
Python干货 | 五分钟教你如何破解字体反爬(一)

学习了前边的爬虫知识,大家一定爬取过很多的网站了,也一定被很多网站的各式各样的反爬机制劝退过。那么这些反爬机制如何来破解,大家也一定想破了头。本节课,我们来搞点不同寻常的有深度的事情——破解字体反爬!
大家看目录,发现我把字体反爬分了多个章节,可想而知字体反爬的“困难程度”,但是不要紧,我们会把目前的字体反爬技术一一给大家讲解!
一、扫盲
字体反爬,一种常见的反爬技术,一些网站采用了自定义的字体文件,在字体文件中给需要加密的符号指定一个十六进制编码,这些符号对应的编码被传输到前端,由前端根据字体文件内容解析并显示回正常的字符。
二、字体文件
常见的字体文件包括:
ttf
、
eot
、
woff
、
woff2
等, 我们一般在前端页面中通过
@font-face
定义字体样式(字体样式属于CSS样式)来构建与字体文件的映射,然后再将其设置到元素控件中去,并且我们也能够在前端页面的源代码中找到这些字体文件,但是也并不是所有的字体文件都会出现在前端页面的源代码中,部分网站还会将其放入到 API 接口中等等,那么接下来,我们先来讲解下比较简单的字体反爬——静态字体反爬!
三、实战
第一步:接口数据抓取
我们针对“某某二手车”进行爬虫操作,这是链接: https://www. guazi.com/ ,大家可以在“我要买车”这里随便选择一个品牌,我选择了“大众”。
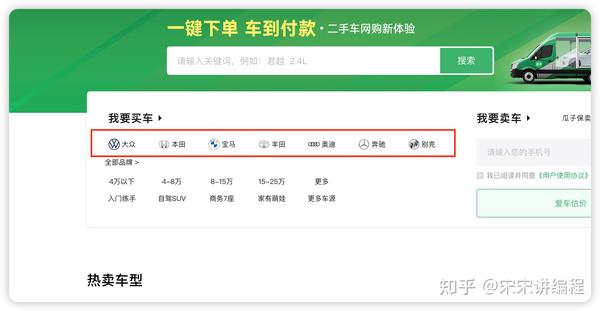
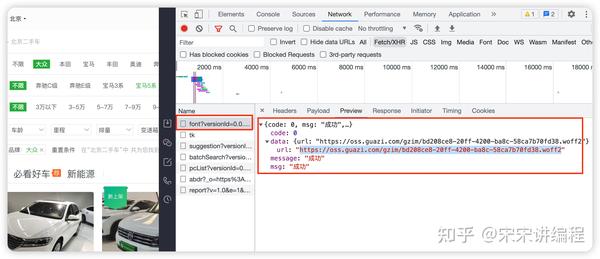
这个二手车网站的数据都是通过 API 接口的形式传输的,所以大家要先找到这个网站的 API 接口,请看下图:
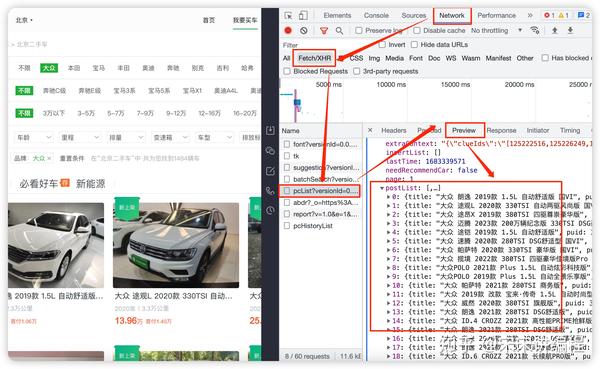
第二步:发现问题
找到这个接口以后呢,我们需要关注一些数据,仔细看,你是能够发现一些问题的:
看我在图中圈中的信息,我们发现有些关键性数据信息居然是加密过后的,这就意味着这个网站采用了字体反爬,那么按照我们的思路,首先就要想到去网页源代码或者 API 接口中找字体文件进行解密。
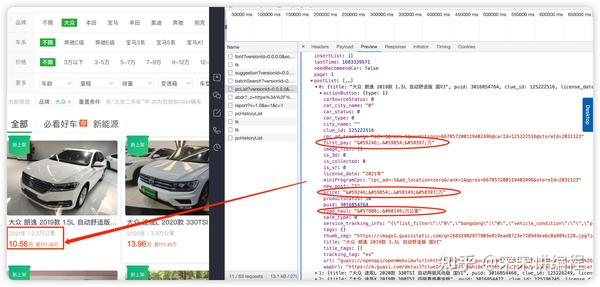
第三步:找字体文件
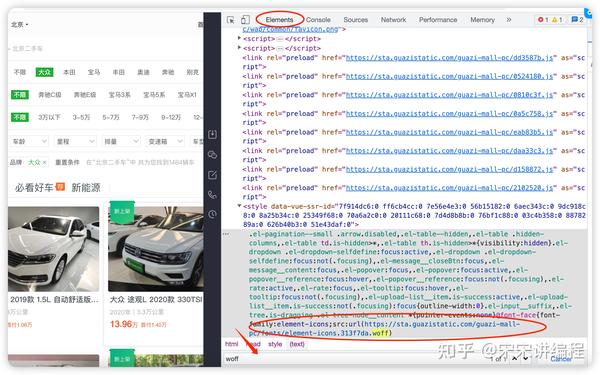
回到开发者工具的 Elements 选项卡中,先用快捷键 Ctrl + F 调出搜索框( Tips:很多工具都可以使用这个快捷键调出搜索框进行关键字检索),输入woff 查看反馈结果(注意,不一定只搜 woff,上面提到过的 ttf、eot 等关键词也可以搜索,不同网站用的字体文件可能不同),我们发现搜到了和 woff 关键字相匹配的一些信息,这个链接可能就是我们需要的,大家可以复制此处的链接(要先双击,再选中这部分内容),用浏览器打开,会下载一个字体文件。
这个字体文件我们先用这个网站打开: https:// kekee000.github.io/font editor/
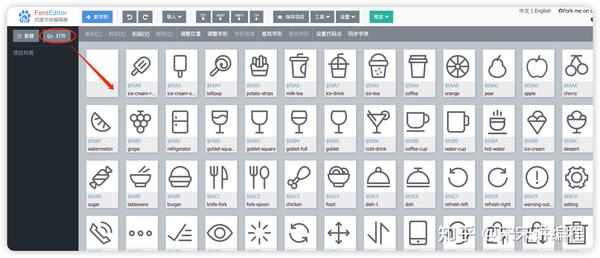
看到上图的内容,基本就宣告这个字体文件找错了,但是别怕,多找找,网页源代码找不到就从 API 接口中再找找。发现从 API 接口中找到一个 woff2 的字体文件,我们下载下来看看,发现是数字,和前面就能联想到了一起了,基本正确无疑了!
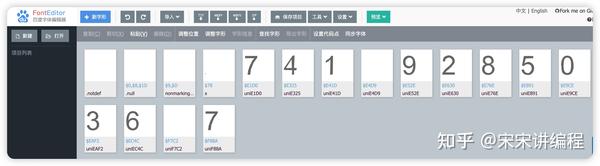
第四步:代码编写
先把接口中需要的数据抓出来。
import requests
# 接口有点长,做个换行处理
API_URL = 'https://mapi.guazi.com/car-source/carList/pcList?' \
