


基于Python的“轮子” | 依赖库与工具(一)

显然,车轮子是圆形的,这是大家公认的,最合适的形状。而你非要发明另一种形状的轮子,这种行为就叫「重复发明轮子(Reinventing the wheel)」,即「造轮子」—— 明知道你做的不可能比前辈做得更好 ,却仍然坚持要做。
放到编程中,就是说 业界已经有公认的软件或者库 了,你明知道自己不可能比它做得更好,却还坚持要做。作为练习,造轮子可以增加自己的经验,很多事情看起来简单,但只有自己动手,才会发现其中的难点。
tqdm | 进度条 | Python | Alive Progress、Progress PySimpleGUI
进度条是流程完成所需时间的直观表示。它们使您不必担心进程是否挂起或尝试预测代码的运行情况。您可以直观地实时看到脚本的进展情况!
如果您以前从未考虑过或使用过进度条,则很容易假设它们会给您的代码增加不必要的复杂性,并且难以维护。事实与事实相去甚远。在tqdm中,仅几行代码就可以在我们的命令行脚本以及中添加进度条。
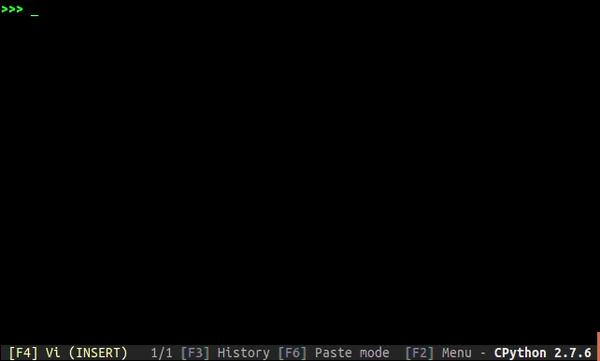
from tqdm import tqdm
for i in tqdm(range(10000)):
...
代码以及官方文档托管在GitHub上:
tqdm与多线程结合使用示例代码:
import time
from tqdm import tqdm
from multiprocessing.pool import ThreadPool
from multiprocessing.pool import Pool
def fun():
"""测试函数"""
time.sleep(0.01)
num = 1000
pbar = tqdm(total=num)
update = lambda *args: pbar.update()
if __name__ == '__main__':
pool = ThreadPool(4)
# pool = Pool(4)
for i in range(num):
pool.apply_async(fun, callback=update)
pool.close()
pool.join()在导航栏备注中还有其他3个进度条库,推荐依次递减,重要的依据是GitHub的Star数以及根据维护频率。
Streamlit | Web应用 | Python | dash、PyWebIO
Streamlit是一个开源Python库,可轻松构建用于机器学习的漂亮应用程序。
安装Streamlit,将其导入,编写一些代码,然后运行脚本。Streamlit会监视每次保存和更新的更改,并在编码时可视化您的输出。代码从上到下运行,始终从干净状态开始,不需要回调。这是一个简单而强大的应用程序模型,可让您快速构建丰富的UI。
将您的数据应用程序转换为 Web 应用程序很容易成为一个难题。如果您主要关注数据科学、机器学习和深度学习,那么您可能不想花时间学习 Web 框架来构建和部署数据应用程序。
有很多库可用于构建数据应用程序,但Streamlit却是一个很好的选择,原因在于:
- 无需前端经验
- 用你已经知道的东西写一切 -- Python
- 与滑块等小部件交互时易于布局
- 快速且易于部署
- 与大多数数据科学框架兼容
其中:无需前端经验
如果你要建立一个使用Flask和Django框架的数据应用,前端工具(比如HTML和CSS以及JavaScript)是一种必须的知识。但是,在 Streamlit 中,所有这些都是使用 Streamlit 小部件完成的。例如,可以使用selectbox小部件轻松实现下拉菜单。其他 HTML 标签(例如输入框和按钮)也可以使用简单的 Streamlit 小部件实现。
其中:Python
在 Streamlit 中构建数据应用程序时,您永远不会离开 Python 编辑器。这是因为它是用 Python 编写的。因此,这是非常有利的,因为您继续使用您已经熟悉的语言工作。如果这是在其他 Python 框架中完成的,那么编写 HTML、CSS 和 Javascript 代码将是不可避免的。
其中:互动性
向 Streamlit 应用程序添加交互非常简单。Streamlit 提供了一些小部件,您可以使用这些小部件将交互性融入到您的应用程序中。例如,可以使用日期输入小部件来过滤他们的数据。也可以使用选择框和滑块来实现相同的效果。
其中:部署
共享 Streamlit 应用程序非常简单。可以轻松部署到 Heroku 和 AWS 之类的平台。但是,您也可以通过单击两个按钮在 Streamlit Sharing 上部署他们的应用程序。您所要做的就是请求访问。然后,您的 Github 电子邮件地址将链接到 Streamlit 共享。完成此操作后,您可以在您的 Github 帐户上部署任何可用的 Streamlit 项目。
其中:兼容性
Streamlit 与最流行的数据科学库兼容。例如,您可以使用您已经习惯的工具在 Streamlit 中执行可视化。支持的可视化库包括:
- Matplotlib
- Seaborn
- Altair
- Plotly
- Bokeh
在可视化结果之前,您肯定需要执行数据清理和整理。支持 Pandas 和 NumPy,以便您可以实现这一点。
在机器学习方面,您可以部署使用您已经习惯的流行库构建的模型。这是因为 Keras、TensorFlow 和 PyTorch 是开箱即用的。
Streamlit Components
如果您需要 Streamlit 不支持的功能,请首先查看 Streamlit 组件页面。Streamlit Components 是由社区构建的第三方功能。这些组件可以通过 pip 安装并立即在您的项目中使用。它的美妙之处在于您还可以编写自己的组件并与社区共享。
我希望我已经说服您开始将 Streamlit 用于您的下一个数据应用程序。
如果您正在寻找灵感和使用方法,作者推荐提供 Data Professor 的 《 Build 12 Data Science Apps with Python and Streamlit - Full Course 》3个小时的教程,教程是英文版的,Youtube上提供翻译功能,替代方案是哔哩哔哩上的翻版,但无翻译,大家自己选择:
Streamlit API 文档
参考文章:
- 有了这个神器,轻松用 Python 写 APP ! Streamlit基本教程中文翻译
- Building Machine Learning Apps with Streamlit
- Streamlit- Deploy a Machine Learning Model without learning any web framework
Streamlit可以称得上神器,但更专注于机器学习和数据科学领域。或许streamlit 应用的编写逻辑还是没有终端程序那么自然,但熟悉之后,编写 Web 服务需要的代码量会很少,另外,streamlit 不支持整合到现有的 Web 服务。
