Facebook和亚马逊推出全新PyTorch库,针对大型高性能AI模型
刚刚,Facebook联合AWS 宣布了PyTorch的两个重大更新。
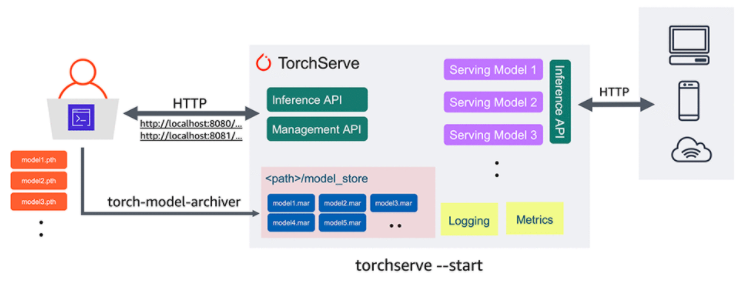
第一个是TorchServe,它是 PyTorch 的一个生产模型服务框架,可以使开发人员更容易地将他们的模型投入生产。
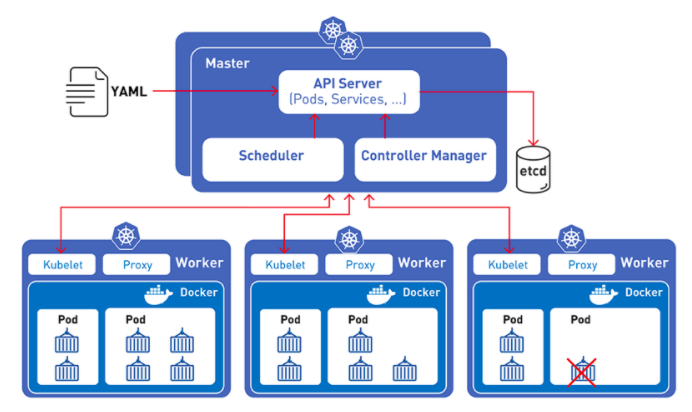
第二个是 TorchElastic,可以让开发人员更容易地在 Kubernetes 集群上构建高容错训练作业,包括 AWS 的 EC2 spot 实例和 Elastic Kubernetes Service。
但是在发布过程中,Facebook官方博客产生了一个小插曲,将文章的发布日期2020年错标称了2019年。
TorchServe剑指何方
最近几年,Facebook 和 AWS都积攒了大量的机器学习工程实践经验,而PyTorch在学术界和开源社区大受追捧。
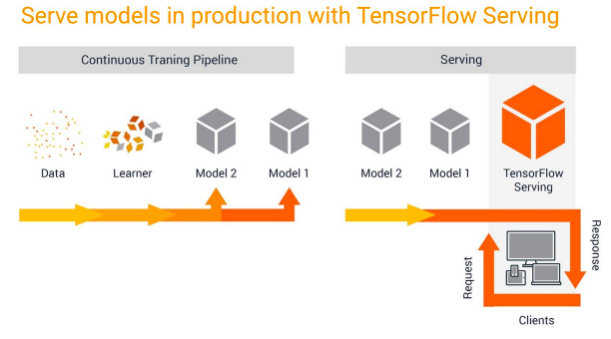
TensorFlow的一个重要优势在于TensorFlow Serving 和 Multi Model Server这些可快速部署到生产环境的模型服务器。
AWS 在 SageMaker 运行自己的模型服务器方面经验丰富,SageMaker模型服务器虽然可以处理多个框架。而PyTorch则拥有十分活跃的社区,更新也频繁。
开发者需要一个自己的模型服务器,要能根据自己的需求方便地进行定制化开发,而AWS也需要推广自己的服务器,于是双方一拍即合,在新版本的PyTorch中开源了TorchServe。
集成Kubernetes,TorchElastic让训练和部署更容易
TorchElastic可以和Kubernetes无缝集成,PyTorch 开发人员可以在多个计算节点上训练机器学习模型,这些计算节点可以动态伸缩,让模型训练更加高效。
TorchElastic 的内置容错能力支持断点续传,允许模型训练出错后继续使用前面的结果。这个组件编写好了分布式 PyTorch作业的接口,开发人员只需要简单的编写接口部分,就能让模型跑在众多分布式节点上,而不需要自己去管理 TorchElastic 节点和服务。
为什么结合Kubernetes如此重要
传统的程序部署的方法是通过操作系统在主机上安装程序。这样做的缺点是,容易造成程序、依赖库、环境配置的混淆。而容器部署基于操作系统级别的虚拟化,而非硬件虚拟化。
容器又小又快,每一个容器镜像都可以打包装载一个程序。Kubernetes 就是来管理容器的,所以PyTorch结合Kubernetes将大大提高模型的训练速度,降低部署难度,而且更好管理模型的整个生命周期。
Google推出DynamicEmbedding,将TensorFlow推向“巨量级”应用