'versionId=0.0.0.0&sourceFrom=wap&deviceId=5215c1f1-5b57-4568-9631-d36477f616ad' \
'&osv=IOS&minor=dazhong&sourceType=&ec_buy_car_list_ab=&location_city=&district_id=' \
'&tag=-1&license_date=&auto_type=&driving_type=&gearbox=&road_haul=&air_displacement=' \
'&emission=&car_color=&guobie=&bright_spot_config=&seat=&fuel_type=&order=' \
'&priceRange=0,-1&tag_types=&diff_city=&intention_options=&initialPriceRange=' \
'&monthlyPriceRange=&transfer_num=&car_year=&carid_qigangshu=&carid_jinqixingshi=' \
'&cheliangjibie=&page=1&pageSize=20&city_filter=12&city=12&guazi_city=12&qpres=&platfromSource=wap'
# 发送请求得到响应结果
resp = requests.get(url=API_URL)
# json 数据转字典
data = resp.json()
# 数据提取
car_data = data['data']['postList']
# 二手车概述、车辆时间、里程、首付、总价
car_info = [
[car['title'], car['license_date'], car['road_haul'], car['first_pay'], car['price']] for car in car_data
print(car_info)
然后针对上方打印结果中加密数据,根据上方打开的字体文件构建映射。
# 字体映射
font_dict = {
'uniE9CE': '0', 'uniE41D': '1', 'uniE630': '2', 'uniEAF2': '3',
'uniE325': '4', 'uniE891': '5', 'uniEC4C': '6', 'uniE1D0': '7',
'uniF88A': '7', 'uniE76E': '8', 'uniE52E': '9'
}接下来就是知识积累与经验之谈了,大家在这里记好。看到 unixxxx 这种, uni 代表的就是 Unicode 编码,一般 Unicode 编码是十六进制,所以 unixxxx 还可以写作 0xxxxx,那么我们借助 Python 中的 hex 方法,将十进制转为十六进制检验下。
# 随便找一个加密信息,取其中的数值进行转换:
print(hex(58928))这里打印的结果为:0xe630,发现正好能和映射中的 uniE630 对应,那么只需要使用代码稍加处理,便能够得到二手车的正确信息。
# 将上方字体映射字典中 unicode 编码改为二手车网站的 ‘&#十进制数值;’ 的形式
new_font_dict = {f'&#{int(key[3:], 16)};': value for key, value in font_dict.items()}
# print(new_font_dict)
# 使用字符串的替换操作来一次全局替换
for key, value in new_font_dict.items():
car_info = str(car_info).replace(key, value)