导航栏中的备注中提到的dash和PyWebIO,其实都是推荐的轮子,只因为各有特点,但是Streamlit毕竟Star很多,霸主地位不可撼动。
而dash可以用来编写全功能的 Web 页面,虽然不需要编写 html,需要先声明布局,且布局声明后无法动态改变。dash 采用“响应式”的程序模型,非常依赖回调。如果只是简单写一个小应用,dash 显得太重,需要的代码量也比 PyWebIO 更多。
PyWebIO 能够让你用编写终端程序的逻辑来编写 Web 应用,不需要编写前端页面和后端接口,非常适合在短时间内快速构建对 UI 要求不高的应用(比如自用的 Web 后台、在线小工具等)。PyWebIO 既适合从来没有接触过 Web 开发的程序员来像编写终端程序一样编写 Web 应用,又适合有 Web 开发经验的程序员在自己的 Web 应用中快速实现某些小功能。
关于 PyWebIO 对传统 Web 的优势可以进一步阅读这篇文章: Why PyWebIO 。
代码以及官方文档托管在GitHub上:
numpy-ml |NumPy 手写机器学习模型 | Python
这个项目最大的特点是作者把机器学习模型都用 NumPy 手写了一遍,包括更显式的梯度计算和反向传播过程。可以说它就是一个机器学习框架了,只不过代码可读性会强很多。
David Bourgin 表示他一直在慢慢写或收集不同模型与模块的纯 NumPy 实现,它们跑起来可能没那么快,但是模型的具体过程一定足够直观。每当我们想了解模型 API 背后的实现,却又不想看复杂的框架代码,那么它可以作为快速的参考。
代码以及官方文档托管在GitHub上:
尽管目前使用 NumPy 写模型已经不是主流,但这种方式依然不失为是理解底层架构和深度学习原理的好方法。普林斯顿的博士后 David Bourgin 将 NumPy 实现的所有机器学习模型全部开源,并提供了相应的论文和一些实现的测试效果。
Pyppeteer | 自动化测试| Python | Selenium
Puppeteer是谷歌出品的一款基于Node.js开发的一款工具,主要是用来操纵Chrome浏览器的 API,通过Javascript代码来操纵Chrome浏览器,完成数据爬取、Web程序自动测试等任务。
 10分钟快速上手爬虫之Puppeteer
https://www.zhihu.com/video/1489297202203357184
10分钟快速上手爬虫之Puppeteer
https://www.zhihu.com/video/1489297202203357184
Pyppeteer其实是Puppeteer的Python版本,下面简单介绍下Pyppeteer的两大特点:
chromium浏览器
Chromium是一款独立的浏览器,是Google为发展自家的浏览器Google Chrome而开启的计划,相当于Chrome的实验版,Chromium的稳定性不如Chrome但是功能更加丰富,而且更新速度很快,通常每隔数小时就有新的开发版本发布。Pyppeteer的web自动化是基于chromium来实现的,由于chromium中某些特性的关系,Pyppeteer的安装配置非常简单。
Asyncio框架
asyncio是Python的一个异步协程库,自3.4版本引入的标准库,直接内置了对异步IO的支持,号称是Python最有野心的库。由于Pyppeteer是基于asyncio实现的,所以它本身就支持异步操作,执行效率得到大幅提升。
Example : open web page and take a screenshot.
import asyncio
from pyppeteer import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('http://example.com')
await page.screenshot({'path': 'example.png'})
await browser.close()
asyncio.get_event_loop().run_until_complete(main())代码以及官方文档托管在GitHub上:
如果由于某种原因,你不能正常安装,请对应找到自己的操作系统的网址去下载chromium压缩包。
linux: chrome-linux.zip mac: chrome-mac.zip
win32: chrome-win32.zip win64: chrome-win64.zip
在导航栏备注中提到Selenium是一个用于Web应用程序测试的工具。提起selenium想必大家都不陌生,作为一款知名的Web自动化测试框架,selenium支持多款主流浏览器,提供了功能丰富的API接口,经常被我们用作爬虫工具来使用。但是selenium的缺点也很明显, 比如速度太慢、对版本配置要求严苛,最麻烦是经常要更新对应的驱动。 所以相比较之下,不太推荐。
知晓云 | MBaaS平台 | 支持多语言
知晓云是个好用、顺手的小程序开发工具。它免去了小程序开发中服务器搭建、域名备案、数据接口实现等繁琐流程。让您专注于业务逻辑的实现,使用知晓云开发小程序,门槛更低,效率更高。
「知晓云」是国内第一个专注于微信小程序开发的 MBaaS(后端即服务)服务平台。
只要你有好的想法,只需简单地在小程序中接入知晓云的 JS SDK,不用去管什么 PHP、数据库等后端逻辑,无需管理服务器或编写后端代码,不用担心自己服务器的负载和运维。
官方网站:
官方文档:
Python版标准示例模版:
# python3.6 2019.5.1
# client_id 自己注册后查
# client_secret 自己注册后查
# TABLE_ID 自己注册后查
import json
import requests
from urllib.parse import urlencode
CODE_CONFIG = {
'url': 'https://cloud.minapp.com/api/oauth2/hydrogen/openapi/authorize/',
'headers': {'Content-Type': 'application/json'}
TOKEN_CONFIG = {
'url': 'https://cloud.minapp.com/api/oauth2/access_token/',
'headers': {'Content-Type': 'application/json'}
CODE_DATA = {
'client_id': '*******************',
'client_secret': '*******************'
TOKEN_DATA = {
'client_id': '*******************',
'client_secret': '*******************',
'code': None,
'grant_type': 'authorization_code'
TABLE_ID = '*****'
def get_access_token():