Google比Facebook早几天公布了一个叫做DynamicEmbedding的产品,能够将TensorFlow扩展到具有任意数量特征(如搜索查询)的 "巨量级 "应用,还专门为此发布了一篇论文,在Google为其评估的数十个不同国家的72个重估指标中,DynamicEmbedding驱动的模型赢得了49个指标。
论文地址:
https://arxiv.org/pdf/2004.08366.pdf
论文中Google称,DynamicEmbedding能够通过模型训练技术进行自我进化,能够很好的处理可能会丢弃太多有价值信息的场景。
DynamicEmbedding拥有"不间断地"增长特性,在不到六个月的时间里,从几千兆字节自动增长到几百兆字节,而不需要工程师不断地进行回调。
同时DynamicEmbedding的内存消耗也极少。例如训练Seq2Seq的模型时,在100个TensorFlow worker和297781个词汇量的情况下,它只需要123GB到152GB的RAM,相比之下TensorFlow要达到同样精度至少需要242GB的RAM。
事实上,DynamicEmbedding模型早已经应用在Google的智能广告业务中,为 "海量 "搜索查询所告知的图片进行注释(使用Inception),并将句子翻译成跨语言的广告描述(使用神经机器翻译)。
其上开发的AI模型在两年的时间里取得了显著的准确率提升,截至2020年2月,Google Smart Campaign模型中的参数已经超过1240亿,在20种语言的点击率等指标上,其表现优于非DynamicEmbedding模型
Build过程也很简单,只需要在TensorFlow的Python API中添加一组新的操作,这些操作将符号字符串作为输入,并在运行模型时 "拦截 "上游和下游信号。
再通过一个叫做EmbeddingStore的组件,让DynamicEmbedding和Spanner和Bigtable等外部存储系统集成。数据可以存储在本地缓存和远程可变数据库中。
DynamicEmbedding可以从worker故障中快速恢复,不需要等之前所有的数据加载完毕后才能接受新请求。
两大阵营又开战端,Facebook亚马逊各取所长联手对抗Google
TensorFlow依托于Google这颗大树,占了早期红利,在基数上暂时领先。
但随着越来越多竞争者的加入,TF的老大地位受到了极其严重的威胁,PyTorch大有取而代之的势头。
此前,PyTorch相对TensorFlow最大优势只是一个动态图机制,导致PyTorch能够比TensorFlow调试起来更容易,开发者不需要在编译执行时先生成神经网络的结构,然后再执行相应操作,可以更加方便地将想法转化为代码。
而且,相比TensorFlow,PyTorch的代码风格是更加纯正的Pythonic风味。PyTorch的动态图机制,加上更纯正Pythonic的代码风格,使得PyTorch迅速流行起来。
等到谷歌发掘势头不对,在2017年着急的上了一个支持动态图的TensorFlow Fold,后来发布升级版本Eager Excuation。但TensorFlow长久以来深入骨髓的静态计算,怎么可能短期内就能彻底改变呢?
