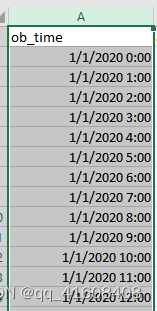
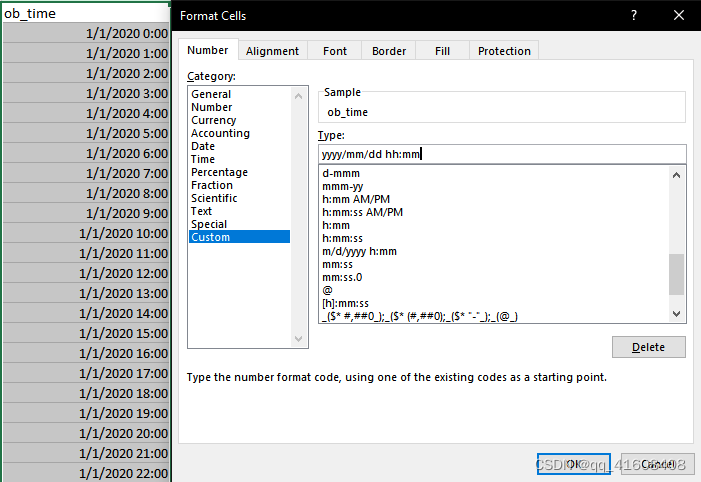
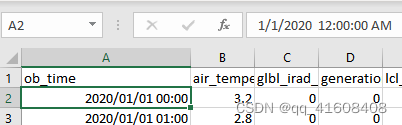
修改成功,但是我想打开excel修改个别数据的时候发现日期格式又变回原来的%m/%d/%Y。一阵冲浪后发现,excel自动会把日期的变量转换为windows默认日期格式,就是windows右下角的日期格式。
所以,即使数据只有 ‘10:00 AM’,windows也会自动补齐年月日,变成1/0/1900 10:00:00 AM。
Excel中将对应单元格
修改成文本
格式后,输入2020-1-1,可以正确显示,但是将此
文件存为
CSV文件之后,在重新打开
CSV文件,他娘的怪事发生了,它自动变回了
日期格式2020/1/1。太离奇了。
经过探索找到了解决方案,这一问题和电脑系统的
日期设置
格式有关,将电脑的
日期格式设置成yyyy-mm-dd。
完美解决!!!!!
我在.csv文件里,某列写成20151209 12:13:14.1234567时,用excel打开,总是不能按照预期的显示,经过搜索,发现这样可以按照自己的想法显示出来信息:
在某列的列首,右键,设置单元格格式
然后,可以写成“yyyy/mm/dd aaaa hh:mm:ss.000”的格式,
如果不知道这个格式是什么意思,可以写一个错误的格式,然后点击帮助,就可以查看Windo
问题描述:将
数据读取为byte[]数组之后,其中有的
数据并非笔者并不期望它是
日期格式,但是形式和
日期格式一样,这样写出到
CSV的时候会将其默认转化为
日期斜杠形式。例如:2021-12-22
数据,写到
csv中变成了2021/12/22。这并非笔者期望。
解决办法(并不推荐):读取每个String字符串,在此字符串后面加入"\t",可以避免
CSV的默认转换。
副作用:这样会导致
数据本身被
修改了,加入“\t”本质是
修改了这个字符串。并且产生的
CSV此字段在选择的时候会出现多余的留白。所以并不推荐。
python处理csv文件将字符串格式XXXX年XX月XX日转化为datetime64XXXX-XX-XX格式
python读取csv文件中,某列卫XXXX年XX月XX日,如何将其转化为可以设置为索引的时间格式呢
如图处理之前数据为这样的
data.loc[:, '信息发布时间'] = pd.to_datetime(data.loc[:, '信息发布时间'], format='%Y年%m月%d日', errors='coerce')
data['信息发布时间'] = pd.to_datetime(data
我们可以使用 Python 的 datetime 库来实现。
首先,我们需要从 CSV 文件中读取时间数据,这可以使用 Python 的 csv 库来实现。例如:
import csv
# 读取 CSV 文件中的时间数据
with open('data.csv', 'r') as f:
reader = csv.reader(f)
dates = [row[0] for row ...