code_response = requests.post(url=CODE_CONFIG['url'], data=json.dumps(CODE_DATA),
headers=CODE_CONFIG['headers'])
# 获取token
TOKEN_DATA['code'] = code_response.json().get('code')
token_response = requests.post(url=TOKEN_CONFIG['url'], data=json.dumps(TOKEN_DATA),
headers=TOKEN_CONFIG['headers'])
return token_response.json().get('access_token')
class Model(object):
def __init__(self):
# 获取code
self.access_token = get_access_token()
def add(self, add_data):
增加数据api
:param add_data: add_data={
"phone": '123456789',
:return:
base_api = 'https://cloud.minapp.com/oserve/v1/table/{0}/record/'.format(TABLE_ID)
headers = {
'Authorization': 'Bearer %s' % self.access_token,
'Content-Type': 'application/json',
'charset': 'utf-8'
response = requests.post(url=base_api, headers=headers, data=json.dumps(add_data))
if response.status_code != 201:
return None
return 'Success'
def delete(self, record_id):
删除数据api
:param record_id: 删除数据的id
:return:
base_api = 'https://cloud.minapp.com/oserve/v1/table/{0}/record/{1}/'.format(TABLE_ID, record_id)
headers = {
'Authorization': 'Bearer %s' % self.access_token,
'Content-Type': 'application/json',
'charset': 'utf-8'
response = requests.delete(url=base_api, headers=headers)
if response.status_code != 204:
return None
return 'Success'
def update(self, record_id, update_data):
更新数据api
:param record_id: 待更新数据id
:param update_data: 更新的数据
:return:
base_api = 'https://cloud.minapp.com/oserve/v1/table/{0}/record/{1}/'.format(TABLE_ID, record_id)
headers = {
'Authorization': 'Bearer %s' % self.access_token,
'Content-Type': 'application/json',
'charset': 'utf-8'
response = requests.put(url=base_api, headers=headers, data=json.dumps(update_data))
if response.status_code != 200:
return None
return 'Success'
def query(self, phone):
查询数据api
:param phone:查询数据字段
:return:
base_api = r'https://cloud.minapp.com/oserve/v1/table/{0}/record/'.format(TABLE_ID)
headers = {
'Authorization': 'Bearer %s' % self.access_token
where_ = {
'account': {'$eq': phone},
query_ = urlencode({
'where': json.dumps(where_),
'order_by': '-created_at',
'limit': 1,
'offset': 0,
account_api = '?'.join((base_api, query_))
account_response = requests.get(account_api, headers=headers)
if account_response.status_code != 200:
return None
return account_response.json().get('objects')
总结一下,如果开发一个小程序或者小型Web产品,并且不太关注数据的持久化存储以及安全,知晓云绝对是无可厚非的助手。知晓云相当于提供了一个云数据库,并且可以是免费的,当然有一定限制,但对于我开发桌面应用级的个人兴趣产品来说,它无疑是给我提供了在线账户管理平台,通过它我可以简单的适配到我的数据管理。
Wget | 下载 | Python
提取数据,尤其是从网络上提取数据,是数据科学家的重要任务之一。Wget是一个免费的实用程序,用于从Web上进行非交互式下载文件。它支持HTTP,HTTPS和FTP协议,以及通过HTTP代理进行检索。由于它是非交互式的,即使用户没有登录也可以在后台运行。因此,下次要下载网站或页面中的所有图像时,wget 将在那里提供帮助。
pip install wgetExample:
>>> import wget
>>> url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3'
>>> filename = wget.download(url)
100% [................................................] 3841532 / 3841532>
>> filename
'razorback.mp3'FuzzyWuzzy | 字符串模糊匹配 | Python
这个名字听起来很奇怪,但是当涉及字符串匹配时,FuzzyWuzzy是一个非常有用的库。它可以轻松实现字符串比较比率,令牌比率等操作。它还可以方便地匹配保存在不同数据库中的记录。
代码以及官方文档托管在GitHub上:
Example:
from fuzzywuzzy import process
