


数据分析理论系列3——异常分析

上一篇:
初版时间:2020年4月2日
更新时间:2020年4月8日 01:16:16
一个已上线的产品数据运营分析包含三个部分,确认当前阶段的主要目标、监控目标、异常分析和处理。大致流程如下:


一、异常分析方法概述
首先,异常是比较出来的,近期和长期(环比和同比),如果确实可以定义为自然增值,那么就没有太大的必要深究,如果定义为异常,那么就可以去挖掘导致变化的原因了。
然后,异常数据分析思路大致是两个方向,多变量分析和交叉分析(见引用部分)
接着,业务分析:运营部门采取了策略,可能导致这类的影响?
然后,综合两者去分析导致“异常”的原因,进行回归建模,进而评估关键变量对目标值会带来那些收益和损失。
最后,制定相应的策略去挽回损失或者复现增长。
异常数据分析:
1.多变量分析 :看看那些变量会影响目标值
直接影响——线性相关,相关性分析
间接影响——来源分布变化,例如用户群的改变、竞争格局的改变等
2. 交叉分析 :看看相关变量种哪些细分属性的影响更大,具体可以参见表格分析。
二、异常分析7步法,抄袭自 @磊叔-运营增长
1.变化量化
第一个步骤是量化变化,例如相同比/环比变化了多少?
可以通过描述统计来计算,例如同比、环比、定基比、均值、中位数、标准差等,描述统计可以参考: 相对静止:统计学原理之描述性统计——开篇
2.变化评估
第二个步骤是评估这个变化,可以问“异常的范围是什么?”“此时的变化是否属于异常?”
3类异常度量方法如下:
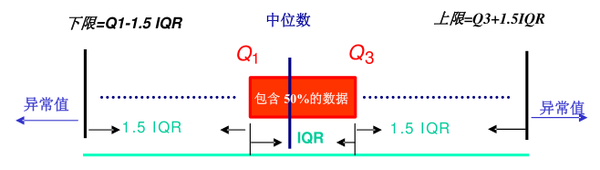
- 箱线图:[Q1 - 1.5IQR,Q3 + 1.5IQR],如图2;
- 3σ原则:正常值范围[μ-3σ,μ+3σ],前提分布属于正态分布,理论上可以覆盖99.74%的数据;
- 自定义:根据业务经验设定异常阈值;

3.多维、交叉列表分析
这个步骤主要用于 发现 目标变量的 主要的影响因素, 可以尝试问以下问题 :
- 那些变量可能导致该变化?相关程度如何?
- 哪些变量可能会影响变化的含金量呢?
- 变化的“幅度”有哪些其它解释?
3.1 直接影响(直接导致变化)
- 线性相关分析:
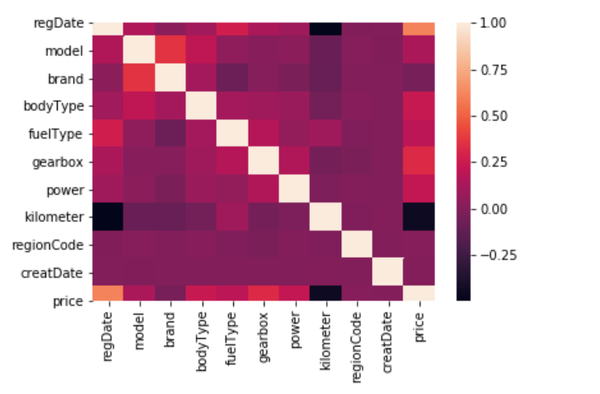
- 变量/维度层面:计算相关系数,或者绘制相关矩阵;
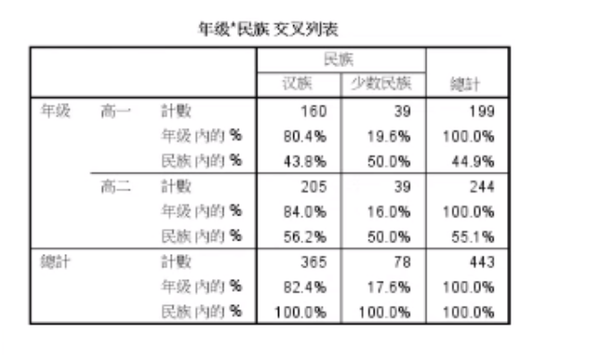
- 属性层面:进行交叉分析,绘制交叉分析表格或者直接通过SPSS的交叉表分析功能计算并进行检验;
- 非线性相关分析:
- 定性分析:散点图,肉眼观察变量间的变化是否有一定的规律可寻;
- 定量分析:可参考: Distance correlation(距离相关系数) ,当距离相关系数为0或者很接近0时,可以认为是没有非线性关系的;


3.2间接影响(有隐藏变量)
分布不均匀:直接对比绝对量,就相当于默认整体中分布是均匀的,但是往往都不是,解决方法是引入整体分布作对比,例如计算TGI指标,
- TGI的计算和含义可参考: 偏好度(TGI)是如何计算的,以及如何理解这个指标?
- 分布不均匀的数据分析示例: 闯红灯倾向和星座(出生月份)是否存相关性?
4.业务分析
这个步骤主要是考虑商业宣传和产品运营上的影响,是否有相关的操作可能导致该指标的变化?下面举3个例子:
- 例如促销力度加大了,可能导致下单用户量猛增,但是销售额却没有多大变化;
- 例如在快手上投放广告,没有在抖音上进行投放,所以产品里的北方人占比明显增加;
- 例如在B站进行运营初见成效,导致产品中弹幕使用量、AWSL、我可以等网络用语激增;
5.预测分析
这个步骤是为了将数据分析的结果就是目标变量和关键影响因素的相关性进行固定,相当于是一个简易版本的数据产品,这个数据产品里只有一个数据分析的思路:
- 建立模型(回归/时间序列分析) → 预测未来变化趋势
6.风险评估
这个步骤是为了量化损失和收益(核心KPI的变化),可以问这个问题:
- 该变化对产品的核心KPI有什么影响?
7.策略制定
这个步骤是为了采取行动,复现增长/避免损失,可以问以下两问题:
- 如何挽回损失/下次避免?
- 如何促进增长?/复现增长的流程?
三、总结
总的来说,就是 量化变化 、 定义异常 、 统计分析 、 业务分析 、 建模预测 、 风险分析 最后 回归业务 ,复现增长或者避免损失。
下一篇:
参考资料:
- 磊叔-运营增长:【十】第二场知乎Live:带你建立清晰有效的数据分析思路
- 蒋小北:培养数据分析思路:电商数据落地实战
- 交叉分析法 - MBA智库百科
- 相对静止:统计学原理之描述性统计——开篇
- Distance correlation(距离相关系数)
- 偏好度(TGI)是如何计算的,以及如何理解这个指标?
- 闯红灯倾向和星座(出生月份)是否存相关性?
