置信度返回规则{eggs} -> {bacon} 。
from efficient_apriori import apriori
支持度衡量一个项集在数据集中出现的频率,定义为包含该项集的事务数目与总事务数的比例。置信度衡量关联规则的可靠性,定义为规则的支持度与规则左侧项集的支持度的比值。Apriori算法通过逐层搜索的方式逐渐生成更高阶的频繁项集,直到不能再生成新的频繁项集为止。Apriori算法的主要思想是利用频繁项集的性质,通过逐层搜索的方式发现频繁项集。1.初始扫描:计算单个项的支持度,筛选出满足最小支持度阈值的项集作为一阶频繁项集。3.频繁项集计数:对候选k阶项集进行扫描,计算每个项集的支持度。
关联规则分析是数据挖掘中最活跃的研究方法之一,目的是在一个数据集中找到各项之间的关联关系,而这种关系并没有在数据中直接体现出来。Apriori算法关联规则学习的经典算法之一,是R.Agrawal和R.Srikartt于1944年提出的一种具有影响力的挖掘布尔关联规则挖掘频繁项集的算法。
啤酒与尿布的故事:
在美国,一些年轻的父亲下班后经常要到超市去买婴儿尿布,超市也因此发现了一个规律,在购买婴儿尿布的年轻的父亲们中,有30%~40%的人同时要买一些啤酒。超市随后调整了货架的摆放,将尿布和啤酒放在一起,因此,明显增加了销售额。
关联规则常用算法
关联规则(Association Rules)是海量数据挖掘(Mining Massive Datasets,MMDs)非常经典的任务,其主要目标是试图从一系列事务集中挖掘出频繁项以及对应的关联规则。关联规则来自于一个家喻户晓的“啤酒与尿布”的故事,本文通过故事来引出关联规则的方法。
啤酒与尿布的故事
在一家超市里,有一个有趣的现象:尿布和啤酒赫然摆在一起出售。但是这个奇怪的举措却使尿布和啤酒的销量双双增加了。这不是一个笑话,而是发生在美国沃尔玛连锁店超市的真实案例,并一直为商家
问题引入关联规则挖掘发现大量数据中项集之间有趣的关联或者相互联系。关联规则挖掘的一个典型例子就是购物篮分析,该过程通过发现顾客放入其购物篮中不同商品之间的联系,分析出顾客的购买习惯,通过了解哪些商品频繁地被顾客同时买入,能够帮助零售商制定合理的营销策略。购物篮事务的例子如下图所示:
例如:在同一次去超级市场时,如果顾客购买牛奶,同时他也购买面包的可能性有多大?
通过帮助零售商有选择地经销
关联规则算法总结
文章目录一、Apriori、FP Growth算法原理:1.1 Apriori算法原理1.2 FP Growth(Frequent Pattern Growth)算法原理二、Apriori、FP Growth算法的实现三、实际应用
一、Apriori、FP Growth算法原理:
频繁项集的评估标准有:
1.1 Apriori算法原理
频繁项集: 是支持值大于阈值(support)的项集。
关联分析的目的:
发现频繁项集:发现满足最小支持度的所有项集;
发现关联规则:从频繁项集中提
★ 关联分析:
从大规模数据集中寻找物品间的隐含关系被称作关联分析。而寻找物品的不同组合是一项十分耗时的任务,所需的计算代价很高。Apriori算法正是来解决这一问题。
物品之间的关系一般可以有两种形式:频繁项集和关联规则。
频繁项集:数据集中经常出现在一块的物品的集合。
关联规则:两种物品之间可能存在很强的关系。
两个重要参数:
1、频繁项集(frequent item sets)。包括计算:频繁项集的支持度(support)
2、关联规则(association rules)。包括计算:关联规则的置信度(confidence)
频繁项集(frequent item sets),支持度(support)
单是肉眼去观察的话,似乎顾客经常购买P1, P2这样的组合。这种的购物中出现的经常的组合,就是我们要找的频繁项集了。项集可以由一个商品组成,也可以由多个商品组成。比如
参考《【机器学习实战-python3】使用Apriori算法进行关联 分析》,《 使用Apriori进行关联分析(一)》,《使用Apriori进行关联分析(二)》,《关于apriori算法中置信度、支持度怎么理解的问题》
文章目录1. 频繁项集(frequent item sets)1.1 频繁项集的支持度(support)和阈值1.2 频繁项集的特点1.3 频繁项集计算方法
关联规则的目的在于分析出经常出现在一起的物品的集合之间的关系。Apriori算法本质由两部分组成,分别是
频繁项集(frequ.
由啤酒和尿布引出:
在一家超市中,人们发现了一个特别有趣的现象:尿布与啤酒这两种风马牛不相及的商品居然摆在一起。但这一奇怪的举措居然使尿布和啤酒的稍量大幅增加了。这可不是一个笑话,而是一直被商家所津津乐道的发生在美国沃尔玛连锁超市的真实案例。原来,美国的妇女通常在家照顾孩子,所以她们经常会嘱咐丈夫在下班回家的路上为孩子买尿布,而丈夫在买尿布的同时又会顺手购买自己爱喝的啤酒。这个发现为商家带来