choices = ["Atlanta Falcons", "New York Jets", "New York Giants", "Dallas Cowboys"]
process.extract("new york jets", choices, limit=2)
# [('New York Jets', 100), ('New York Giants', 78)]
process.extractOne("cowboys", choices)
# ("Dallas Cowboys", 90)FakeApp | 人脸合成 | 多语言混合
软件简介以及成果示例在 全栈系列 - 爵爷个人应用产品研发发展历史 中 2019/2/23 视频合成 <用FakeApp玩被火速封杀的Deepfake黑科技> 部分已经做了概述。
Deepfake是一种人工智能基础的人物图像合成技术。它用于使用称为“ 生成对抗性网络 ”(GAN)的机器学习技术将现有图像和视频组合并叠加到源图像或视频上。现有视频和源视频的组合产生假视频,该视频显示在现实中从未发生过的事件中执行动作的一个或多个人。
例如,可以用于改变政治家用来使其看起来像那个人说他们从未做过的事情的文字或手势。由于这些功能,Deepfake可能被用来制作虚假的名人色情视频或报复色情内容。Deepfakes也可用于制作假新闻和恶意恶作剧。
其一问世就被钉上了耻辱柱,现在在国内这项技术是被封禁的。但是从科技的角度来看,这应该归属于人类的问题还是技术的无耻这类哲学问题。
使用教程:
1. 安装NVidia CUDA9 ,FakeApp依赖于神经网络,这种网络的训练成本非常高。尽管它们有成本,但训练神经网络的过程是高度可并行的。出于这个原因,大多数机器学习框架(如Keras和TernsorFlow)可以分派在计算GPU。GPU代表 图形处理单元,是机器内部通常处理图形输入的芯片。GPU被设计为并行执行操作,因此它们非常适合训练建立在并行工作的独立神经元上的神经网络。FakeApp使用TensorFlow,一种机器学习框架,支持使用NVIDIA显卡进行GPU加速计算。但是,在使用它之前,您需要安装CUDA®,这是一个将密集计算委派给NVIDIA GPU的并行计算平台。 检查你的显卡。 并非NVIDIA的所有显卡都集成了对GPU计算的支持。您可以检查您的GPU是否兼容访问CUDA GPU列表。任何计算能力大于或等于3.0的图形卡都可以使用。 安装CUDA®Toolkit9.0 , 官网直接去下载。确保为CUDA和操作系统选择正确的版本。在安装过程中,选择“自定义”选项并选择其所有组件。
安装cuDNN, 虽然CUDA®Toolkit提供了GPU计算所需的基本工具集,但它不包括某些特定任务的库。ML-Agents使用强化学习来训练神经网络。因此,您还需要下载CUDA®对深度神经网络的支持,也称为cuDNN。下载cuDNN需要登录。您可以作为NVIDIA开发者免费注册,然后再次访问该网页以访问下载链接。FakeApp适用于cuDNN 7,因此请务必选择正确的版本。 本人Cuda版本:V9.0.176(我是成功实现FakeApp的使用,所以在配置上如果你不能准确配置,请和我的一样) (没有GPU就不要继续下去了,CPU训练太慢了)。
2.安装FakeApp ,尽管仍需要一些配置,但安装FakeApp是最简单的步骤。可以从FakeApp下载页面下载( http://www. fakeapp.org (不用想了,已经是上不去的了。如果想下,自行在网上找办法吧))安装程序。下载版本是 FakeApp2.2.0, 您需要下载两个文件。一个是FakeApp二进制文件的实际安装程序,而另一个名为core.zip,包含它所需的所有依赖项。解压缩后,其所有内容都应合并到C:\Users[USER]\AppData\Local\FakeApp\app-2.2.0\resources\api 文件夹,它应如下所示:
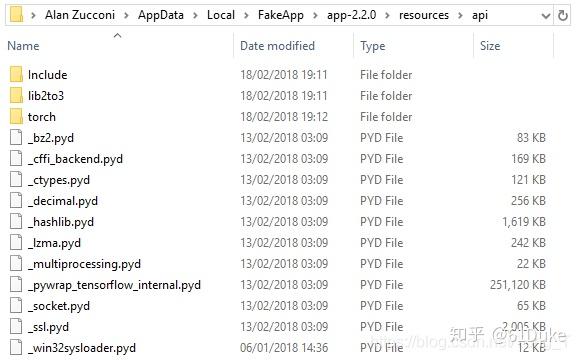
如果一切正常,您现在应该可以使用FakeApp。
3.提取, 为了训练您的模型,FakeApp需要大量的图像数据集。除非您已经选择了数百张图片,否则FakeApp会提供一个便捷功能,可以从视频中提取所有帧。这可以在GET DATASET选项卡中完成。您只需指定mp4视频的链接即可。单击EXTRACT将启动该过程。
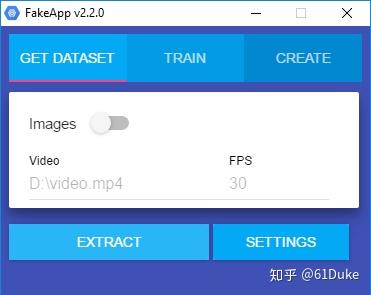
如果您的原始视频名为movie.mp4,则会在名为dataset-video的文件夹中提取这些帧。在里面,会有另一个名为extract的文件夹 ,其中包含准备在训练过程中使用的对齐图像。您可能还会看到一个名为alignments.json的文件,该文件为每个对齐的帧指示其在提取它的图像中的原始位置。提取过程完成后,您唯一需要的是 extract 文件夹; 你可以删除所有其他文件。在继续下一步之前,只需确保对齐的面确实对齐(下图)。面部检测经常失败,因此需要一些手动工作。

理想情况下,您需要的是人A的视频和人B的视频。然后,您需要运行该过程两次,以获得两个文件夹。如果您有同一个人的多个视频,请提取所有这些视频合并文件夹。或者,您可以使用Movie Maker或等效程序依次附加视频。
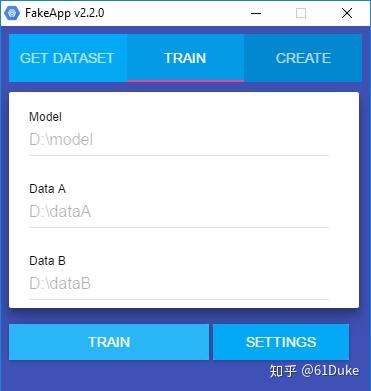
4.训练, 在FakeApp中,您可以从TRAIN选项卡训练您的模型。在数据A和数据B下, 您需要复制解压缩文件夹的路径。按照惯例,数据A是从背景视频中提取的文件夹,数据B包含要插入数据A视频的人物的面部。训练过程将人A的面部转换为人B。实际上,神经网络在两个方向上工作; 你选择哪一个和你选择哪一个并不重要。
您还需要一个模型文件夹。如果这是您第一次从A人训练到B人,您可以使用空文件夹。FakeApp将使用它来存储训练好的神经网络的参数。在开始此过程之前,需要设置训练设置。红色,下面,表示参考培训过程的那些。节点和层 用于配置神经网络; 批量大小用于在更多数量的面上训练它。
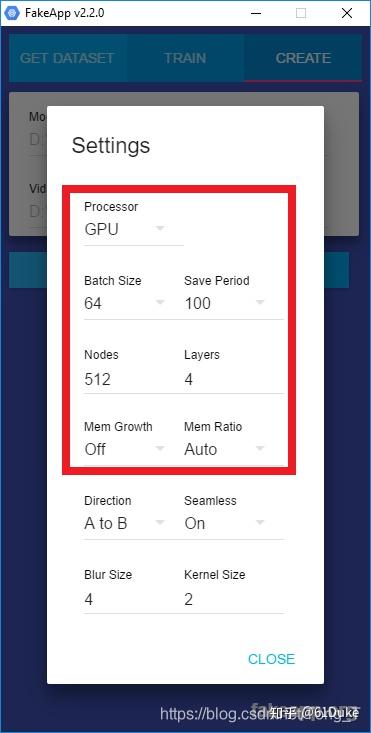
如果您的GPU的RAM少于2GB,那么您可以运行的最高设置可能是:
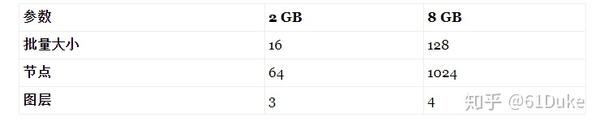
您必须根据GPU上可用的内存量来调整设置。这些是您通常应该运行的推荐设置,尽管这可能因您的型号而异。如果内存不足,则该过程将失败。在训练时,您将看到一个窗口,显示神经网络的执行情况。
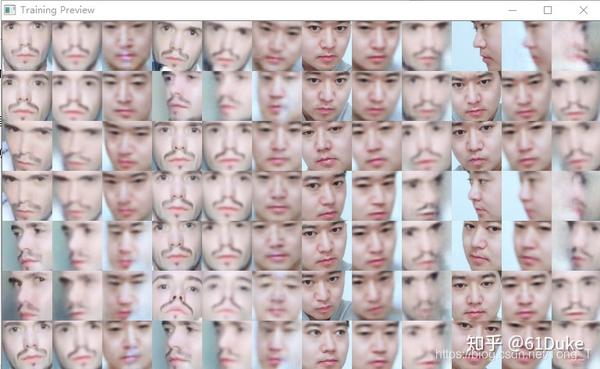
您可以随时按Q停止培训过程。要恢复它,只需使用与模型相同的文件夹再次启动它。FakeApp还显示一个分数,表示在尝试将人A重建为B而人B重建为A时所犯的错误。低于0.02的值通常被认为是可接受的。(至少15个小时以上)
5.创作, 创建视频的过程与GET DATASET中的过程非常相似。您需要提供mp4视频的路径以及模型的文件夹。这是一个包含文件的文件夹:encoder.h5,decoder_A.h5 和decoder_B.h5。您还需要指定目标FPS。