假设上述
csv文件保存为”test.
csv”
1.读
文件
如何用
Python像操作
Excel一样提取其中的一列,即一个字段,利用
Python自带的
csv模块,有两种
方法可以实现:
第一种
方法使用reader函数,接收一个可迭代的对象(比如
csv文件),能返回一个生成器,就可以从其中解析出
csv的内容:比如下
读取多个txt
文件并将
文件中某一行的值全部写入
Excel,可以采用以下步骤:
1、首先需要安装
Python的
Excel操作库openpyxl,可以在命令行中输入“pip install openpyxl”进行安装。
2、然后需要确定txt
文件的路径,可以使用
Python的os模块中的
方法,如os.listdir()获取对应
文件夹下的
文件名列表。
3、用
Python中的for循环依次读取每个txt
文件,并获取需要写入到
Excel中的某一行的值,可以使用
Python中的with open()
方法打开
文件,使用readlines()
方法读取
文件中的每一行,最后使用split()
方法或正则表达式提取需要的行
数据。
4、使用openpyxl操作
Excel,首先需要打开或创建一个
Excel文件和一个工作簿(Workbook),然后使用Active
方法获取具体的工作表(Worksheet),并根据读取的txt
文件行
数据在
Excel中对应的行进行
数据写入,可以使用
Python的for循环和Worksheet.cell(row,column,value)
方法进行写入。
5、最后需要保存
修改后的
Excel文件,可以使用
Python中的Workbook.save()
方法保存
文件。
总之,
Python读取多个txt
文件,并将
文件中某一行的值全部写入
Excel的实现,需要结合
Python的
文件操作、正则表达式和
Excel操作等内容,通过掌握对应的
Python库和
方法,应该可以完成较为简单的
CSV或TXT
数据的读取和导入工作。
### 回答2:
Python可以通过多种方式读取多个txt
文件,并将
文件中某一行的值全部写入
Excel。其中比较常见的方式是使用xlwt和xlrd库,这两个库可以分别用于
Excel的写入和读取。
以下是一种通用的
Python脚本,可以读取指定目录下所有txt
文件,将
文件中某一行的值全部写入
Excel的同一列中:
```
python
import os
import xlwt
import xlrd
# 设置txt
文件路径和
Excel文件路径
txt_path = "txt_files"
excel_path = "output.xls"
# 创建
Excel文件,并设置第一行标题
wb = xlwt.Workbook()
ws = wb.add_sheet("Sheet1")
headers = ["
文件名", "指定行内容"]
for i, header in enumerate(headers):
ws.write(0, i, header)
# 获取txt
文件列表,并遍历每个
文件
files = os.listdir(txt_path)
row = 1 # 从第二行开始写入
数据
for file in files:
if file.endswith(".txt"):
# 读取txt
文件中指定行的内容
with open(os.path.join(txt_path, file), "r") as f:
lines = f.readlines()
content = lines[1].strip() # 假设需要获取第二行的内容
# 将
文件名和指定行的内容写入
Excel中
ws.write(row, 0, file)
ws.write(row, 1, content)
row += 1
# 保存
Excel文件
wb.save(
excel_path)
print("
数据已写入
Excel文件")
在以上脚本中,首先需要指定txt
文件和
Excel文件的路径。然后使用xlwt库创建一个
Excel文件,并设置第一行标题。接着通过os库获取txt
文件列表,并逐个打开
文件,读取指定行的内容。最后将
文件名和指定行内容写入
Excel中,并保存
Excel文件。
需要注意的是,为了让以上脚本能正常运行,需要先安装xlwt、xlrd和os三个库。可以使用pip命令进行安装,如下所示:
pip install xlwt
pip install xlrd
pip install os
以上是一种
Python读取多个txt
文件,并将
文件中某一行的值全部写入
Excel的基本
方法。如果需要更加复杂的操作,可以根据具体需求进行调整。