# print(car_info)
经过验证,信息是没有问题的,所以再将 car_info 从字符串转回列表即可。
import ast
print(ast.literal_eval(car_info))有小伙伴可能在 ast 模块这里有疑问,为什么不是用 eval,而是用 ast.literal_eval 呢,这是因为 eval 方法会自动执行恶意指令,如果你的字符串中存在恶意指令,那么恭喜你即将中招。所以我们用更加安全的 ast 模块中的 literal_eval 方法。
这就是本二手车网站的字体反爬的破解方式,你学会了吗!
四、完整代码
在这里提供了最标准的代码。
import requests
import ast
# 接口有点长,做个换行处理
API_URL = 'https://mapi.guazi.com/car-source/carList/pcList?' \
'versionId=0.0.0.0&sourceFrom=wap&deviceId=5215c1f1-5b57-4568-9631-d36477f616ad' \
'&osv=IOS&minor=dazhong&sourceType=&ec_buy_car_list_ab=&location_city=&district_id=' \
'&tag=-1&license_date=&auto_type=&driving_type=&gearbox=&road_haul=&air_displacement=' \
'&emission=&car_color=&guobie=&bright_spot_config=&seat=&fuel_type=&order=' \
'&priceRange=0,-1&tag_types=&diff_city=&intention_options=&initialPriceRange=' \
'&monthlyPriceRange=&transfer_num=&car_year=&carid_qigangshu=&carid_jinqixingshi=' \
'&cheliangjibie=&page=1&pageSize=20&city_filter=12&city=12&guazi_city=12&qpres=&platfromSource=wap'
# 发送请求得到响应结果
resp = requests.get(url=API_URL)
# json 数据转字典
data = resp.json()
# 数据提取
car_data = data['data']['postList']
# 二手车概述、车辆时间、里程、首付、总价
car_info = [
[car['title'], car['license_date'], car['road_haul'], car['first_pay'], car['price']] for car in car_data
print(car_info)
# 字体映射
font_dict = {
'uniE9CE': '0', 'uniE41D': '1', 'uniE630': '2', 'uniEAF2': '3',
'uniE325': '4', 'uniE891': '5', 'uniEC4C': '6', 'uniE1D0': '7',
'uniF88A': '7', 'uniE76E': '8', 'uniE52E': '9'
# 正确信息解析
# 将上方字体映射字典中 unicode 编码改为二手车网站的 ‘&#十进制数值;’ 的形式
new_font_dict = {f'&#{int(key[3:], 16)};': value for key, value in font_dict.items()}
# print(new_font_dict)