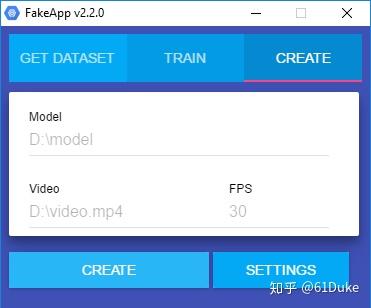
按CREATE将自动:
- 从workdir-video 文件夹中的源视频中提取所有帧。
- 裁剪所有面并在workdir-video / extracted 文件夹中对齐它们,裁剪所有面并在workdir-video / extracted 文件夹中对齐它们。
- 使用训练过的模型处理每个面部,使用训练过的模型处理每个面部。
- 将面合并回原始帧并将它们存储在workdir-video / merged 文件夹中,将面合并回原始帧并将它们存储在workdir-video / merged 文件夹中。
- 加入所有帧以创建最终视频。加入所有帧以创建最终视频。
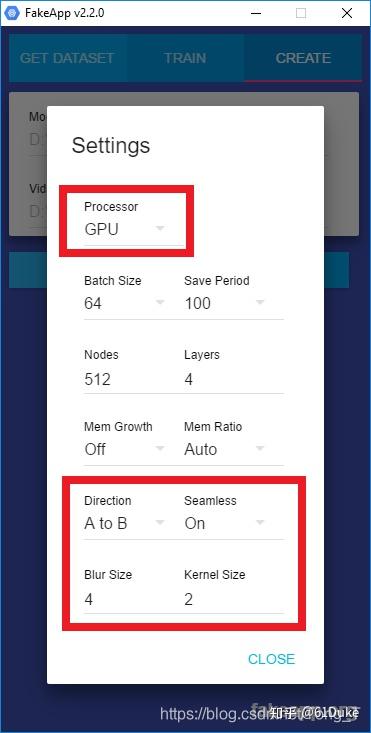
在设置(下方)中,可以选择是否要将人A转换为人B(A至B)或人B转换为人A(B至A)。
natapp
natapp是内网映射牛逼工具,国内高速内网穿透服务。
natapp 基于ngrok的反向代理软件,通过在公网和本地运行的 Web 服务器之间建立一个安全的通道。natapp 可捕获和分析所有通道上的流量,便于后期分析和重放。
官方网站:
Shapely | 计算几何 | Python | geopandas
确定性空间分析是解决农业、生态学、流行病学、社会学和许多其他领域问题的计算方法的重要组成部分。这些动物栖息地的调查周长/面积比是多少?这个镇上的哪些财产与这个新洪水模型中50年一遇的洪水等值线相交?有“A”和“B”标记的古代陶瓷器的范围是多少?范围在哪里重叠?从家到办公室的最佳途径是什么?找出基于位置的垃圾邮件区域?这些只是一些可以通过非统计空间分析解决的问题,更具体地说,是计算几何。
Shapely是一个python包,用于设置平面特征的理论分析和操作(通过python的
ctypes
模块)来自著名和广泛部署的地理类库的功能。GEOS,一个
Java Topology Suite
(JTS)是PostgreSQL RDBMS的PostGIS空间扩展的几何引擎。联合特遣部队和全球测地系统的设计主要受
Open Geospatial Consortium
的简单功能访问规范,并大致依附于同一套标准类和操作。因此,shapely深深植根于地理信息系统(gis)世界的惯例,但也希望对处理非常规问题的程序员同样有用。
Shapely的第一个前提是,Python程序员应该能够在RDBMS之外执行PostGIS类型的几何操作。并非所有地理数据都源自或驻留在RDBMS中,或者最好使用SQL进行处理。我们可以将数据加载到一个空间RDBMS中来完成工作,但是如果没有管理(RDBMS中的“m”)数据库中的数据的授权,那么我们就使用了错误的工具来完成工作。第二个前提是特征的持久性、序列化和映射投影是重要的,但是是正交的问题。你可能不需要一百个地理信息系统格式的读者和作者,也不需要大量的州平面投影,而且形状也不会给你带来负担。第三个前提是Python熟语TrAMP GIS(或Java,在这种情况下,因为GEOS库来自JTS,Java项目)的成语。
如果您喜欢并从惯用的python中获益,那么请欣赏能够很好地完成一件事情的软件包,并同意支持空间的RDBMS通常足以作为计算几何任务的错误工具,而shapely可能适合您。
代码以及官方文档托管在GitHub上:
导航备注中geopandas也是一个挺不错的地理计算库,底层用的就是Shapely。
geopandas是用来处理地理空间数据的python第三方库,它是在pandas的基础上建立的,完美地融合了pandas的数据类型,并且提供了操作地理空间数据的高级接口,使得在python中进行GIS操作变成可能。
如果你几何计算的应用场景是地理坐标,那可以用这个工具。但如果是计算几何相关的,例如作者曾在互联网家装企业工作,处理基础户型图数据、定制衣柜数据的时候,Shapely提供基本的几何操作就很便利。
ezdxf | CAD绘图 | Python | dxfgrabber、dxfwrite pyautocad
作者曾在互联网家装独角兽企业做Machine Learning R&D,一段时间的工作是对户型图研究和实现智能分区以及智能识别,而其中很多数据源是CAD格式的,那就会涉及到基础图形坐标数据的获取和处理问题。
AutoCAD一直是二维绘图软件的霸主,这么些年无人能撼动他的地位,而Autodesk公司一直较为封闭,导致很少有开源的第三方库能很好的支持。而AutoCAD中有一种DXF的文件却可以作为编程突破口进行第三方二次开发,它是AutoCAD作为与其它软件之间进行CAD数据交换的文件格式。
ezdxf 是一个用于创建和修改DXF图纸的Python软件包,与DXF版本无关。您可以打开/保存每个DXF文件,而不会丢失任何内容(注释除外)。DXF文件中的未知标签将被忽略,但会保留下来进行保存。通过这种行为,还可以打开包含来自第三方应用程序的数据的DXF工程图。
ezdxf 是作者研究很长时间发现的对接CAD做的最详细、支持接口最丰富、最新和更新维护较频繁的工具库。文档还算不错,其中支持读写操作,开发项目首选。
代码以及官方文档托管在GitHub上:
该库作者mozman 曾将读/写DXF文件分别写了两个第三方库, dxfgrabber 和 dxfwrite 。
两个都是Python库,可从DXF工程图中获取信息-支持所有DXF版本。Python兼容性: dxfgrabber 已通过CPython 3.6和PyPy进行了测试。该库已经过时了,作者终止了该项目,最后更新时间为2018年1月1日。
代码以及官方文档托管在GitHub上:
导航备注中pyautocad库是作者最先接触到绘制CAD图的开源库,其特点是调用CAD软件进行绘制。但是支持接口太少,速度太慢,不太好用。
代码以及官方文档托管在GitHub上: pyautocad
其功能和方法现今已经没有参考价值了,附上当时刚学习的时候绘制的简单户型图做个纪念:

感谢各位同行者的关注和评论,10W的阅读量和较多的评论让作者倍感感动,砥砺前行;其次,希望大家尊重原创,转载请标注出处。(就这篇文章竟然有人说我是抄袭,无语凝噎)
nmap | 内网映射 | 多语言混合
NMap,也就是Network Mapper,最早是Linux下的网络扫描和嗅探工具包。nmap是一个网络连接端扫描软件,用来扫描网上电脑开放的网络连接端。确定哪些服务运行在哪些连接端,并且推断计算机运行哪个操作系统(这是亦称 fingerprinting)。它是网络管理员必用的软件之一,以及用以评估网络系统安全。
正如大多数被用于网络安全的工具,nmap 也是不少黑客及骇客(又称脚本小子)爱用的工具 。系统管理员可以利用nmap来探测工作环境中未经批准使用的服务器,但是黑客会利用nmap来搜集目标电脑的网络设定,从而计划攻击的方法。Nmap 常被跟评估系统漏洞软件Nessus 混为一谈。Nmap 以隐秘的手法,避开闯入检测系统的监视,并尽可能不影响目标系统的日常操作。Nmap 在黑客帝国(The Matrix)中,连同SSH1的32位元循环冗余校验漏洞,被崔妮蒂用以入侵发电站的能源管理系统。