TensorFlow 2.0不仅对开发者来说学习成本高,甚至不得不为Google自己员工撰写操作指南。
用户都是用脚投票的,不论你是Google还是Facebook,做不做恶,产品好用才是第一位的。而招聘网站上的需求,能够最直观的体现企业的态度。
数据来源:
https://towardsdatascience.com/which-deep-learning-framework-is-growing-fastest-3f77f14aa318
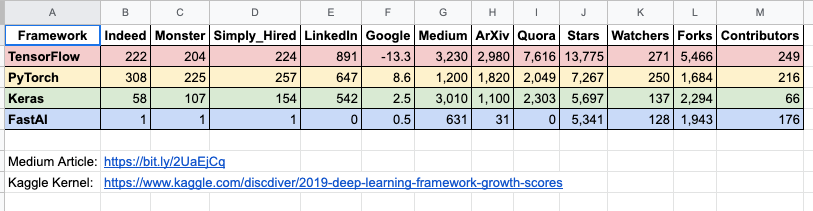
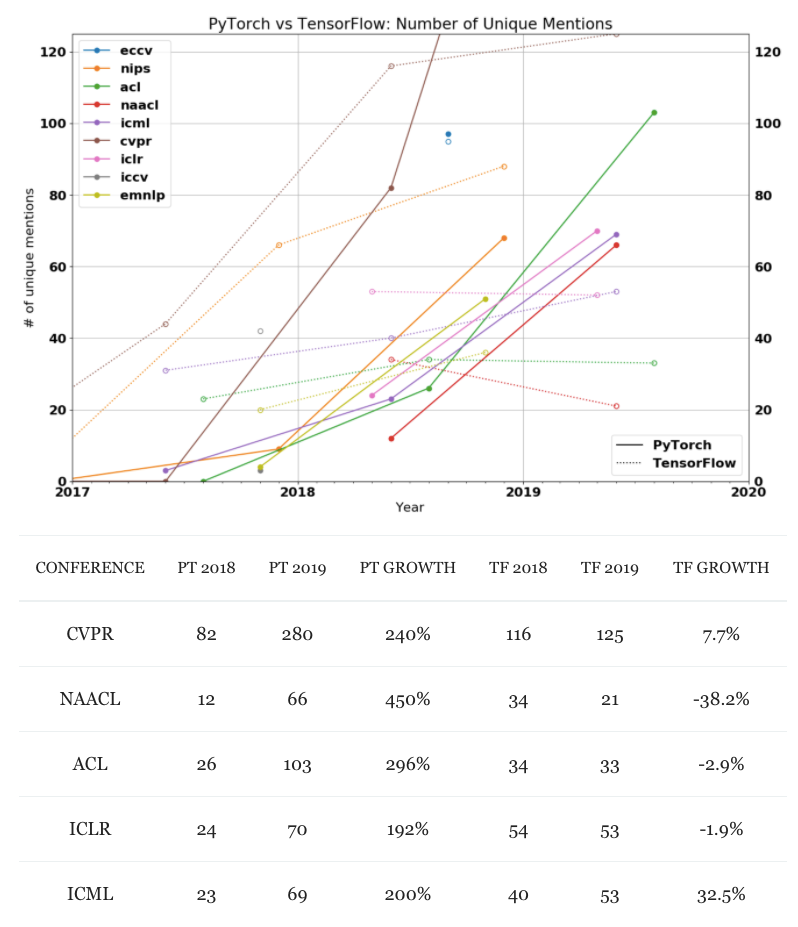
根据the gradient统计的数据,PyTorch在学术界越来越受到青睐,将TensorFlow远远甩在身后。
从几大AI顶会关键词数量来看,PyTorch在过去的两年中都是呈现爆炸式增长,而TF则是不断在走下坡路。
数据来源:
https://thegradient.pub/state-of-ml-frameworks-2019-pytorch-dominates-research-tensorflow-dominates-industry/
从业务线来看,Google不仅有框架,也有自己的云服务。而Facebook和亚马逊,一个框架够尖利,但是云端欠缺;另一个刚好相反,AWS稳居云计算第一的位置,但框架相比二者弱一些。
Google的意图很明显是要进一步扩大自己在训练和部署方面的优势,而Facebook的PyTorch,此前一直在生产环境部署等环节落后TensorFlow,此次更新的TorchServe和TorchElastic将弥补之前的差距。
和AWS合作也将获得亚马逊大量云端客户的青睐,毕竟自己开发的框架在自己平台用着更顺手,当然亚马逊也会在PyTorch社区获得更多支持。
说到这里我们不得不提到另外两个知名框架:Caffe和MXNet。虽然两者的市场规模不大,但也曾是全村的希望。
如今,Caffe已经被PyTorch取代,而一旦F/A合体,MXNet的命运又将如何呢?欢迎大胆留言猜测!