### 回答3:
Python作为一种高级编程语言,拥有强大的文本处理能力,可以轻松读取多个txt
文件,并将
文件中某一行的值全部写入
Excel表格中。
首先,我们需要导入
Python中的相关模块,包括os和xlwt,代码如下:
```
Python
import os
import xlwt
其中,os模块是
Python中专门用于
文件和目录操作的模块,而xlwt则是
Python中用于创建和写入
Excel文件的模块。
接下来,我们需要设置读取的txt
文件夹路径和要查询的行数,代码如下:
```
Python
path = './txt' # txt
文件夹路径
row_num = 2 # 要查询的行数,以第2行为例
这
里,我们设置了txt
文件夹路径为'./txt',即当前
文件夹下的txt
文件夹。同时,我们也设置了要查询的行数为2,即第2行的
数据。
接下来,我们需要遍历txt
文件夹下的所有
文件,并在每个
文件中读取指定行数的
数据,代码如下:
```
Python
book = xlwt.Workbook() # 创建一个
Excel工作簿
sheet1 = book.add_sheet('sheet1', cell_overwrite_ok=True) # 在工作簿中创建sheet1
row_count = 0 # 工作表行数
# 遍历txt
文件夹下的所有
文件
for root, dirs, files in os.walk(path):
for file in files:
if file.endswith('.txt'): # 判断是否为txt
文件
file_path = os.path.join(root, file) # 获取
文件完整路径
with open(file_path, 'r', encoding='utf-8') as f:
lines = f.readlines() # 读取
文件所有行
row_data = lines[row_num - 1] # 获取指定行
数据
# 写入
Excel表格中
for col, data in enumerate(row_data.strip().split('\t')):
sheet1.write(row_count, col, data)
row_count += 1 # 工作表行数加1
在代码中,我们先创建了一个
Excel工作簿,并在其中创建了一个名为sheet1的工作表。然后,我们使用os.walk()函数遍历txt
文件夹下的所有
文件,对于每个以'.txt'结尾的
文件,我们获取其完整路径,并使用open()函数打开
文件并读取其所有行。接着,我们使用readlines()函数读取指定行数的
数据,将其按照'\t'分割,并将
数据依次写入
Excel表格中。
最后,我们需要将
Excel文件保存到本地,代码如下:
```
Python
book.save('data.xls') # 保存
Excel文件
完整代码如下:
```
Python
import os
import xlwt
path = './txt' # txt
文件夹路径
row_num = 2 # 要查询的行数,以第2行为例
book = xlwt.Workbook() # 创建一个
Excel工作簿
sheet1 = book.add_sheet('sheet1', cell_overwrite_ok=True) # 在工作簿中创建sheet1
row_count = 0 # 工作表行数
# 遍历txt
文件夹下的所有
文件
for root, dirs, files in os.walk(path):
for file in files:
if file.endswith('.txt'): # 判断是否为txt
文件
file_path = os.path.join(root, file) # 获取
文件完整路径
with open(file_path, 'r', encoding='utf-8') as f:
lines = f.readlines() # 读取
文件所有行
row_data = lines[row_num - 1] # 获取指定行
数据
# 写入
Excel表格中
for col, data in enumerate(row_data.strip().split('\t')):
sheet1.write(row_count, col, data)
row_count += 1 # 工作表行数加1
book.save('data.xls') # 保存
Excel文件
这段代码可实现读取多个txt
文件,并将
文件中某一行的值全部写入
Excel表格中,并将
Excel文件保存到本地。如果有需要,还可以进一步优化代码的结构和性能。