基本功能有三个:
- 一是探测一组主机是否在线
- 其次是扫描 主机端口,嗅探所提供的网络服务;
- 还可以推断主机所用的操作系统 。
Nmap可用于扫描仅有两个节点的LAN,直至500个节点以上的网络。Nmap 还允许用户定制扫描技巧。通常,一个简单的使用ICMP协议的ping操作可以满足一般需求;也可以深入探测UDP或者TCP端口,直至主机所 使用的操作系统;还可以将所有探测结果记录到各种格式的日志中, 供进一步分析操作。
- 软件下载: nmap
- 代码和文档托管于bitbucket: python-nmap
python-nmap 提供
- ping扫描,支持域名,公网IP地址,IP地址段,批量IP地址。
- A扫描,支持域名,公网IP地址,IP地址段,批量IP地址。
import nmap
def nmap_A_scan(network_prefix):
nmap_host = {}
nm = nmap.PortScanner()
# 配置nmap扫描参数
scan_raw_result = nm.scan(hosts=network_prefix, arguments="-v -n -A")
# 分析扫描结果
for host, result in scan_raw_result["scan"].items():
if result["status"]["state"] == "up":
nmap_host["host"] = host
nmap_host["os"] = []
for idno, os in enumerate(result.get("osmatch", [])):
nmap_host["os"].append({
"id": idno,
"name": os["name"],
"accuracy": os["accuracy"]
nmap_host["tcp_host"] = []
for idno, port in enumerate(result.get("tcp", [])):
nmap_host["tcp_host"].append({
"id": idno,
"port": port,
"state": result["tcp"][port].get("state"),
"reason": result["tcp"][port].get("state"),
"extrainfo": result["tcp"][port].get("extrainfo"),
"name": result["tcp"][port].get("name"),
"version": result["tcp"][port].get("version"),
"product": result["tcp"][port].get("product"),
"cpe": result["tcp"][port].get("cpe"),
"script": result["tcp"][port].get("script")
nmap_host["udp_host"] = []
for idno, port in enumerate(
result.get("udp", [])):
nmap_host["tcp_host"].append({
"id": idno,
"port": port,
"state": result["udp"][port].get("state"),
"reason": result["udp"][port].get("state"),
"extrainfo": result["udp"][port].get("extrainfo"),
"name": result["udp"][port].get("name"),
"version": result["udp"][port].get("version"),
"product": result["udp"][port].get("product"),
"cpe": result["udp"][port].get("cpe"),
"script": result["udp"][port].get("script")
return nmap_host
def nmap_ping_scan(network_prefix):
# 创建一个扫描实例
nm = nmap.PortScanner()
# 配置nmap参数
ping_scan_raw_result = nm.scan(hosts=network_prefix, arguments='-v -n -sn')
# 分析扫描结果,并放入主机清单
hosts = [
result['addresses']['ipv4'] for result in ping_scan_raw_result['scan'].values() if
result['status']['state'] == 'up'
return {
"up": hosts
if __name__ == "__main__":
a_scan_result = nmap_A_scan("www.baidu.com")
print(a_scan_result)
ping_scan_result = nmap_ping_scan("www.baidu.com")
print(ping_scan_result)另外,如果安装配置过程中遇到以下的问题:
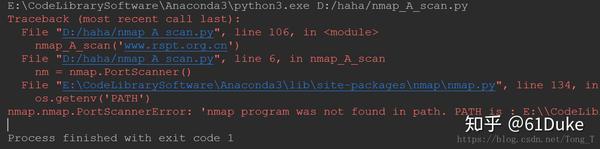
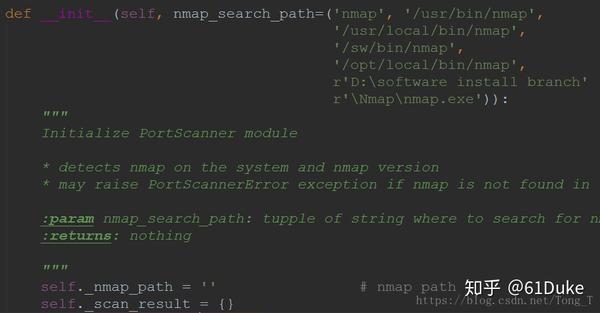
解决方案:打开nmap.py文件,在import nmap处按住Ctrl,点击进入nmap。在 nmap_search_path 中添加nmap.exe路径:
Gooey | GUI | Python | PyQt5、tkinter
GUI是一个人机交互的界面,换句话说,它是人类与计算机交互的一种方法。GUI主要使用窗口,图标和菜单,也可以通过鼠标和键盘进行操作。GUI库包含部件。部件是一系列图形控制元素的集合。在构建GUI程序时,通常使用层叠方式。众多图形控制元素直接叠加起来。
当使用Python编写应用程序时,你就必须使用GUI库来完成。对于Python GUI库,你可以有很多的选择。
之前我用的最多的是 Tkinter ,这个 GUI 库比较灵活,可以做出比较复杂的界面。但是在页面布局和控件使用上比较复杂,想画出一个好看的界面还是要花很多功夫的。
而 Gooey,一行代码就可以快速生成 GUI 应用程序,是作者最推荐的Python 快速GUI实现方案。
安装
:
pip install Gooey
示例:
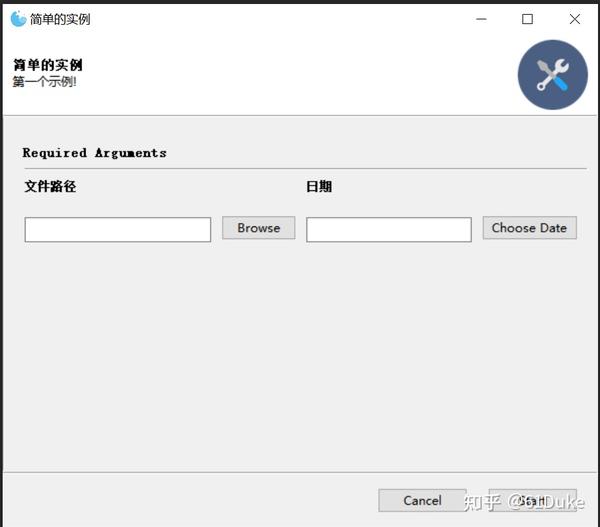
from gooey import Gooey, GooeyParser
@Gooey(program_name="简单的实例")
def main():
parser = GooeyParser(description="第一个示例!")
parser.add_argument('文件路径', widget="FileChooser") # 文件选择框
parser.add_argument('日期', widget="DateChooser") # 日期选择框
args = parser.parse_args() # 接收界面传递的参数
print(args)
if __name__ == '__main__':
main()运行之后的效果如下:
Gooey 的代码和官方文档托管在Github上:
其他的GUI框架:PyQt5和Tkinter
PyQt5是一组来自Digia的Qt5应用程序框架的Python绑定。它适用于Python2和Python3。当然我们会用python3进行讲解。在教程中我们使用的Python3.5.2和PyQt5.3。首推荐。
官方的参考指南: PyQt5指南
中文的参考教程: PyQt5教程
导航备注中还有tkinter,是 Python 的标准 GUI 库。Python 使用 tkinter 可以快速的创建 GUI 应用程序。由于 tkinter 是内置到 python 的安装包中、只要安装好 Python 之后就能 import tkinter 库、而且 IDLE 也是用 tkinter 编写而成、对于简单的图形界面 tkinter 还是能应付自如。整体UI没有PyQt5好看。
参考教程: Python GUI 编程(Tkinter) | 菜鸟教程
Python就不是特别擅长做这种图形界面,还有一些比较炫酷的框架,但一般情况PyQt5都能应付。曾经做的个性签名的小案例,留个纪念:
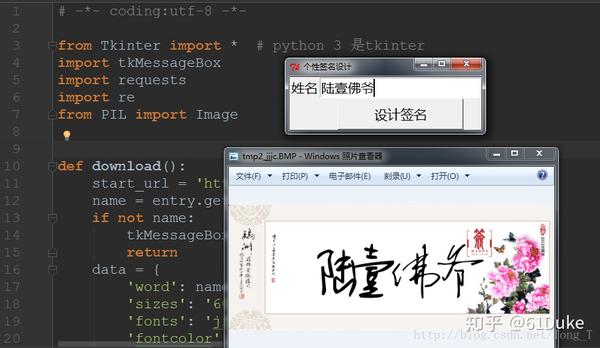
records | MySQL | Python | SQLAlchemy、pymysql
Records(SQL for Humans™)作者与著名Requests库的作者是同一个人-Kenneth Reitz,被称作K神,这就证明了这个库的地位和稳健度。它是一个非常简单但功能强大的库,用于对大多数关系数据库进行原始SQL查询。只需编写SQL。没有钟声,没有哨声。使用可用的标准工具,这一常见任务可能会令人惊讶地困难。该库致力于使此工作流程尽可能简单,同时提供一个优雅的界面来处理您的查询结果。
数据库支持包括 RedShift,Postgres,MySQL,SQLite,Oracle 等。
代码以及官方文档托管在GitHub上:
导航备注栏中还提到传统熟知的SQLAlchemy 和 pymysql,records的内部也是基于这两个库进行深度封装,所以相比较下首推records,但是如果你熟悉使用上面两个,也是推荐的。另外,在Python3中, MySQLdb 已经不能继续使用了,所以这个库就不要考虑了。
SQLAlchemy 是Python 操作数据库的一个库。能够进行ORM映射。SQLAlchemy“采用简单的Python语言,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型”。SQLAlchemy的理念是,SQL数据库的量级和性能重要于对象集合;而对象集合的抽象又重要于表和行。
- pymysql 的代码以及官方文档: PyMySQL
- SQLAlchemy 的代码以及官方文档: sqlalchemy
redis | Redis | Python
redis 是Redis键值存储的Python接口。
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
代码以及官方文档托管在GitHub上:
pymongo | MongoDB | Python
PyMongo发行版包含用于从Python与MongoDB数据库进行交互的工具。该BSON包是的实现 BSON格式 为Python。该pymongo 包是MongoDB的原生Python的驱动程序。该GridFS的包是一个 GridFS的 之上实现pymongo。
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
主要特点:
- MongoDB的提供了一个面向文档存储,操作起来比较简单和容易。
- 你可以在MongoDB记录中设置任何属性的索引 (如:FirstName=”Sameer”,Address=”8 Gandhi Road”)来实现更快的排序。
- 你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
- 如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
- Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
- Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
- Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
- GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
-
MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
PS:自己对MongoDB集合的理解是:集合就是一组文档;文档类似于关系库里的行,集合类似于关系库里的表;集合中的文档无需固定结构(与关系型数据库的区别)
代码以及官方文档托管在GitHub上:
elasticsearch | ElasticSearch | Python
Elasticsearch的官方低级客户端。它的目标是为Python中所有与Elasticsearch相关的代码提供共同点;因此,它试图做到无意见且可扩展。
Elasticsearch(简称ES)是一个基于Apache Lucene(TM)的开源搜索引擎,无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎,无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要发挥其强大的作用,你需使用Java并要将其集成到你的应用中。Lucene非常复杂,你需要深入的了解检索相关知识来理解它是如何工作的。
Elasticsearch也是使用Java编写并使用Lucene来建立索引并实现搜索功能,但是它的目的是通过简单连贯的RESTful API让全文搜索变得简单并隐藏Lucene的复杂性。
不过,Elasticsearch不仅仅是Lucene和全文搜索引擎,它还提供:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 实时分析的分布式搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
而且,所有的这些功能被集成到一台服务器,你的应用可以通过简单的RESTful API、各种语言的客户端甚至命令行与之交互。上手Elasticsearch非常简单,它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。Elasticsearch在Apache 2 license下许可使用,可以免费下载、使用和修改。 随着知识的积累,你可以根据不同的问题领域定制Elasticsearch的高级特性,这一切都是可配置的,并且配置非常灵活。
代码以及官方文档托管在GitHub上:
Elasticsearch提供了一种json风格的查询语言,称为Query DSL(Query domain-specific language)。查询语言功能很全面。某热力图项目中的查询示例代码:
from elasticsearch import Elasticsearch, helpers
es = Elasticsearch(hosts="http://192.168.3.33:9200")
query_json = {
"query": {
"bool": {
"must": [
"prefix": {
"area_code": 44
"range": {
"lng": {
"gte": 20.226494890684076,
"lt": 25.523274722156945
"range": {
"lat": {
"gte": 109.67459750070368,
"lt": 117.32227799461175
"_source": [
"area_code",
"lat",
"lng"
es_result = helpers.scan(
client=es,
query=query_json,
scroll="5m",
index="company_info_1",
size=10000,
preserve_order=False,
raise_on_error=False
for i, item in enumerate(es_result):
print(i, item["_source"])pyinstaller | 应用打包 | Python
在命令行用pip安装 pyinstaller包:
pip install pyinstaller
支持 MAC,Windows, Linux
下载安装pyinstaller运行时所需要的windows扩展pywin32:
选择最新版的下载,注意要选择对应的python版本(version)和python位数(bittedness),通过在命令行输入python查看python版本和位数。
如下所示为python3.6的32位,需要下载
[pywin32-223.win32-py3.6.exe]
Python 3.6.3 ... [MSC v.1900 32 bit (Intel)] on win32
如下所示为python3.6的64位,需要下载
[pywin32-223.win-amd64-py3.6.exe]
Python 3.6.3 ... [MSC v.1900 64 bit (AMD64)] on win32
在命令行中直接输入下面的指令即可:
pyinstaller [opts]
yourprogram.py
参数含义
- -F 指定打包后只生成一个exe格式的文件(建议写上这个参数)
- -D –onedir 创建一个目录,包含exe文件,但会依赖很多文件(默认选项)
- -c –console, –nowindowed 使用控制台,无界面(默认)
- -w –windowed, –noconsole 使用窗口,无控制台
- -p 添加搜索路径,让其找到对应的库。
- -i 改变生成程序的icon图标
比如你有个python程序叫test.py,绝对路径在
[D:\project]
,打包成一个exe格式的文件
pyinstaller -F D:\project\test.py
条件同上,如果还希望没有控制台的黑框框,在进程中偷偷运行
pyinstaller -F -w D:\project\test.py
条件同上,如果还希望更换程序图标
pyinstaller -F -w -i D:\project\test.ico D:\project\test.py
官方文档 :
You-Get | 下载媒体内容 | Python
You-Get 是一个小型的命令行实用程序,用于从Web下载媒体内容(视频,音频,图像),以防没有其他方便的方法。
作者用过很多下载视频的第三方库,没有一个能够比拟You-Get 这个神器的,它支持的视频媒体平台很多,一个工具用遍所有地方。其中音频和图像其实还有 wget 进行推荐,可以自己做选择。
如果你
- 喜欢在互联网上的东西,只是想下载自己的快乐。
- 可以通过计算机在线观看自己喜爱的视频,但不能保存。你觉得你不能控制自己的电脑。(这不是一个开放的网络应该如何工作。)
- 希望摆脱任何封闭源代码技术或专有JavaScript代码,并禁止在您的计算机上运行Flash等操作。
- 你是一个黑客文化和自由软件的坚持。
那就立刻去 You-Get 的代码和官方文档托管仓库:
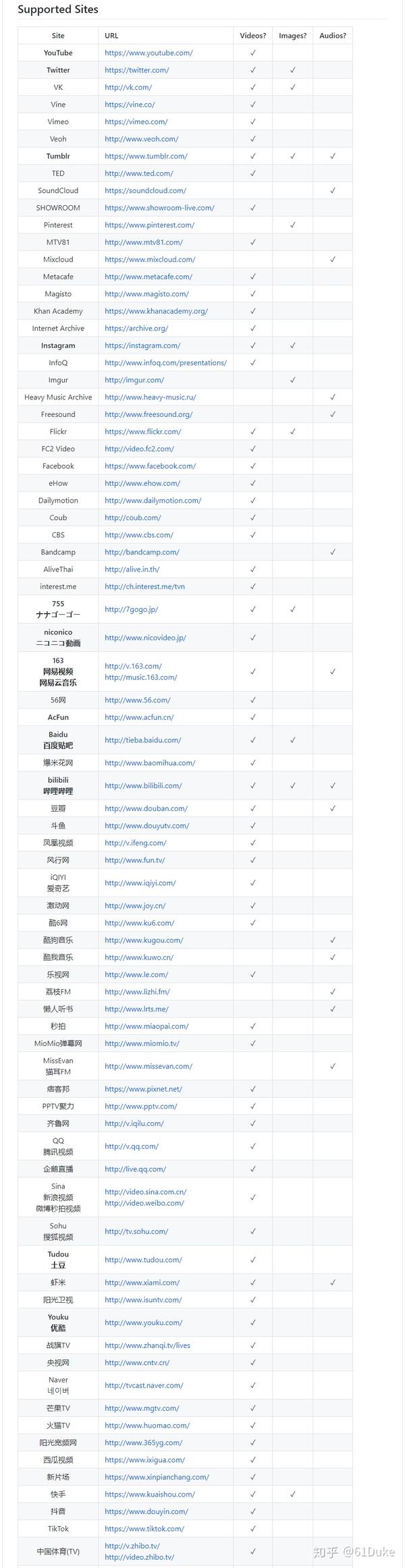
截止2020年12月31日,支持网站列表:
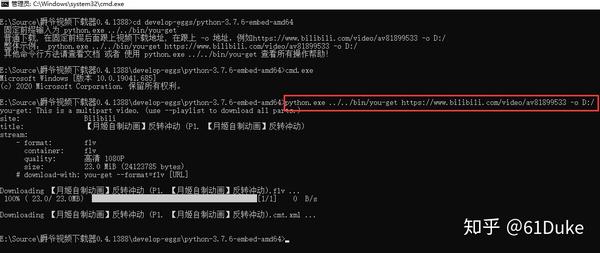
作者用You-Get作为底层,封装了所有资源做了一下Windows的命令行下载器。可以不用配置任何环境,软件包可随意使用。示例如下:
PyPy | Python解释器 | Python
Python是开发人员中最常用的编程语言之一,但它有一定的局限性。例如,对于某些应用程序而言,它的 运行速度可能比其它语言低100倍 。这就是为什么当Python的运行速度成为用户瓶颈后,许多公司会用另一种语言重写他们的应用程序。但是有 没有一种方法既可以保持Python的特性又能提高速度呢?它就是PyPy 。
PyPy是一种非常兼容的Python解释器,它是CPython2.7、3.6和3.7的一种值得替代的方法。在安装和运行应用程序时使用它,可以显著提高速度。速度提高多少取决于你运行的应用程序。官方定义为: PyPy是使用RPython转换工具链的Python中Python的重新实现。
请记住,PyPy如何影响代码的性能取决于您用代码来做什么。在某些情况下,PyPy实际上较慢。但是 ,就几何平均而言,它的速度是Python的4.3倍。
PyPy并非万能,它不是一个适合您所有任务的工具。它甚至可能使应用程序的执行速度比CPython慢得多。这就是为什么您必须记住以下局限性。
- 它不适用于C扩展: PyPy最适合纯Python应用程序。无论何时使用C扩展模块,它的运行速度都要比在CPython中慢得多。原因是PyPy无法优化C扩展模块,因为它们不受完全支持。此外,PyPy必须模拟代码中的引用计数,使其更慢。在这种情况下,PyPy团队建议去掉CPython扩展并将其替换为纯Python版本。如果不行的话,则必须使用CPython。尽管如此,核心团队正在处理C扩展。有些软件包已被移植到PyPy,并且工作速度也同样快。
- 它只适用于长时间运行的程序: 当使用PyPy运行脚本时,它会执行许多操作以使代码运行得更快。如果脚本本身很简单,则实际脚本运行速度会低于CPython。另一方面,如果您有一个长时间运行的脚本,那么可能会带来显著的性能提升。
- 它不执行提前编译: 正如您在本教程开头所看到的,PyPy不是一个完全编译型的Python实现。它编译Python代码,但不是Python代码的编译器。由于Python固有的一些特性,导致无法将Python编译为独立的二进制文件并重用它。PyPy比完全解释型的语言快,但比完全编译的语言(如C)慢。
官方网站(包含文档和下载地址):
作者简单试了一些算法的实现,使用PyPy的确是缩短了2倍的时间。
weasyprint | HTML2PDF | Python | wkhtmltopdf
WeasyPrint是一种智能解决方案,可帮助Web开发人员创建PDF文档。它将简单的HTML页面变成华丽的统计报告,发票,票据...从技术角度来看,WeasyPrint是用于HTML和CSS的可视化呈现引擎,可以 导出为PDF和PNG 。它旨在支持用于打印的Web标准。WeasyPrint是根据BSD许可提供的免费软件。它基于各种库,但 不 基于WebKit或Gecko之类的完整渲染引擎。CSS布局引擎是用Python编写的,专为分页而设计,旨在易于破解。
代码和官方文档托管于GitHub:
作者测试示例代码:
from weasyprint import HTML
# HTML 2 PNG