论文分享|腾讯音乐天琴实验室两篇论文入选国际会议INTERSPEECH 2022

一年一度的全球语音大会INTERSPEECH 2022论文评选结果已经揭晓,我们的论文I《KaraTuner: Towards end to end natural pitch correction for singing voice in karaoke》和论文II《WideResNet with Joint Representation Learning and Data Augmentation for Cover Song Identification》成功被收录其中,TME 在智能歌声美化领域和翻唱识别领域取得的成果再次得到了全球专业评委的认可。
1、针对K歌场景的端到端修音系统
KaraTuner: Towards end to end natural pitch correction for singing voice in karaoke
作者: Xiaobin Zhuang, Huiran Yu, Weifeng Zhao, Tao Jiang, Peng Hu
主要创新点 :智能修音系统通常包括几个阶段:基音提取、偏差估计、基频偏移处理和交叉淡入平滑。经典的基于规则的修音策略不但需要有音乐领域的专业知识,而且设计的规则很难涵盖绝大部分的修音情况,会造成在某些情况下修出怪音的问题。在本文中,我们提出了首个基于曲谱的端到端修音方案KaraTuner,先在曲谱的指导下预测出修正后的音高曲线,然后结合从原始录音中提取的频谱包络,通过基频可控的歌声声码器重新合成歌唱声音,实现自动修音。KaraTuner中引入了几个关键技术点,以确保音高精度、音高自然度、音色一致性和音质。在基频预测器中,采用了基于Transformer的前馈网络来捕获频谱包络和音符的相关性,同时也设计了一种基于源-滤波器模块和Fre-GAN结构相结合的基频可控歌声声码器,确保修音后的音质。KaraTuner通过A/B测试获得了比基于规则的基频校正方法更高的偏好,感知实验也表明,与传统World声码器、Phase Vocoder以及神经网络声码器CLPCNet相比 ,KaraTuner在音色一致性和音质方面具有显著优势。
论文方法
1)在修音任务中,几乎不存在来自同一个非专业用户的的修音前后的数据,这也为设计端到端修音系统增加了难度。本文的新颖之处在于我们使用HMM平滑对跑调的人声提取标准 MIDI 音符序列作为训练数据中的参考模板。在训练阶段,我们从跑调的参考音符模板学习生成用户跑调的音高曲线。在推理阶段,我们使用准确的参考音符模板替换跑调的音符模板。通过这种方法,我们构建了一个大型的数据集,无需手动标记完成音高预测任务。在实验中也发现,频谱包络特征仍然隐含地包含音高曲线的信息,因此将频谱包络和参考音符结合进行基频预测,不但可以确保音调修正,还能保留原始歌声中的更多的基频曲线细节。
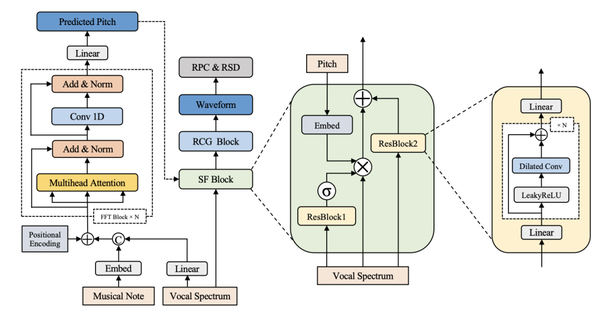
2)源-滤波器 (SF) 模块的输入是音高曲线和频谱包络。在训练阶段,真实音高直接接入SF块,而在推理阶段,预测音高通过嵌入层并与频谱包络生成周期性分量,频谱包络也通过 ResBlock2 预测非周期分量。一种简单的组合方式是将周期性分量和非周期性分量直接等比例相加,但是我们发现每帧信号通过可学习的权重参数来控制混合比例,可以显著提高合成音频的音质,减少频谱缺陷。因此,每一帧信号r可以隐式表示为:
r = σ(f1(sp)) ⊗ emb(pitch) ⊗ sp + f2(sp)
在生成器中,采用 HiFi-GAN 中提出的多感受野融合 (MRF) 模块和 Fre-GAN 中的两个鉴别器,并调整了部分参数,将音频采样率提升到32kHz。整体的模型结构如图所示:
实验分析
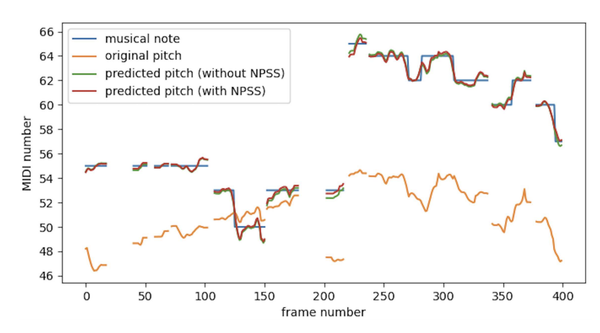
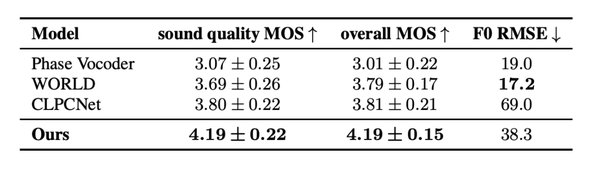
我们收集了 5294 首不同演唱水平的业余用户的歌唱数据,平均每首歌4.3分钟。在效果评估方面,我们先对音高自然度、坏点数进行了A/B测试。在测试集上,KaraTuner相比于基于规则的方法有更好的自然度。我们也把Phase Vocoder、WORLD 声码器和 CLPCNet 作为基线系统,对音色一致性、音频质量和整体质量进行MOS分评估,打分结果也表明KaraTuner在音质和整体质量上都取得了最高的 MOS 分数。而在实验中我们也发现了,DSP 声码器比神经网络声码器对音高的还原能力更强,且对于低音质的音频鲁棒性更强,这也是KaraTuner后续可以结合改进一个方向。
☞demo: https:// ella-granger.github.io/ KaraTuner/
☞arxiv链接: https:// arxiv.org/abs/2110.0912 1
功能体验
欢迎进入全民K歌体验歌声美化之「智能修音」

2、翻唱识别(CSI)
WideResNet with Joint Representation Learning and Data Augmentation for Cover Song Identification
作者: Shichao Hu, Bin Zhang, Jinhong Lu, Yiliang Jiang, Wucheng Wang, Lingcheng Kong, Weifeng Zhao and Tao Jiang
背景
歌曲翻唱往往基于一首原唱歌曲进行不同程度的改编或者由不一样的声音来进行演绎。这造成翻唱歌曲和原唱歌曲在节奏,旋律,乐器,风格等各种维度的差异,从而产生不可计数的变化,给翻唱识别任务带来严峻的挑战。短视频的狂野生长,带动互联网又一片春天。但往往事物都是一把双刃刀,有好的也有坏的。短视频一边给音乐人带来了热度或者爆红的希望,但同时也有部分创作者不合法/不合规利用对歌曲进行翻唱改编,给歌曲公司带来麻烦。
论文方法
数据增强
- 对歌曲进行不同长度的截取
- 对数据特征时间维度以及特征维度进行随机遮掩
模型架构
- 基于WideResNet构建多维表征学习,提出 LayraC-Net
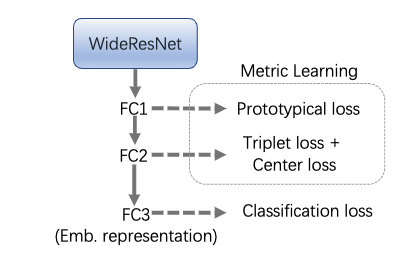
- 对不同全连接层的表征进行不一样的学习目标
- PN loss
- Triplet + Center Loss
- Softmax Loss
- 最终输出的表征有更强的泛化性以及鲁棒性
实验指标
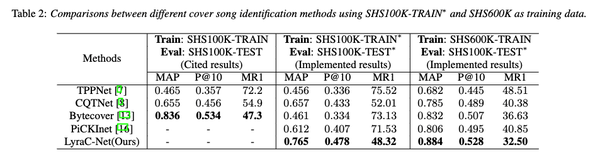
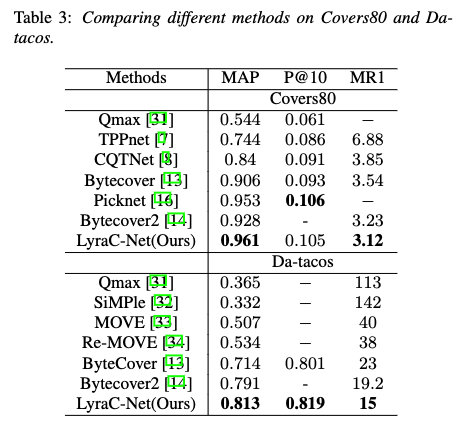
- 基于目前3个业界主流的数据集进行验证,并对多个前SOTA模型进行一一对比。我们模型(LayraC-Net)均达最优,并比较早时间发表于icassp2022的bytecover2(1536维)在表征维度上更低(1024维),同时指标上也取得了一定的突破。
业务场景展望
- 可对库内的原唱和翻唱歌曲进行更好归纳整理
- 歌曲推荐多样性
- 听歌识曲
3、线上片段翻唱
听歌识曲通过严格的指纹匹配,对于未入库的翻唱作品,未必能通过指纹匹配找到,片段翻唱识别通过片段建库、相似度匹配的方式,能够帮助听歌识曲识别出原曲。下图是听歌识曲没有返回结果的情况下,「翻唱识别」返回结果: