


AI“末世论”的逻辑到Alignment Research

研究一个行为,可以分为几个层次: 描述,解释,预测,控制。
对于大模型,我们处于哪个层次?
补充一个Geoffrey Hinton最新的访谈。我猜他应该同意下文里AI Doomer的大部分假设,而且他还给出了一些新的担忧。比如,在下文的假设里面并没有考虑AI被“恶意使用”的情况。
从ChatGPT亮相开始,除了分析模型和应用场景,研究如何优化AI系统对其进行加速之外,我也做了一些延伸思考。关于AI未来的讨论中,AI的风险,特别是所谓x-risk(The existential risk)自然是一个热门的问题。对此,AI末世论者的观点是:“AGI可能给人类带来毁灭性的灾难”。
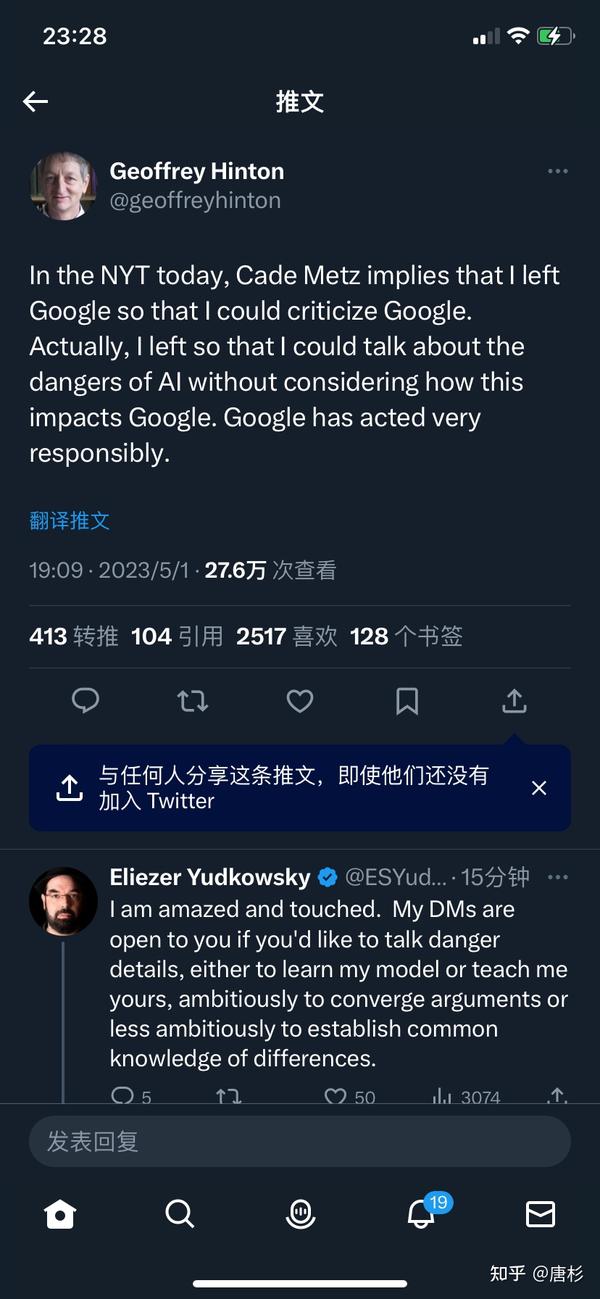

上周看到Hinton从Google离职的消息,而他的推文也提到“ talk about the dangers of AI ”。在评论区里,果然看到了Eliezer Yudkowsky的“讨论邀约”。Eliezer Yudkowsky是AI末世论者的代表人物。如果你搜索“AI Doomer”,很可能会看到这样一幅图,正是把Yudkowsky作为调侃的对象。


虽然Eliezer Yudkowsky有一些比较“刺耳”的言论,但我觉得对他的“扣帽子”攻击也是不公平的。最近Lex Fridman对Eliezer Yudkowsky有个 3个多小时的访谈 [1],大家可以看看(当然 Sam Altman的访谈 [2]也非常值得一看),相信会对他的观点有更清晰的了解。


回到正题,这里主要是看看Eliezer Yudkowsky的“AGI x-risk”的论点,以便大家能够比较客观的进行讨论。以下是对他的论点的总结,来自Sarah Constantin的文章“ Why I am Not An AI Doomer ”[3](应该是比较准确的)。
1.Artificial general intelligence is possible in principle.
There is a property, which we can call intelligence, which humans have, which allows us vastly more power to shape the world than any other organism. It is possible in principle for a machine to have this property, to a degree exceeding our own. Thus, it is in principle possible for machines to be generally smarter and more powerful than people.
2.Artificial general intelligence, by default, kills us all.
If humanity creates an AGI, in most possible cases it will be an alien mind, not a human-like or animal-like mind. By default it will place no value on human life; by default it will prioritize some goal and pursue it relentlessly; in the vast majority of possible cases, that goal will not happen to be compatible with the survival of our species. Just as humans have caused many nonhuman species to go extinct as a side effect of our industrial activities, an agent that doesn’t explicitly value our survival will be likely to wipe us out.
3.It is technically difficult, and perhaps impossible, to ensure an AI values human life.
We have not even begun to develop the theory or technical capacity to get AIs to have any coherent values or goals “in the world”. We have no good way to ensure that a computer program even knows what a human is across contexts, so we can’t possibly “program” it to “value human life”.
4.Current machine learning developments are progressing rapidly towards an AGI.
Current progress in machine learning performance indicates substantial steps towards the kind of “intelligence” that drastically reshapes the world in pursuit of goals (and is therefore an existential threat.)
上述Sarah Constantin文章也非常值得一读。简单来说,Sarah Constantin自己的观点是“ My position is that claims 1, 2, and 3 are true, and 4 is false. ”
也就是说,她同意前三个论点:“ 1. 通用人工智能在原则上是可能的;2. 默认情况下,通用人工智能会杀死我们所有人。3.在技术上,确保人工智能重视人类生命是非常困难的,也许是不可能的。 ”唯一不同意的是第四点:“ 4. 当前的机器学习正在朝着 AGI 快速发展。 ” Sarah Constantin的主要论据是,x-risk AGI需要的能力,除了一个更健壮的世界模型(world model)(目前的LLM的增强版本)之外,还必须有一个因果模型( causal model )和以及跨本体的目标鲁棒性( goal robustness across ontologies ,简单说就是通过复杂行为实现一个“大目标”的能力);而这些能力在目前的模型里还没有看到迹象。“ I’m confident they won’t be developed in the 2020s, and maybe not in the 2030’s either. ” 从另一个角度来看她的说法,2040年x-risk AGI就可能出现了,这好像也不是很乐观啊。
对于她的观点(AI不可能发展那么快),Lesswrong网站上的文章“ On AutoGPT ”[4]给出了不同的看法。其主要论点是: AutoGPT [5]和 Generative Agents [6]这样的工作让LLM Agent化,从“光说不练”到可以按照一个目标来执行操作,会大大加速大模型进化的过程,文章甚至给出了对未来可能发生的情况的预判,不确定的是。如果Eliezer Yudkowsky的这四个假设都成立,那么AI Doom似乎是必然的结果。但我相信各位读者对此都会有自己的看法(也许后续可以搞个投票)。比如,我看到对于第2点,反对意见和延申讨论就非常多。
AI Doomer的理论很早就有,可以说是一直伴随着AI的发展。但在今天,由于我们每个人都在亲身经历AI能力的跳跃和快速发展,对于AI安全性的讨论更具现实意义。这不仅仅是个科学和技术问题,也涉及哲学,心理学,社会学和其它很多内容。因此,对这个问题的思考和讨论的过程可以让我们从不同角度更好的认识AI,为未来的发展做好准备。
乐观来看,目前我们面对的大模型还不是super intelligence(如果不是故意装傻的话 ;-) )。我们还可以通过更多的应用,实践,观察,以及sandbox实验来进行研究和积累经验,从而“ make artificial general intelligence (AGI) aligned with human values and follow human intent ”(OpenAI, " Our approach to alignment research "[7])。如果我们无法对大模型进行准确的 解释 , 预测 ,和 控制 (Openai对于GPT-4的改进是一种“控制”,但更多的是实践上的而非原理上的),就始终无法摆脱AI Doom的阴影。
- The End -
推荐阅读
[1] "Eliezer Yudkowsky: Dangers of AI and the End of Human Civilization | Lex Fridman Podcast #368", https:// youtu.be/AaTRHFaaPG8
[2] "Sam Altman: OpenAI CEO on GPT-4, ChatGPT, and the Future of AI | Lex Fridman Podcast #367", https:// youtu.be/L_Guz73e6fw
[3] Sarah Constantin, "Why I am Not An AI Doomer", https:// sarahconstantin.substack.com /p/why-i-am-not-an-ai-doomer
[4] Zvi, "On AutoGPT", https://www. lesswrong.com/posts/566 kBoPi76t8KAkoD/on-autogpt
[5] "Auto-GPT: An Autonomous GPT-4 Experiment", https:// github.com/Significant- Gravitas/Auto-GPT
[6] Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, Michael S. Bernstein, "Generative Agents: Interactive Simulacra of Human Behavior", https:// arxiv.org/abs/2304.0344 2
[7] OpenAI, "Our approach to alignment research", https:// openai.com/blog/our-app roach-to-alignment-research
本文为个人兴趣之作,仅代表本人观点,与就职单位无关
